Selenium WebDriver(一)
这是Selenium里面最总要的东西。Selenium Webdriver(也就是Selenium2,Selenium3)和Selenium RC(Selenium 1)一样提供了web自动化的各种语言调用接口库。相比Selenium RC,Selenium WebDriver的编程接口更加直观易懂,也更加简练。但是和Selenium RC不同的是,Selenium Webdriver是通过各种浏览器的驱动(web driver)来驱动浏览器的,而不是通过注入JavaScript的方式,下面是其原理的示意图:

我们的代码运行起来是一个进程,里面调用Selenium WebDriver的库 和 各个浏览器的驱动进程 进行交互,传递Selenium命令 给它们,并且获取命令执行的结果,返回给我们的代码进行处理。
Selenium WebDriver目前包括两个版本Selenium 2和Selenium 3。这两个版本从开发代码调用接口上来看,几乎没什么区别。区别在于库的实现和web driver的实现。Selenium2是Selenium组织帮各种浏览器写web driver的,而Selenium 3里面的web driver是由各个浏览器厂商(Apple,Google,Microsoft,Mozilla)自己提供的。所以Selenium 3的自动化效率更高,成功率也更高。
Selenium WebDriver 支持浏览器众多:
- Google Chrome
- Microsoft Internet Explorer 7,8,9,10,11在 Windows Vista,Windows 7,Windows 8,Windows 8.1.
- Microsoft Edge
- Firefox
- Safari
- Opera
3.1安装
Selenium WebDriver提供了各种语言的编程接口,来进行Web自动化开发。我们以Python来讲解它的使用。首先我们要确保Python解释器已经安装好了。由于我们习惯在Windows操作系统上进行操作,建议大家安装Python官方的Python 3.6
- 安装编程接口库
python安装好后,我们用Pip来安装Selenium Web Driver的python库,执行下面的命令即可。(执行该命令之前,要确保python的script目录在系统环境变量path里面已经包括了)。命令为:pip install selenium
安装完成后,运行python解释器,执行命令import selenium,如果没有异常,则表示安装成功了,如下所示

- 安装各浏览器的驱动
当然我们是通过各浏览器的驱动程序来操作浏览器的,所以,还要有各浏览器的驱动程序。我们主要以谷歌的chrome浏览器为例来演示。
chrome浏览器的web driver(chromedriver.exe),可以在下面网址访问:
http://npm.taobao.org/mirrors/chromedriver/
firefox(火狐浏览器)的web driver (geckodriver.exe)在这里访问:
https://github.com/mozilla/geckodriver/releases
其他浏览器驱动可以见下面列表:
Edge:https://developer.microsoft.com/en-us/micrsosft-edage/tools/webdriver
Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
3.2从一个例子开始
#从selenium里面导入webdriver
from selenium import webdriver
#指定chrom的驱动
#执行到这里的时候Selenium会到指定的路径将chrome driver程序运行起来
driver = webdriver.Chrome('E:\ChromDriver\chromedriver.exe')
#driver = webdriver.Firefox()#这里是火狐的浏览器运行方法
#get 方法 打开指定网址
driver.get('http://www.baidu.com')
#选择网页元素
element_keyword = driver.find_element_by_id('kw')
#输入字符
element_keyword.send_keys('宋曲')
#找到搜索按钮
element_search_button = driver.find_element_by_id('su')
下面是对搜索结果的验证:
import time
#注意这里必须要等待时间,因为代码运行过快,代码运行完的时候页面还没加载出来就会找不到元素
time.sleep(2)
ret = driver.find_element_by_id('1')
print(ret.text)
if ret.text.startswith('宋曲'):#是不是已宋曲开头
print('测试通过')
