Jeff Dean | 回顾2021:除了超大的AI模型,谷歌还有啥?
来源:新智元
作者:Jeff Dean 谷歌AI掌门人
新年伊始,谷歌AI掌门人Jeff Dean的年度总结「虽迟但到」,这篇万字长文系统回顾了过去一年来机器学习领域的五大趋势。除了超大AI模型,谷歌去年还做了啥?
2021年,谷歌在机器学习领域可谓是十分高产。毕竟,这帮人在NeurIPS 2021上就投了177篇论文。
1月11日,Jeff Dean终于用一篇万字长文完成了总结。

趋势 1:功能更强大、
通用的机器学习模型
研究人员正在训练出比以往任何时候更大、功能更强大的机器学习模型。近几年,语言领域的模型规模迅速增长,参数数量从百亿级(例如110亿参数的T5模型)发展到现在的数千亿级(如 OpenAI 的 1750亿参数的GPT-3模型和 DeepMind 的 2800亿参数的Gopher模型。在稀疏模型方面,如Google的GShard模型参数为6000亿,GLaM模型参数更是达到了1.2万亿)。
数据集和模型规模的扩大,使得各种语言任务的准确性显著提高,标准自然语言处理 (NLP)基准任务性能获得全面改进。
这些高级模型中,很大一部分模型专注于书面语言的单一但重要的模态,并在语言理解基准和开放式会话能力方面达到了最先进的结果。此外,这些模型可以在训练数据相对较少的情况下泛化到新的语言任务中,有时甚至不需要新的训练样本。比如Google的的LaMDA模型就可以进行开放式对话,并在多轮对话中保留重要的上下文语境信息。
用于图像识别和视频分类的Transformer在许多基准测试中取得了SOTA。与单独的视频数据相比,在图像数据和视频数据上共同训练模型可以提高视频任务的性能。
我们为图像和视频Transformer开发了稀疏的轴向注意力机制,为视觉Transformer模型找到了更好的标记图像的方法,并通过研究视觉Transformer方法与卷积神经网络相比如何运作,提高了对视觉Transformer的理解。Transformer与卷积操作的结合,在视觉以及语音识别任务中均表现出明显优势。
生成式模型的输出也在大幅提高。尤其是图像生成模型。最近的模型已经具备这样的能力:只给定一个类别的逼真图像,模型就可以对低分辨率的图像进行「填充」,生成自然的高分辨率对应图像,甚至可以生成自然的任意尺度的自然场景。图像甚至可以被转换为一串离散的标记,然后用自回归生成模型实现高精度合成。
除了先进的单模态模型外,大规模的多模态模型开始兴起。它们可以接受多种不同的输入模式(语言、图像、语音、视频),并且在某些情况下产生不同的输出模式,比如从描述性句子或段落生成图像, 或用人类语言描述图像的内容。

基于自然文本描述生成的图像
与现实世界一样,在多模态数据中有些东西更容易学习。因此,将图像和文本配对可以帮助完成多语言检索任务,以及更好地理解如何将文本和图像输入配对,可以为图像字幕任务带来更好的结果。同样,对视觉和文本数据的联合训练也有助于提高视觉分类任务的准确性和鲁棒性,而对图像、视频和音频任务的联合训练可以提高所有模态的泛化性能。
基于视觉的机器人操作系统示例,可以完成从「将葡萄放进碗」到「将瓶子放进托盘」的任务泛化
这些模型一般都是使用自监督学习方法训练的。自监督学习允许大型语音识别模型以匹配之前的语音搜索自动语音识别(ASR)基准准确度,同时仅使用 3% 的带注释训练数据。这可以大大减少为特定任务启用机器学习所需的工作量,并使在更具代表性的数据上训练模型变得更容易。
所有这些趋势都指向训练功能强大的通用模型的方向,这些模型可以处理多种数据模式并解决数千或数百万个任务。通过构建稀疏性,以便为给定任务激活的模型的唯一部分是那些已经为其优化的部分,这些多模态模型可以变得高效。
在接下来的几年中,我们将在称为Pathways的下一代架构和总体努力中追求这一愿景,并有望望在这一领域看到实质性进展。
趋势 2:机器学习模型效率持续提升
计算机硬件设计、机器学习算法和元学习研究的进步推动机器学习模型的效率和性能提升。过去一年里,机器学习模型从训练和硬件、到架构的各个组件,都实现了效率的不断优化,同时保持整体性能不降低,甚至提升,大大降低了计算成本,提升了效率。
机器学习加速器性能持续提升
每一代机器学习加速器都在前几代的基础上实现性能提升,去年,谷歌发布了TPUv4 系统,这是谷歌的第四代张量处理器,比 TPUv3 的性能测试结果提高了2.7 倍。

