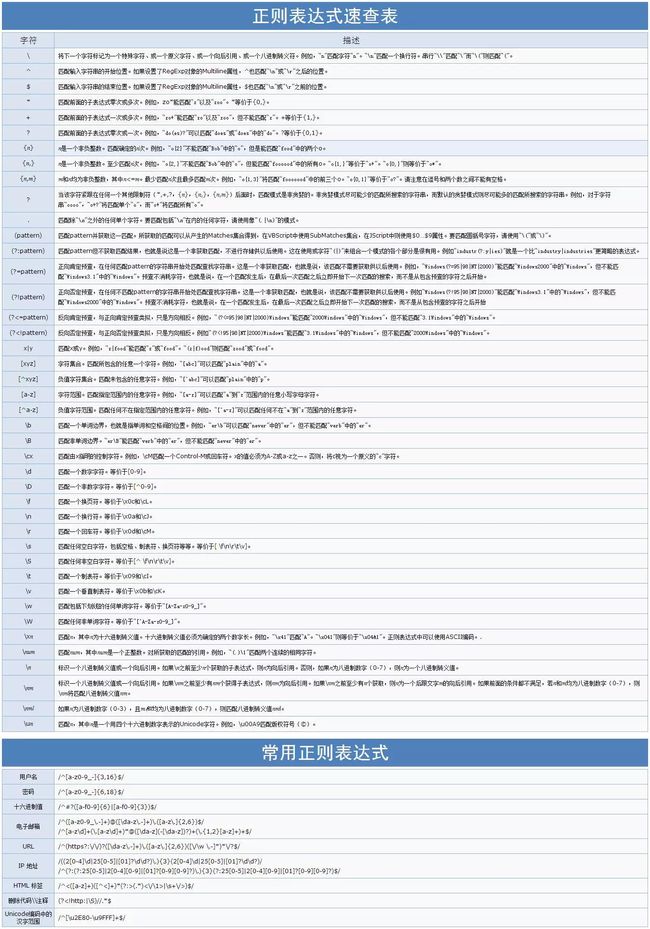
R语言在提取字符串上有着强大的能力,其中字符串可以看做为文本信息。今天需要跟大家介绍一款更为通用、更加底层的文本信息提取工具——正则表达式。
所谓正则表达式,即使用一个字符串来描述、匹配一系列某个语法规则的字符串。通过特定的字母、数字以及特殊符号的灵活组合即可完成对任意字符串的匹配,从而达到提取相应文本信息的目的。在R语言中,有两种风格的正则表达式可以实现,一种就是在基本的正则表达式基础上进行扩展,这和相应的R字符串处理函数相关,另一种就是Perl正则表达式,这种风格的正则我们在R中一般不常用,本文主要还是针对R默认的基础的正则表达式风格进行讲解。
正则表达式是对字符串类型数据进行匹配判断,提取等操作的一套逻辑公式。
处理字符串类型数据方面,高效的工具有Perl和Python。如果我们只是偶尔接触文本处理任务,则学习Perl无疑成本太高;如果常用Python,则可以利用成熟的正则表达式模块:re库;如果常用R,则使用Hadley大神开发的stringr包则已经能够游刃有余。
下面,我们先简要介绍重要并通用的正则表达式规则。接着,总结一下stringr包中重要的字符处理函数。
元字符
正则表达式中,有12个字符被保留用作特殊用途。他们分别是:
[ ] \ ^ $ . | ? * + ( )
它们的作用如下:
[ ]:括号内的任意字符将被匹配;-
\:具有两个作用:- 1.对元字符进行转义
- 2.一些以
\开头的特殊序列表达了一些字符串组
^:匹配字符串的开始.将^置于character class的首位表达的意思是取反义。如[^5]表示匹配除了”5”以外的任何字符。$:匹配字符串的结束。但将它置于character class内则消除了它的特殊含义。如[akm$]将匹配’a’,’k’,’m’或者’$’..:匹配除换行符以外的任意字符。|:或者?:前面的字符(组)最多被匹配一次*:前面的字符(组)将被匹配零次或多次+:前面的字符(组)将被匹配一次或多次( ):表示一个字符组,括号内的字符串将作为一个整体被匹配。
重复
| 代码 | 含义说明 |
|---|---|
? |
重复零次或一次 |
* |
重复零次或多次 |
+ |
重复一次或多次 |
{n} |
重复n次 |
{n,} |
重复n次或更多次 |
{n,m} |
重复n次到m次 |
转义
如果我们想查找元字符本身,如”?”和”*“,我们需要提前告诉编译系统,取消这些字符的特殊含义。这个时候,就需要用到转义字符\,即使用\?和\*.当然,如果我们要找的是\,则使用\\进行匹配。
注:R中的转义字符则是双斜杠:\\
R中预定义的字符组
| 代码 | 含义说明 |
|---|---|
[:digit:] |
数字:0-9 |
[:lower:] |
小写字母:a-z |
[:upper:] |
大写字母:A-Z |
[:alpha:] |
字母:a-z及A-Z |
[:alnum:] |
所有字母及数字 |
[:punct:] |
标点符号,如. , ;等 |
[:graph:] |
Graphical characters,即[:alnum:]和[:punct:] |
[:blank:] |
空字符,即:Space和Tab |
[:space:] |
Space,Tab,newline,及其他space characters |
[:print:] |
可打印的字符,即:[:alnum:],[:punct:]和[:space:] |
代表字符组的特殊符号
| 代码 | 含义说明 |
|---|---|
\w |
字符串,等价于[:alnum:] |
\W |
非字符串,等价于[^[:alnum:]] |
\s |
空格字符,等价于[:blank:] |
\S |
非空格字符,等价于[^[:blank:]] |
\d |
数字,等价于[:digit:] |
\D |
非数字,等价于[^[:digit:]] |