else:
print('不通过')
#最后,driver.quit()让浏览器和驱动进程一起退出,不然桌面会有好多窗口
driver.quit()
下面是对代码的详细分析:
driver = webdriver.Chrome('E:\ChromDriver\chromedriver.exe')
执行到这里的时候Selenium会到指定的路径将chrome driver程序运行起来,chrome driver会将浏览器运行起来。成功后会返回一个WebDriver实例对象,通过它的方法,可以控制浏览器,我们可以把它想象成浏览器的遥控器一样。
浏览器运行起来后,通常第一件事情就是打开网址了。一般我们通过控制对象的get方法来控制浏览器打开指定网址
driver.get('http://www.baidu.com')
这一行执行后,web浏览器将会访问http://www.baidu.com这个网址。Selenium的官方文档说,不同的WebDriver和浏览器行为可能会有所不同。有的浏览器不一定等web页面完全加载完成,就返回了。当然通常我们希望的是加载完毕,再返回,不然可能页面上有的元素还没有出现,后续的操作可能有问题。这样还需要加入一些其他的代码等待某个关键的页面元素出现再进行后续操作。个人测试的情况看,Selenium 3的Chrom WebDriver驱动相应的chrom浏览器是会等待页面完全加载完成才返回的。所以我们可以放心。
接下来我们要查找到那个搜索输入栏网页元素,这里是根据该网页元素的id来选择的。
element_keyword = driver.find_element_by_id('kw')
网页元素的信息可以通过浏览器的debug功能来查看。怎么寻找网页元素,可以说是web自动化最重要的东西之一。下一节会讲到。
driver找到该元素的话,就会返回一个该元素的WebElement对象。我们接着就可以对其进行操作了,这个例子里面的操作,就是在这个输入框里面输入字符。
element_keyword.send_keys('宋曲')
后面就是在进行一次元素的选择和操作,找到搜索按钮,点击它。最后,执行下面的代码让浏览器和驱动进程一起退出
driver.quit()
这里大家要注意代码里我们用了time,注意这里必须要等待时间,因为代码运行过快,代码运行完的时候页面还没加载出来就会找不到元素。后面我们会想到更好的解决方法。
3.3 Web元素选择
浏览器读入页面文档(html格式)后,通过内置的layout engine(就是页面渲染引擎,也成为浏览器内核,比如Webkit、Gecko)将整个页面显示出我们看到的样子。我们人在看web页面的时候,是用眼睛视觉上web页面的元素,比如上面有个输入框。下面有个按钮。可是对浏览器这个程序来说,他会创建一个HTML DOM(Document Object Model)来理解和操作整个页面结构。这是一个树状的结构,下面是一张示意图:
DOM是W3C指定的标准,DOM是由一个个的node(节点)组成。而element(元素)是最重要的一种node,他是html中一个tag里面的内容,比如
<a href="www.baidu.com">My linka>
这个就是一个element,我们中文称之为元素。HTML DOM就是一个用来给程序增删改查HTML元素的接口。
所以,我们在程序中选择元素,就是在网页的DOM结构里选择元素。就像上面说的,web元素的选择,是Selenium开发的重中之重。因为,我们首先必须要找到web元素,才能对其进行操作。web元素的选择,在Selenium可以通过WebDriver对象,也可以通过WebElement对象选择,它们都有成员 方法来进行选择。通过WebDriver对象选择,查找范围是整个html文档。而通过WebElement对象选择,查找范围是整个该对象的子元素,web元素的选择,有好几种方式。下面会一一讲述。
3.3.1通过id选择属性
web元素可以有很多属性(attribute)
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
上面元素的属性被用黑体显示了。这些属性中,id是非常特殊的一个,它是在DOM中唯一标志这个元素的。所以,如果web元素有id属性的话,是最好查找的,也是效率最高的,通过id就唯一的找到了它。
要找到该元素,可以用下面的方法
element = driver.find_element_by_id("kw")
或者换一种写法,导入Selenium by这个类,效果是一样的,个人更喜欢上面的方法
from selenium.webdriver.common.by import By
element = driver.find_element(by=By.ID, value="kw")
都是可以的,大家以后看到别人的代码这样写,不要感到吃惊
注:id其实还有重复的,虽然我们讲id不应该重复
