本文部分内容来自 腾讯 研究院 辛俊波 有部分修改和整理
部分个人理解用andy注明,不代表原文观点。
目录:
1.介绍推荐系统的分类
2.介绍分类之间的细节区别
3.一句话总结
4.参考和建议看的文献和分析
传统算法推荐系统核心——给定user和context,匹配最佳的item 。
----------------------------------------------------------------------------------------------------
1.分类
推荐系统大体分为两类:传统模型(协同cf为代表)和深度模型(神经网络ncf为代表)
传统模型,又可分为基于协同过滤的模型和基于特征的模型,两者最大的不同在于是否使用了 side information(辅助信息)如商品的类名、店铺名等。
andy:先说结论,传统模型终极发展模型应该是因子分解机FM(或者在FM基础上发展出来的算法-FFM Field-aware Factorization Machine )。
----------------------------------------------------------------------------------------------------
1.1传统模型
1.1.1基于协同过滤的模型
如 CF,MF,FISM,SVD++,只用到了用户-物品的交互信息,如 userid, itemid, 以及用户交互过的 item 集合本身来表达。
1.1.2基于特征的模型
以 FM 为例,主要特点是除了用户-物品的交互之外,还引入了更多的 side information。FM 模型是很多其他模型的特例,如 MF,SVD++,FISM 等。
对于深度模型,主要分为基于 representation learning 的深度模型以及 match function learning 的深度模型。
----------------------------------------------------------------------------------------------------
1.2深度模型
1.2.1基于 representation learning 的深度模型学习
是用户和物品的表示,然后通过匹配函数来计算,这里重点在与 representation learning 阶段,可以通过 CNN 网络,auto-encoder,知识图谱等模型结构来学习。
1.2.2 match function learning 的深度模型
也分为基于协同过滤的模型和基于特征的模型。前者和传统 CF 模型一样,不同在于后面接入了 MLP 模型来增强非线性表达,目的是为了使得 user 和 item 的 vector 尽可能接近,这种方法就是基于 NCF 的模型;也有通过引入 relation vector 来是的 user vector 加上 relation vector 后接近 item vector,这种方法是基于翻译的模型。对于 match function learning 另一种模型框架,是基于特征层面的,有基于 fm 模型的,基于 attention 的,以及高阶特征捕捉的,另外还有基于时间序列的文章中只提到了 DIEN 模型。
andy:关于传统模型和深度模型哪个更好,推荐系统行业内的大会有不同的意见,在此不树立观点。比较一致的想法是:模型不存在谁淘汰谁的问题。模型可以理解为在一批观察数据集上给出最好解释的一个数学公式,真理只有一个,简单和复杂都是客观的,一般都是简单的模型来淘汰复杂的。原因:从概率角度讲,如果能解释有限数据集的模型有N个,而模型是由很多结构和参数组合而成的,这样的话简单的模型数量一定是远远比复杂模型要少。如果一个数据集命中了一个简单的模型,那说明这个简单模型的置信度极高。这也就是所谓的奥卡姆剃刀原理,即简单的总是最好的。
----------------------------------------------------------------------------------------------------
2. 细节区别和优化方向
每章节分别介绍该算法基本特点和优化方向。
每下一个算法分别指出优化了算法的哪里不足。
----------------------------------------------------------------------------------------------------
2.1 协同过滤CF
2.1.1基本思想:
基于

其中左侧 M=m*n 表示用户评分矩阵,m 矩阵的行表示用户数,n 矩阵的列表示 item 数,在大多数推荐系统中 m 和 n 规模都比较大,因此希望通过将 M 分解成右侧低秩的形式。一般来说 SVD 求解可以分为三步:
❶ 对 M 矩阵的 missing data 填充为0
❷ 求解 SVD 问题,得到 U 矩阵和 V 矩阵
❸ 利用 U 和 V 矩阵的低秩 k 维矩阵来估计
2.1.2 优化思想:
其中 yij 为用户 i 对物品 j 的真实评分,也就是 label,U 和 V 为模型预估值,求解矩阵 U 和 V 的过程就是最小化用户真实评分矩阵和预测矩阵误差的过程。
原始的 SVD 方法有一些问题,最小化过程没有正则化 ( 只有最小方差 ),容易产生过拟合。所以会有很多改进方法。
----------------------------------------------------------------------------------------------------
2.2 矩阵分解
2.2.1 基本思想:
为解决系统过滤中过拟合情况,矩阵分解模型 ( matrix factorization ) 提出的模型如下(引入了 L2 正则来解决过拟合问题)
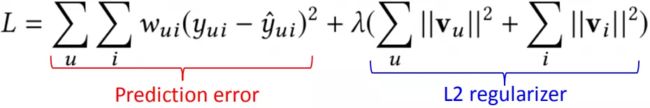
MF 模型的核心思想可以分成两步:
❶ 将用户 u 对物品 i 的打分分解成用户的隐向量 vu,以及物品的隐向量 vi;
❷ 用户 u 和物品 i 的向量点积 ( inner product ) 得到的 value,可以用来代表用户 u 对物品i的喜好程度,分数越高代表该 item 推荐给用户的概率就越大。
关于L2可以做的优化工作有很多,可以参考我之前的文章。
2.2.2 优化思想:
MF 模型可以看成是 user-based 的 CF 模型,直接将用户id映射成隐向量,而 FISM 模型(2014年 KDD 上提出了一种更加能够表达用户信息的方法,Factored Item Similarity Model,就是将用户喜欢过的 item 作为用户的表达来刻画用户)可以看成是 item-based 的 CF 模型,将用户交户过的 item 的集合映射成隐向量。一个是 user id 本身的信息,一个是 user 过去交互过的 item 的信息。而SVD++ 方法正是结合 user-base 和 item-base 这两者本身的优势。

其中,每个用户表达分成两个部分,左边 vu 表示用户 id 映射的隐向量 ( user-based CF 思想 ),右边是用户交互过的 item 集合的求和 ( item-based CF 思想 )。User 和 item 的相似度还是用向量点击来表达。这种融合方法可以看成早期的模型融合方法。
----------------------------------------------------------------------------------------------------
2.3 传统模型升级——因子分解机FM(划重点!)
背景:
1.无论是 CF,MF,SVD,SVD++,还是 FISM,都只是利用了 user 和 item 的交互信息 ( rating data ),而对于大量的 side information 信息没有利用到。例如 user 本身的信息,如年龄,性别、职业;item 本身的 side information,如分类,描述,图文信息;以及 context 上下文信息,如位置,时间,天气等。所以:特征之间是关联的,线性模型中需要人工的特征组合。
2.one-hot编码带来特征空间暴增,数据稀疏,需要的参数量暴增。在数据很稀疏的情况下,满足xi,xj都不为0的情况非常少,这样将导致wij无法通过训练得出。
解决:
1.数据稀疏的情况下,FM可以自动进行特征组合(而SVM无法解决稀疏问题)
2.数据稀疏的情况下表现依然良好。利用矩阵分解的思想,引入辅助V矩阵,对W进行建模
andy:传统算法里面,因子分解机应该是大势所趋。FM算法(Factorization Machine)主要目标是:解决数据稀疏的情况下,特征怎样组合的问题。
----------------------------------------------------------------------------------------------------
2.3.1 基本思想:
andy:普通的线性模型,我们都是将各个特征独立考虑的,并没有考虑到特征与特征之间的相互关系。但实际上,大量的特征之间是有关联的。最简单的以电商为例,一般女性用户看化妆品服装之类的广告比较多,而男性更青睐各种球类装备。那很明显,女性这个特征与化妆品类服装类商品有很大的关联性,男性这个特征与球类装备的关联性更为密切。如果我们能将这些有关联的特征找出来,显然是很有意义的。
一般的线性模型没有考虑特征间的关联。为了表述特征间的相关性,损失函数采用多项式模型。在多项式模型中,特征xi与xj的组合用xixj表示。为了简单起见,具体的模型表达式如下:

p表示样本的特征数量,xi表示第i个特征。与线性模型相比,FM的模型就多了后面特征组合的部分。FM 模型可以看成由两部分组成,蓝色的 LR 线性模型,以及红色部分的二阶特征组合。对于每个输入特征,模型都需要学习一个低维的隐向量表达 v,也就是在各种 NN 网络里所谓的 embedding 表示。
andy:在图中FM中标注的方框矩形在某种意义上可以理解为类似低维的神经网络的embedding层,比纯的神经网络可解释性更好。
