
| 文|程瑞林(山东大学第二医院足踝外科) 来源|(微信公众号)云中瑞麟(ID:ruilinfly) |
|---|
目录
一、概述
二、如何进行统计方法的选择[2]
三、分析目的
1.统计描述
2.统计推断
3.差异分析
4.回归分析/相关分析
四、研究设计
完全随机设计
配对设计
析因分析
重复测量设计
五、资料类型
1.数值变量
2.无序分类
3.有序分类
六、数据特征
数据的分布特征
方差齐性
七、统计分析方法的原理
1.假设检验的基本思想
2.假设检验的基本步骤
3.假设检验结果的判读
4.假设检验结论的两类错误
八、组间比较/差异分析-常用的假设检验方法
1.根据资料类型选择
2.根据数据组数选择
例子
九、相关分析/自变量与因变量关系分析/回归分析-常用检验方法
1.常用数值资料的关系分析方法
2.无序分类变量(计数资料)的相关分析
3.有序分类变量(等级资料)等级相关分析
一、概述

- 统计学可以用来进行推测
- 采用恰当的统计学方法是研究结论可靠、可信的前提
- 数理统计与概率论是统计的理论基础
- 只有当某个或某些条件满足时,某个数理统计公式才成立
涉及最多的是数据分布特征,其次方差齐性,再次理论数大小
例子1:假设检验及临床优效性检验
一研究者宣布找到一种治疗某病的新药,试验结果如下,问:该新药是否值得推广?

例子2:分析中混杂因素的控制
英国某年全人口统计资料如下,矛盾:移民组的发病率在各个年龄组均高于英格兰和威尔士组,为什么它的合计发病率反而低?

例子3:假设检验及判别诊断
为鉴别胃癌、胃炎、非胃病患者,各测定了50名患者的铜兰蛋白等指标,其中铜兰蛋白的观察结果如下,问:三种人的铜兰蛋白有无不同?能否根据测定的铜兰蛋白数据对患者进行初步诊断?

例子4:影响因素筛选-回归分析
研究心肌梗死患者预后的的影响因素,以是否发生心性死亡作为观察结果指标,对116名心梗患者的22个可能影响预后的因素进行观察和记录。
结局指标:心性死亡
预后因素:年龄、性别、高血压病、心梗位置、心梗分级、传导阻滞、溶栓治疗,……等
问:哪些预后因素与发生心性死亡有关系?关系的强度如何?
二、如何进行统计方法的选择[2]
【瑞麟】研究目的(4)+设计类型(4)+数据类型(3)+数据特征(4)→统计方法
| 因素 | 种类 |
|---|---|
| 研究目的 | 描述、推断、差异分析、相关分析/回归分析 |
| 设计类型 | 完全随机设计、配对设计、析因设计、重复测量设计 |
| 数据类型 | 计量资料、等级资料、计数资料 |
| 数据特征 | 分布特征、方差齐性、理论数大小、样本量 |
——↑瑞麟总结——
医学统计分析方法选择的核心三要素(3-5-3)
| 研究目的(3) 统计设计(5) 变量类型(3) |
|---|
"方法看变量、设计看类型、目的定乾坤"
“大怕踢、二怕镖、老三怕剪刀”
老大指数值型变量、老二指等级变量、老三指无序分类变量
大怕踢:T(脚踢)、F(旋风腿)
数值型变量一般选用t检验(两组变量)、方差分析(3组及以上资料)
二怕镖:非参数(飞镖)
等级变量一般选用非参数检验
老三怕剪刀:卡方(剪刀)
无序分类变量一般选用卡方检验
三、分析目的
1.统计描述
统计指标、统计图或统计表
如,均数、中位数、标准差、百分比、频数分布等
2.统计推断
参数估计、假设检验
估计总体参数、95%可信区间
3.差异分析
对几组资料进行差异性检验
假设检验方法,如,t检验、卡方检验、方差分析、秩和检验等
4.回归分析/相关分析
研究某因素与另一因素的依存关系
探讨变量之间的关系及影响大小
具体说,探讨自变量(影响因素)对应变量(结果变量)的影响大小
多变量分析方法
如,线性相关、线性回归、Logistic回归、Cox回归、生存分析等。
四、研究设计
完全随机设计
最常见,最易实施的实验设计方案
将研究对象随机分配到几个组,然后做实验
配对设计
将具有相似特征的研究对象配成对子,然后再将每个对子的对象随机分配到两个组进行实验
常见形式:同源配对(如样品一分为二);异源配对(按性别、体重、年龄进行配对);自身前后配对(试验前后的对比)
析因分析
同时研究多个实验因素对结果的影响
例如,研究药物剂量(3mg、6mg)及给药方式(口服、肌注)对结果的影响,每种组合均需要做试验(3mg+口服,3mg+肌注,6mg+口服,6mg+肌注)
重复测量设计
同一对象在不同时间点上进行某个指标的观测,以分析该指标在时间上的变化。
【瑞麟疑问】如只进行两个时间点上的测量,是否与自身前后配对的设计相同?
五、资料类型
| 计量资料→数值变量资料 等级资料→有序分类变量资料 计数资料→无序分类变量资料 |
|---|
1.数值变量
- 描述集中趋势的指标,用以反映一组数据的平均水平
- 描述离散程度的指标,用以反映一组数据的变异大小
两类指标的联合应用才能全面描述一组数值变量的基本特征
每一个观察对象都有一个数值,且大小差异有意义。
例如,血红蛋白(g/L)、住院天数、产前检查次数、住院费用等。
数值变量资料的描述