的,但是有的人可能写错了,如果有重复的假如说你要查个某个id通过Webdriver对象查找,他查找的是整个页面查找的是第一个符合条件的,他可能不是你想要的,你可以先通过先缩小查找范围,先查找他的父节点id,再通过父节点id再去find_element_by_id这样就限制他的范围了,这是一种常用的方法。
没有找到会抛出如下异常
selenium.common.exceptions.NoSuchElementException
如果抛出异常,后面的程序就执行不到了,假如
你不希望由于某一个异常导致程序结束的话,我们可以加一个异常的捕获
from selenium.common.exceptions import NoSuchElementException
try:
ele = driver.find_element_by_id("food333")
except NoSuchElementException:
print('NoSuchElementException')
3.3.2获取元素 inner Text
innerText 是 DOM节点的属性,它代表了 node 节点(通常是元素)可以显示出来的文本内容。通俗点说,就是我们能在界面上看到的文本内容,比如按钮上的问题、输入框里面的内容、元素的内容、链接的文本内容,等等。可想而知,这是我们经常需要获取的东西。Selenium 通过 Webdriver 的 text属性来获取其内容。下面的代码将当前页面上的 id 为 1 的元素的可见文本打印出来。代码实例如下
text属性 显示该元素在web页面显示出来的文本内容。
ret = driver.find_element_by_id('1')
print(ret.text)
我们有的时候,希望获取的不是某个元素的页面展示部分,而是它的一个属性的值, 这时候,我们可以通过一个方法get_attribute方法,这个方法就是返回元素的某个属性的值。看下面示例:
a>
下面的代码就是获取href属性的值,就获取到了链接
ele = driver.find_element_by_id("baidulink")
print (ele.get_attribute('href'))
有的时候,我们需要完整的获取这个元素对应的html进行分析,比如
我们还是通过get_attribute方法,只需要参数指定为outerHTML就可以了。
ele = driver.find_element_by_id("baidulink")
print (ele.get_attribute('outerHTML '))
上面代码输出的结果就是:
a>
如果我们只想获取 该元素的内部的html源代码,我们还是通过get_attribute方法, 只需要参数指定为innerHTML就可以了。
ele = driver.find_element_by_id("baidulink")
print (ele.get_attribute('innerHTML'))
上面代码输出结果就是:
转到百度
有如下一段html
div id="food" style="margin-top:10px;color:red">
<span calss="vegetable good">黄瓜span>
<span calss="meat">牛肉span>
<p calss="vegetable">南瓜p>
<p calss="vegetable">青菜p>
用attribute('innerHTML')方法获取该元素的内部的html源代码效果如下:
ele = driver.find_element_by_id("food")
print (ele.get_attribute('innerHTML'))
上面代码输出结果就是:
<span calss="vegetable good">黄瓜span>
<span calss="meat">黄瓜span>
<p calss="vegetable">南瓜p>
<p calss="vegetable">青菜p>
就是这个元素的内部的内容,不包括它本身的这段。
各位可能会疑惑我们获取这些东西干嘛?我们为什么要或整个html呢,因为有的时候我们开发自动化程序的时候,比如测试不通过,某个点不通过,这个时候想把比如说选择元素没选择到,或者元素的内容和预期的内容不一样,这个时候需要判断分析定位,这个时候把它放在自动化用例里面,就可以把他整个html信息弄回来,把它打印到日志里面,方便自动化用例执行完了用来分析和判断,用来定位问题的一种手段。
还有一种场景有时候你去选择一个元素的时候根据常规手段,无法去获取选择内容了比如看下面的例子。
div id="food" style="margin-top:10px;color:red">
<span calss="vegetable good">黄瓜span>
<span calss="meat">牛肉span>
<p calss="vegetable">南瓜p>
<p calss="vegetable">青菜p>