每个 TPUv4 芯片的峰值性能是 TPUv3 芯片的约 2 倍,每个 TPUv4 pod 的规模为 4096 个芯片(是 TPUv3 pod 的 4 倍),每个 pod 的性能约为 1.1 exaflops。拥有大量芯片并通过高速网络连接在一起的 Pod 可以提高大型模型的效率。移动设备上的机器学习能力也在大幅提升。Pixel 6 手机采用全新的Google Tensor 处理器,该处理器集成了强大的机器学习加速器,以更好地支持重要的设备端功能。
机器学习编译和负载优化性能持续提升
即使硬件不变,编译器的改进和机器学习加速器系统软件的其他优化也可以大大提高效率。
《A Flexible Approach to Autotuning Multi-pass Machine Learning Compilers》 展示了如何使用机器学习来执行编译设置的自动调整,以获得 5-15% 的全面性能提升(有时甚至高达2.4 倍改进)用于同一底层硬件上的一套机器学习程序。
在上个月谷歌的题为《神经网络的通用和可扩展并行化》的博客中,描述了一种基于XLA 编译器的自动并行化系统,该系统能够将大多数深度学习网络架构扩展到加速器的内存容量之外,并已应用于许多大型模型,例如GShard-M4、LaMDA、BigSSL、ViT、MetNet-2和GLaM,在多个领域实现了SOTA。

通过在 150 个 ML 模型上使用基于 ML 的编译器自动调整实现端到端模型的加速
人类驱动的更高效模型架构的发现
模型架构的持续改进大大减少了为许多问题实现给定精度水平所需的计算量。Transformer架构能够提高几多个 NLP 和翻译基准的最新技术水平,大大降低计算量,同样,尽管使用的计算量比卷积神经网络少 4 到 10 倍,但Vision Transformer能够在许多不同的图像分类任务上实现最先进的结果。
机器驱动的更高效模型架构的发现
神经架构搜索(NAS)可以自动发现对给定问题更有效的新机器学习架构。
NAS 的一个主要优点是可以大大减少算法开发所需的工作量,因为它只需要每个搜索空间和问题域组合的一次性工作量。此外,虽然执行 NAS 的初始工作在计算上可能很昂贵,但由此产生的模型可以大大减少下游研究和生产设置中的计算,从而大大降低总体资源需求。

最近发现了一种更高效的NAS架构,称为Primer(也已开源),与普通的 Transformer 模型相比,它可以将训练成本降低75%。
NAS 还被用于在视觉领域发现更高效的模型。EfficientNetV2模型架构是一个神经结构的搜索,对模型的准确性,模型的大小,并且训练速度联合优化的结果。
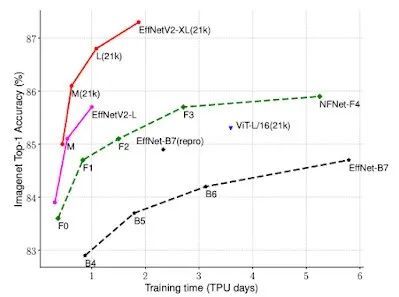
在 ImageNet 基准测试中,EfficientNetV2 将训练速度提高了 5 到 11 倍,同时比以前的最先进模型显著减小了模型大小。
使用稀疏性
稀疏性,即模型具有非常大的容量,但对于给定的任务、示例或令牌,只有模型的某些部分被激活,这是又一个可以明显提高效率的算法进步。
2017 年,我们引入了稀疏门控混合专家层,该层在各种翻译基准上展示了更好的结果,同时计算量比以前最先进的密集 LSTM 模型下降了90%。
最近,Switch Transformers实现了将混合专家风格的架构与 Transformer 模型架构的结合,与密集的T5-Base Transformer 模型相比,训练效率提高了 7 倍。GLaM模型将转换器和混合专家风格的层结合起来,在 29 个基准测试中平均超过 GPT-3 模型的准确性,而训练所需的能量减少了三分之二,推理计算量减少了一半。
稀疏性的概念也可以用于降低核心 Transformer 架构中注意力机制的成本。