论文中最常用的组合
- 正态分布或近似正态分布:均数与标准差
- 偏态分布或未知分布:中位数与P25、P75(四分位数间距)
2.无序分类
以比代率,即误将构成比(proportion)当作率(rate)来描述某病发生的强度和频率。
把各种不同的率相混淆,如把患病率与发病率、死亡率与病死率等概念混同。
指类别或属性间无顺序、程度之分。
例如,性别(男、女)为二分类、血型(A、B、AB、O)为多分类。

3.有序分类
指类别间存在着次序,或程度上的差异。
例如,治疗效果(无效、好转、显效、治愈)、实验室检验(-、+、++、+++)
分类变量资料的描述:通常需要描述各个类别的频数及频率(百分比)

六、数据特征
任何统计方法都有自己的适用条件,只有当某个或某些条件满足时,统计计算公式才成立。
适用条件可根据数据特征来判断
- 数据的分布特征(正态、偏态)
- 方差齐性
- 理论数大小【待讨论】
- 样本量大小【待讨论】
数据的分布特征
数值变量资料的描述:通过绘制直方图可以直观了解数据的分布
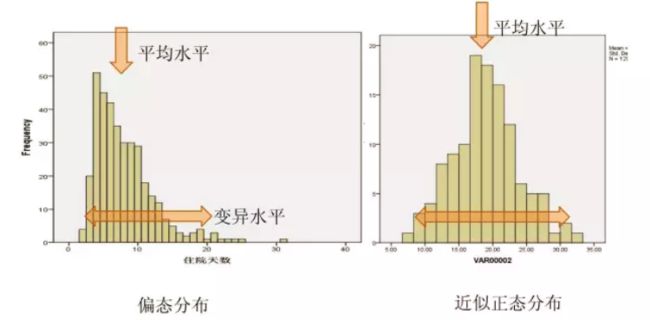