\b |
Word edge(单词开头或结束的位置) |
\B |
No Word edge(非单词开头或结束的位置) |
\< |
Word beginning(单词开头的位置) |
\> |
Word end(单词结束的位置) |
stringr包中的重要函数
| 函数 | 功能说明 | R Base中对应函数 |
|---|---|---|
| 使用正则表达式的函数 | ||
str_extract() |
提取首个匹配模式的字符 | regmatches() |
str_extract_all() |
提取所有匹配模式的字符 | regmatches() |
str_locate() |
返回首个匹配模式的字符的位置 | regexpr() |
str_locate_all() |
返回所有匹配模式的字符的位置 | gregexpr() |
str_replace() |
替换首个匹配模式 | sub() |
str_replace_all() |
替换所有匹配模式 | gsub() |
str_split() |
按照模式分割字符串 | strsplit() |
str_split_fixed() |
按照模式将字符串分割成指定个数 | - |
str_detect() |
检测字符是否存在某些指定模式 | grepl() |
str_count() |
返回指定模式出现的次数 | - |
| 其他重要函数 | ||
str_sub() |
提取指定位置的字符 | regmatches() |
str_dup() |
丢弃指定位置的字符 | - |
str_length() |
返回字符的长度 | nchar() |
str_pad() |
填补字符 | - |
str_trim() |
丢弃填充,如去掉字符前后的空格 | - |
str_c() |
连接字符 | paste(),paste0() |
可见,stringr包中的字符处理函数更丰富和完整(其实还有更多函数),并且更容易记忆。或许速度也会更快。
其他相关的重要函数
windows下处理字符串类型数据最头疼的无疑是编码问题了。这里介绍几个编码转换相关的函数。
| 函数 | 功能说明 |
|---|---|
iconv() |
转换编码格式 |
Encoding() |
查看编码格式;或者指定编码格式 |
tau::is.locale() |
tests if the components of a vector of character are in the encoding of the current locale |
tau::is.ascii() |
|
tau::is.utf8() |
tests if the components of a vector of character are true UTF-8 strings |
R默认的正则表达式风格包括基础文本处理函数和stringr包中的文本处理函数。在R中二者都支持正则表达式,也都具备基本的文本处理能力,但基础函数的一致性要弱很多,在函数命名和参数定义上很难让人印象深刻。stringr包是Hadley Wickham开发了一款专门进行文本处理的R包,它对基础的文本处理函数进行了扩展和整合,在一致性和易于理解性上都要优于基础函数。本文在介绍基本的正则表达式语法的基础上,通过R中这两种文本处理函数进行实例说明,也好让大家对R语言中正则表达式的基本用法有个大致了解,在后续的爬虫演练中更容易理解一些信息提取的细节知识。
基本的正则表达式语法
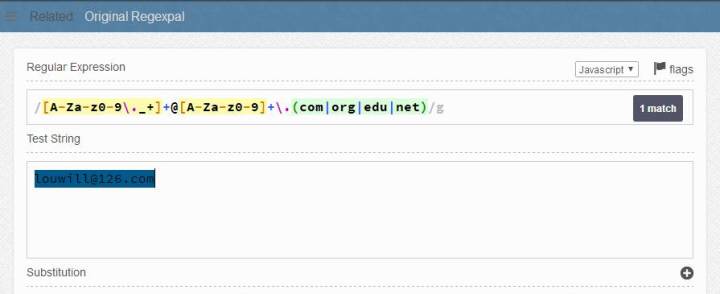
实际应用中正则表达式的一个比较经典的使用场景是识别电子邮箱地址。一个正常的电子邮箱账户应该由下面几部分构成:任意字符、数字和符号组成的用户名+@+.+com/net等域名。根据正则表达式的语法规则,我们就可以由这几部分写出邮箱账户的正则表达式:
[A-Za-z0-9._+]+@[A-Za-z0-9]+.(com|org|edu|net)
其中:
[A-Za-z0-9._+]+:A-Z表示匹配任意的A-Z大写字母,所有可能的组合放在中括号里表示可以匹配其中的任一个,加号表示任意字符可以出现1次或者多次,\表示转义,因为.在正则表达式中有特殊含义,想要正常的表达.号必须使用转义符。
@:邮箱必须的一个符号。
[A-Za-z0-9]:同前面一样,@符号后面必须有一个包含运营商信息的字符串。
.:邮箱地址中必须要有的一个点号。
(com|org|edu|net):列出邮箱地址可能的域名系统,括号内表示分组处理,|符号表示或的含义。
另外也有一些在线测试正则表达式的网页,大家可以拿来练手,小编这里也推荐一个:
https://www.regexpal.com/
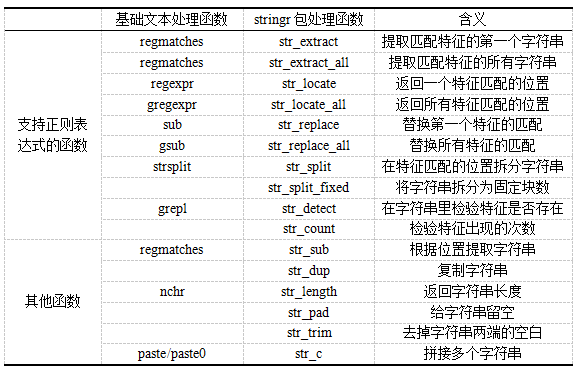
R中基础文本处理函数和stringr包文本处理函数对于正则表达式的支持情况如下表所示:
基础文本处理函数中正则表达式的应用
R中常用的支持正则表达式的基础文本处理函数包括grep/grepl、sub/gsub、regexpr/gregexpr等。
example_text1 <- c("23333#RRR#PP","35555#CCCC","louwill#2017")
- 以#进行字符串切分
unlist(strsplit(example_text1, "#"))
[1] "23333" "RRR" "PP" "35555" "CCCC" "louwill" "2017"
- 以空字符集进行字符串切分
unlist(strsplit(example_text1, "\\s"))
[1] "23333#RRR#PP" "35555#CCCC" "louwill#2017"
- 以空字符替换字符串第一个#匹配
sub("#","", example_text1)
[1] "23333RRR#PP" "35555CCCC" "louwill2017"
- 以空字符集替换字符串全部#匹配
gsub("#","",example_text1)
[1] "23333RRRPP" "35555CCCC" "louwill2017"
- 查询字符串中是否存在3333或5555的特征并返回所在位置
grep("[35]{4}", example_text1)
[1] 1 2
- 查询字符串中是否存在3333或5555的特征并返回逻辑值
grepl("[35]{4}", example_text1)
[1] TRUE TRUE FALSE
- 返回匹配特征的字符串
pattern <- "[[:alpha:]]*(,|#)[[:alpha:]]"
m <- regexpr(pattern, example_text1)
regmatches(example_text1, m)
[1] "#R" "#C"
stringr包文本处理函数中的正则表达式的应用
stringr包一共为我们提供了30个字符串处理函数,其中大部分均可支持正则表达式的应用,包内所有函数均以str_开头,后面单词用来说明该函数的含义,相较于基础文本处理函数,stringr包函数更容易直观地理解。本文仅以str_extract和str_extract_all函数为例,对stringr包的正则表达式应用进行简要说明。
example_text2 <- "1\. A small sentence. - 2\. Another tiny sentence."
library(stringr)
- 提取small特征字符
str_extract(example_text2, "small")
[1] "small"
- 提取包含sentence特征的全部字符串
unlist(str_extract_all(example_text2, "sentence"))
[1] "sentence" "sentence"
