YOLOX讲解
目录
-
- 1、基准模型base line
- 2、Yolox-Darknet53
-
- 2.1 输入端
-
- 2.1.1 strong augmentation
-
- Mosaic增强
- Mixup增强
- 2.2 backbone
- 2.3 Neck
- 2.4 Head层
-
- 2.4.1 Decoupled Head
-
- 2.4.1.1 为什么需要decoupled head
- 2.4.1.2 decoupled head细节
- 2.4.1.2 Anchor-free
- 2.4.1.2 标签分配
-
- (1)初步筛选
- (2)精细化筛选
- 3、Yolox-s、l、m、x系列
类似于YOLOV5,YOLOX同样具有不同的可选配网络,
(1)标准网络结构:Yolox-s、Yolox-m、Yolox-l、Yolox-x、Yolox-Darknet53。
(2)轻量级网络结构:Yolox-Nano、Yolox-Tiny。
在实际的项目中,大家可以根据不同项目需求,进行挑选使用。
1、基准模型base line
在设计算法时,为了对比改进trick的好坏,常常需要选择基准的模型算法。
而在选择Yolox的基准模型时,作者考虑到:
Yolov4和Yolov5系列,从基于锚框的算法角度来说,可能有一些过度优化 ,因此最终选择了Yolov3系列。
不过也并没有直接选择Yolov3系列中标准的Yolov3算法,而是选择添加了spp组件,性能更优的Yolov3_spp版本 。
下面是YOLOV3_spp的网络结构图
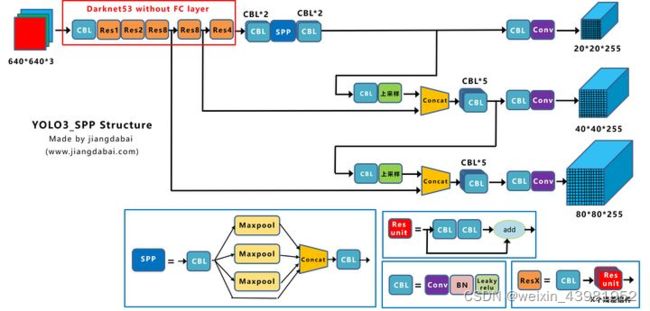
2、Yolox-Darknet53
我们在前面知道,当得到Yolov3 baseline后,作者又添加了一系列的trick,最终改进为Yolox-Darknet53网络结构。
为了便于分析改进点,我们对Yolox-Darknet53网络结构进行拆分,变为四个板块:
① 输入端 :Strong augmentation数据增强
② BackBone主干网络 :主干网络没有什么变化,还是Darknet53。
③ Neck :没有什么变化,Yolov3 baseline的Neck层还是FPN结构。
④ Prediction :Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives。
2.1 输入端
2.1.1 strong augmentation
在网络的输入端,Yolox主要采用了Mosaic、Mixup 两种数据增强方法。
Mosaic增强
Mosaic增强的方式,是U版YOLOv3引入的一种非常有效的增强策略。
而且在Yolov4、Yolov5算法中,也得到了广泛的应用。
通过随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标 的检测效果提升,还是很不错的。
Mixup增强
MixUp是在Mosaic基础上,增加的一种额外的增强策略 。

其实方式很简单,比如我们在做人脸检测 的任务。
先读取一张图片,图像两侧填充,缩放到640*640大小,即Image_1,人脸检测框为红色框。
再随机选取一张图片,图像上下填充,也缩放到640*640大小,即Image_2,人脸检测框为蓝色框。
然后设置一个融合系数,比如上图中,设置为0.5,将Image_1和Image_2,加权融合,最终得到右面的Image。
从右图可以看出,人脸的红色框和蓝色框是叠加存在的。
我们知道,在Mosaic和Mixup的基础上,Yolov3 baseline增加了2.4个百分点。
不过有两点需要注意 :
(1)在训练的最后15个epoch,这两个数据增强会被关闭掉。
而在此之前,Mosaic和Mixup数据增强,都是打开的,这个细节需要注意。
(2)由于采取了更强的数据增强方式,作者在研究中发现,ImageNet预训练将毫无意义, 因此,所有的模型,均是从头开始训练的 。
2.2 backbone
Yolox-Darknet53的Backbone主干网络,和原本的Yolov3 baseline的主干网络都是一样的。都是采用Darknet53 的网络结构。
2.3 Neck
在Neck结构中,Yolox-Darknet53和Yolov3 baseline的Neck结构,也是一样的,都是采用FPN 的结构进行融合。
2.4 Head层
在输出层中,主要从四个方面进行讲解:Decoupled Head、Anchor Free、标签分配、Loss计算 。
2.4.1 Decoupled Head