假如我要获取牛肉他的class属性是否是meat,我们后面学到的选择元素方法是很简单获取到的,假如根据现在的知识点,只有父元素有id他本身没有id的,根据当前的知识点获取不到他,那怎么办呢?我们可以把有id的父元素整个HTML拿回来,通过get_arrtibute(innerHTML)方法拿回来,然后通过split()切割字符串的方法得到。
代码如下:
#找到id为food的元素
ele = driver.find_element_by_id('food')
#通过get_attribute('innerHTML')方法拿到内部元素
foodText = ele.get_attribute('innerHTML')
#通过split()方法得到数据
ret1 = foodText.split('</span>)[1]
ret2 = ret1.split('"')[1]
通过这样一个方法,我们就得到了meat上面这种方法当然可以达到目的,但是比较丑陋代码多了一点让人费解,更重要的是不够健壮,比如属性值可以用单引号也可以用双引号,如果开发下次改代码改成了单引号,我们的代码就没用了。
我们怎么样让程序更健壮一点呢,不需要那么麻烦使用字符串分割,我们可以使用另外一种方法BeautifulSoup4这个库。
3.3.3 BeautifulSoup4的介绍与安装
BS是可以从HTML或XMl文件中提取数据的库,他就是一个让你来HTML的工具,他可以把信息提取出来,不需要用字符串切割这种方法Selenium可以 用来远程获取数据。有的时候,感觉用Selenium获取某些元素数据不太方便
我们可以将它 和 Selenium两种技术融合使用达到我们的目的。
beautifulSoup4 和** Selenium的关系:直接的讲他们 两者没有直接关系,beautifulSoup4** 是python程序直接对一个字符串进行分析的,这个字符串要符合HTML或XMl的格式,他是专门用来处理HTML或XMl格式的字符串的,他和selenium自动化没有直接的关系。他是python语言独有的
beautifulSoup4 中文文档大家可以看一下:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
- 安装编程接口库
我们用Pip来安装BeautifulSoup4这个库,执行下面的命令即可。(执行该命令之前,要确保python的script目录在系统环境变量path里面已经包括了)。命令为:pip install beautifulsoup4
安装好beautifulsoup之后强烈要求大家安装html5lib 这个库,如果大家要进行HTML分析的话,因为beautifulsoup4内置分析HTML他对HTML语法兼容性不够好,指定用html5lib来分析,html5lib库对HTML兼容性比较好,这个库对html的兼容性基本和浏览器差不多。
- 安装html5lib
pip install html5lib
3.3.4 BeautifulSoup4的使用
现在我们根据一个例子来讲解如何使用bs,本地有一个html文档,注意他只是本地的一个磁盘文件和Selenium没有关系,如下
<html lang="en">
<head>
<meta charset="UTF-8">
<title>三兄弟的故事title>
<title>三兄弟的故事23454554545title>
head>
<body>
<p class="title tile2" style="color:red"><b>三兄弟的故事b>p>
<p class="story">从前有三个兄弟,他们的名字是
<a href="http://example.com/elsie" class="sister" id="link1">张三a>,
<a href="http://example.com/lacie" class="sister" id="link2">李四a> 和
<a href="http://example.com/tillie" class="sister" id="link3">王二a>;
他们都住在一口井里.p>
<p class="story">...p>
<div id="d1">
<a href="http://baidu.com/tillie" class="sister" >百度a>
div>
body>
html>
下面是使用BeautifulSoup库处理HTML字符串
with open('bs1.html',encoding='utf8') as f:
html_doc = f.read()
#从bs4这个库导入BeautifulSoup对象
from bs4 import BeautifulSoup
#指定用html5lib来解析文档
soup = BeautifulSoup(html_doc,'html5lib')
下面我们从html文档获取我们想要获取的信息,比如说获取一个标签名为title的元素,怎么做呢?看示例
# 查找 标签名为title的第一个元素 ,
# 返回一个 实例
print(soup.find('title'))
find就是找,这里我们找到的是标签名为title的元素.
