YOLOX 阅读笔记
注:此文为阅读笔记,参考了很多论文,博客,如有侵权请联系,我附上原出处。
文章大部分内容主要来自以下博客:
睿智的目标检测53——Pytorch搭建YoloX目标检测平台
YOLOX深度解析
文章目录
- YOLO X
- 创新点
- 网络架构
-
- Backbone
- Neck
- Head
- Strong data augmentation
- Anchor-free
- Multi positives 正样本
-
- SimOTA
- 损失函数
- 实验效果
YOLO X
论文:https://arxiv.org/pdf/2107.08430.pdf
github地址:https://github.com/Megvii-BaseDetection/YOLOX
其他大佬自己实现博客:https://blog.csdn.net/weixin_44791964/article/details/120476949?spm=1001.2014.3001.5501
创新点
1、主干部分:使用了Focus网络结构,这个结构是在YoloV5里面使用到比较有趣的网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。
2、分类回归层:Decoupled Head,以前版本的Yolo所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现,YoloX认为这给网络的识别带来了不利影响。在YoloX中,Yolo Head被分为了两部分,分别实现,最后预测的时候才整合在一起。
3、数据增强:Mosaic数据增强。
4、Anchor Free:不使用先验框。
5、SimOTA :为不同大小的目标动态匹配正样本。
原论文作者认为,然而,在过去的两年中,目标检测学术界的主要进展集中在anchor-free detectors、dvanced label assignment strategies(高级标签分配)和end-to-end(NMS-free) detectors。这些新技术还没有集成到YOLO系列中,如YOLO V4和YOLO V5。
并且原论文作者可能考虑到YOLO V4和YOLO V5用到许多tricks对anchor-based detectors进行优化,而且不好直接在其基础上进行进一步改进,故选择YOLO V3 作为起点( set YOLOv3-SPP as the default YOLOv3).
并且
1、代码已开源。
2、源码提供了ONNX, TensorRT, NCNN, and Openvino版本,相信能减少很多部署所需要的时间,对工业界相当友好,相信很快就能应用于工业界。
网络架构
Backbone
DarkNet53
相比原始的YOLOv3,本论文的YOLOv3 baseline对训练策略做了如下改动:
1.加入EMA权重更新
2.加入cosine lr schedule
3.加入IoU loss
4.加入IoU-aware branch
CSPDarknet
此外,YOLOX中还有以YOLO V5的CSPDarknet做为Backbone进行分析
具体可以参考博客:睿智的目标检测53——Pytorch搭建YoloX目标检测平台
此大佬有给出详细的网络结构图及代码复现

1、使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;残差边部分不做任何处理,直接将主干的输入与输出结合。
残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。

2、使用CSPnet网络结构,CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;另一部分则像一个残差边一样,经过少量处理直接连接到最后。因此
可以认为CSP中存在一个大的残差边。
3、使用了Focus网络结构,这个网络结构是在YoloV5里面使用到的网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道。

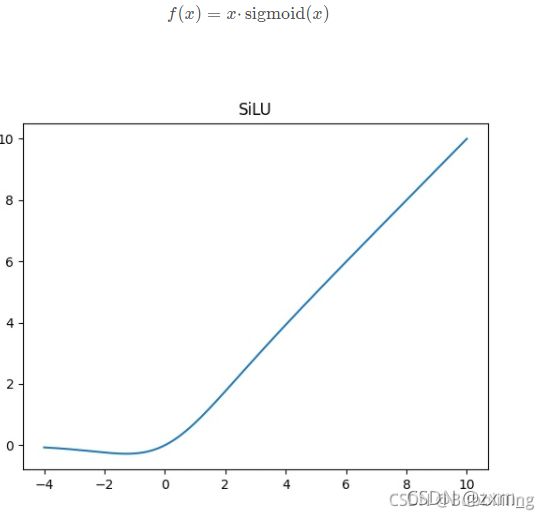
4、使用了SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。
Neck
SPP
使用了SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。在YoloV4中,SPP是用在FPN里面的,在YoloX中,SPP模块被用在了主干特征提取网络中。
YoloX提取多特征层进行目标检测,一共提取三个特征层(类似FPN,具体可以看我上一篇博客)
Head
Decoupled head
YoloX中的YoloHead与之前版本的YoloHead不同。
以前版本的Yolo所用的Head是(Cls、Reg、Obj)一起的,也就是分类和回归在一个1X1卷积里实现,认为这给网络的识别带来了不利影响。
YOLO X实验发现这给网络的识别带来了不利影响。故进行两点改进:
①将预测分支解耦极大的改善收敛速度。在YoloX中,Yolo Head被分为了两部分,分别实现,最后预测的时候才整合在一起。
②相比较于非解耦的端到端方式,解耦能带来 4.2% AP提升。