2.4.1.1 为什么需要decoupled head
论文作者在实验中发现,不单单是精度上 的提高,替换为Decoupled Head后,网络的收敛速度也加快了 。
因此可以得到一个非常关键的结论:
★ 目前Yolo系列使用的检测头,表达能力可能有所欠缺,没有Decoupled Head的表达能力更好。
但是需要注意的是:将检测头解耦,虽然可以加快模型的收敛速度,但同时会增加运算的复杂度。
因此作者经过速度和性能上的权衡,最终使用 1个1x1 的卷积先进行降维,并在后面两个分支里,各使用了 2个3x3 卷积,最终调整到仅仅增加一点点的网络参数。
2.4.1.2 decoupled head细节

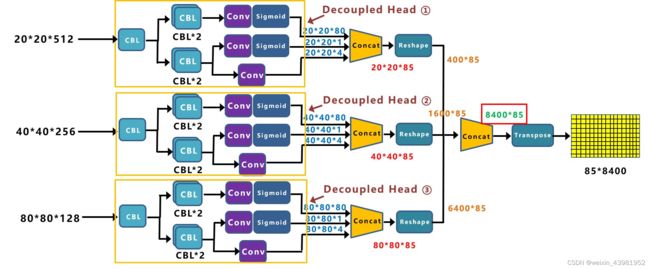
我们将Yolox-Darknet53中,Decoupled Head①提取出来,经过前面的Neck层,这里Decouple Head①输入的长宽为20*20。
从图上可以看出,Concat前总共有三个分支 :
(1)cls_output:主要对目标框的类别,预测分数 。因为COCO数据集总共有80个类别,且主要是N个二分类判断,因此经过Sigmoid激活函数处理后,变为202080大小。
(2)obj_output:主要判断目标框是前景还是背景 ,因此经过Sigmoid处理好,变为20201大小。
(3)reg_output:主要对目标框的坐标信息(x,y,w,h)进行预测 ,因此大小为20204。
最后三个output,经过Concat融合到一起,得到202085的特征信息。
当然,这只是Decoupled Head①的信息,再对Decoupled Head②和③进行处理。
2.4.1.2 Anchor-free
anchor的问题:
①使用anchor时,为了调优模型,需要对数据聚类分析,确定最优锚点,缺乏泛化性。
②anchor机制增加了检测头复杂度,增加了每幅图像预测数量(针对coco数据集,yolov3使用416416图像推理, 会产生3(1313+2626+52*52)*85=5355个预测结果)。
使用ancho-free可以减少调整参数数量,减少涉及的使用技巧,即直接预测bbox
从原有一个特征图预测3组anchor 减少成只预测1组 ,直接预测4个值 (左上角xy坐标和box高宽) 。减少了参数量和GFLOPs,使速度更快,且表现更好。
2.4.1.2 标签分配
当有了8400个Anchor锚框后,这里的每一个锚框,都对应85*8400特征向量中的预测框信息。
不过需要知道,这些预测框只有少部分是正样本,绝大多数是负样本。
这里需要利用锚框和实际目标框的关系,挑选出一部分适合的正样本锚框。
那么在Yolox中,是如何挑选正样本锚框的呢?
这里就涉及到两个关键步骤:初步筛选、SimOTA 。
(1)初步筛选
初步筛选的方式主要有两种:根据中心点来判断、根据目标框来判断 ;
- a 根据中心点判断 :寻找anchor_box中心点,落在groundtruth_boxes矩形范围的所有anchors,即为正样本
- b 根据目标框来判断 :以groundtruth中心点为基准,设置边长为5的正方形,挑选在正方形内的所有锚框。
(2)精细化筛选
我们知道有8400个锚框,但是经过初步筛选后,假定有1000个锚框是正样本锚框。
SimOTA 进行精细化筛选
3、Yolox-s、l、m、x系列
在对Yolov3 baseline进行不断优化,获得不错效果的基础上。
作者又对Yolov5系列,比如Yolov5s、Yolov5m、Yolov5l、Yolov5x四个网络结构,也使用一系列trick进行改进。
先来看一下,改进了哪些地方?
我们主要对Yolov5s进行对比,下图是Yolov5s的网络结构图:
这里对yolov5的改进与yolov3_spp的改进类似
我们再看一下Yolox-s的网络结构:
由上面两张图的对比,及前面的内容可以看出,Yolov5s和Yolox-s主要区别在于:
(1)输入端:在Mosa数据增强的基础上,增加了Mixup数据增强效果;
(2)Backbone:激活函数采用SiLU函数;
(3)Neck:激活函数采用SiLU函数;
(4)输出端:检测头改为Decoupled Head、采用anchor free、multi positives、SimOTA的方式。
在前面Yolov3 baseline的基础上,以上的tricks,取得了很不错的涨点。