在模型中利用稀疏性,是一种在计算效率方面具有非常高的潜在回报的方法,目前我们在这个方向上的尝试才刚刚开始。
趋势 3:机器学习造福个人和社区
随着机器学习模型、算法和硬件的创新,移动设备已经能够持续有效地感知周围的环境。这些技术进步提高了机器学习技术的可用性和易用性,也提高了算力。这对于手机拍照、实时翻译等流行功能至关重要。同时,用户也能获得更加个性化的体验,并加强了隐私保护。
现在,人们比以往任何时候都依靠手机摄像头来记录日常生活。机器学习技术不断提升手机摄像头的功能,拍出更高质量的图像。
比如 HDR+、提升在极弱光下拍照的能力、更好地处理人像,拍摄出更符合摄影师视觉的照片。Google Photos 现在提供的基于机器学习的强大工具进一步改进拍摄品质。

HDR+ 可以将多张曝光不足的原始图像进行合并,合并后的图像减少了噪点并增加了动态范围,获得更高质量的最终图像(右)
手机除了拍照之外,还是重要的实时沟通工具,用户可以使用实时翻译和实时字幕进行电话通话。由于自监督学习等技术的进步,语音识别的准确性不断提高,对于重音、嘈杂的条件或重叠语音的环境以及多种语言都有明显改善。

由于文本—语音合成技术的进步,信息能够更容易跨越形式和不同语言的障碍。在 Lyra 语音编解码器和更通用化的 SoundStream 音频编解码器中,研究人员将机器学习与传统编解码器方法相结合,能够可靠地传达更高保真度的语音、音乐和其他声音。
Duplex 技术的进步,让自动呼叫筛选等功能更加强大,日常交互变得更自然。即使是用户可能经常执行的简短任务,也已通过智能文本选择等工具得到改进。该工具会自动选择电话号码或地址等实体,便于复制粘贴。

最近的研究表明,用户是否「凝视」屏幕,是衡量精神疲劳的重要生物标志物。
Screen Attention机制可防止手机屏幕在用户注视时变暗。机器学习技术还支持了更多确保人员和社区安全的新方式,比如对可能的网络钓鱼攻击的警报、更安全的路由检测手段等。
鉴于这些新功能背后的数据具有潜在的敏感性,因此必须将它们默认设计为私有的。它们中的许多都在Android的私有计算核心内运行——这是一个与操作系统的其余部分隔离的开源安全环境。
Android确保在私有计算核心中处理的数据不会在用户未采取操作的情况下共享给任何应用程序,还要阻止私有计算核心内的任何功能直接访问网络。研究人员利用包括联邦学习在内的隐私技术,联合分析和私人信息检索,在确保隐私的同时实现学习。
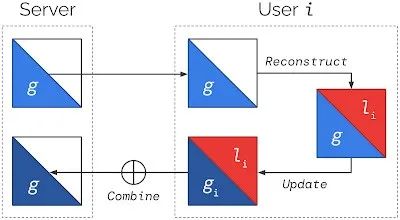
「联邦重建」是一种局部联邦学习新技术
这些技术对于发展下一代计算和交互范式至关重要,个人或公共设备可以在不损害隐私的情况下学习并有助于训练世界的集体模型。
过去一段时间里,机器学习系统的交互变得更加直观,更像是一个社交实体而不是机器。只有对目前的技术堆栈(从边缘到数据中心)进行深度变革,才能广泛而公平地访问这些智能接口,更好地支持神经计算。
趋势 4:机器学习在科学、
健康和可持续发展方面的进步
近年来,机器学习在基础科学领域的影响越来越大,从物理学到生物学,甚至是医学。
随着ML变得更加强大和完善,它在现实世界中的应用范围和影响力也将持续扩大,为解决一些最具挑战性的问题提供帮助。
大规模的计算机视觉应用
过去十年来,计算机视觉的进步使计算机能够被用于不同科学领域的各种任务。在神经科学领域,自动重建技术可以从高分辨率的脑组织薄片的电子显微镜图像中恢复脑组织的神经连接结构。去年,谷歌与哈佛大学的Lichtman实验室合作,分析了脑组织样本,并制作了人类大脑皮层中突触连接的第一个大规模研究,跨越了大脑皮层各层的多种细胞类型。这项工作的目标是产生一种新的资源,以协助神经科学家研究人类大脑惊人的复杂性。

一个成年人类大脑中大约860亿个神经元中的6个神经元
另外,谷歌提出了一种基于深度学习的天气预报方法。使用卫星和雷达图像作为输入,并结合其他大气数据,从而让产生的天气和降水预报比传统的基于物理学的模型更准确,预报时间长达12小时。不仅如此,机器学习还可以比传统方法更快地产生更新的预测,这在极端天气的时候可能是至关重要的。

