相关精彩专题链接: 数据成就更好的你
本案例数据下载: https://pan.baidu.com/s/1HZ8mygqr-cJSVUyIQuX1bA 提取码: kkvv
整体概述
本案例的数据为小程序运营数据,以行业常见指标对用户行为进行分析,包括UV、PV、新增用户分析、漏斗流失分析、留存分析、用户价值分析、复购分析等内容。其分析框架如下图:

一、数据提取
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
import datetime
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#数据存储在mysql数据库中
conn=create_engine("mysql+pymysql://用户名:密码@127.0.0.1:3306/数据库名称?charset=utf8")
data=pd.read_sql("behavior",conn)
本数据集约76万条数据

二、数据处理
#1.观察数据,查看数据内容包含什么
data.head()
#2.数据去重处理
data.drop_duplicates(inplace=True)
#3.时间戳time数据处理。转化为访问网站的具体时间、月份、日期、每天几点访问
data["time1"]=data["time"].apply(lambda x:datetime.datetime.fromtimestamp(x))
data["month"]=data["time"].apply(lambda x:int(datetime.datetime.fromtimestamp(x).strftime("%Y%m")))
data["date"]=data["time"].apply(lambda x:datetime.datetime.fromtimestamp(x).strftime("%Y%m%d"))
data["hour"]=data["time1"].apply(lambda x:x.hour)
#4.销售金额计算
data["money"]=data["price"]*data["amount"]
#5.缺失值处理:观察有没有缺失值,有缺失值则对缺失值处理。本数据集没有缺失值
data.isnull().sum()
#6.观察数据有没有异常值。总共757565条记录,和时间相关的数据都正常,其他字段也无异常值
data.describe()

三、用户行为分析:pv/uv
1、pv/uv 按天分析,观察其访问走势
all_puv=pd.pivot_table(data,index=["date"],values="user_id",aggfunc="count")
uv=data[["user_id","date"]].drop_duplicates()["date"].value_counts()
all_puv=all_puv.join(uv)
all_puv.columns=["pv","uv"]
all_puv["avg_pv"]=all_puv["pv"]/all_puv["uv"]
all_puv


2、pv/uv 按天分析,观察每个行为操作的点击量
pv=pd.pivot_table(data,index=["date"],columns=["behavior"],values="user_id",aggfunc="count")
pv["all"]=pv.sum(axis=1)

plt.figure(figsize=(12,5))
plt.plot(pv.index,pv["all"])
plt.plot(pv.index,pv["pv"],color="r")
plt.plot(pv.index,pv["cart"],color="b")
plt.plot(pv.index,pv["buy"],color="c")
plt.plot(pv.index,pv["fav"],color="y")
plt.xlabel("日期",fontsize=12)
plt.ylabel("pv",fontsize=12)
plt.title("用户行为pv分析",fontsize=16)
plt.legend( ["all","pv","cart","buy","fav"],loc = 'upper left',fontsize=12)
plt.show()
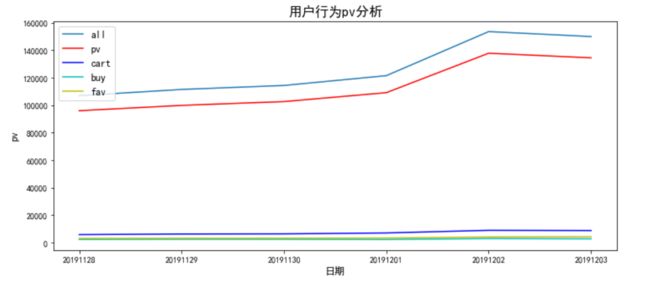
3.观察用户每天的访问高峰区。本数据集中,访问高峰期为晚上19点至23点
hour_pv=data["hour"].value_counts().reset_index().rename(columns={'index':'hour', 'hour':'pv'})
plt.figure(figsize=(12,3))
plt.bar(hour_pv["hour"],hour_pv["pv"])
plt.xlabel("小时",fontsize=12)
plt.ylabel("访问量pv",fontsize=12)
plt.title("用户按小时统计的访问量",fontsize=16)
plt.show()

