一般提升模型效果从两个大的方面入手
数据层面:数据增强、特征工程等
模型层面:调参,模型融合
模型融合:通过融合多个不同的模型,可能提升机器学习的性能。这一方法在各种机器学习比赛中广泛应用, 也是在比赛的攻坚时刻冲刺Top的关键。而融合模型往往又可以从模型结果,模型自身,样本集等不同的角度进行融合。
模型融合是后期一个重要的环节,大体来说有如下的类型方式:
-
加权融合(投票、平均)
硬投票

软投票

-
boosting/bagging(集成学习)
-
stacking/blending
本文主要介绍stacking/blending方法的原理,及其实际应用
Stacking模型本质上是一种分层的结构,这里简单起见,只分析二级Stacking.假设我们有3个基模型M1、M2、M3。[1]
-
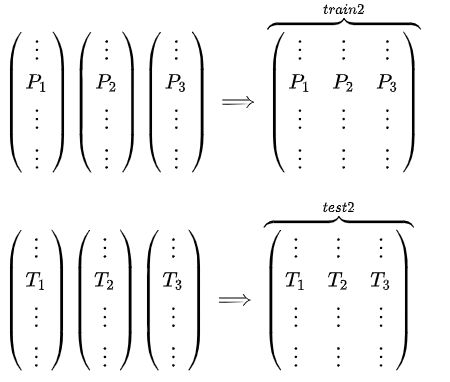
基模型M1,对训练集train训练,然后在训练集和测试集预测,分别得到P1,T1。同理,得到P2,T2;P3,T3
\[\begin{pmatrix} \vdots\\ P1\\ \vdots\\ \end{pmatrix} \begin{pmatrix} \vdots\\ T1\\ \vdots\\ \end{pmatrix}, \begin{pmatrix} \vdots\\ P2\\ \vdots\\ \end{pmatrix} \begin{pmatrix} \vdots\\ T2\\ \vdots\\ \end{pmatrix}, \begin{pmatrix} \vdots\\ P3\\ \vdots\\ \end{pmatrix} \begin{pmatrix} \vdots\\ T3\\ \vdots\\ \end{pmatrix} \] -
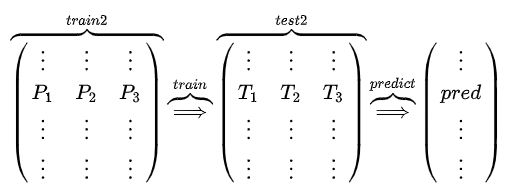
分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2.
-
再用第二层的模型M4训练train2,预测test2,得到最终的标签列。
注意:
用整个训练集训练的模型反过来去预测训练集的标签,毫无疑问过拟合是非常非常严重的,因此现在的问题变成了如何在解决过拟合的前提下得到P1、P2、P3,这就变成了熟悉的节奏——K折交叉验证。
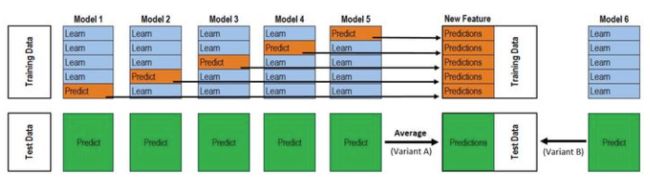
上图的模型1-5其实是一个模型在不同折下训练。
最终的代码是两层循环,第一层循环控制基模型的数目,每一个基模型要这样去得到P1,T1,第二层循环控制的是交叉验证的次数K,对每一个基模型,会训练K次最后拼接得到P1,取平均得到T1。
python实现[2]
### 6折stacking
n_folds = 6
skf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=1)
for i,clf in enumerate(clfs):
# print("分类器:{}".format(clf))
X_stack_test_n = np.zeros((X_test.shape[0], n_folds))
for j,(train_index,test_index) in enumerate(skf.split(X_train,y_train)):
tr_x = X_train[train_index]
tr_y = y_train[train_index]
clf.fit(tr_x, tr_y)
#生成stacking训练数据集
X_train_stack [test_index, i] = clf.predict_proba(X_train[test_index])[:,1]
X_stack_test_n[:,j] = clf.predict_proba(X_test)[:,1]
#生成stacking测试数据集
X_test_stack[:,i] = X_stack_test_n.mean(axis=1)
理论介绍推荐阅读[1],实现部分可以阅读[2]
references
【1】【机器学习】模型融合方法概述. https://zhuanlan.zhihu.com/p/25836678
【2】Kaggle提升模型性能的超强杀招Stacking——机器学习模型融合. https://zhuanlan.zhihu.com/p/107655409