2020年3月30日科罗拉多州丹佛上空0.2毫米/小时降水的比较(左:来自MRMS的基准真相;中:由MetNet-2预测的概率图;右:基于物理学的HREF模型预测的概率图。)
MetNet-2能够在预测中比HREF更早地预测风暴的开始,以及风暴的起始位置,而HREF错过了起始位置,但很好地捕捉了它的增长阶段。将计算机视觉技术应用于卫星图像可以帮助识别大陆范围内的建筑边界,进而提供自然灾害后的快速损害评估。
目前,谷歌已经在「开放建筑」数据集中开源,其中包含了5.16亿栋建筑的位置和足迹,覆盖了非洲大陆的大部分地区。

卫星图像中建筑物的分割实例(左:原始图像;中:语义分割,每个像素都有一个置信度分数,即它是建筑物还是非建筑物;右图:实例分割,通过阈值处理和将相连的组件组合在一起获得。)
这些案例中的一个共同主题是,ML模型能够在分析现有视觉数据的基础上高效、准确地执行专门任务,支持高影响的下游任务。
自动设计空间探索
让ML算法以自动化的方式探索和评估一个问题的设计空间,也在许多领域产生了出色结果。
比如,一个基于Transformer的自动编码器学会了创建美观并实用的文档布局,同样的方法可以扩展到家具装修的布局探索上。

变量Transformer网络(VTN)模型,能够提取布局元素之间的有意义的关系,以生成现实的合成文件
或者是让机器学习自己去探索计算机游戏的规则,通过调整设计来提高游戏的可玩性,帮助人类游戏设计师能够更快地创建优秀的游戏。
此外,谷歌还将ML用于快速创建ASIC芯片的设计布局,不仅将时间从几周缩短到几小时,而且甚至比人类专家给出的结果更好。在即将推出的TPU-v5芯片的设计中,就利用了这种自动布局方法。
在健康方面的应用
除了推动基础科学的发展,ML还可以更广泛地推动医学和人类健康的进步。以基因组学领域为例,计算从一开始就对基因组学很重要,但ML增加了新的能力并颠覆了旧的模式。
对于新开发的测序仪,它们更准确、更快速,但也带来新的推断挑战。谷歌发布的开源软件DeepConsensus以及与UCSC合作的PEPPER-DeepVariant,用最先进的信息学支持这些新仪器。
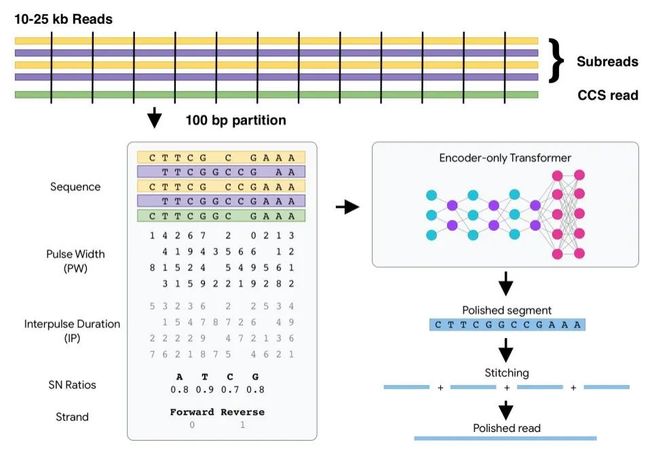
DeepConsensus的Transformer架构示意图,它可以纠正测序的错误
在处理测序仪数据之外,由广泛的表型和测序个体组成的大型生物库可以彻底改变理解和管理疾病遗传倾向的方式。其中,谷歌提出的DeepNull方法更好地利用大型表型数据进行遗传发现。

