Inception
文章目录
- Inception 系列
-
- Inception v1
-
-
- Inception模块
- 网络架构
-
- Inception v2 和 Inception v3
-
- Batch Normalization
- 分解卷积核
- 辅助分类器
- Efficient Grid Size Reduction
-
- Inception v2
- Inception v3
- 实验
- Inception v4
-
-
- 相关实验
-
- Xception
-
- Inception 模块
- Xception网络结构
- 相关实验
- 参考文献
Inception 系列
Inception 系列网络有个问题:网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
Inception v1
V1论文:Going deeper with convolutions(2014)
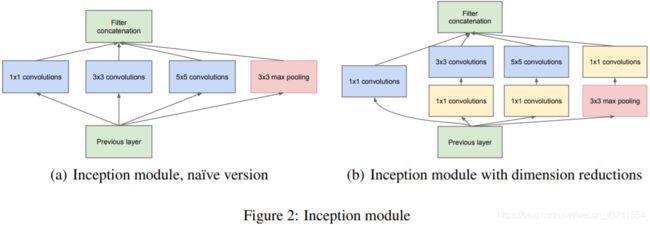
Inception模块
- 每个采用不同大小的卷积核或者Pooling(不知道哪个好,让网络自己选择)
- 1×1卷积:匹配维度,跨通道提取特征
网络架构
采用Inception模块结构(9个)进行搭建,共22层。为了避免梯度消失,网络额外增加了2个辅助的softmax、(实际测试的时候会被去掉),并按一个较小的权重(0.3)加到最终分类结果中,相当于训练的时候多两个监督信号

Inception v2 和 Inception v3
论文:Rethinking the Inception Architecture for Computer Vision(ML 2015)速达>>
Batch Normalization
论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift(2015)


分解卷积核
分解大的卷积核后,共用一个激活层,MobileNets v2对此有较深入讨论
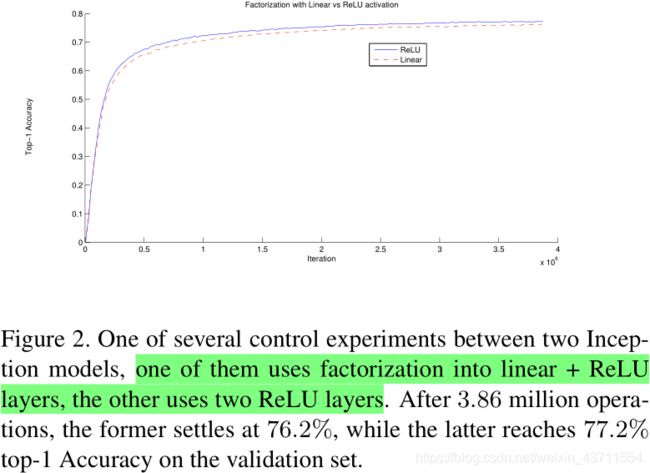
两种分解卷记的方式:
- 将大卷积分解成更小的3×3卷积(减少参数,增强分线性表达能力)
- 将n×n卷积分解成1×n和n×1卷积的组合(网络前期使用这种分解效果并不好,在中度大小的feature map上效果较好,推荐在大小为12到20间的特征图上使用)
辅助分类器
引入辅助分类器的概念改善深度网络的收敛性,最初动机是解决梯度消失问题,加快收敛。但是实验发现辅助分类器并没有在训练早期提高收敛性:
- 在两个模型达到高精度之前,有辅助分类器和没有辅助分类器的网络训练进程几乎相同,在训练快结束时,有辅助分支的网络优势开始显现,精度稳定在一个更高的水准。
另外,实验还发现移除一条辅助支路(Inception v1 中设置了两条)对网络没有任何不利影响
Efficient Grid Size Reduction
加深网络的同时,一般会逐渐降低特征图分辨率,提升通道数,卷积网络常使用池化(以前)操降低分辨率,先卷积(提升通道数)后pooling(降分辨率)计算代价更高,先pooling后卷积会限制特征提取,如 Fig 9
折中的方法就是两者并行,如 Fig10

|

|
Inception v2
Inception v2 在 Inception v1 的基础上改进,
- 网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8特征层的模块
- 使用BN,增大学习率并加快学习率衰减速度以适用BN规范化后的数据
- 去除了Dropout、LRN等结构
- 3个3x3卷积层代替7x7卷积层
具体网络架构如下表:


|

|

|
Inception v3
Inception v2 + RMSProp + Lable Smoothing + Factorizes 7×7 ⟹ Inception v3 \color{blue}\text{Inception v2 + RMSProp + Lable Smoothing + Factorizes 7×7 $\Longrightarrow$ Inception v3} Inception v2 + RMSProp + Lable Smoothing + Factorizes 7×7 ⟹ Inception v3