研究中,右偏态分布更常见,如住院时间、住院费用、病程等;左偏态分布较少见,如考生成绩有时呈左偏态分布。
R语言中如何进行频数分布直方图
得到的图表如下

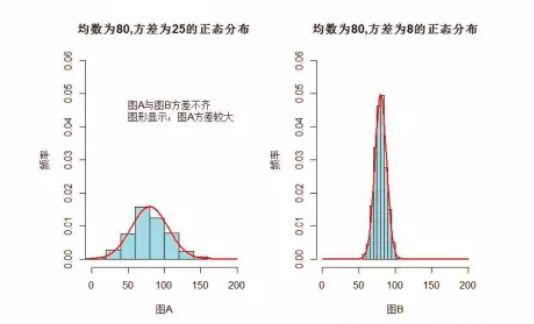
方差齐性
方差是否齐同(相等)
粗略判断:两组标准差之比在2.5倍以上,就得警惕方差不齐
七、统计分析方法的原理
1.假设检验的基本思想
假设检验出发点是:判断样本之间差异由什么原因造成的
样本数据间的差异有两种原因所致:(1)样本来自同一总体,差异因抽样误差所引起;(2)样本来自不同总体,差异因不同总体所引起
假设检验以P值大小作为推断依据:P值大,表示差异由抽样误差引起可能性大;P值小,表示差异由抽样误差引起可能性小,即由总体不同引起的可能性大;一般以0.05作为临界值来判断
假设检验是反证法原理的统计应用
假设两个样本均数可能来源于同一总体,然后计算出在此假设下的某个统计量的大小,当这个统计量在其分布中的概率较小时(如p≤0.05)我们就拒绝其假设,而接受其对立假设,认为两样本分别来自不同的总体。
2.假设检验的基本步骤
- 建立检验假设:无效假设(null hypothesis)H0、备择假设(alternative hypothesis)H1、检验水准(size of test)α
- 计算统计量(瑞麟:两个样子究竟有多大的不同)
- 根据统计量的值来得到概率(p)值;再按概率值的大小得出结论。
3.假设检验结果的判读
- 当p≤α时,概率越小,越理由拒绝H0假设(无差别假设),即拒绝H0假设的可信程度就越大
- 注意:当p≤α时,不能说“p值越小,组间的差别就越大”
- 假设检验的结论不能绝对化。在作出结论时,要避免使用绝对的或肯定的语句
- 当p≤α时,只要p≠0,我们就无法完全拒绝无差别假设,即不能肯定各总体间有差别
- 当p>α时,只要p≠1,我们就无法完全接受无差别假设,即不能肯定各总体间无差别
4.假设检验结论的两类错误
1)当p≤α时,做出“拒绝其无差别的假设,可认为各总体间有差别”的结论时就有可能犯错误,这类错误称为第一类错误(type I error)。其犯错误的概率用α表示,若α取0.05,此时犯I型错误的概率≤0.05,若假设检验的p值比0.05越小,犯第一类错误的概率就越小。
2)当p>α时,做出“不拒绝其无差别的假设,还不能认为各总体间有差别”的结论时就有可能犯第二类错误(type II error)。其犯错误的概念用β表示,通常β为未知数,但假设检验p值越大,犯第二类错误的概率就越小。
八、组间比较/差异分析-常用的假设检验方法
1.根据资料类型选择
计量资料的假设检验:t检验、F检验(方差分析)、Z检验、秩和检验(Wilcoxon秩和检验、H检验、Friedman检验)等。

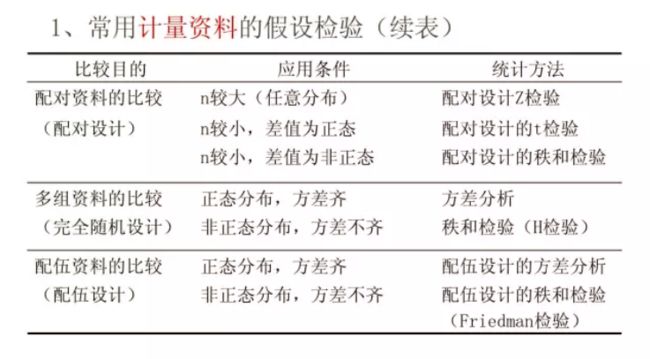


计数资料的假设检验:卡方检验、Z检验(瑞麟疑问:z检验即u检验?)



等级资料的假设检验:秩和检验(Wilcoxon秩和检验、H检验、Friedman检验)


2.根据数据组数选择
单个自变量资料

两个或以上自变量资料

两组比较:t检验、u检验、两组秩和检验、四格表和较正四格表的卡方检验等
多组比较:方差分析、多组秩和检验、行×列卡方检验等。
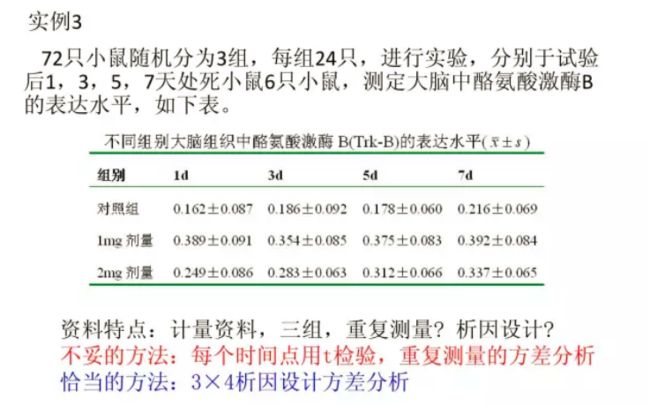
例子