- 提取以1开始的字符串
str_extract(example_text2, "^1")
[1] "1"
- 提取以句号结尾的字符
unlist(str_extract_all(example_text2, ".$"))
[1] "."
- 提取包含tiny或者sentence特征的字符串
unlist(str_extract_all(example_text2, "tiny|sentence"))
[1] "sentence" "tiny" "sentence"
- 点号进行模糊匹配
str_extract(example_text2, "sm.ll")
[1] "small"
- 中括号内表示可选字符串
str_extract(example_text2, "sm[abc]ll")
[1] "small"
str_extract(example_text2, "sm[a-p]ll")
[1] "small"
对于特定的字符我们可以手动指定,比如[a-z A-Z]表示a-z和A-Z之间的所有字母,但R预先定义了一些字符集方便大家调用,如下表所示。

str_extract(example_text2, "([[:alpha:]]).+?\\1")
[1] "A small sentence. - 2\. A"
除此之外,R中正则表达式的应用还有若干简化的形式,它被分配给几个特定的字符类,如下表所示:
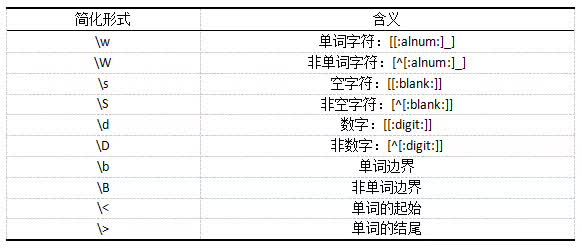
- 提取全部单词字符
unlist(str_extract_all(example_text2, "\\w+"))
[1] "1" "A" "small" "sentence" "2" "Another" "tiny"
[8] "sentence"
前言
在数据预处理阶段用的比较多的是dplyr包、reshape2包和tidyr,但字符串处理也是必不可少的。虽然R语言的基础包本身有着基本的字符处理能力,但使用起来并不是很方便。为此,今天我们学习stringr包。该包极大的简化了R语言中字符串的转换,搜索,辨识,定位,匹配,替换,提取,分离等操作。同时封装了一些R语言中原来繁琐的字符串操作函数,但本章的重点是正则表达式(regular expression, regexp)。正则表达式的用处非常大,字符串通常包含的是非结构化或半结构化数据,正则表达式可以用简练的语言来描述字符串中的模式。
10.1 字准备工作
library(tidyverse)
library(stringr)
10.2 字符串基础
# 创建字符串
string1 <- "This is a string"
string2 <- 'To put a "quote" inside a string, use single quotes'
如果想要在字符串中包含一个单引号或双引号,可以使用 \ 对其进行“转义”
double_quote <- "\""
single_quote <- '\''
10.2.1 字符串长度
以 str_ 开头的。例如, str_length() 函数可以返回字符串中的字符数量
str_length(c("a", "R for data science", NA))
10.2.2 字符串组合
str_c("x", "y")
str_c("x", "y", "z")
str_c("x", "y", sep = ", ")
x <- c("abc", NA)
str_c("|-", x, "-|")
# 和多数 R 函数一样,缺失值是可传染的。如果想要将它们输出为 "NA",可以使用 str_replace_na()
str_c("|-", str_replace_na(x), "-|")
str_c() 函数是向量化的,它可以自动循环短向量,使得其与最长的向量具有相同的长度
str_c("prefix-", c("a", "b", "c"), "-suffix")