生成大规模的解剖学和疾病特征量化的过程,以便与生物库中的基因组数据相结合
正如ML可以看到基因组学数据的隐藏特征一样,它也可以从其他健康数据类型中发现新的信息和见解。疾病的诊断往往是关于识别一个模式,量化一个相关性,或识别一个更大类别的新实例,而这些都是ML擅长的任务。
ML辅助的结肠镜检查程序就是一个特别有趣的例子。在这一领域,谷歌证明了ML可以帮助检测难以捉摸的息肉。在与耶路撒冷Shaare Zedek医疗中心的合作中,平均每次手术可以检测到一个本来会被遗漏的息肉,使每次手术的错误警报少于4次。
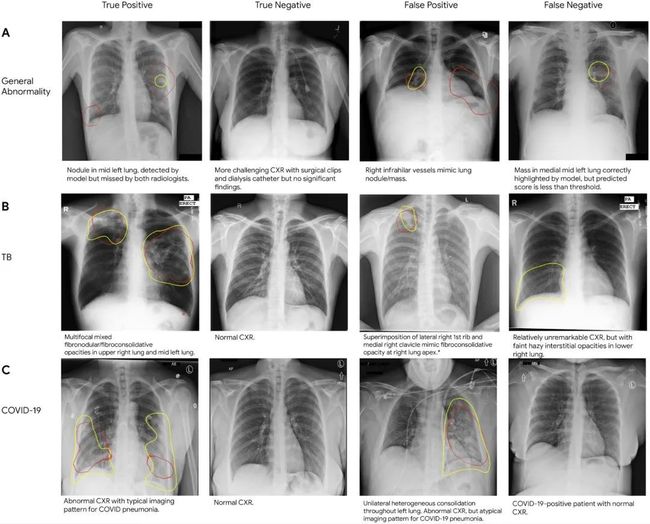
A:一般异常情况;B:结核病;
C:COVID-19的真阳性,真阴性,假阳性,假阴性的胸部X光片样本。
在每张CXR上,红色的轮廓表示模型集中识别异常的区域,黄色的轮廓指的是由放射科医生识别的区域。另一个雄心勃勃的医疗保健计划,Care Studio,使用最先进的ML和先进的NLP技术来分析结构化数据和医疗笔记,在正确的时间向临床医生提供最相关的信息。

此外,现在谷歌也将ML的应用集成到智能手机当中。
例如手机摄像头评估心率和呼吸率,在不需要额外硬件的情况下,让用户更好地了解夜间的健康状况。
用于非接触式睡眠传感的定制ML模型自动计算用户存在的可能性和清醒状态(醒着或睡着)的概率
趋势 5:对机器学习更深更广的理解
随着ML在技术产品和社会中被更广泛地使用,研究人员必须确保技术的公平和公正,并且使其能够惠及到所有人。其中一个重点领域是基于用户在在线产品中活动的推荐系统。
由于这些推荐系统通常由多个不同的组件组成,理解它们的公平性往往需要对单个组件以及单个组件在组合在一起时的行为进行观察。
此外,当从隐含的用户活动中学习时,推荐系统以无偏见的方式学习也很重要。因为从以前的用户所展示的项目中学习的直接方法表现出众所周知的偏见。

https://research.google/pubs/pub49284/
与推荐系统一样,背景知识在机器翻译中也很重要。因为大多数机器翻译系统都是孤立地翻译单个句子,从而让与性别、年龄或其他领域有关的偏见进一步加强。
去年谷歌发布了一个数据集,以研究基于维基百科传记的翻译中的性别偏见。

https://storage.googleapis.com/gresearch/translate-gender-challenge-sets/Readme.html
部署机器学习模型的另一个常见问题是分布性转变:如果模型所训练的数据的统计分布与模型作为输入的数据的统计分布不一样,那么模型的行为有时会无法预测。
对此,谷歌采用了Deep Bootstrap框架来比较一个模型在现实世界和「理想世界」中的表现,前者有有限的训练数据,后者有无限的数据。由此可以帮助开发出能更好地概括新环境的模型,并减少对固定训练数据集的偏见。

https://arxiv.org/pdf/2010.08127.pdf
尽管关于ML算法和模型开发的工作得到了极大的关注,但数据收集和数据集的策划往往得到的关注较少。
这是一个重要的领域,因为训练ML模型的数据可能是下游应用中偏见和公平问题的潜在来源。而分析ML中的这种数据级联可以帮助评估整改项目的生命周期,从而对结果产生实质性影响。

