0. 前言
Elasticsearch 搜索源码分析将会分为三个部分进行讲解:
- 请求转发及消息解析
- 搜索 Query 阶段
- 搜索 Fetch 阶段及数据排序和合并
本文将主要讲述第一部分,具体过程如下:
- 用户发起搜索请求,elasticsearch 使用 netty 监听消息
- 然后将请求进行转发,然后匹配对应的 Action
- 执行 Action 的 execute() 方法,
- 最终根据参数 SEARCH_TYPE,获取要执行的 TransportSearchTypeAction 子类,执行搜索逻辑。
1. 一个简单Query请求示例
假设我们有一个名为 item 的索引,且索引文档的 field 中包含 iid 字段,如果我们想查询 iid 为 16368545 的数据,那么 DSL 可以用一个 curl 命令写成如下格式:
curl -XGET "http://127.0.0.1:9200/item/_search" -d'
{
"query": {
"term": {
"iid": {
"value": 16368545
}
}
}
}'
参数注释:
- 请求的index:
item - 请求的es ip:
127.0.0.1 - 请求的query:
{"query": {"term": {"iid": { "value" : "16368545" }}}}
2. 搜索时序图
第一部分主要是接收用户请求,然后匹配Action,获取实际的RestAction处理请求

第二部分主要是解析Search请求参数,封装成SearchRequest对象,然后调用搜索客户端执行search()
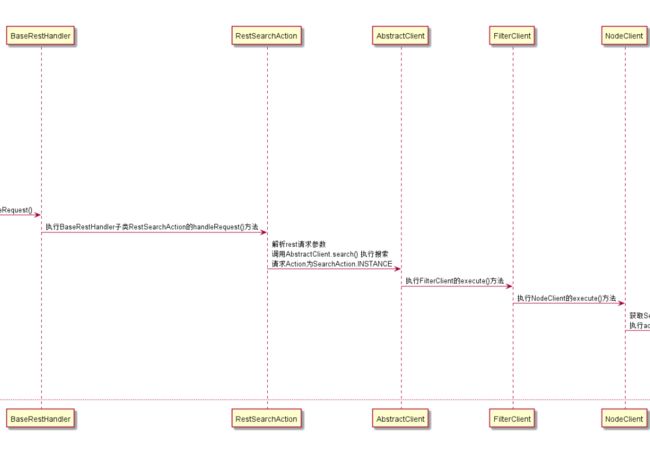
第三部分主要是根据search_type匹配TransportSearchTypeAction,调用子类的execute()方法执行具体的搜索逻辑

3. 搜索过程
3.1 搜索入口及请求转发
在 elasticsearch 启动时,会启动 Netty 模块,并使用 HttpRequestHandler 的 messageReceived() 方法监听 http 请求,然后对请求进行转发,由对应的 RestAction 处理。
@ChannelHandler.Sharable
public class HttpRequestHandler extends SimpleChannelUpstreamHandler {
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) throws Exception {
HttpRequest request;
if (this.httpPipeliningEnabled && e instanceof OrderedUpstreamMessageEvent){
oue = (OrderedUpstreamMessageEvent) e;
request = (HttpRequest) oue.getMessage();
}
...
if (oue != null) {
serverTransport.dispatchRequest(httpRequest, new NettyHttpChannel(serverTransport, httpRequest, corsPattern, oue, detailedErrorsEnabled));
}
...
super.messageReceived(ctx, e);
}
}
在 elasticsearch 启动阶段,会执行 guice 注入,具体的代码如下:
- 该代码为节点启动时创建 Node 的代码,会添加 Rest 模块,在创建 Injector 时会执行 Module 的 configure() 方法
public final class InternalNode implements Node {
public InternalNode(Settings preparedSettings, boolean loadConfigSettings) throws ElasticsearchException {
try {
ModulesBuilder modules = new ModulesBuilder();
// 添加Rest模块
modules.add(new RestModule(settings));
...