10.2.3 字符串取子集
str_sub() 函数来提取字符串的一部分。除了字符串参数外, str_sub() 函数中还
有 start 和 end 参数,它们给出了子串的位置(包括 start 和 end 在内)
x <- c("Apple", "Banana", "Pear")
str_sub(x, 1, 3)
#> [1] "App" "Ban" "Pea"
# 负数表示从后往前数,
str_sub(x, -3, -1)#倒数第三个到倒数第一个字符
#> [1] "ple" "ana" "ear"
#注意,即使字符串过短,str_sub() 函数也不会出错,它将返回尽可能多的字符:
str_sub("a", 1, 5)
#> [1] "a"
还可以使用 str_sub() 函数的赋值形式来修改字符串
> x <- c("Apple", "Banana", "Pear")
> a <-str_to_lower(str_sub(x, 1, 1))
> a
[1] "a" "b" "p"
10.2.5 练习
(1) 在没有使用 stringr 的那些代码中,你会经常看到 paste() 和 paste0() 函数,这两个函数的区别是什么? stringr 中的哪两个函数与它们是对应的?这些函数处理 NA 的方式有什么不同?
paste("foo", "bar")
#> [1] "foo bar"
paste0("foo", "bar")
#> [1] "foobar"
str_c("foo", "bar")
#> [1] "foobar"
str_c("foo", NA)
#> [1] NA
paste("foo", NA)
#> [1] "foo NA"
paste0("foo", NA)
#> [1] "fooNA"
(2) 用自己的语言描述一下 str_c() 函数的 sep 和 collapse 参数有什么区别?
(3) 使用 str_length() 和 str_sub() 函数提取出一个字符串最中间的字符。如果字符串中的
字符数是偶数,你应该怎么做?
x <- c("a", "abc", "abcd", "abcde", "abcdef")
L <- str_length(x)
m <- ceiling(L / 2)
str_sub(x, m, m)
#> [1] "a" "b" "b" "c" "c"
(4) str_wrap() 函数的功能是什么?应该在何时使用这个函数?
将文本处理成固定宽度的文本
thanks_path <- file.path(R.home('doc'),'thanks')
thanks <- str_c(readLines(thanks_path),collapse = '\n')
thanks <- word(thanks,1,3,fixed("\n\n"))
cat(str_wrap(thanks),"\n")
(5) str_trim() 函数的功能是什么?其逆操作是哪个函数?
str_trim()去除字符串两边的空格,str_pad()在两边增加空格
str_trim(" abc ")
#> [1] "abc"
str_trim(" abc ", side = "left")
#> [1] "abc "
str_trim(" abc ", side = "right")
#> [1] " abc"
str_pad("abc", 5, side = "both")
#> [1] " abc "
str_pad("abc", 4, side = "right")
#> [1] "abc "
str_pad("abc", 4, side = "left")
#> [1] " abc"
(6) 编写一个函数将字符向量转换为字符串,例如,将字符向量 c("a", "b", "c") 转换为字符串 a、 b 和 c。仔细思考一下,如果给定一个长度为 0、 1 或 2 的向量,那么这个函数应该怎么做?