对于每一个特征层,我们可以获得三个预测结果,分别是:
1、Reg(h,w,4)用于判断每一个特征点的回归参数-目标框的坐标信息(x,y,w,h),回归参数调整后可以获得预测框。
2、Obj(h,w,1)用于判断每一个特征点是否包含物体(即判断目标框是前景还是背景)。
3、Cls(h,w,num_classes)用于判断每一个特征点所包含的物体种类。
将三个预测结果进行堆叠Concat,每个特征层获得的结果为:Out(h,w,4+1+num_classses)
前四个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框;
第五个参数用于判断每一个特征点是否包含物体;
最后num_classes个参数用于判断每一个特征点所包含的物体种类。
Strong data augmentation
使用Mosaic和MixUp技术
可以看我上一篇博客传送门,原理差不多。
Anchor-free
目前,有一些工作表明,anchor-free detectors的性能可以与anchor-based detectors相当。
anchor的问题:
参考博客:https://zhuanlan.zhihu.com/p/392221567
①使用anchor时,为了调优模型,需要对数据聚类分析,确定最优锚点,缺乏泛化性。
②anchor机制增加了Head复杂度,增加了每幅图像预测数量(针对coco数据集,yolov3使用416 * 416图像推理, 会产生3 * (13 * 13+26 * 26+52 * 52)* 85=5355个预测结果)。
使用ancho-freer可以减少调整参数数量,减少涉及的使用技巧
将YOLO 转化成 anchor-free manner
从原有一个特征图预测3组anchor减少成只预测1组,直接预测4个值(左上角xy坐标和box高宽)。减少了参数量和GFLOPs(每秒10亿次的浮点运算数),使速度更快,且表现更好。
作者在正样本选择方式做过以下几个尝试:
①只将物体中心点所在的位置认为是正样本,一个gt最多只会有一个正样本。AP达到42.9%。
②Multi positives。直接将中心3 * 3区域都认为是正样本,即从上述策略每个gt有1个正样本增长到9个正样本。且AP提升到45%,已经超越U版yolov3的44.3%AP。
③SimOTA
Multi positives 正样本
在YoloX中,物体的真实框落在哪些特征点内就由该特征点来预测。
对于每一个真实框,我们会求取所有特征点与它的空间位置情况。作为正样本的特征点需要满足以下几个特点:
1、特征点落在物体的真实框内。
2、特征点距离物体中心尽量要在一定半径内。
特点1、2保证了属于正样本的特征点会落在物体真实框内部,特征点中心与物体真实框中心要相近。
上面两个条件仅用作正样本的而初步筛选,在YoloX中,我们使用了SimOTA方法进行动态的正样本数量分配。
SimOTA
OTA(Optimal Transport Assignment)
在目标检测中,有时候经常会出现一些模棱两可的anchor。
如下图,即某一个anchor,按照正样本匹配规则,会匹配到两个gt,Retinanet这样基于IoU分配是会把anchor分配给IoU最大的gt。
而OTA作者认为,将模糊的anchor分配给任何gt或背景都会对其他gt的梯度造成不利影响。
因此,对模糊anchor样本的分配是特殊的,除了局部视图之外还需要其他信息。因此,更好的分配策略应该摆脱对每个gt对象进行最优分配的惯例,而转向全局最优的思想,换句话说,为图像中的所有gt对象找到全局的高置信度分配。(和DeTR中使用使用匈牙利算法一对一分配有点类似)

下面讲述下SimOTA。首先看一个公式:

SimOTA不仅减少训练时间,而且避免额外的参数。
SimOTA将AP从45.0%提升到47.3%。
在YoloX中,我们会计算一个Cost代价矩阵,代表每个真实框和每个特征点之间的代价关系,Cost代价矩阵由三个部分组成:
1、每个真实框和当前特征点预测框的重合程度;
2、每个真实框和当前特征点预测框的种类预测准确度;
3、每个真实框的中心是否落在了特征点的一定半径内。
每个真实框和当前特征点预测框的重合程度越高,代表这个特征点已经尝试去拟合该真实框了,因此它的Cost代价就会越小。
每个真实框和当前特征点预测框的种类预测准确度越高,也代表这个特征点已经尝试去拟合该真实框了,因此它的Cost代价就会越小。
每个真实框的中心如果落在了特征点的一定半径内,代表这个特征点应该去拟合该真实框,因此它的Cost代价就会越小。
Cost代价矩阵的目的是自适应的找到当前特征点应该去拟合的真实框,重合度越高越需要拟合,分类越准越需要拟合,在一定半径内越需要拟合。
在SimOTA中,不同目标设定不同的正样本数量(dynamic_k),以旷视科技官方回答中的蚂蚁和西瓜为例子,传统的正样本分配方案常常为同一场景下的西瓜和蚂蚁分配同样的正样本数,那要么蚂蚁有很多低质量的正样本,要么西瓜仅仅只有一两个正样本。对于哪个分配方式都是不合适的。
动态的正样本设置的关键在于如何确定k,SimOTA具体的做法是首先计算每个目标Cost最低的10个特征点,然后把这10个特征点对应的(预测框与真实框的) IOU 加起来求得最终的k。
因此,SimOTA的过程总结如下:
1、计算每个真实框和当前特征点预测框的重合程度。
2、计算将重合度最高的十个预测框与真实框的IOU加起来求得每个真实框的k,也就代表每个真实框有k个特征点与之对应。
3、计算每个真实框和当前特征点预测框的种类预测准确度。
4、判断真实框的中心是否落在了特征点的一定半径内。
5、计算Cost代价矩阵。
6、将Cost最低的k个点作为该真实框的正样本。

SimOTA的详细解析也可参考博客:YOLOX深度解析(二)-simOTA详解
损失函数
YoloX的损失由三个部分组成:
1、Reg部分,由第三部分可知道每个真实框对应的特征点,获取到每个框对应的特征点后,取出该特征点的预测框,利用真实框和预测框计算IOU损失,作为Reg部分的Loss组成。
2、Obj部分,由第三部分可知道每个真实框对应的特征点,所有真实框对应的特征点都是正样本,剩余的特征点均为负样本,根据正负样本和特征点的是否包含物体的预测结果计算交叉熵损失,作为Obj部分的Loss组成。
3、Cls部分,由第三部分可知道每个真实框对应的特征点,获取到每个框对应的特征点后,取出该特征点的种类预测结果,根据真实框的种类和特征点的种类预测结果计算交叉熵损失,作为Cls部分的Loss组成。
实验效果
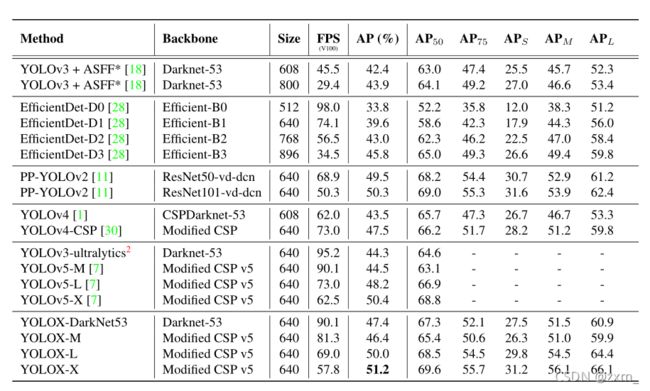
为了公平比较,选择了300次迭代训练的所有模型。比较了COCO 2017测试开发中不同目标探测器的速度和精度。
(1)Yolox-Nano
Yolox-Nano是Yolox系列最小的结构,网络参数只有0.91M。
(2)Yolox-Tiny
(3)Yolox-Darknet53
Yolox-Darknet53是在Yolov3的基础上,进行的改进,也是后面主要介绍的网络结构。
(4)Yolox-s
Yolox-s是在Yolov5-s的基础上,进行的改进,也是后面主要介绍的网络结构。
(5)Yolox-m
(6)Yolox-l
(7)Yolox-x
depth_dict = {'nano': 0.33, 'tiny': 0.33, 's' : 0.33, 'm' : 0.67, 'l' : 1.00, 'x' : 1.33,}
width_dict = {'nano': 0.25, 'tiny': 0.375, 's' : 0.50, 'm' : 0.75, 'l' : 1.00, 'x' : 1.25,}