一、说明
本文主要介绍InfluxDB的聚合类函数Aggregations。
二、函数介绍
1)count()函数
返回一个(field)字段中的非空值的数量。
语法:SELECT COUNT(
> select count(region_endKey) from hbase_regions
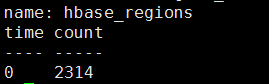
说明region_endKey这个字段在hbase_regions表中共有2314条数据。 注意:InfluxDB中的函数如果没有指定时间的话,会默认以 epoch 0 (1970-01-01T00:00:00Z) 作为时间。
可以在where中加入时间条件,如下:
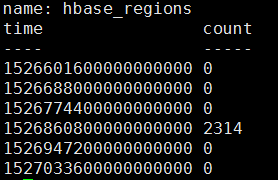
select count(region_endKey) from hbase_regions where time >='2018-05-18T00:00:00Z' AND time<'2018-05-23T12:25:00Z' GROUP BY time(1d)
2)DISTINCT()函数 不寻常的; 有区别的; 确切的;
返回一个字段(field)的唯一值。
语法:SELECT DISTINCT(
> select distinct(table_online_regions) from hbase_tables
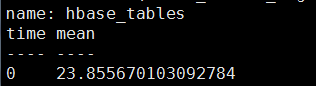
3)MEAN() 函数
返回一个字段(field)中的值的算术平均值(平均值)。字段类型必须是长整型或float64。
语法格式:SELECT MEAN(
select mean(table_online_regions) from hbase_tables
4)MEDIAN()函数 中位数
从单个字段(field)中的排序值返回中间值(中位数)。字段值的类型必须是长整型或float64格式。
语法:SELECT MEDIAN(
select median(table_online_regions) from hbase_tables
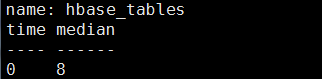
注意:数据中的相同数字不互斥
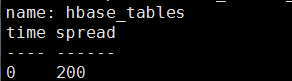
5)SPREAD()函数 范围
返回字段的最小值和最大值之间的差值。数据的类型必须是长整型或float64。
语法:SELECT SPREAD(
select spread(table_online_regions) from hbase_tables
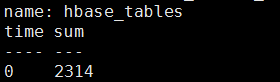
6)SUM()函数
返回一个字段中的所有值的和。字段的类型必须是长整型或float64。
语法:SELECT SUM(
> select sum(table_online_regions) from hbase_tables