<titile>三兄弟的故事title>
大家看我上面HTML的截图,里面有两个元素标签名为title,他找的是第一个,这里代码运行会很快因为我们是本地运行,不需要和浏览器交互和Selenium没关系,假如我们想要获取title的内容进行分析的话该怎么办?
可以用string方法
#.string就是获取内部的内容
print(soup.find(title).string)
#也可以这样写
print(soup.title.string)
也可以用get
print(soup.find(title).get_text())
#也可以这样写
print(soup.title.get_text())
输出结果为:
三兄弟的故事
这两种方法是有区别的,建议大家使用get_text()方法,下面给大家举个例子,看下面的html
<div id="dl">
<a herf="http://baidu.com/tillie" class="sister">百度a>>
<div>
如果想要获取div元素里面的文本内容,百度并不是直接内容,是他子节点的内容,这个时候就用get_text()才能获取到“百度”,如果用.string的话会打印出“None”,None就是没有因为string优先显示div元素的直接文本,但是这里面的文本是他子元素的文本,所以建议大家优先使用get_text()。
目前我们只简单介绍了BeautifulSoup如果获取文本,这还没有什么神奇的,我们还可以进行更为复杂的分析,比如我们想获取其中某一个属性的值,我们要获取第一个a的class属性值
<body>
<p class="title tile2" style="color:red"><b>三兄弟的故事b>p>
<p class="story">从前有三个兄弟,他们的名字是
<a href="http://example.com/elsie" class="sister" id="link1">张三a>,
<a href="http://example.com/lacie" class="sister" id="link2">李四a> 和
<a href="http://example.com/tillie" class="sister" id="link3">王二a>;
他们都住在一口井里.p>
那我们该怎么写呢?
#第一种方法
print(soup.find('a')['class'])
#第二种方法
print(soup.a['calss'])
就获取到了第一个a的class属性的值,这样我们就可以获取属性的值了,讲到这里大家发现我们都是找第一个元素,如果我想找第三个第四个怎么办?find还有一个方法叫find_all,那我们要找到所有的a该怎么写呢??
print(soup.find_all('a'))
这个时候打印出来的是一个列表,就全找到了
[<a class="sister" href="http://example.com/elsie" id="link1">张三</a>,
<a class="sister" href="http://example.com/lacie" id="link2">李四</a>,
<a class="sister" href="http://example.com/tillie" id="link3">王二</a>,
<a class="sister" href="http://baidu.com/tillie">百度</a>, <a class="sister" herf="http://baidu.com/tillie">百度</a>]
我们想找第二个怎么办,直接用python的知识下标。
print(soup.find_all('a'))[1]
就找到李四了,这种方法有时候比较麻烦,有的时候网页很大很大,比如有上百个a,你要找第几个你也不知道,一个个数肯定不现实,那怎么办?还一种方法根本不需要find_all把所有的都找出来再通过下标去找,可以通过其他的属性还限定他,假如说我们要找第二个a,发现他有id这个时候我们可以通过id属性来找。
print(soup.find('a',id='link2'))
通过上面的代码就可以直接找到他,不一定要用id属性,任何属性都可以
这里就可以发现BeautifulSoup可以进行数据的提取,我们甚至可以用多个条件进行提取。
print(soup.find('a',id='link2',herf='http://exaple.com/lacie'))
大家还记得上面我们想获取牛肉的calss属性是否是meat,当时我们用python字符串切割的方法得到的,我们可以通过BeautifulSoup直接获取啦!
