安装Nginx:
yum install -y nginx
systemctl start nginx
systemctl stop nginx
安装MariaDB(MySQL的一个分支):
yum install -y mariadb mariadb-server
systemctl start mariadb
mysql -u root
安装MySQL:

- 清除掉所有跟mariadb相关的东西
yum list installed | grep mariadb | awk '{print $1}' | xargs yum erase -y - 清理之前的数据和日志文件(如果存在)
rm -rf /var/lib/mysql
rm -f /var/log/mysqld.log - 下载MySQL官方提供的RPM包并解归档
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.28-1.el7.x86_6ls4.rpm-bundle.tar
tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar - 安装依赖库
yum install -y libaio - 使用rpm包管理工具安装MySQL
rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm - 启动服务查看随机密码
systemctl start mysqld
cat /var/log/mysqld.log | grep password - 用客户端工具连接MySQL
mysql -u root -p - 修改root用户口令
set global validate_password_policy=0;
set global validate_password_length=6;
alter user 'root'@'localhost' identified by '123456';
安装Python3
- 安装依赖项
yum install -y zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel - 下载Python3源代码
wget https://www.python.org/ftp/python/3.7.6/Python-3.7.6.tar.xz - 解压缩和解归档
xz -d Python-3.7.6.tar.xz
tar -xvf Python-3.7.6.tar - 执行安装前的配置
cd Python-3.7.6
./configure --prefix=/usr/local/python37 --enable-optimizations - 构建和安装
make && make install - 注册环境变量
vim ~/.bash_profile
PATH=$PATH:/usr/local/python37/bin
export PATH
安装Redis:
下载Redis官方源代码
wget http://download.redis.io/releases/redis-5.0.7.tar.gz解压缩和解归档
gunzip redis-5.0.7.tar.gz
tar -xf redis-5.0.7.tar构建和安装
cd redis-5.0.7启动Redis服务
redis-server --requirepass 口令 >> redis.log &Redis客户端工具
redis-cli
网络应用的模式:
~ C/S - 客户端/服务器模式
~ B/S - 浏览器/服务器模式
~ P2P - 对等模式URL/URI - 统一资源定位符/统一资源标识符
https://www.baidu.com:443/index.html
https://www.baidu.com:443/img/bd_logo1.pngDNS - 域名服务器(将服务器的域名转换成对应的IP地址)
反向代理 - 代理用户浏览器向服务器发起请求
~ 保护真正的服务器免于直接被攻击
~ 配置负载均衡,将流量分摊到多台服务器上Web服务器 - 处理静态资源 - Nginx / Apache
应用服务器 - uWSGI / Gunicorn
其他服务器
~ 缓存服务器 - Redis
~ 数据库服务器 - MySQL
~ 邮件服务器 - Sendmail
~ 文件服务器 - NFS / FastDFS
~ 消息队列服务器 - RabbitMQ / KafkaHTTP - 超文本传输协议
~ HTTP请求报文
请求行 - GET /path/resource HTTP/1.1
请求头 - 键值对
\r\n
消息体 - 发给服务器的数据
~ HTTP响应报文
响应行 - HTTP/1.1 200 OK
响应头 - 键值对
\r\n
消息体 - 服务器返回的数据
CPython - C语言实现的Python解释器
Jython - Java实现的Python解释器
IronPython - C#实现的Python解释器
PyPy - Python实现的Python解释器 - JIT
Anaconda - 不仅有Python解释器还有诸多三方库
配置PATH环境变量保证在命令行模式下
Python解释器和相关工具在任何路径都能运行
Web应用 - 基于浏览器来使用的应用程序
手机App - 应用中呈现的数据和内容是通过服务端的程序动态生成的
用程序动态生成页面内容
用Python编写服务器端的程序,为Web和手机应用生成动态内容
开发效率高 + 生态圈非常繁荣
Django / Flask / Tornado / Sanic / FastAPI
pip install django==2.1.14 -i https://pypi.doubanio.com/simple/
创建并运行Django项目
~ 第一种方式:
- django-admin startproject django1906
- 使用PyCharm打开项目并创建虚拟环境
~ File ---> Settings ---> Project --->
Project Interpreter ---> Add
~ Terminal --->
python -m venv venv / virtualenv
(--python=/usr/bin/python3 venv)
source venv/bin/activate / "venv/Scripts/activate" - 安装项目所需依赖项
pip install django==2.1.15 - 运行项目
~ python manage.py runserver
~ Add Configuration --> + --> Python
--> Script Path (manage.py)
--> Parameters (runserver)
~ 第二种方式:
- 用PyCharm创建一个普通的Python项目
- 安装Django所需的依赖项
~ pip install django==2.1.14 - 把Python项目变成Django项目
~ django-admin startproject django1906 . - 运行项目
~ 第三种方式:
- 克隆项目到本地
~ 使用PyCharm的"get from version control"
~ git clone [email protected]:jackfrued/django1906.git - 创建虚拟环境
~ Linux/macOS: source venv/bin/activate
~ Windows: "venv/Scripts/activate" - 重建依赖项
~ pip install -r requirements.txt
GitLab ---> Git私服
对本地代码实施版本控制并同步到版本控制服务器
- git init ---> 将普通文件夹变成版本仓库
- git add . ---> 将文件从工作区同步到暂存区
- git commit -m '...' ---> 将文件提交到本地仓库
- git status / git log
- git remote add origin
---> 绑定远端仓库 - git push -u origin master ---> 将本地代码推到服务器
DDL --> create drop alter
DML --> insert delete update
DQL --> select
DCL --> grant revoke
-- 创建数据库
create database django1906 default charset utf8;
-- 创建用户
create user 'jackfrued'@'%' identified by '123456';
-- 给用户授权
grant all privileges on django1906.* to 'jackfrued'@'%';
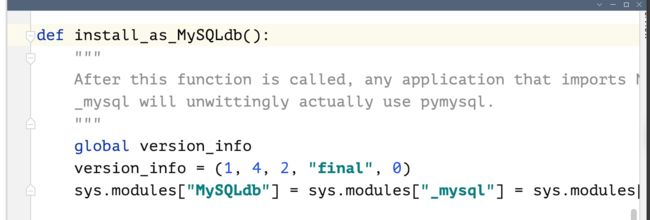
如果要在django2.2版本以上使用pymysql
需要在init中添加pymysql代码之后然后改源代码