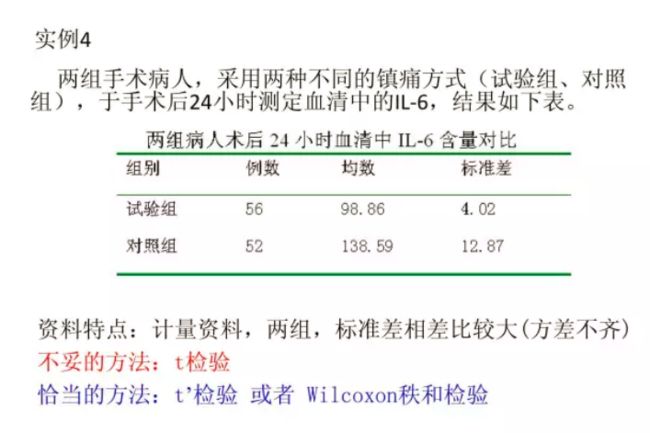


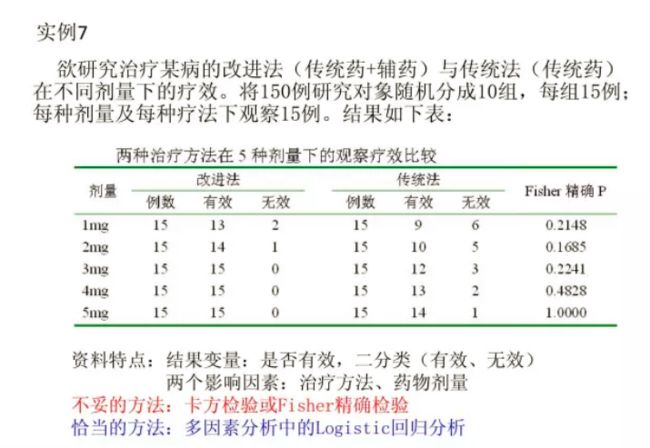
九、相关分析/自变量与因变量关系分析/回归分析-常用检验方法
差异分析/数据资料的比较,是同一指标在不同处理间的比较。
临床研究中,经常需要分析某些因素与疾病之间的关系,探讨疾病的危险因素。
注意,相关关系并不等于因果关系。

1.常用数值资料的关系分析方法

2.无序分类变量(计数资料)的相关分析
前瞻性研究:相对危险度(RR)、归因危险度(AR)
回顾性研究:比值比(OR)
3.有序分类变量(等级资料)等级相关分析
参数检验:积矩相关系数(Pearson's sγ)
非参数检验:Spearman等级相关系数
十、诊断性试验的研究与评价
1.方法与评价条件
1)确定金标准
诊断性试验的金标准(gold standard)是指当前临床医师公认的诊断疾病最可靠的方法,也称为标准诊断。应用金标准可以正确区分“有病”和“无病”。
拟评价的诊断性试验对疾病的诊断,必须有金标准为依据,所谓金标准包括活检、手术发现、细菌培养、尸检、特殊检查和影像诊断,以及长期随访的结果。
2)选择研究对象
诊断性试验的研究对象,应当包括两组:一组是用金标准确诊“有病”的病例组,另一组是用金标准证实为“无病”的患者,称为对照组。所谓“无病”的患者,是指没有金标准诊断的目标疾病,而不是完全无病的正常人。
病例组应包括各型病例:如典型和不典型的,早、中与晚期病例,轻、中与重型的,有和无并发症者等,以便使诊断性试验的结果更具有临床实用价值。
对照组可选用金标准证实没有目标疾病的其他病例,特别是与该病容易混淆的病例,以期明确其鉴别诊断价值。正常人一般不宜纳入对照组。
3)盲法比较诊断性试验与金标准的结果
评价诊断性试验时,采用盲法具有十分重要的意义,即要求判断试验结果的人,不能预先知道该病例用金标准划分为“有病”还是“无病”,以免发生疑诊偏倚。
新的诊断性试验,对疾病的诊断结果应当与金标准诊断的结果进行同步对比,并且列出格表,以便进一步评估,其方法如下:
①用金标准诊断为“有病”的病例数为a+c;
②上述“有病”的病例经诊断性试验检测,结果阳性者为a,阴性者为c;
③金标准诊断“无病”的倒数为b+d,其中经诊断性试验检测阳性者为b,阴性者为d;
④列出四格表,将a,b,c,d的倒数分别填入下列四格表。