四、获客分析
获客分析:观察每日新增用户情况。新用户的定义:第一次访问网站
new_visitor=data[["user_id","date"]].groupby("user_id").min()["date"].value_counts().reset_index()
new_visitor.columns=["date","new_visitor"]
plt.figure(figsize=(8,3))
x,y=new_visitor["date"],new_visitor["new_visitor"]
plt.bar(x, y, width=0.6)
for a, b in zip(x, y):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=10)
plt.xlabel("日期",fontsize=12)
plt.ylabel("新用户数",fontsize=12)
plt.title("每日新增用户数",fontsize=16)
plt.show()

五、用户留存分析
留存定义为 1月1日,新增用户200人;
次日留存:第2天,1月2日,这200人里面有100人活跃,则次日留存率为:100 / 200 = 50%
2日留存:第3天,1月3日,这200名新增用户里面有80人活跃, 第3日新增留存率为:80/200 = 40%; 以此类推
#建立n日留存率计算函数,data传入的为用户id和登录日期, start_date为起始时间(格式为:%Y%m%d),n为n日留存,不传入start_date和n时,则计算所有留存
def cal_retention(data,start_date="20100101",n=0):
if n>0:
new_user=data[["user_id","date"]].groupby("user_id").min().reset_index()
date2=datetime.datetime.strptime(start_date,"%Y%m%d")+datetime.timedelta(n)
end_date=datetime.datetime.strftime(date2,"%Y%m%d")
start_user=set(new_user[new_user.date==start_date].user_id)
end_user=set(data[data.date==end_date].user_id)
user=start_user&end_user
return [start_date,end_date,len(start_user),len(user),round(len(user)/len(start_user),4)]
else:
new_user=data[["user_id","date"]].groupby("user_id").min().reset_index()
date_sourse=new_user.date.unique()
date_sourse.sort()
result1=[]
flag=0
for start_date in date_sourse:
start_user=set(new_user[new_user.date==start_date].user_id)
for end_date in date_sourse[flag:]:
end_user=set(data[data.date==end_date].user_id)
user=start_user&end_user
result1.append([start_date,end_date,len(start_user),len(user),round(len(user)/len(start_user),4)])
flag=flag+1
return pd.DataFrame(result1,columns=["开始日期","留存日期","新用户数","留存人数","留存率"])
#调用cal_retention函数计算留存。
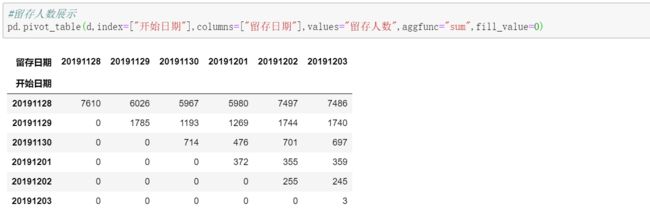
#例:计算11约28日的3日留存,其返回结果为:['20191128', '20191201', 7610, 5980, 0.7858],此数据的含义为:28号的新用户数为7610,第3日的留存用户为5980,留存率为78.58%
cal_retention(data[["user_id","date"]],"20191128",3)
#调用cal_retention函数计算留存,只传入数据集
retention=cal_retention(data[["user_id","date"]])
#留存人数展示
pd.pivot_table(retention,index=["开始日期"],columns=["留存日期"],values="留存人数",aggfunc="sum",fill_value=0)
#留存率展示
pd.pivot_table(retention,index=["开始日期"],columns=["留存日期"],values="留存率",aggfunc="sum",fill_value=0)