高内聚 低耦合
high cohesion low coupling
项目架构模式:MVC架构模式
数据和显示分离(模型和视图解耦合)
同一个模型可以渲染成不同的视图,同一个视图可以加载不同的模型
Model - View - Controller
模型 视图 控制器
数据 数据的显示
Model - Template - View
模型 模板 视图(一部分控制器)
创建应用
~ python manage.py startapp 应用名字
~ django-admin startapp 应用名字
Django框架本身扮演了一部分控制器的角色
views.py - 控制器
~ 接收用户的请求,验证用户请求
~ 操作模型
~ 产生响应(渲染页面)
Django ORM框架
对象关系映射框架 - 解决对象模型到关系模型双向转换问题
Fruit ---> fruit ---> fruit.save()
---> fruit.delete()
cursor.execute('insert into tb_fruit values (%s, %s)')
INSTALLED_APPS = [
.....
'polls',
]
python manage.py makemigrations polls
python manage.py migrate
insert into tb_subject (name, intro) values
('Python+人工智能', 'Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。'),
('JavaEE+分布式', 'Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程。'),
('HTML5+跨平台', 'HTML5是构建Web内容的一种语言描述方式。HTML5是互联网的下一代标准,是构建以及呈现互联网内容的一种语言方式.被认为是互联网的核心技术之一。HTML产生于1990年,1997年HTML4成为互联网标准,并广泛应用于互联网应用的开发。');
创建Django后台超级管理员账号
python manage.py createsuperuser
http://127.0.0.1:8000/admin
{% load staticfiles %}
{% static 静态资源 %}
Ajax - Asynchronous JavaScript and XML
YAML
JSON - JavaScript Object Notation
{
"from": "Jack",
"to": "Tom",
"content": "Hello, world!"
}
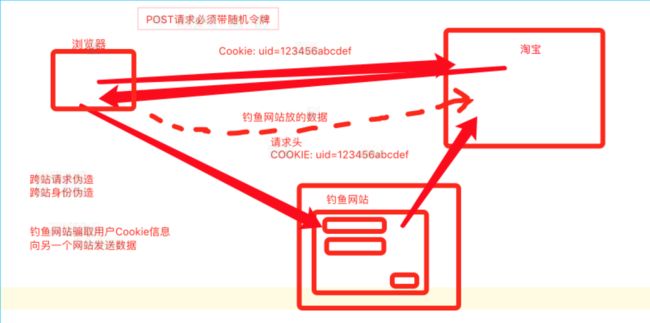
CSRF ---> 跨站请求伪造 ---> {% csrf_token %}
Cross Site Request Forge
HTTP协议是无连接状态协议 --->两次请求之间不会保存用户的任何数据
再次请求服务器的时候 服务器无法得知请求来自哪个用户的请求
一般情况下服务器应用都需要记住用户来为用户提供更好的服务
要记住用户有三种辅助方式:(用户跟踪)
1.URL重写 http://www.baidu.com/uid=xxxxxx
2.隐藏域(影视表单域) --> 埋点