----------------------------------------------------------
2.3.1.1 FM(因子分解机)与MF(矩阵分解)的区别
假如只使用 userid 和 itemid(即没有特征组合的部分),我们可以发现其实 FM 退化成只加了 bias 的 MF 模型,如图

数学表达式如下
----------------------------------------------------------------------------------------------------
2.3.1.2 FM(因子分解机)与FISM(分解项目相似性模型)的区别
回顾一下: CF 方法和 MF 方法都只是简单利用了 user-item 的交互信息,FISM,将用户喜欢过的 item 作为用户的表达来刻画用户,注意到用户表达不再是独立的隐向量,而是用用户喜欢过的所有 item 的累加求和得到作为 user 的表达。而 FISM的item 本身的隐向量 vi 是另一套表示,两者最终同样用向量内积表示。损失函数如下:
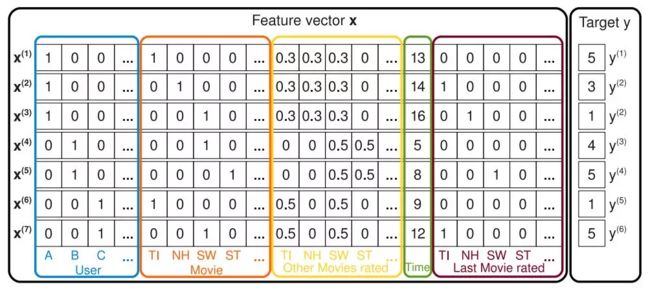
如果输入包含两个变量:1用户交互过的 item 集合和2itemid 本身,那么,此时的 FM 又将退化成只带 bias 的 FISM 模型(即没有特征组合的部分)。
如图所示,蓝色方框表示的是用户历史交互过的 item ( rated movies ),右边橙色方框表示的是 itemid 本身的 one-hot 特征。
----------------------------------------------------------------
2.3.2 优化思想FFM--场感知分解机
背景:one-hot类型变量会导致严重的数据特征稀疏。解决:引入field的概念,同一类经过One-Hot编码生成的特征都可以放到同一个field。
FFM(Field-aware Factorization Machine)模型中引入了类别的概念,即field。andy:说白了,引入了field的概念目的是FFM把相同性质的特征归于同一个field。因此,隐向量不仅与特征相关,也与filed相关。
已一个广告分类的问题为例,根据用户与广告位的一些特征,来预测用户是否会点击广告。数据如下:(本例来自美团技术团队分享的paper)
country,day,ad_type则是对应的特征。对于这种categorical特征,一般都是进行one-hot编码处理。因为是categorical特征,所以经过one-hot编码以后,不可避免的样本的数据就变得很稀疏。举个非常简单的例子,假设淘宝或者京东上的item为100万,如果对item这个维度进行one-hot编码,光这一个维度数据的稀疏度就是百万分之一。
one-hot编码带来的另一个问题是特征空间变大。同样以上面淘宝上的item为例,将item进行one-hot编码以后,样本空间有一个categorical变为了百万维的数值特征,特征空间一下子暴增一百万。所以大厂动不动上亿维度,就是这么来的。为了表述特征间的相关性,FM采用多项式模型。在多项式模型中,特征xi与xj的组合用xixj表示。
在上面的广告点击案例中,“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中(注意!FM是没有的)。同理,Country也可以放到一个field中。简单来说,同一个categorical特征经过One-Hot编码生成的数值特征都可以放到同一个field,包括用户国籍,广告类型,日期等等。在FFM中,每一维特征 xi,针对其它特征的每一种field fj,都会学习一个隐向量 v_i,fj。因此,隐向量不仅与特征相关,也与field相关。也就是说,“Day=26/11/15”这个特征与“Country”特征和“Ad_type"特征进行关联的时候使用不同的隐向量,这与“Country”和“Ad_type”的内在差异相符,也是FFM中“field-aware”的由来。
假设样本的 n个特征属于 f个field,那么FFM的二次项有 nf个隐向量。而在FM模型中,每一维特征的隐向量只有一个。FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。根据FFM的field敏感特性,可以导出其模型方程。
下面以一个例子简单说明FFM的特征组合方式。输入记录如下:
这条记录可以编码成5个特征,其中“Genre=Comedy”和“Genre=Drama”属于同一个field,“Price”是数值型,不用One-Hot编码转换。为了方便说明FFM的样本格式,我们将所有的特征和对应的field映射成整数编号。andy:所有的特征必须转换成“field_id:feat_id:value”格式,field_id代表特征所属field的编号,feat_id是特征编号,value是特征的值.