str_commasep <- function(x, delim = ",") {
n <- length(x)
if (n == 0) {
""
} else if (n == 1) {
x
} else if (n == 2) {
# no comma before and when n == 2
str_c(x[[1]], "and", x[[2]], sep = " ")
} else {
# commas after all n - 1 elements
not_last <- str_c(x[seq_len(n - 1)], delim)
# prepend "and" to the last element
last <- str_c("and", x[[n]], sep = " ")
# combine parts with spaces
str_c(c(not_last, last), collapse = " ")
}
}
str_commasep("")
#> [1] ""
str_commasep("a")
#> [1] "a"
str_commasep(c("a", "b"))
#> [1] "a and b"
str_commasep(c("a", "b", "c"))
#> [1] "a, b, and c"
str_commasep(c("a", "b", "c", "d"))
#> [1] "a, b, c, and d"
10.3 使用正则表达式进行模式匹配
10.3.1 基础匹配
x <- c("apple", "banana", "pear")
str_view(x, "an")
str_view(x, ".a.")
用”.”任意字符匹配(除了换行符):str_view(x, ".a.")
好像是同一个字符串里只匹配一次哦。看banana其实可以匹配到两次
# 要想建立正则表示式,我们需要使用\\
dot <- "\\."
# 实际上表达式本身只包含一个\:
writeLines(dot)
#> \.
# 这个表达式告诉R搜索一个.
str_view(c("abc", "a.c", "bef"), "a\\.c")
x <- "a\\b"
writeLines(x)
#> a\b
str_view(x, "\\\\")
#正则表达式 . 的字符串形式应是 \. 你需要 4 个反斜杠来匹配 1 个反斜杠!
10.3.3 锚点
有时我们需要在正则表达式中设置锚点,以便 R 从字符串的开头或末尾进行匹配。我们可以设置两种锚点。
• ^ 从字符串开头进行匹配。
• $ 从字符串末尾进行匹配。
x <- c("apple", "banana", "pear")
str_view(x, "^a")
str_view(x, "a$")
x <- c("apple pie", "apple", "apple cake")
str_view(x, "apple")
str_view(x, "^apple$")
始于^,终于$
10.3.4 练习
(1) 如何匹配字符串
" ? $$$
str_view(c("$^$", "ab$^$sfas"), "^\\$\\^\\$$")
(2) 给定 stringr::words 中的常用单词语料库,创建正则表达式以找出满足下列条件的所
有单词。
a. 以 y 开头的单词。
b. 以 x 结尾的单词。
c. 长度正好为 3 个字符的单词。(不要使用 str_length() 函数)
d. 具有 7 个或更多字符的单词。
因为这个列表非常长,所以你可以设置 str_view() 函数的 match 参数,只显示匹配的单词(match = TRUE)或未匹配的单词(match = FALSE)。
word <- stringr::words
str_view(word,"^y",match = T)
str_view(word,"x$",match = T)
str_view(word,"^...$",match = T)
str_view(word,".......",match = T)
str_view(word,".......",match = F)
10.3.5 字符类与字符选项
• \d 可以匹配任意数字。
• \s 可以匹配任意空白字符(如空格、制表符和换行符)。
• [abc] 可以匹配 a、 b 或 c。
• [^abc] 可以匹配除 a、 b、 c 外的任意字符。
10.3.6 练习
(1) 创建正则表达式来找出符合以下条件的所有单词。
a. 以元音字母开头的单词。
str_view(word,"^[aeiou]",match = T)
b. 只包含辅音字母的单词(提示:考虑一下匹配“非”元音字母)。
str_view(word,"^[^aeiou]+$",match = T)
c. 以 ed 结尾,但不以 eed 结尾的单词。
str_view(word,"ed$|^[^e]ed$",match = T)
d. 以 ing 或 ize 结尾的单词。
str_view(word,"ing$|ize$",match = T)
str_view(stringr::words, "i(ng|se)$", match = TRUE)
(2) 实际验证一下规则: i 总是在 e 前面,除非 i 前面有 c。
str_view(stringr::words, "(cei|[^c]ie)", match = TRUE)
(3) q 后面总是跟着一个 u 吗?