不同颜色的箭头表示各种类型的数据级联,
每一种级联通常起源于上游,在ML开发过程中复合,并体现在下游
更好地理解数据的总体目标是ML研究的一个重要部分。因为错误标记的数据或其他类似的问题会对整个模型行为产生巨大的影响。
谷歌为此建立了「了解你的数据」(Know Your Data)工具,以帮助ML研究人员和从业人员更好地了解他们的数据集的属性。
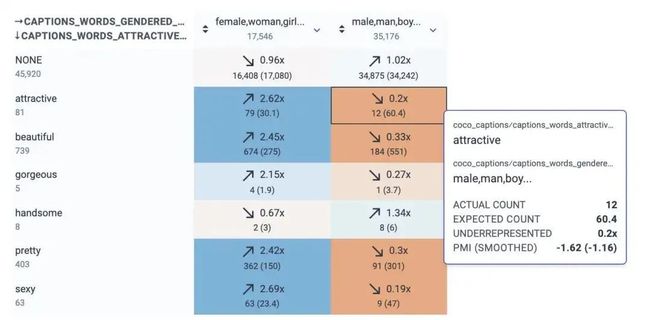
Know Your Data显示了描述吸引力的词和性别之间的关系
同样,了解基准数据集的使用动态也很重要,因为它们在ML作为一个领域的组织中发挥着核心作用。尽管对单个数据集的研究已经越来越普遍,但对整个领域的数据集使用动态的研究仍然没有得到充分探索。
因此谷歌发表了第一个关于数据集创建、采用和重用动态的大规模经验分析。这项工作为实现更严格的评估,以及更公平和社会化的研究提供了深入的见解。

https://arxiv.org/pdf/2112.01716.pdf
创建更具包容性和更少偏见的公共数据集是帮助为每个人改善ML领域的一个重要途径。
2016年,谷歌发布了开放图像数据集,这是一个约900万张图像的集合,其中有横跨数千个对象类别的图像标签和600个类别的注释。去年,谷歌在Open Images Extended集合中引入了More Inclusive Annotations for People(MIAP)数据集。该集合中每个注解都标有公平性相关的属性,包括感知的性别和年龄范围。

https://storage.googleapis.com/openimages/web/extended.html
解决网上各种形式的滥用行为,如有毒语言、仇恨言论和错误信息,是谷歌的一个核心优先事项。
能够可靠、高效、大规模地检测出这些形式的滥用行为,对于确保我们的平台安全,以及避免通过语言技术以无监督的方式从在线话语中学习到这些负面特征的风险,都是至关重要的。
谷歌通过Perspective API工具开创了这一领域的工作,但大规模的检测所涉及的细微差别仍然是一个复杂的问题。

https://www.perspectiveapi.com/case-studies/
在最近的工作中,谷歌与不同的学术伙伴合作,引入了一个全面的分类法来推理网络仇恨和骚扰的变化情况。
此外,通过定性研究和网络层面的内容分析,谷歌的Jigsaw团队与乔治华盛顿大学的研究人员合作,研究了虚假信息是如何在社交媒体平台上传播的。

https://medium.com/jigsaw/hate-clusters-spread-disinformation-across-social-media-995196515ca5
另一个潜在的担忧是,ML语言理解和生成模型有时也会产生没有适当证据支持的结果。为了解决问题回答、总结和对话中的这个问题,谷歌开发了一个新的框架来衡量结果是否可以归于特定的来源。

https://arxiv.org/pdf/2112.12870.pdf
模型的互动分析和调试仍然是负责任地使用ML的关键。
谷歌利用新的能力和技术更新了语言可解释性工具,包括对图像和表格数据的支持,从之前What-If工具中延续下来的各种功能,以及通过用概念激活矢量测试技术对公平性分析的支持。
https://pair-code.github.io/lit/
此外,ML系统的可解释性也是一个重点问题。
在与DeepMind的合作中,谷歌在理解人类象棋概念在自监督训练的AlphaZero象棋系统中的获得方面取得了进展。

探索AlphaZero在下棋方面可能学到的东西
随着ML模型变得更有能力并在许多领域产生影响,保护ML中使用的私人信息就变得尤为重要了。
而谷歌在最近的一些工作中,既强调了训练数据有时可以从大型模型中提取,又指出了如何在大型模型中保障隐私。