3.浏览器本地存储
cookie - 浏览器中的临时文件可以保存键值对
cookie 中的数据在发起HTTP请求式 会自动加载请求头中
window.localStorage / window.sessionStorage
cookie和sisson的关系
request.session --->服务器内存中的一个对象
cookie --> 用户浏览器临时文件 -->cookie中保存了sisson的ID
csfr跨站请求

非ASCII字符以及特殊字符都不能出现在URL中

加密解密 rsa / aes
编码解码 base64 / 百分号编码
from urllib.parse import quote
编码
result = quote(字符串)
解码
result = unquote(百分号字符)
摘要签名 md5 sha1 sha256 sha512
pycharm 取消双击shift
1、按ctrl+shift+a,弹出搜索框
2、输入registry,然后按回车
3、找到“ide.suppress.double.click.handler”,将后面的复选框勾上
4、勾选上复选框后直接点击close,然后双击shift的时候就不会再出现全局搜索框了
可以将错误的日志写进指定的文件

如果空文件夹想纳入版本控制,直接在目录中添加一个无意义的.gitkeep文件就行,默认版本控制不会加入空文件夹
strftime() -- 时间格式化
vue中的过滤器

? : 写法是vue中的三元操作符
vue中阻止时间默认行为
orderdict -- 有序字典
类.object.filter(条件).only(字段) -- 查询的时候指定字段
类.object.filter(条件).defer(字段) -- 查询的时候排除字段
在标签中加入v-cloak
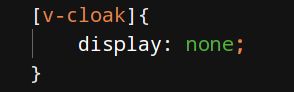
可以让数据没加载出来的时候不显示标签源码
利用redis做缓存,利用延迟同步的原理,先将数据存到redis,最后以周期同步的方式更新到数据库


mysql给相应权限

安装django_debug-toobar流程


pycharm删除依赖项
RESTful
数据反向工程--表转模型
python manage.py inspectdb > common/models.py --- 将数据库中的表转化到common应用中的models.py文件中
实体 --> 数据 --> 数据接口 --> 网络API(HTTP/HTTPS)
REST架构 --> RESTful API --> 无状态、幂等性
REpresentational State Transfer ---> 表述性状态转移
最适合互联网应用的架构
水平扩展 ---> 单机结构 ---> 多机结构(分布式集群)
HTTP --> 无连接无状态
URL --> Universal Resource Locator --> 资源
HTTP协议 请求行 GET/POST/DELETE/PUT/PATCH
新建 - POST
查看 - GET
更新 - PUT / PATCH
删除 - DELETE
设计URL --> 名词
查询数据库为空的数据
多对一、一对多的优化筛选