str_view(stringr::words, "qu", match = TRUE)
(4) 编写一个正则表达式来匹配英式英语单词,排除美式英语单词。
(5) 创建一个正则表达式来匹配你所在国家的电话号码。
x <- c("123-4560-7890", "1235-2351")
str_view(x, "\\d\\d\\d-\\d\\d\\d\\d-\\d\\d\\d\\d")
10.3.7 重复
正则表达式的另一项强大功能是,其可以控制一个模式能够匹配多少次。
• ?: 0 次或 1 次。
• +: 1 次或多次。
• *: 0 次或多次。
x <- "1888 is the longest year in Roman numerals: MDCCCLXXXVIII"
str_view(x, "CC?")
str_view(x, "CC+")
str_view(x, 'C[LX]+')
• {n}:匹配 n 次。
• {n,}:匹配 n 次或更多次。
• {,m}:最多匹配 m 次。
• {n, m}:匹配 n 到 m 次。
str_view(x, "C{2}")
str_view(x, "C{2,}")
str_view(x, "C{2,3}")
默认的匹配方式是“贪婪的”:正则表达式会匹配尽量长的字符串。通过在正则表达式后
面添加一个 ?,你可以将匹配方式更改为“懒惰的”,即匹配尽量短的字符串。
10.3.8 练习
(1) 给出与 ?、 + 和 * 等价的 {m, n} 形式的正则表达式。
? {0,1} + {1,} * {0,}
(2) 用语言描述以下正则表达式匹配的是何种模式(仔细阅读来确认我们使用的是正则表达
式,还是定义正则表达式的字符串)?
a. ^.*$
b. "{.+}"
c. \d{4}-\d{2}-\d{2}
d. "\{4}"
(3) 创建正则表达式来找出满足以下条件的所有单词。
a. 以 3 个辅音字母开头的单词
b. 有连续 3 个或更多元音字母的单词。
c. 有连续 2 个或更多元音—辅音配对的单词。
str_view(stringr::words, "^[^aeiou]{3}",match=T)
str_view(stringr::words, "[aeiou]{3,}",match=T)
str_view(stringr::words, "[aeiou][^aeiou]{2,}",match=T)
括号还可以定义“分组”,你可以通过回溯引用(如 \1、 \2 等)来引用这些分组。
str_view(stringr::words, "(..)\\1", match = TRUE)
10.4.1 匹配检测
x <- c("apple", "banana", "pear")
str_detect(x, "e")
#> [1] TRUE FALSE TRUE
# 有多少个以t开头的常用单词?
sum(str_detect(words, "^t"))
#> [1] 65
# 以元音字母结尾的常用单词的比例是多少?
mean(str_detect(words, "[aeiou]$"))
#> [1] 0.277
str_detect() 函数的一种常见用法是选取出匹配某种模式的元素。你可以通过逻辑取子集方式来完成这种操作,也可以使用便捷的 str_subset() 包装器函数:
words[str_detect(words, "x$")]
#> [1] "box" "sex" "six" "tax"
str_subset(words, "x$")
#> [1] "box" "sex" "six" "tax"
df <- tibble(
word = words,
i = seq_along(word))
df %>%
filter(str_detect(words, "x$"))
str_detect() 函数的一种变体是 str_count(),后者不是简单地返回是或否,而是返回字符
串中匹配的数量:
x <- c("apple", "banana", "pear")
str_count(x, "a")