敏感度(sensitivity, SN)是正确诊断的真阳性病例在中风组中所占的百分率,计算公式为为:SN=a/(a+c)×100%
特异度(specificity, SP)是正确诊断的真阴性部分所占百分率,计算公式为:SP=d/(b+d)×100%
准确性(accuracy,AC)反映了诊断试验结果与金标准试验结果的符合或一致程度,计算公式为:AC = (a+d)/N
阳性预测值(positive predictive value,PPV)是诊断试验为阳性结果中金标准证实患中风者所占的百分率,计算公式为: PPV = a/(a+b)×100%
阴性预测值(negative predictive value,NPV)是诊断试验为阴性结果中金标准证实未患中风者所占的百分率,计算公式为:NPV = d/(c+d)×100% .
阳性似然比(positive likelihood ratio, LR+)为患中风组真阳性率和未患中风组假阳性率的比值,计算公式为:LR+ =SN/(1-SP) ,表明诊断性试验为阳性时患病于不患病的比值,比值越大则患病的概率越大.
阴性似然比(negative likelihood ratio, LR-)为患中风组假阴性率与未患中风真阴性率的比值,计算公式为:LR- =(1-SN)/SP,表明诊断试验为阴性时,患病与不患病时机会的比值.
2.诊断性试验的应用及其临床意义
1)ROC曲线
ROC曲线(receiver operator characteeristic curve)又称受试者工作特征曲线,在诊断性试验中,用于正常值临界点的选择,对临床实验室工作尤为重要.
诊断资料可以按资料的等级或性质归纳成2X2表(四格表)或行列表。一般地说,如果诊断资料本身为二值变量,即诊断的结果为阳性和阴性,则归纳成四格表最合理。如果诊断资料为等级或连续变量,归纳成四格表就会造成信息的浪费,所以,最好将资料归纳成行列表,这样可以最大限度地利用信息。
如果诊断实验的资料为连续变量,可以将资料按一定的等级分级,归纳成行列表进行分析。

像这样的行列表,我们可以将其分割成表3形式的四格表,分别计算各指标,计算的结果见表3。

由表3可见,灵敏度和假阳性率随界值的降低而生高,但特异度则随界值的降低而降低。根据这样的关系,我们可以用假阳性率为横坐标,灵敏度为纵坐标做ROC曲线,见下图。

曲线左上角灵敏度是1.0(100%),假阳性率是0,即所有的病人全部被确诊,所有无病者都不会误诊。距左上角距离越近的曲线实验效果越好;
在ROC曲线上,靠坐上角距离最近的界点作为界值最好。(Q:为什么?)
在左上角处(灵敏度+特异度)/2的值最大,可以根据此及实际工作的需要来确定具体诊断实验的界值。
用ROC曲线可以比较不同诊断实验的优劣(Q:解释理由)。
2)似然比的临床应用
似然比(likelihood ratio)是诊断试验综合评价的理想指标,它综合了敏感度与特异度的临床意义,而且可依据试验结果的阳性或阴性,计算患病的概率,便于在诊断试验检测后,更确切地对患者作出诊断.
真阳性率越高,则阳性似然比越大.

参考文献:
1.《临床研究中统计方法的选择》,(微信公众号)临床科研与meta分析,2015-12-18
2.武松 《SPSS中级统计实战教程》之《医学统计方法选择秘籍(5秒判读法)》(丁香园公开课),2018-3-6
3.鸡小贩. 临床科研中如何选择统计学方法(PPT). 百度文库.2014-3-13