深度学习-Inception和Xception网络结构详解
Inception 是神经网络结构的一大神作,其提出的「多尺寸卷积」和「多个小卷积核替代大卷积核」等概念是现如今许多优秀网络架构的基石。也正是如此,基于此的 Xception 横空出世,作者称其为 Extreme Inception,提出的 Depthwise Separable Conv 也是让人眼前一亮。
本文不详细讲解论文内容,只探讨提出的这几个基础概念和结构,并按照时间顺序来探讨。首先探讨的是 Inception 的 多尺寸卷积核 和 卷积核替换,然后到 Bottleneck,最后到 Xception 的 Depthwise Separable Conv 。
多尺寸卷积核
Inception 最初提出的版本,其核心思想就是使用多尺寸卷积核去观察输入数据。
举个例子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图:
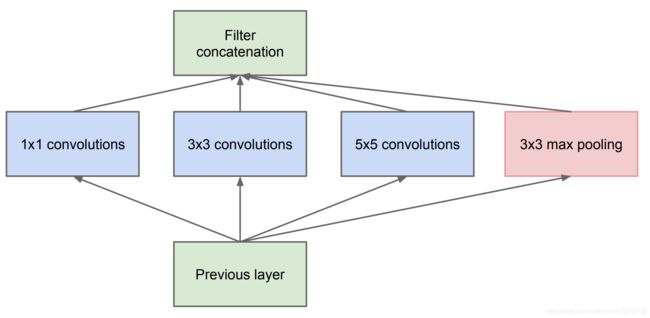
Naive Inception V1
于是我们的网络就变胖了,增加了网络的宽度,同时也提高了对于不同尺度的适应程度。
Pointwise Conv
但是我们的网络变胖了的同时,计算量也变大了,所以我们就要想办法减少参数量来减少计算量,于是在 Inception v1 中的最终版本加上了 1x1 卷积核。
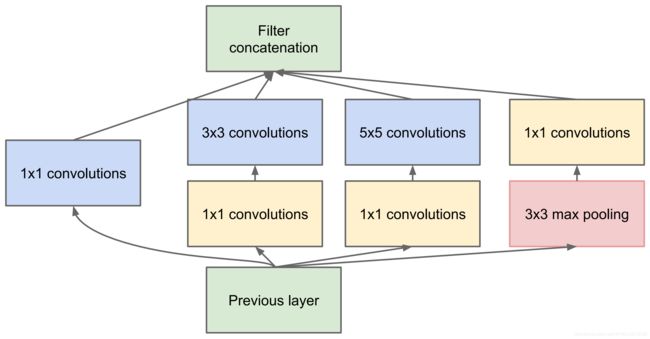
Inception V1
使用 1x1 卷积核对输入的特征图进行降维处理,这样就会极大地减少参数量,从而减少计算。
举个例子,输入数据的维度是 256 维,经过 1x1 卷积之后,我们输出的维度是 64 维,参数量是原来的 14 。
这就是 Pointwise Convolution,俗称叫做 1x1 卷积,简写为 PW,主要用于数据降维,减少参数量。
也有使用 PW 做升维的,在 MobileNet v2 中就使用 PW 将 3 个特征图变成 6 个特征图,丰富输入数据的特征。
想深入了解 MobileNet v2 的可以看看原文 MobileNet V2 - arxiv.org ,再对照地读这篇MobileNet V2 论文初读 - Michael Yuan。
卷积核替换
就算有了 PW ,由于 5x5 和 7x7 卷积核直接计算参数量还是非常大,训练时间还是比较长,我们还要再优化。
人类的智慧是无穷的,于是就想出了 使用多个小卷积核替代大卷积核 的方法,这就是 Inception v3,如图所示:
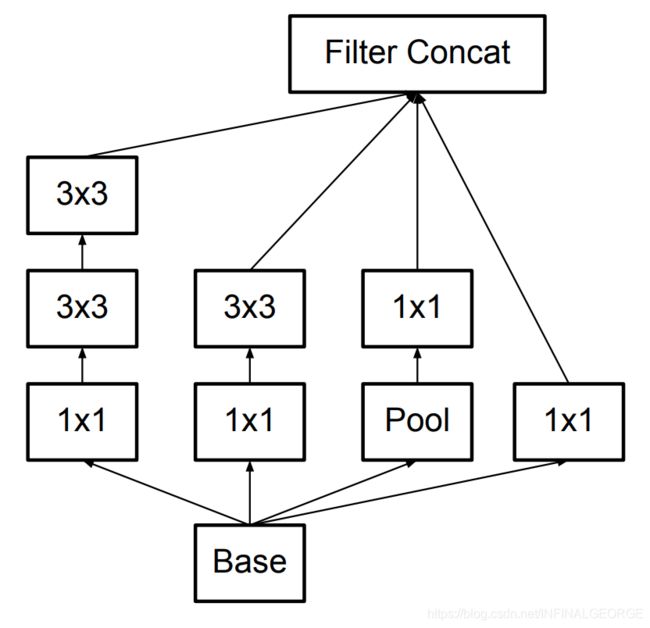