原文:

实验
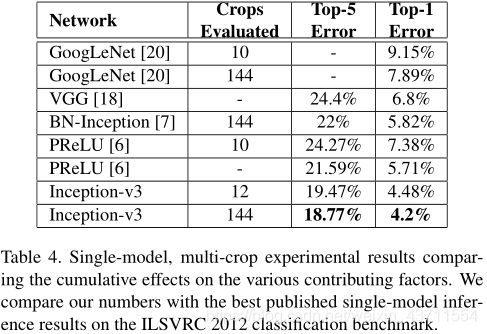
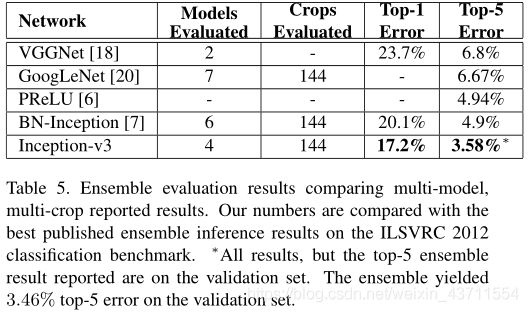
Inception v4
论文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning(CVPR 2016)速达>>
结合ResNet,加速训练,同时提升性能
| Inception v4 | ||
|---|---|---|

|

|

|
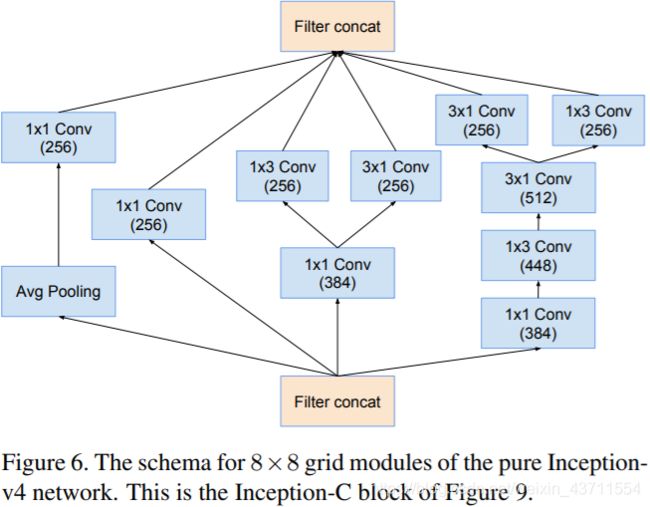
|

|
|

|
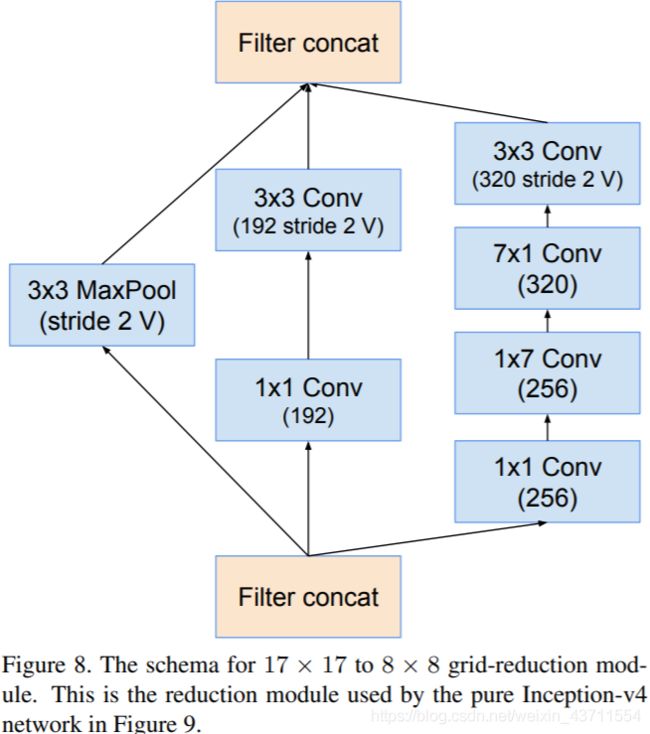
|
|
| Inception-ResNet-v1 | ||
|---|---|---|

