作者|Soner Yıldırım
编译|VK
来源|Towards Data Science

SQL是一种编程语言,大多数关系数据库管理系统(RDBMS)都使用它来管理以表格形式(即表)存储的数据。
SQL是数据科学家所期望的一项基本技能。你可能会说,这是一个数据工程师的工作,但数据科学家的角色往往是全套的。此外,作为一名数据科学家,你不希望依赖数据工程师从数据库中检索数据。
在本文中,我们将编写复杂的查询来检索存储在表中的数据。我已经将客户流失数据集(https://www.kaggle.com/shubh0799/churn-modelling)上传到MySQL数据库的一个表中。
我们将从简单的查询开始,逐步增加复杂性。我将描述所需的数据,然后编写查询以从表中检索数据。
让我们先看看表中的列。
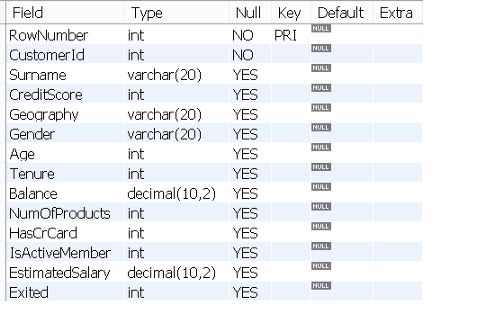
关于客户和他们在银行的账户有一些特点。“Exited”列指示客户是否流失(即离开银行)。
我们现在可以开始查询了。
“CustomerId”和“姓氏”列的前5行
SELECT CustomerId, Surname
FROM CHURN
LIMIT 5;

余额最高的客户的ID
SELECT CustomerId, MAX(Balance)
FROM CHURN;
我们没有检索整个“Balance”列,而是使用MAX函数仅选择该列中的最大值。
余额排名前5位的客户
我们不能在这个查询中使用MAX,因为我们需要排名前5的客户。我们可以做的是根据余额对客户进行排序,然后选择使用LIMIT得到前5名。
SELECT Geography, Balance
FROM CHURN
ORDER BY Balance DESC
LIMIT 5;

没有信用卡的顾客的平均年龄
有一个条件,所以我们使用WHERE语句。
SELECT AVG(Age)
FROM CHURN
WHERE HasCrCard = 0;
39.1121
如果你想知道,拥有信用卡的顾客的平均年龄是38.8424岁。
每个国家拥有2种以上产品的客户数量
我们将使用另一个聚合函数来计算客户数量。为了根据属性对客户进行分组,将使用GROUPBY语句。
SELECT Geography, COUNT(CustomerId)
FROM CHURN
WHERE NumOfProducts > 2
GROUP BY Geography;

基于产品数量的平均工资
我们可以将AVG函数应用于薪资,并按产品数量分组。
SELECT NumOfProducts, AVG(EstimatedSalary)
FROM CHURN
GROUP BY NumOfProducts;
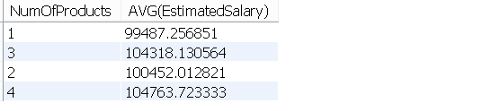
WHERE语句允许我们选择符合一个或多个条件的条目。但是,它不能与聚合函数一起使用。
对于上面的查询,我们只对平均值大于100000的产品类别感兴趣。因此,我们需要对平均值应用一个条件,这个条件可以使用HAVING语句来完成。
SELECT NumOfProducts, AVG(EstimatedSalary)
FROM CHURN
GROUP BY NumOfProducts
HAVING AVG(EstimatedSalary) > 100000;

50岁以上并且余额高于平均水平的客户
我们在这里介绍两个新主题。一种是使用多个条件(age和balance),另一种是嵌套的SELECT语句。
我们可以使用AND和OR等逻辑运算符在WHERE语句中组合多个条件。一个条件显式给定(age>50),但另一个条件需要使用另一个SELECT语句在表上计算。这就是我们需要嵌套SELECT语句的地方。
SELECT CustomerId, Age, Balance
FROM CHURN
WHERE Age > 50 AND Balance > (
SELECT AVG(Balance)
FROM CHURN );
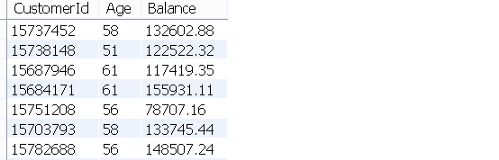
余额上的条件是另一个SELECT语句。
为已离开的女性并且存留时间超过了平均水平的客户数量
它与前面的示例类似,但有一个附加条件。我们将根据三个条件统计客户数量:
- 性别
- Exited= 1
- 客户在银行的存留时间
SELECT COUNT(CustomerId) AS 'Number of Customers'
FROM CHURN
WHERE Gender = 'Female' AND Exited=1 AND Tenure > (
SELECT AVG(Tenure)
FROM CHURN);
我们还可以使用“AS”关键字调整结果集中列的名称。

)
结论
我们已经讨论了一些基本和复杂的查询。我们通过查询实现的是一些计算和过滤。因此,我们只能检索我们需要的数据。
由于实际的数据库包含更多的数据和许多关系表,因此能够使用SQL查询所需的数据是非常重要的。
原文链接:https://towardsdatascience.com/sql-queries-for-data-scientists-5260737fc442
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/