六、复购分析
指在单位时间段内,重复购买率=再次购买人数/总购买人数。
例如在一个月内,有100个客户成交,其中有20个是回头客,则重复购买率为20%。
此处的回头客定义为:按天去重,即一个客户一天产生多笔交易付款,则算一次购买,除非在统计周期内另外一天也有购买的客户才算是回头客。
data_buy=data[data.behavior=="buy"][["user_id","date"]].drop_duplicates()["user_id"].value_counts().reset_index()
data_buy.columns=["user_id","num"] #user_id表示用户id,num表示购买次数
#复购率计算
rebuy_rate=round(len(data_buy[data_buy.num>=2])/len(data_buy),4)
print("复购率为:",round(rebuy_rate*100,2),"%") #输出结果为:42.06 %
#购买的总人数
buy_user=len(data_buy)
#购买次数的人数分布
buy_freq=data_buy.num.value_counts().reset_index()
buy_freq.columns=[["购买次数","人数"]]
buy_freq["人数占比"]=round(buy_freq["人数"]/buy_user,4)
从以下数据可以看出,一共有6110个用户有购买行为,购买1次的人数最多,为3540,占了57.94%。本数据集的复购率为42.06 %,商家需从商品质量、价格、促销活动、物流等多方面寻找问题点,需求高复购率的突破

七、RFM模型分析
RFM模型分析前提条件:
a. 最近有过交易行为的客户,再次发生交易的可能性高高于最近没有交易行为的客户;
b.交易频率较高的客户比交易频率较低的客户,更有可能再次发生交易行为;
c.过去所有交易金额较多的客户,比交易金额较少的客户,更有消费积极性。
#取数规则:最近一次消费的时间取最大,消费频次根据计数统计,消费金额求平均值统计
RFM_date=data[data.behavior=="buy"][["user_id","date"]].groupby("user_id").max()
RFM_F=data[data.behavior=="buy"][["user_id","behavior"]].groupby("user_id").count()
RFM_M=data[data.behavior=="buy"][["user_id","money"]].groupby("user_id").mean()
RFM=RFM_date.join(RFM_F).join(RFM_M)
#用户价值分层(RFM模型):模型计算的日期为 2019-12-05
end_date=datetime.datetime.strptime("20191205","%Y%m%d")
#时间间隔天数计算
RFM["days"]=RFM["date"].apply(lambda x:(end_date-datetime.datetime.strptime(x,"%Y%m%d")).days)
RFM=RFM[["days","behavior","money"]]
RFM.columns=["间隔天数","消费频次","消费金额"]

模型打分,这里采用5分制,规则如下:

根据打分规则对数据进行处理
RFM["R_S"]=RFM["间隔天数"].apply(recency)
RFM["F_S"]=RFM["消费频次"].apply(frequency)
RFM["M_S"]=RFM["消费金额"].apply(monetary)
RFM["RFM"]=RFM.apply(lambda x: int(x.R_S*100+x.F_S*10+x.M_S),axis=1)
RFM.head()
每一个RFM代码都对应着一小组客户,开展市场营销活动的时候可以从中挑选出若干组进行。例如 :RFM代码为443的用户,其消费时间间隔比较短,消费频次和购买力都很高,可做为重点客户重点维护。计算结果如下:

八、漏斗分析---转化路径
转化路径定义:pv点击 ---cart放入购物车 ---buy购买
#导入绘制漏斗图的工具包
from pyecharts.charts import Funnel
from pyecharts import options as opts
#转化分析,转化路径为:pv点击 ---cart放入购物车 ---buy购买
data_behavior=data[data.behavior!="fav"]["behavior"].value_counts().reset_index().rename(columns={"index":"环节","behavior":"人数"})
#单一环节的转化率
temp1 = np.array(data_behavior['人数'][1:])
temp2 = np.array(data_behavior['人数'][0:-1])
single_convs = temp1 / temp2
single_convs = list(single_convs)
single_convs.insert(0,1)
data_behavior['单一环节转化率'] = single_convs
#总体转化率
flag=data_behavior['人数'][0]
data_behavior['总体转化率'] = data_behavior['人数']/flag
#总体转化漏斗
attrs=[a+": "+str(round(b,2))+"%" for a,b in zip(data_behavior['环节'],data_behavior['总体转化率']* 100)]
attr_value=[round(a,2) for a in data_behavior['总体转化率']* 100]
funnel = Funnel()
funnel.add("商品", [list(z) for z in zip(attrs, attr_value)],label_opts=opts.LabelOpts(position="inside"))
funnel.set_global_opts(title_opts=opts.TitleOpts(title="总体转化漏斗分析"))
funnel.render_notebook()