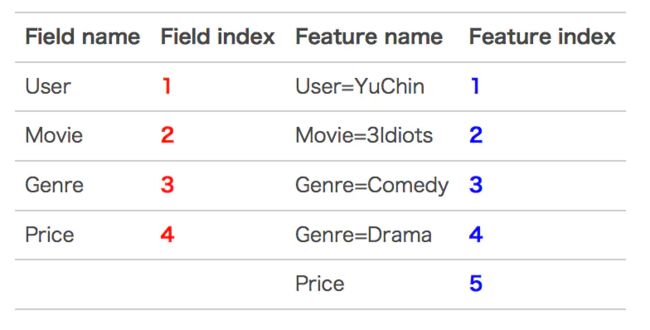
那么,FFM的组合特征有10项,如下图所示。其中,红色是field编号,蓝色是特征feat_id编号。
在FFM论文版本里的梯度更新,学习率是通过类似于adagrad自适应的学习率计算的。根据AdaGrad的特点,对于样本比较稀疏的特征,学习率高于样本比较密集的特征,因此每个参数既可以比较快速达到最优,也不会导致验证误差出现很大的震荡。
------------------------------------------------------
3.区别总结
andy:之所以说FM是传统方法(矩阵分解、协同过滤)最终形式,因为如果再加上 userid 的隐向量表达,那么 FM 模型将退化成 SVD++ 模型。可见 MF,FISM,SVD++ 其实都是 FM 的特例。而一切打分优化的实质:为了缩小实际的推荐系统排序指标的 gap。

用户一般倾向于给自己喜欢的 item 打分,而用户没有打分过的 item 未必就真的是不喜欢。针对推荐系统的排序问题,一般可以用 pairwise (输入空间中样本是(同一 query 对应的)两个 doc(和对应 query)构成的两个特征向量)的 ranking 来替代 RMSE。如下列公式所示,不直接拟合用户对 item 的单个打分,而是以 pair 的形式进行拟合(敲黑板!)。
观察数据的天然偏好bias:一般来说,用户打分高的 item > 用户打分低的 item;用户用过交互的 item > 用户未交互过的 item ( 不一定真的不喜欢 )。
对于传统模型,主要分为基于协同过滤的模型和基于特征的模型,两者最大的不同在于是否使用了 side information。基于协同过滤的模型,如 CF,MF,FISM,SVD++,只用到了用户-物品的交互信息,如 userid, itemid, 以及用户交互过的 item 集合本身来表达。而基于特征的模型以 FM 为例,主要特点是除了用户-物品的交互之外,还引入了更多的 side information。FM 模型是很多其他模型的特例,如 MF,SVD++,FISM 等。
一句话总结优化方法:1.找side info;2.考虑特征间的关联,用适合的模型找特征如何组合;3.调参用pair拟合;
----------------------------------------------------------------------------------------------------
4.参考
(paper的关键字文章已经提及,以下仅罗列分析,括号内为我的标注):
阿里电商推荐中亿级商品的embedding策略(推荐系统中面临的三个问题)https://cloud.tencent.com/developer/article/1442393
深度学习在美团点评推荐平台排序中的运用(有代码)https://www.cnblogs.com/wuxiangli/p/7258474.html
基于神经网络的推荐系统模型(基本模型分析入门)https://blog.csdn.net/qq_14976015/article/details/78986611
KDD 2018best Airbnb文章解读(Embedding)https://zhuanlan.zhihu.com/p/49537461
深度学习的推荐系统(协同深度学习)https://blog.csdn.net/juanjuan1314/article/details/70045762
基于深度学习的推荐系统(Survey)https://blog.csdn.net/qq_14976015/article/details/78986611
FM算法(通俗易懂)https://blog.csdn.net/kingzone_2008/article/details/80541422
Neural Attentive Item Similarity Model算法(FISM升级)
https://www.jianshu.com/p/c695808100c7
https://blog.csdn.net/qq_30516823/article/details/84442961
FISM factored item similarity models for top-N :再次考虑项目的相似模型的Top-N(2013KDD)https://www.docin.com/p-866410834.html
FFM算法实现(带tf的代码实现):https://www.jianshu.com/p/781cde3d5f3d
FM FFM的区别:https://www.cnblogs.com/ljygoodgoodstudydaydayup/p/6340129.html
因子分解机(FM)的代码实现(有ffm和fm以及DeepFM的区别):https://www.jianshu.com/p/f9cb21fa3c21
因子分解机的推倒过程:https://blog.csdn.net/ddydavie/article/details/82667890
因子分解机的具体实现:https://plushunter.github.io/2017/07/13/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AE%97%E6%B3%95%E7%B3%BB%E5%88%97%EF%BC%8826%EF%BC%89%EF%BC%9A%E5%9B%A0%E5%AD%90%E5%88%86%E8%A7%A3%E6%9C%BA%EF%BC%88FM%EF%BC%89%E4%B8%8E%E5%9C%BA%E6%84%9F%E7%9F%A5%E5%88%86%E8%A7%A3%E6%9C%BA%EF%BC%88FFM%EF%BC%89/
RecSys2016 关于fm的paper视频讲解:https://www.bilibili.com/video/av75067871/
以上视频非常详细的代码对照分析:https://blog.csdn.net/qq_40006058/article/details/88656959
FM在电影数据的应用:https://blog.csdn.net/u011984148/article/details/99439481
https://mp.weixin.qq.com/s/LEkTcasLGVayJqFcoS4jPQ