ele = driver.find_element_by_id('food')
html= ele.get_Attribute('innerHTML)
print(html)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'html5lib')
target = soup.find_all('span')[1]['class']#列表
print(taget)
这种写法更稳定可靠,写法有很多种下面再介绍一种写法,目的就是判断值是不是meat,我们直接根据class属性去找,如果我们根据class等于meat能找到说明也有。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'html5lib')
target = soup.find('span',{'class':'meat'})
if target:
print('是meat')
print(taget)
注意这里不能直接这样写find('span',class='meat'),因为class是我们定义类的关键字
3.3.5 查看元素的属性
上面讲了可以根据id来查找元素,可是,面对一个别人开发的网页,我们怎么知道元素的属性值呢?现在,基本上每款浏览器都会内置开发者工具(通常是在浏览器窗口下按F12按键打开),我们可以利用浏览器的开发者工具来查看。在chrom浏览器里,按F12,打开开发工具窗口,chrom界面如下所示:
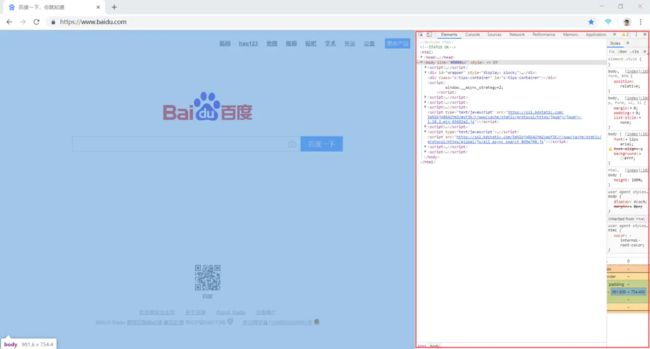
其中右边红框里面的窗口就是开发者工具窗口。它的功能非常强大,web前端开发人员经常用来调试前端代码。我们这里先使用它来查看web元素的属性信息。工具栏的上边最左边的箭头,就是用来选择界面元素,并且查看其信息用的。我们点击这个箭头,再异动鼠标到左边的页面上,点击一下搜索输入框,结果右边的开发工具窗口内容如下:
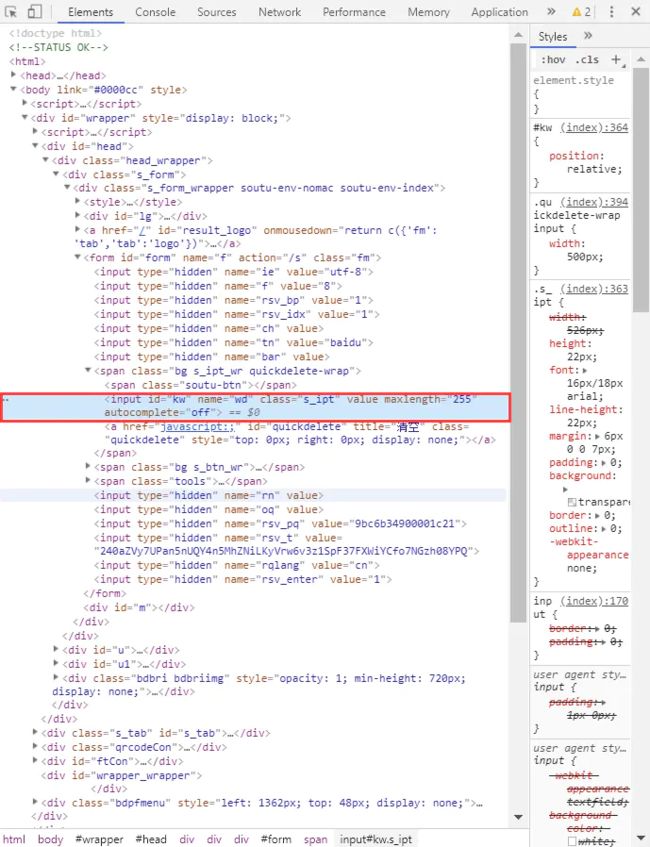
大家请注意红圈里面的内容,这里就是该输入框的html代码内容,里面的属性有id,name,class等。这样我们就可以知道该元素的信息了。这是Chrome浏览器的用法。事实上,其他浏览器基本也大同小异。大家可以自己尝试一下
3.3.6 通过name属性选择
name也是html标准属性之一,假设要选择的元素具有该属性的话,也可以通过它来进行选择。假设html中有如下元素:
<input name="cheese" type="text"/>
要找到该元素,可以用下面的方法:
cheese = driver.find_element_by_name("cheese")
或者:
from selenium.webdriver.common.by import By
cheese = driver.find_element(By.NAME, "cheese")
要注意的是,和id不同,name不一定是唯一的(当然通常是唯一的)。
当指定选择的名字,在网页中有多个元素都具有时,返回的是第一个找到的元素。
如果我们要找出所有具有该名字的元素可以这样,代码如下:
cheeses = driver.find_elements_by_name("cheese")
或者:
from selenium.webdriver.common.by import By
cheeses = driver.find_elements(By.NAME,"cheese")
这时,返回的是一个python list,里面包含了所有找到的WebElement对象,如果找不到,返回空列表,不抛出异常。
3.3.7 通过class选择元素
class也是html标准属性之一,假设要选择的元素具有该属性的话,也可以通过它来进行查找。但是通常具有相同class 属性值的元素很多,我们往往调用选择多个元素的方法,而不是选择一个元素。假设html中有如下片段:
<div class="cheese"><span>Cheddarspan>div>
<div class="cheese"><span>Goudaspan>div>
要找到该元素,可以用下面的方法:
cheeses = driver.find_elements_by_class_name("cheese")
或者:
from selenium.webdriver.common.by import By
cheeses = driver.find_elements(By.CLASS_NAME, "cheese")
这时,返回的是一个python list,里面包含了所有找到的WebElement对象。