#> [1] 1 3 1
# 平均来看,每个单词中有多少个元音字母?
mean(str_count(words, "[aeiou]"))
#> [1] 1.99
df %>%
mutate(vowels = str_count(word, "[aeiou]"),
consonants = str_count(word, "[^aeiou]"))
str_count("abababa", "aba")
#> [1] 2
str_view_all("abababa", "aba")
10.4.3 提取匹配内容
要想提取匹配的实际文本,我们可以使用 str_extract() 函数。为了说明这个函数的用
法
length(sentences)
#> [1] 720
head(sentences)
colors <- c("red", "orange", "yellow", "green", "blue", "purple")
color_match <- str_c(colors, collapse = "|")
color_match
#> [1] "red|orange|yellow|green|blue|purple"
has_color <- str_subset(sentences, color_match)
matches <- str_extract(has_color, color_match)
head(matches)
#> [1] "blue" "blue" "red" "red" "red" "blue"
more <- sentences[str_count(sentences, color_match) > 1]
str_view_all(more, color_match)
str_extract(more, color_match)
#> [1] "blue" "green" "orange
str_extract_all(more, color_match)
#> [[1]]
#> [1] "blue" "red"
#>
#> [[2]]
#> [1] "green" "red"
#>
#> [[3]]
#> [1] "orange" "red"
str_extract() 函数可以给出完整匹配; str_match() 函数则可以给出每个独立分组。 str_
match() 返回的不是字符向量,而是一个矩阵,其中一列是完整匹配,后面的列是每个分
组的匹配
noun <- "(a|the) ([^ ]+)"
has_noun <- sentences %>%
str_subset(noun) %>%
head(10)
has_noun %>%
str_extract(noun)
#> [1] "the smooth" "the sheet" "the depth" "a chicken"
#> [5] "the parked" "the sun" "the huge" "the ball"
#> [9] "the woman" "a helps"
has_noun %>%
str_match(noun)
#> [,1] [,2] [,3]
#> [1,] "the smooth" "the" "smooth"
#> [2,] "the sheet" "the" "sheet"
#> [3,] "the depth" "the" "depth"
#> [4,] "a chicken" "a" "chicken"
#> [5,] "the parked" "the" "parked"
#> [6,] "the sun" "the" "sun"
#> [7,] "the huge" "the" "huge"
#> [8,] "the ball" "the" "ball"
#> [9,] "the woman" "the" "woman"
#> [10,] "a helps" "a" "helps"
# 如果数据是保存在 tibble 中的,那么使用 tidyr::extract() 会更容易。这个函数的工作方式
#与 str_match() 函数类似,只是要求为每个分组提供一个名称,以作为新列放在 tibble 中
tibble(sentence = sentences) %>%
tidyr::extract(
sentence, c("article", "noun"), "(a|the) ([^ ]+)",
remove = FALSE)
10.4.7 替换匹配内容
str_replace() 和 str_replace_all() 函数可以使用新字符串替换匹配内容。
x <- c("apple", "pear", "banana")
str_replace(x, "[aeiou]", "-")
#> [1] "-pple" "p-ar" "b-nana"
str_replace_all(x, "[aeiou]", "-")
#> [1] "-ppl-" "p--r" "b-n-n-"
x <- c("1 house", "2 cars", "3 people")
str_replace_all(x, c("1" = "one", "2" = "two", "3" = "three"))
#> [1] "one house" "two cars" "three people
10.4.9 拆分
str_split() 函数可以将字符串拆分为多个片段。
sentences %>%
head(5) %>%
str_split(" ")
"a|b|c|d" %>%
str_split("\\|") %>%
.[[1]]
sentences %>%
head(5) %>%
str_split(" ", simplify = TRUE) # simplify=T返回一个矩阵
fields <- c("Name: Hadley", "Country: NZ", "Age: 35")
fields %>% str_split(": ", n = 2, simplify = TRUE)
#> [,1] [,2]
#> [1,] "Name" "Hadley"
#> [2,] "Country" "NZ"
#> [3,] "Age" "35"
apropos() 函数可以在全局环境空间中搜索所有可用对象。当不能确切想起函数名称时,这个函数特别有用:
apropos("replace")
dir() 函数可以列出一个目录下的所有文件。 dir() 函数的 patten 参数可以是一个正则表达式,此时它只返回与这个模式相匹配的文件名。例如,你可以使用以下代码返回当前目录中的所有 R Markdown 文件
head(dir(pattern = "\\.Rmd$"))