九、商品销售分析
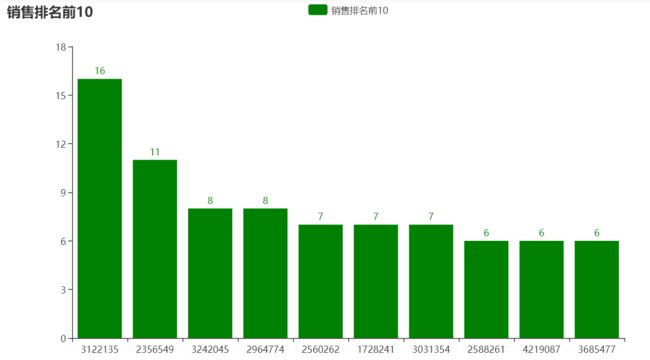
1.商品top分析----销售次数最多的商品,取前10
#商品top分析----销售次数最多的商品,取前10
buy_top=data[data.behavior=="buy"]["goods_id"].value_counts().head(10)
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(buy_top.index.tolist())
bar.add_yaxis("销售排名前10",buy_top.values.tolist(),color="green")
bar.set_global_opts(title_opts=opts.TitleOpts(title="销售排名前10"))
#bar.render()
bar.render_notebook()
2.商品top分析----浏览次数最多的商品,取前10
#商品top分析----浏览次数最多的商品,取前10
pv_top=data[data.behavior=="pv"]["goods_id"].value_counts().head(10)
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(pv_top.index.tolist())
bar.add_yaxis("浏览排名前10",pv_top.values.tolist(),color="green")
bar.set_global_opts(title_opts=opts.TitleOpts(title="浏览排名前10"))
#bar.render()
bar.render_notebook()

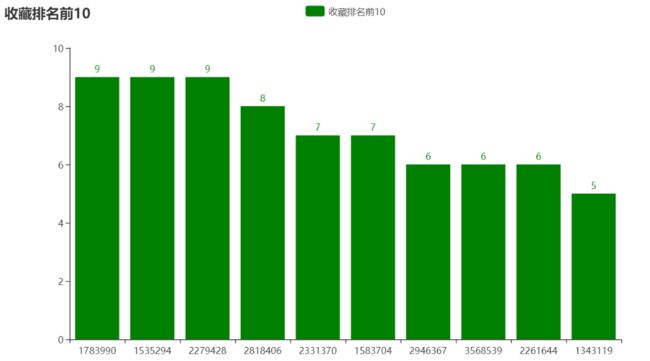
3.商品top分析----收藏次数最多的商品,取前10
#商品top分析----收藏次数最多的商品,取前10
fav_top=data[data.behavior=="fav"]["goods_id"].value_counts().head(10)
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(buy_top.index.tolist())
bar.add_yaxis("销售排名前10",buy_top.values.tolist(),color="green")
bar.set_global_opts(title_opts=opts.TitleOpts(title="销售排名前10"))
#bar.render()
bar.render_notebook()
4.城市购买力排名
#城市购买力排名
city_top=data[data.behavior=="buy"][["addr","money"]].groupby("addr").sum().sort_values("money",ascending=False)
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(city_top.index.tolist())
bar.add_yaxis("城市购买力",[round(a,2) for a in city_top.money])
#bar.render()
bar.render_notebook()

5.不同性别的消费贡献情况
#不同性别的消费贡献情况 sex中:0代表女性,1代表男性
sex_top=data[data.behavior=="buy"][["sex","money"]].groupby("sex").sum()
from pyecharts.charts import Pie
from pyecharts import options as opts
base_pie = Pie()
base_pie.add("", [list(z) for z in zip(['女','男'], [round(a,2) for a in city_top.money])])
base_pie.set_global_opts(title_opts=opts.TitleOpts(title="不同性别的购买力"))
base_pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)")) #自定义显示格式(b:name, c:value, d:百分比)
base_pie.render_notebook()

6.商品类目销售情况分析
cat_top=data[data.behavior=="buy"]["cat"].value_counts().head(10)
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(cat_top.index.tolist())
bar.add_yaxis("商品类目销售排行前10",cat_top.values.tolist())
bar.render_notebook()