改变全局下载路劲:
在C:\Users\Administrator 目录下创建pip文件夹
在pip文件夹中创建一个pip.ini文件
文件中写入
[global]
index-url=https://pypi.doubanio.com/simple
保存搞定
创建序列化器的时候筛选
class DistrictSimpleSerializer(serializers.ModelSerializer):
class Meta:
model = District
# 需要序列化的
fields = ('distid', 'name')
# 不需要序列化的用exclude
# 查询所有用fields=(__all__)
创建类view接口
1.先创建序列器
2.在view中创建视图类

3.配置路径
优化view类中的筛选机制(类的继承,实现一个类同时完成查多和查一)
1.创建序列器(在需要的字段相同的情况下只用建造一个)
class EstateView(ListAPIView, RetrieveAPIView):
queryset = Estate.objects.all()
serializer_class = EstateSimpleSerializer
def get(self, request, *args, **kwargs):
if 'pk' in kwargs:
return RetrieveAPIView.get(self, request, *args, **kwargs)
else:
return ListAPIView.get(self, request, *args, **kwargs)
路劲配置(局部路径)
urlpatterns = [
path('districts/', get_provinces),
path('districts//', get_cities),
path('estates/', EstateView.as_view()),
path('estates/', EstateView.as_view()),
path('agents/', show_agent)
多重继承实现增删改查全接口
序列器部分
为了实现不同的请求通过不同的序列器需要增加多个序列器
class EstateSimpleSerializer(serializers.ModelSerializer):
class Meta:
model = Estate
fields = ('estateid', 'name', 'hot', 'intro')
class EstatePostSerializer(serializers.ModelSerializer):
class Meta:
model = Estate
exclude = ('agents',)
view中的代码部分:
class EstateView(ListAPIView, RetrieveAPIView, CreateAPIView, DestroyAPIView):
queryset = Estate.objects.all().defer('district', 'agents')
def get_serializer_class(self):
if self.request.method == 'POST':
return EstatePostSerializer
else:
return EstateSimpleSerializer
def get(self, request, *args, **kwargs):
if 'pk' in kwargs:
return RetrieveAPIView.get(self, request, *args, **kwargs)
else:
return ListAPIView.get(self, request, *args, **kwargs)
用RetrieveUpdateDestroyAPIView方法实现增删改查全接口
class EstateView(ListCreateAPIView,RetrieveUpdateDestroyAPIView):
queryset = Estate.objects.all().defer('district', 'agents')
def get_serializer_class(self):
if self.request.method in ('POST','PUT','PATCH'):
return EstatePostSerializer
else:
return EstateSimpleSerializer
def get(self, request, *args, **kwargs):
if 'pk' in kwargs:
return RetrieveAPIView.get(self, request, *args, **kwargs)
else:
return ListAPIView.get(self, request, *args, **kwargs)
requests请求接口
import json
import requests
resp = requests.get('http://localhost:8000/api/estates/')
estates = json.loads(resp.text)
for index, estate in enumerate(estates):
print(index, estate)
利用ModelViewSet创建视图集
增删改查全套
class HouseTypeViewSet(ModelViewSet):
queryset = HouseType.objects.all()
serializer_class = HouseTypeSerializer
只能读
class HouseTypeViewSet(ReadOnlyModelViewSet):
queryset = HouseType.objects.all()
serializer_class = HouseTypeSerializer
局部路劲配置
# 创建路由器
router = SimpleRouter()
# 注册视图集(这里路径不能加/,路由器会自动加)
router.register('housetypes', HouseTypeViewSet)
# 最后把注册好的路径列表和原列表合并
urlpatterns += router.urls
创建全局分页
setting中修改REST的配置
# 给REST_FRAMEWORK增加配置,添加分页功能
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 5,
}
如果不想被全局分页影响修改视图中的pagination_class
class HouseTypeViewSet(ModelViewSet):
queryset = HouseType.objects.all()
serializer_class = HouseTypeSerializer
# 修改默认不分页就不被全局分页所影响
pagination_class = None
给view视图集增加缓存功能
1.在类继承的多是多继承一个CacheResponseMixin
class EstateView(CacheResponseMixin, ListCreateAPIView, RetrieveUpdateDestroyAPIView):
queryset = Estate.objects.all().defer('district', 'agents')
def get_serializer_class(self):
if self.request.method in ('POST', 'PUT', 'PATCH'):
return EstatePostSerializer
else:
return EstateSimpleSerializer
def get(self, request, *args, **kwargs):
if 'pk' in kwargs:
return RetrieveAPIView.get(self, request, *args, **kwargs)
else:
return ListAPIView.get(self, request, *args, **kwargs)
2.在setting中增加一个配置代码
# 配置混入类,增加是视图集缓存功能
REST_FRAMEWORK_EXTENSIONS = {
'DEFAULT_CACHE_RESPONSE_TIMEOUT': 120,
'DEFAULT_USE_CACHE': 'default',
'DEFAULT_OBJECT_CACHE_KEY_FUNC': 'rest_framework_extensions.utils.default_object_cache_key_func',
'DEFAULT_LIST_CACHE_KEY_FUNC': 'rest_framework_extensions.utils.default_list_cache_key_func',
}
=========================================================
Django中利用method_decorator装饰器可以加在类上,指定什么装饰器装在什么方法上
待更新!
通过接口筛选数据
1.手写代码:

2.利用django-filter三方库
1)先安装:pip install django-filter
2)将django_filters添加到settings.py中的INSTALLED_APPS中
OrderingFilter -- 排序(可以不加)
filter_fields -- 通过什么筛选(后面跟元组形式)
ordering_fields -- 通过哪些字段排序
3)
class EstateView(CacheResponseMixin, ListCreateAPIView, RetrieveUpdateDestroyAPIView):
queryset = Estate.objects.all().defer('agents')
filter_backends = (DjangoFilterBackend, OrderingFilter)
filter_fields = ('district',)
ordering_fields = ('hot', 'estateid',)
通过字段范围搜索
1.先申明一个筛选类,可以建一个py文件单独存放
自定义一个类来作为筛选条件
class EstateFilterSet(django_filters.FilterSet):
"""自定义FilterSet"""
minhot = django_filters.NumberFilter(field_name='hot', lookup_expr='gte')
maxhot = django_filters.NumberFilter(field_name='hot', lookup_expr='lte')
keyword = django_filters.CharFilter(method='filter_by_keyword')
@staticmethod
def filter_by_keyword(queryset, key, value):
queryset = queryset.filter(Q(name__contains=value) |
Q(intro__startswith=value))
return queryset
在视图集类中加入
class EstateView(CacheResponseMixin, ListCreateAPIView, RetrieveUpdateDestroyAPIView):
queryset = Estate.objects.all().defer('agents')
# 筛选
filter_backends = (DjangoFilterBackend, OrderingFilter)
# filter_fields = ('district',)
# 通过自定义的筛选类来筛选
filterset_class = EstateFilterSet
# 排序
ordering_fields = ('hot', 'estateid',)
# 加上下面这句就不限流
# throttle_classes = ()
配置限流(全局作用)
在setting中的REST_FRAMWORK配置中加入
# 给REST_FRAMEWORK增加配置,添加分页功能
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 5,
# 限流配置包
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.AnonRateThrottle',
),
'DEFAULT_THROTTLE_RATES': {
'anon': '5/min',
},
}
在视图类中加入throttle_classes = ()就不会限流
查询的时候在输入select_related/prefetch_related 1对多/多对多 的方法来解决查询数据库1+N的问题
写序列化方法满足单独的序列需求
view中:

serializer中:

搜索引擎
倒排索引:Whoosh + jieba
ElasticSearch / Solr + ik-analysis/smartcn/pinyin - 可以支持中文分词的搜索引擎
模糊查询:
需要导入drf中的OrderingFilter
from rest_framework.filters import OrderingFilter
然后再视图类中加入
filter_backends = (DjangoFilterBackend, OrderingFilter) - 筛选类/排序类
filterset_class = 你定制的筛选类
定制的筛选类需要先导入django_filters
视图中:
class HouseInfoViewSet(ReadOnlyModelViewSet):
"""房源只读视图集"""
# 查询集
queryset = HouseInfo.objects.all()\
.defer('detail', 'hassubway', 'isshared',
'hasagentfees', 'userid', 'distid2', 'agent')\
.select_related('type', 'estate')\
.prefetch_related('tags')
# 指定你的序列器
serializer_class = HouseInfoSerializer
# 指定你的筛选类
filter_backends = (DjangoFilterBackend, OrderingFilter)
# 自定义你的筛选方法
filterset_class = HouseInfoFilterSet
# 指定你的排序字段
ordering = ('-pubdate', 'houseid')
ordering_fields = ('price', 'area')
声明的筛选器
# 声明筛选类
class HouseInfoFilterSet(django_filters.FilterSet):
# 通过title来模糊查询
title = django_filters.CharFilter(lookup_expr='contains')
# 最低价格小于等于(如果表中没有title字段需要用field_name重新指定)
minprice = django_filters.NumberFilter(field_name='price', lookup_expr='gte')
maxprice = django_filters.NumberFilter(field_name='price', lookup_expr='lte')
# 通过Q对象自己写筛选方法,method=方法名
district = django_filters.NumberFilter(method='filter_by_district')
#自定义筛选静态方法
@staticmethod
def filter_by_district(queryset, key, value):
return queryset.filter(Q(distid2=value) |
Q(distid3=value))
重写序列器的get方法返回需求的序列数据
class HouseInfoSerializer(serializers.ModelSerializer):
"""房源序列器"""
# 声明要重写的序列字段
pubdate = serializers.SerializerMethodField()
type = serializers.SerializerMethodField()
estate = serializers.SerializerMethodField()
tags = serializers.SerializerMethodField()
district = serializers.SerializerMethodField()
# 利用静态方法重新处理字段并返回
@staticmethod
def get_pubdate(obj):
return obj.pubdate.strftime('%Y--%m--%d')
# 如果是ForeignKey的字段obj.属性取到的是关联对象,需要用.方法调用属性
@staticmethod
def get_type(obj):
return obj.type.name
@staticmethod
def get_estate(obj):
return obj.estate.name