https://arxiv.org/pdf/2108.01624.pdf
此外,谷歌也在利用其他的ML技术来确保差异化的隐私,例如私有聚类、私有个性化、私有加权采样等。
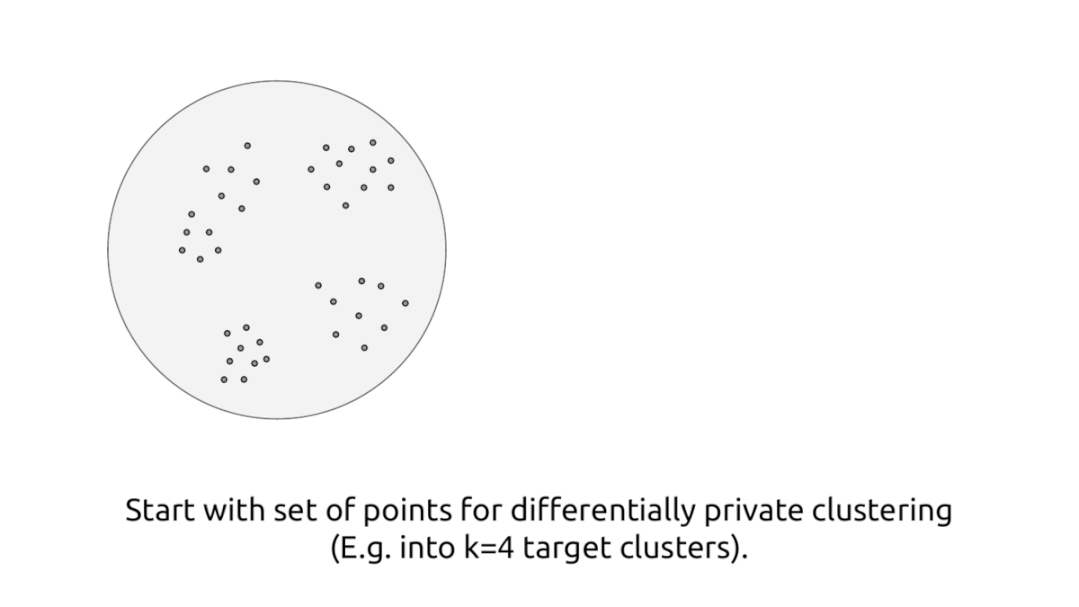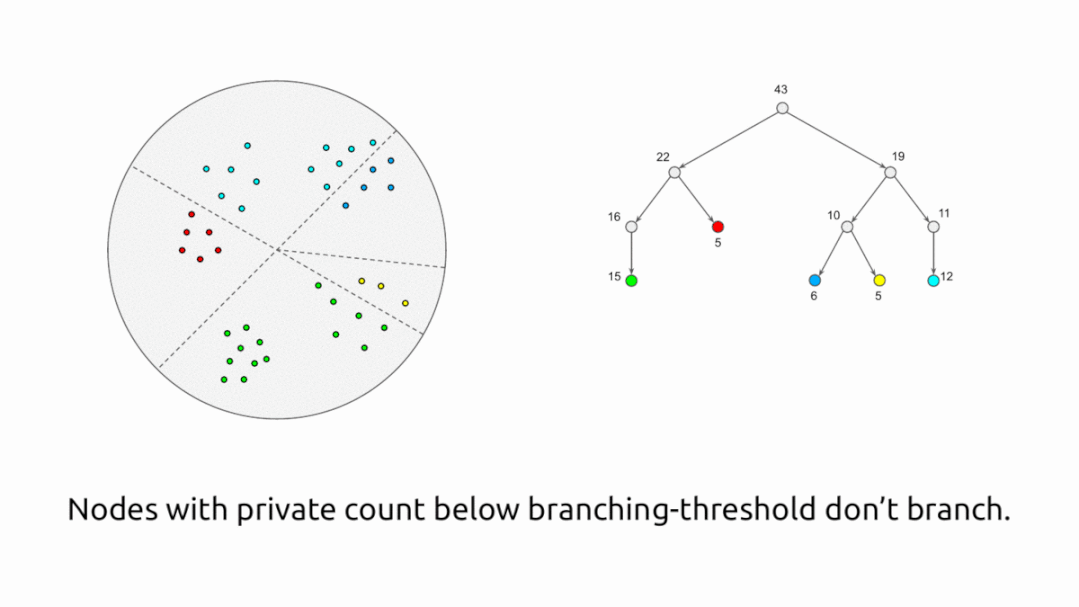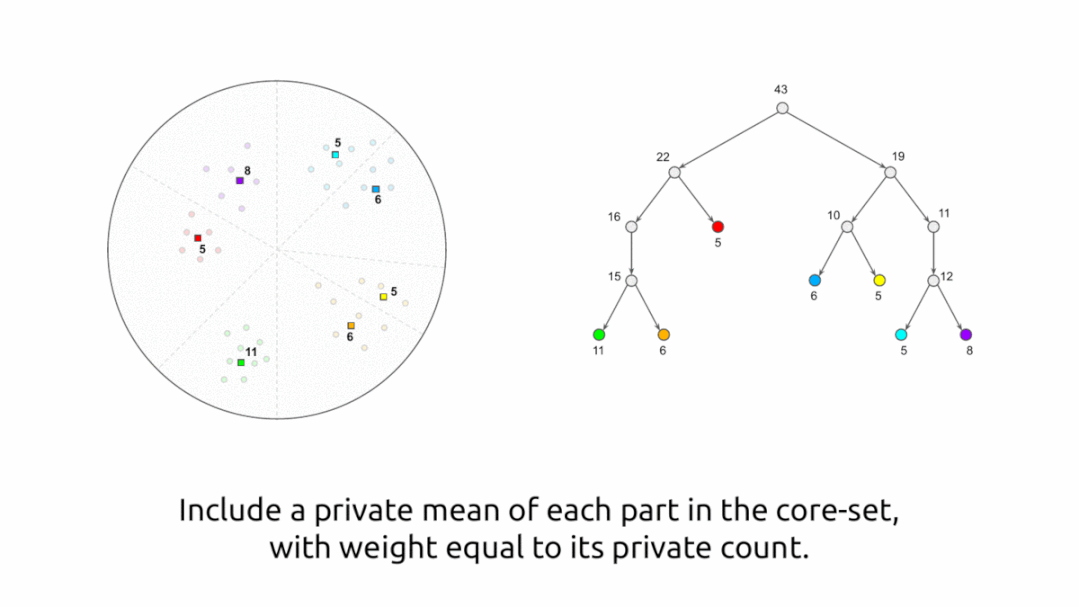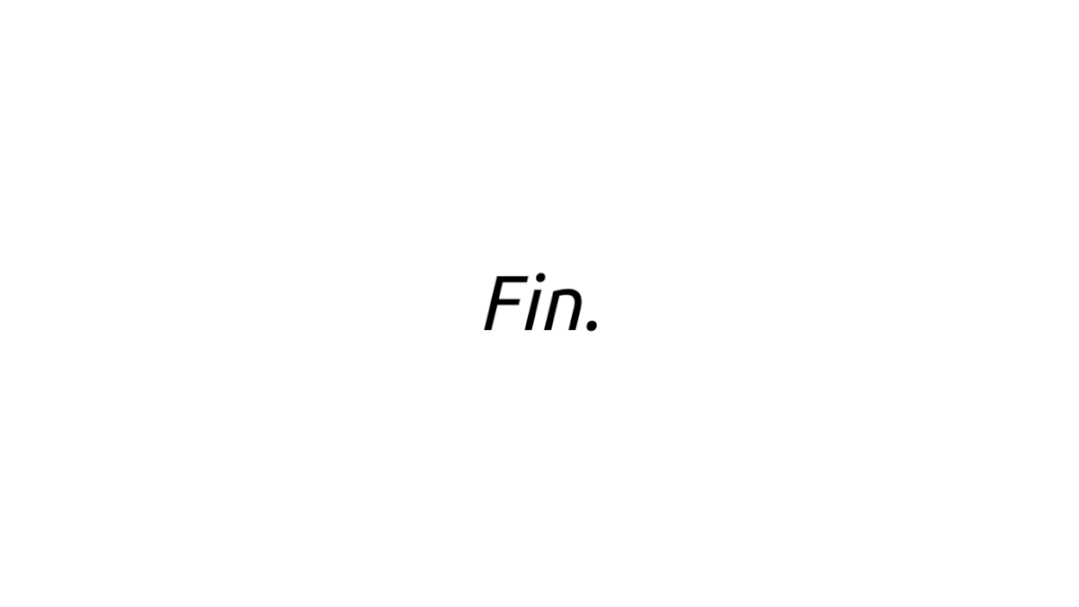
差异化私有聚类算法
结论
研究通常是一个持续多年的旅程。而谷歌近几年的研究工作已经逐渐开始对其产品,甚至整个世界产生影响了。
例如,在TPU等ML硬件加速器以及TensorFlow和JAX等软件框架的投资已经取得了成果,而ML模型在谷歌的产品和功能中越来越普遍。
对创建Seq2Seq、Inception、EfficientNet和Transformer的模型架构的研究或批量规范化和蒸馏等算法研究正在推动语言理解、视觉、语音和其他领域的进展。
Jeff Dean表示,现在是机器学习和计算机科学真正令人兴奋的时代。计算机通过语言、视觉和声音理解周围世界并与之交互的能力在不断提高。
由此,也开辟了一个让计算机帮助人类完成现实世界工作的全新疆域。(完)
参考资料:
https://ai.googleblog.com/2022/01/google-research-themes-from-2021-and.html
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