|

|

|

|
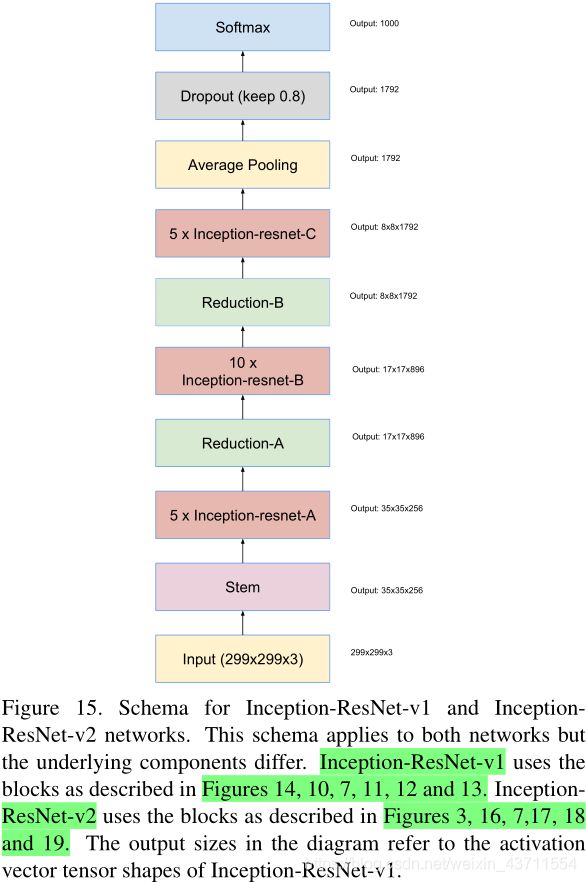
|
|

|

|
|
| Inception-ResNet-v2 | ||
|---|---|---|

|

|
|

|
|
|

|

|
|
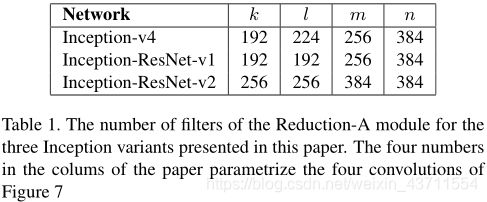
相关实验


Xception
Xception:Xception: Deep Learning with Depthwise Separable Convolutions(CVPR 2017)速达>>
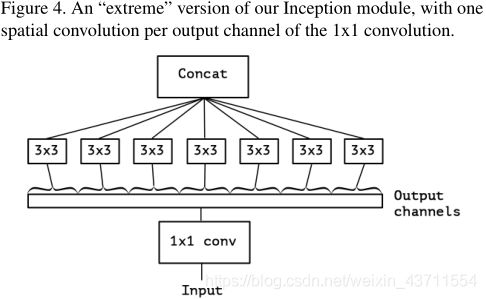
Inception 模块
丢弃繁琐的结构,回归简单


Inception module类似将 MobileNets v1 中的 Depthwise Separable Convolution 反过来,先1×1卷积接着逐通道进行3×3卷积
注意还有一点不同:Inception module 中的卷积层后面均跟有非线性激活层

Xception网络结构
注意:加号处不是先前版本的合并通道,而是类似ResNet残差模块

相关实验








参考文献
【1】GoogLeNet(从Inception v1到v4的演进)
【2】深入浅出——网络模型中Inception的作用与结构全解析
【3】深度学习经典卷积神经网络之GoogLeNet
【4】经典网络GoogLeNet(Inception V3)网络的搭建与实现
【5】MobileNets v1
【6】MobileNets v2
【7】Xception算法详解