# 如果是多对多,manytomany需要用obj.属性.查询方法()返回queryset对象,然后再作处理
@staticmethod
def get_tags(obj):
return [i.content for i in obj.tags.all()]
# 如果没有关联属性又想取关联的对象需要先用指定参数查询一次返回queryset对象然后再作处理
@staticmethod
def get_district(obj):
data = District.objects.filter(distid=obj.distid3).only('name').first()
return data.name
富文本编辑器 - 可以排版、可以插入图片音频视频美化代码
Markdown编辑器
国内比较好用的富文本编辑器
wangEditor
kindEditor
软件开发过程模型
1.传统过程模型:大型、超大型项目
-瀑布模型(经典模型):
1)可行性分析(研究做还是不做)=> 可行性分析报告
2)需求分析(研究做什么)=> {
头脑风暴 => 思维导图 => 需求规格说明书
产品原型图 => Azure RP => 线框图/高保真原型
}
3)概要设计和详细设计
数据库设计 => E-R图 => 物理模型图 <= PowerDesigner
物理模型图
面向对象设计(OOAD)=> UML => 类图
is-a:继承
has-a:关联=>聚合/合成
use-a:依赖
类图
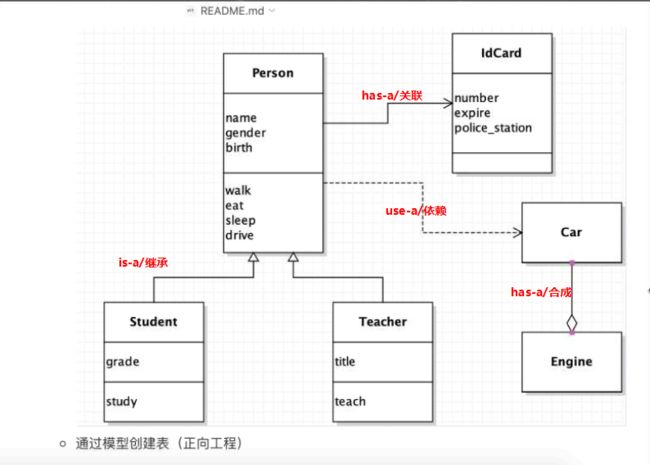
4)编码
5)测试(单元->系统->集成->验收)
6)交付(上线)+运维
缺点:周期慢,不能拥抱需求变化
2.敏捷模型:迅速推出产品占领市场
核心理念:增量迭代式开发
SCRUM(将软件开发分为若干个冲刺周期) - Spring Cycle
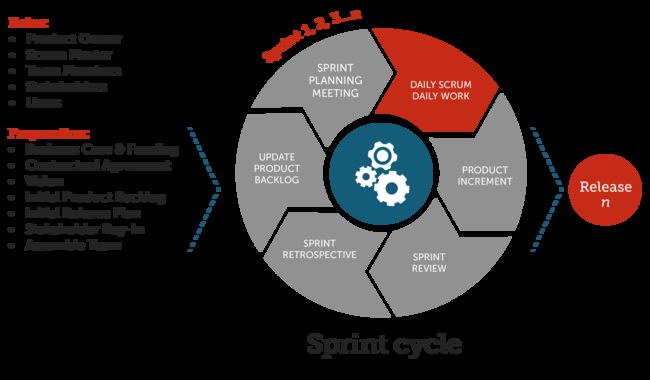
1)建立或更新需求池 -> 用户故事(User Story / Epic) --> 看板
- 计划会议(评估需求)
- 日常开发(站立会议、番茄工作法)
4)版本发布
5)评审会议(show case) - 回顾会议 (总结得失)
时长:2-4周
敏捷闭环工具 - JIRA/禅道
团队协作工具 - 钉钉/TeamBition
版本控制 - 团队开发模式下如何使用Git
Git私服 => GitLab
Git便准工作流程:
git-flow
github-flow(PR流程)
流程
1.克隆或者更新项目
git clone URL
git pull
2.基于master分支创建自己的分支
git branch Name
git checkout Name / git swich Name
git checkout -b Name /git switch -C Name (同时完成建立和切换分支)
3.在自己的分支上做开发并实施版本控制
4.把自己的分支推到服务器上
git push -u origin Name
5.在线发起合并请求(线上操作),请求将工作成果合并到master分支
git branch -d/-D 分支名 (删除分支,-D强删除,删除之前切换到master分支)
git diff - 版本比较
gitlab-flow
调用三方服务的两种方式:
1.API调用 => 通过Http协议请求URL的方式获得服务(数据)
短信、地图、天气 、个人认证、企业认证、物流
短信网关:云片、SendCloud、螺丝帽
2.SDK调用 => 安装对应的库文件,使用封装好的类、函数来调用服务
pip install alipay-sdk-python 阿里云支付
pip install qiuniu 青牛存储
pip install oss2 阿里云对象存储
JWT - Json Web Token - 生成用户身份令牌的方式
优点:JWT无法伪造、也无法篡改令牌中包含的用户信息
保存在用户浏览器端,服务器没有任何储存开销,便于水平扩展
事务上下文环境,要么全成功,要么全失败
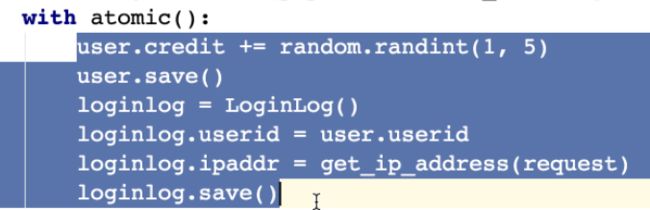
@atomic() => 事务装饰器
命名关键字参数
在传参数的时候必须传关键字参数
函数的参数前面加*
def function(*,x,y):
pass
解决富文本在html中源码显示问题
在vue中,将html的标签加上v-html='内容' 可以告诉内容为html格式
将项目部署上线
1.在项目的setting.py中加入下面代码:
# 保持HTTPS连接的时间
# SECURE_HSTS_SECONDS = 3600
# SECURE_HSTS_INCLUDE_SUBDOMAINS = True
# SECURE_HSTS_PRELOAD = True
# 自动重定向到安全连接
# SECURE_SSL_REDIRECT = True
# 避免浏览器自作聪明推断内容类型
# 防范跨站脚本攻击,浏览器会自己分辨文件内容,不管后缀名,就算是恶意代码也会执行
SECURE_CONTENT_TYPE_NOSNIFF = True
# 避免跨站脚本攻击
SECURE_BROWSER_XSS_FILTER = True
# COOKIE只能通过HTTPS进行传输
# SESSION_COOKIE_SECURE = True
# CSRF_COOKIE_SECURE = True
# 防止点击劫持攻击手段 - 修改HTTP协议响应头
# 当前网站是不允许使用
webSocket(全双工)
django中使用websocket
安装
pip install channels
配置
先在INSTALLED_APPS中加入
然后加上一个配置
ASGI_APPLICATION = 'webapp.routing.application'
在需要的app下新建一个routing.py文件
from django.urls import path
from chatroom.views import ChatConsumer
websocket_urlpatterns = [
path('ws/chat/', ChatConsumer),
]
在项目的(与settings同级)目录下新建一个routing.py
from channels.auth import AuthMiddlewareStack
from channels.routing import ProtocolTypeRouter, URLRouter
from chatroom.routing import websocket_urlpatterns
# 固定写法
# 创建application对象,协议路由
application = ProtocolTypeRouter({
# 如果是websocket走哪
'websocket': AuthMiddlewareStack(
URLRouter(
# 指定从哪个路由
websocket_urlpatterns
)
),
})
在视图函数或者新建一个consumer.py中新建一个类
如果视图函数中代码比较多,最好还是新建一个文件
from channels.generic.websocket import WebsocketConsumer
# Create your views here.
# 定义类
class ChatConsumer(WebsocketConsumer):
# 这三个方法都是回调方法
# 建连接要干嘛
def connect(self):
# 接受连接,这句必加
self.accept()
print('跟浏览器建立了长连接')
# 断连接要干嘛
def disconnect(self, code):
print('连接已经断开')
# 发消息要干嘛
def receive(self, text_data=None, bytes_data=None):
print(text_data)
# 如果浏览器发送的二进制消息:bytes_data
# self.send就是主动给服务器发消息
self.send('收到了你的消息!')
最后是前端代码
websocket测试
websocket测试
主动发消息
先装三方库
pip install channels_redis
待更新
需要配置反向代理
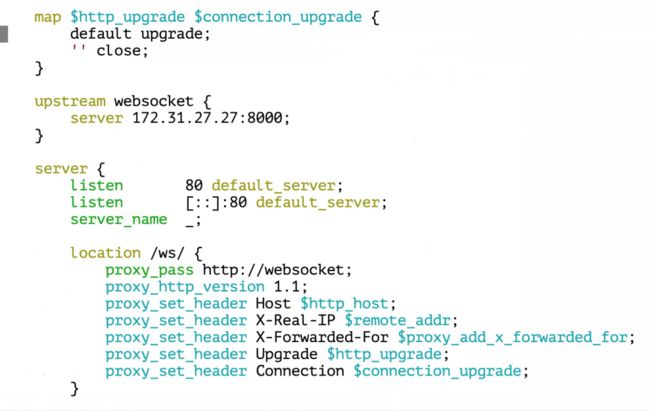 image.png
image.png
自动化运维服务管理
Supervisor
Circus
数据结构和算法
数据结构:数据再计算中如何储存
离散存储
连续存储
算法:解决问题的步骤
渐近时间复杂度
渐进空间复杂度
python自带小根堆结构
heapq模块
解决top_k问题
In [1]: import heapq
In [2]: items = [64,23,51,64,7,5,86,34,2,34,98]
In [3]: heapq.nlargest(3,items)
Out[3]: [98, 86, 64]
In [4]: heapq.nsmallest(5,items)
Out[4]: [2, 5, 7, 23, 34]
cookbook需要看的章节
1,2,4,7,8,9,12