注意:通过elements这个返回的就不是一个webelement对象了,他是所有的符合条件的wedelement对象,既然是所有的返回的时候放在一个列表里面,所以他的返回值就是列表,这个时候我们就不能用这种写法了
eles = find_elements_by_name('button')
print(eles.get_attribute('outerHTMl'))
上面这种写法是不对的,因为eles是个列表,列表并没有get_attribute()方法,这个方法只有webelement对象才有的,只有列表里的每一个元素才有的,那我们该怎么写呢?
eles = find_elements_by_name('button')
for ele in eles:
print(ele.get_attribute('outerHTMl'))
这样就可以了,通过for循环去遍历class同理
3.3.8通过 tag 名称选择
有的时候,有的上述的定位方式都不能定位到,比如 一个元素没有id,没有class、name。 但是它的tag名却是唯一的。可以根据tag名定位
假设html中有如下片段:
<iframe src="...">iframe>
如果iframe这个tag在本html中是唯一的,可以根据iframe这个tag名来找到该元素:
frame = driver.find_element_by_tag_name("iframe")
或者:
from selenium.webdriver.common.by import By
frame = driver.find_element(By.TAG_NAME, "iframe")
3.3.9 通过链接文本选择
web自动化的时候,经常会自动化点击某个链接,对于链接,可以通过其链接文本的内容或者部分内容进行选择。假设html中有如下片段:
<a href="http://www.baidu.com">转到百度</a>
可以这样选择:
ele = driver.find_element_by_link_text("转到百度")
或者:
from selenium.webdriver.common.by import By
ele = driver.find_element(By.LINK_TEXT, "转到百度")
有的时候,链接的文本很长,我们甚至只需要通过部分文本去找到该链接元素只要这个链接文本是唯一的就行,可以这样选择。
ele = driver.find_element_by_partial_link_text("百度")
或者:
from selenium.webdriver.common.by import By
ele = driver.find_element(By.PARTIAL_LINK_TEXT, "百度")
下面是小练习,自己练习玩的
Selenium 练习1
1.访问天气查询网站(网址如下),查询江苏省天气
http://www.weather.com.cn/html/province/jiangsu.shtml
获取江苏所有城市的天气,并找出其中每天最低气温最低的城市,显示出来,比如
温度最低为12℃, 城市有连云港 盐城
方法1:取回 整个 html 代码片段, 用python语言, 直接分析
from selenium import webdriver
driver = webdriver.Chrome(r"d:\tools\webdrivers\chromedriver.exe")
# ------------------------
driver.get('http://www.weather.com.cn/html/province/jiangsu.shtml')
ele = driver.find_element_by_id("forecastID")
print(ele.text)
citysWeather = ele.text.split('℃\n')
# 这样:citysWeather是每个城市的温度信息 list
#
# 每个元素像这样:
# 南京
# 12℃/27
#下面就是算法,算出温度最低城市,
# 有很多方法,大家看看这种
# 我们循环 去遍历这个城市文档信息列表,
# 得到城市名和 低气温的值,
#
# 依次和取出当前的所有城市最低气温比较,
# 如果更低,就记录到当前的低温城市列表中。
lowest = None # 记录目前最低温,先设置为None
lowestCitys = [] # 温度最低城市列表
for one in citysWeather:
one = one.replace('℃','')
print(one)
parts = one.split('\n')
curcity = parts[0]
lowweather = min([int(one) for one in parts[1].split('/')])