Inception V3
使用两个 3x3 卷积核来代替 5x5 卷积,效果上差不多,但参数量减少很多,达到了优化的目的。不仅参数量少,层数也多了,深度也变深了。
除了规整的的正方形,我们还有分解版本的 3x3 = 3x1 + 1x3,这个效果在深度较深的情况下比规整的卷积核更好。
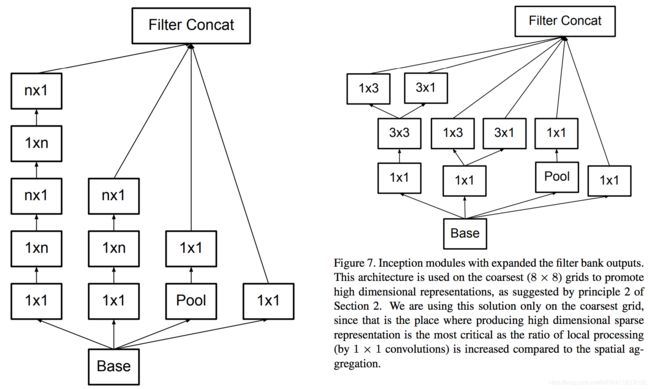
Inception V3
我们假设输入 256 维,输出 512 维,计算一下参数量:
5x5 卷积核
256∗5∗5∗512=3276800
两个 3x3 卷积核
256∗3∗3∗256+256∗3∗3∗512=589824+1179648=1769472
结果对比
17694723276800=0.54
我们可以看到参数量对比,两个 3x3 的卷积核的参数量是 5x5 一半,可以大大加快训练速度。
Bottleneck
我们发现就算用了上面的结构和方法,我们的参数量还是很大,于是乎我们结合上面的方法创造出了 Bottleneck 的结构降低参数量。
Bottleneck 三步走是先 PW 对数据进行降维,再进行常规卷积核的卷积,最后 PW 对数据进行升维。我们举个例子,方便我们了解:
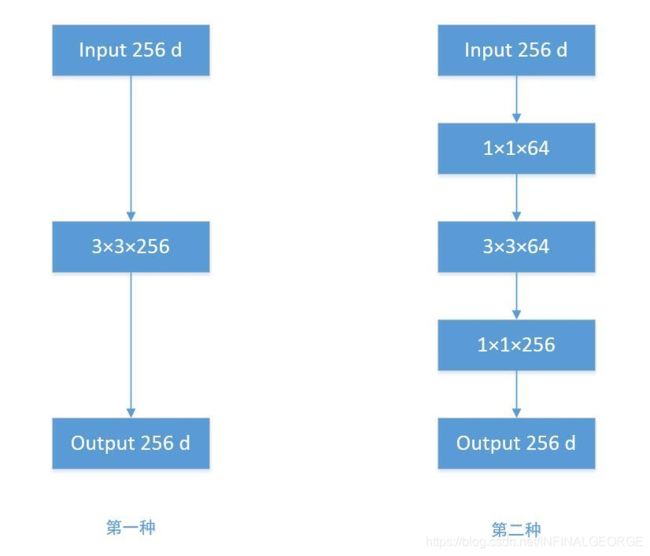
Bottleneck
根据上图,我们来做个对比计算,假设输入 feature map 的维度为 256 维,要求输出维度也是 256 维。有以下两种操作:
直接使用 3x3 的卷积核。256 维的输入直接经过一个 3×3×256 的卷积层,输出一个 256 维的 feature map ,那么参数量为:256×3×3×256 = 589,824 。
先经过 1x1 的卷积核,再经过 3x3 卷积核,最后经过一个 1x1 卷积核。 256 维的输入先经过一个 1×1×64 的卷积层,再经过一个 3x3x64 的卷积层,最后经过 1x1x256 的卷积层,则总参数量为:256×1×1×64 + 64×3×3×64 + 64×1×1×256 = 69,632 。
经过两种方式的对比,我们可以很明显的看到后者的参数量远小于前者的。Bottleneck 的核心思想还是利用多个小卷积核替代一个大卷积核,利用 1x1 卷积核替代大的卷积核的一部分工作。
Depthwise Separable Conv
我们发现参数量还是很多,于是人们又想啊想,得出了 Depthwise Separable Conv 。这个注意最早是来自这篇论文 Design of Efficient Convolutional Layers using Single Intra-channel Convolution, Topological Subdivisioning and Spatial “Bottleneck” Structure ,后面被 Google 用在 MobileNet 和 Xception 中发扬光大。