# 还没有最低温记录,或者发现气温更低的城市
# 注意 条件不能写反
if lowest==None or lowweather<lowest:
lowest = lowweather
lowestCity = [curcity]
# 温度和当前最低相同,加入列表
elif lowweather ==lowest:
lowestCity.append(curcity)
print('温度最低为%s℃, 城市有%s' % (lowest, ' '.join(lowestCity)))
# ------------------------
driver.quit()
方法2:用 selenium 直接的获取我们要的数据,我们分析一下html,看看能否精确的直接获取每个城市的名字和温度,发现每个城市的信息都在dl里面。
driver.get('http://www.weather.com.cn/html/province/jiangsu.shtml')
ele = driver.find_element_by_id("forecastID")
print(ele.text)
# 再从 forecastID 元素获取所有子元素dl
dls = ele.find_elements_by_tag_name('dl')
# 将城市和气温信息保存到列表citys中
citys = []
for dl in dls:
# print dl.get_attribute('innerHTML')
name = dl.find_element_by_tag_name('dt').text
# 最高最低气温位置会变,根据位置决定是span还是b
ltemp = dl.find_element_by_tag_name('span').text
ltemp = int(ltemp.replace('℃',''))
print(name, ltemp)
citys.append([name, ltemp])
既然每个城市的名字和温度都有了, 下面的做法就和前面差不多
lowest = None
lowestCitys = [] # 温度最低城市列表
for one in citys:
curcity = one[0]
ltemp = one[1]
# 发现气温更低的城市
if lowest==None or ltemp<lowest:
lowest = ltemp
lowestCitys = [curcity]
# 温度和当前最低相同,加入列表
elif ltemp ==lowest:
lowestCitys.append(curcity)
print('温度最低为%s℃, 城市有%s' % (lowest, ' '.join(lowestCitys)))
方法3:取回 整个html代码片段, 用beatifulsoup 分析大体思路和方法二 一样, 唯一的区别在于,我们不是用selenium获取每个城市温度对应的web元素信息而是用BS本地操作。
driver.get('http://www.weather.com.cn/html/province/jiangsu.shtml')
ele = driver.find_element_by_id("forecastID")
print(ele.text)
# -----------------------------------
# 再从 forecastID 元素获取所有子元素dl
html_doc = ele.get_attribute('innerHTML')
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "html5lib")
# 发现每个城市的信息都在dl里面
dls = soup.find_all('dl')
# 将城市和气温信息保存到列表citys中
citys = []
for dl in dls:
name = dl.a.string
ltemp = dl.b.string
ltemp = int(ltemp.replace('℃',''))
print(name, ltemp)
citys.append([name,ltemp])
后面的代码一模一样,直接拷贝即可
lowest = None
lowestCitys = [] # 温度最低城市列表
for one in citys:
curcity = one[0]
ltemp = one[1]
# 发现气温更低的城市
if lowest==None or ltemp<lowest:
lowest = ltemp
lowestCitys = [curcity]
# 温度和当前最低相同,加入列表
elif ltemp ==lowest:
lowestCitys.append(curcity)