这个卷积的的大致意思是对每一个深度图分别进行卷积再融合,步骤是先 Depthwise Conv 再 Pointwise Conv,大大减少了参数量。下图是 Xception 模块的结构:
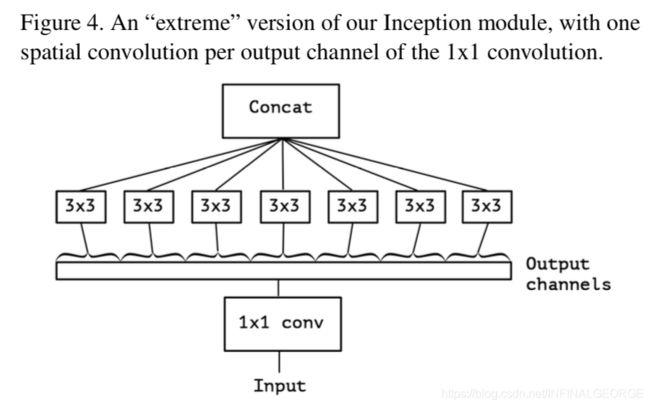
Depthwise Separable Conv
大致的步骤是这样的:
分别按不同通道进行一次卷积(生成 输入通道数 张 Feature Maps)- DW
再将这些 Feature Maps 一起进行第二次卷积 - PW
文字看起来有点抽象,我们用栗子来理解一下。
输入的是 2 维的数据,我们要进行 3x3 卷积并输出 3 维的数据,与正常卷积对比:
正常卷积
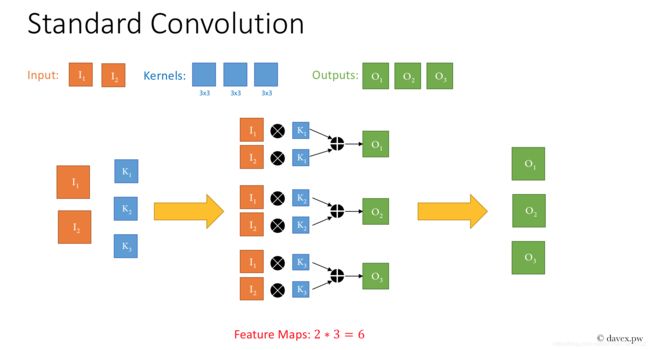
Standard Conv
2∗3∗3∗3=54
DW 卷积
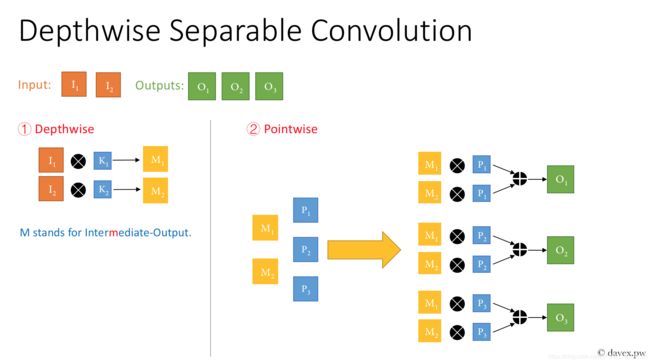
Depthwise Conv
2∗3∗3+2∗1∗1∗3=18+6=24
参数量对比
2454=0.444
我们可以看到,参数量是正常卷积的一半,但实际上可以更少,只不过在输入输出维度相差不大的情况下,效果没那么明显。
理论计算
PDW=I∗Dk∗Dk+I∗O
PNormal=I∗Dk∗Dk∗O
PDWPNormal=1O+1D2k≈1D2k
其中 I 为输入通道数,O 是输出通道数,Dk 是标准卷积核大小。
我们可以看到,当我们使用 3x3 卷积核的时候,参数量约等于标准卷积核的 19 ,大大减少参数量,从而加快训练速度。
Summary
从 Inception 到 Xception 的发展一路看来,每一次创新都让人啧啧称赞,精巧的结构设计和理念思想,让人佩服。
多个不同尺寸的卷积核,提高对不同尺度特征的适应能力。
PW 卷积,降维或升维的同时,提高网络的表达能力。
多个小尺寸卷积核替代大卷积核,加深网络的同时减少参数量。
精巧的 Bottleneck 结构,大大减少网络参数量。
精巧的 Depthwise Separable Conv 设计,再度减少参数量。
了解了这些基础结构的思想,我们就可以站在巨人的肩膀上更好地向前看,走向更优秀的方向。
原文链接:https://www.davex.pw/2018/02/05/breadcrumbs-about-inception-xception/#Depthwise-Separable-Conv