injector = modules.createInjector();
}finally {
if (!success) {
nodeEnvironment.close();
ThreadPool.terminate(threadPool, 10, TimeUnit.SECONDS);
}
}
}
}
- 在 Rest 模块的 configure() 方法中,会继续执行 RestAction 模块的 configure() 方法
public class RestModule extends AbstractModule {
@Override
protected void configure() {
bind(RestController.class).asEagerSingleton();
new RestActionModule(restPluginsActions).configure(binder());
}
}
- 在 RestAction 模块中,会创建 RestSearchAction 的单例对象
public class RestActionModule extends AbstractModule {
@Override
protected void configure() {
bind(RestSearchAction.class).asEagerSingleton();
}
}
- 在注入 RestSearchAction 对象时,会把方法、URI 和当前对象注册到内存中
public class RestSearchAction extends BaseRestHandler {
@Inject
public RestSearchAction(Settings settings, RestController controller, Client client) {
super(settings, controller, client);
controller.registerHandler(GET, "/_search", this);
controller.registerHandler(POST, "/_search", this);
controller.registerHandler(GET, "/{index}/_search", this);
...
}
}
- 下面的代码主要是为不同的method,提供不同的handler,相同的方法放在相同的handler的map中
public class RestController extends AbstractLifecycleComponent {
private final PathTrie getHandlers = new PathTrie<>(RestUtils.REST_DECODER);
public void registerHandler(RestRequest.Method method, String path, RestHandler handler) {
switch (method) {
case GET:
getHandlers.insert(path, handler);
break;
...
default:
throw new ElasticsearchIllegalArgumentException("Can't handle [" + method + "] for path [" + path + "]");
}
}
- 对于 URI 和 Action 对象,主要是用 PathTrie 类进行存取
public class PathTrie {
public void insert(String path, T value) {
String[] strings = Strings.splitStringToArray(path, separator);
if (strings.length == 0) {
rootValue = value;
return;
}
int index = 0;
// supports initial delimiter.
if (strings.length > 0 && strings[0].isEmpty()) {
index = 1;
}
root.insert(strings, index, value);
}
public T retrieve(String path, Map params) {
if (path.length() == 0) {
return rootValue;
}
String[] strings = Strings.splitStringToArray(path, separator);
if (strings.length == 0) {
return rootValue;
}
int index = 0;
// supports initial delimiter.
if (strings.length > 0 && strings[0].isEmpty()) {
index = 1;
}
return root.retrieve(strings, index, params);
}
}
- 请求示例中的 item/search 会匹配
/{index}/search,因此处理该请求的 handler 为 RestSearchAction
3.2 请求解析及执行搜索
由上一步可知,经过请求转发,对于 search 请求,使用 RestSearchAction 进行处理。
处理的大致过程为:先对请求 request 进行解析,得到 SearchRequest 对象,然后调用client.search() 执行搜索,最终的搜索结果使用 listener 进行返回
public class RestSearchAction extends BaseRestHandler {
@Override
public void handleRequest(final RestRequest request, final RestChannel channel, final Client client) {
SearchRequest searchRequest;
searchRequest = RestSearchAction.parseSearchRequest(request);
searchRequest.listenerThreaded(false);
client.search(searchRequest, new RestStatusToXContentListener(channel));
}
}
对请求解析主要分为两部分:
- 对http search参数的解析,将解析的结果构造为SearchRequest对象
public class RestSearchAction extends BaseRestHandler {
public static SearchRequest parseSearchRequest(RestRequest request) {
String[] indices = Strings.splitStringByCommaToArray(request.param("index"));
SearchRequest searchRequest = new SearchRequest(indices);
searchRequest.extraSource(parseSearchSource(request));
searchRequest.searchType(request.param("search_type"));
...
return searchRequest;
}
}
对于search_type,如果请求中没有设置,则默认为QUERY_THEN_FETCH
public enum SearchType {
public static SearchType fromString(String searchType) throws ElasticsearchIllegalArgumentException {
if (searchType == null) {
return SearchType.DEFAULT;
}
if ("dfs_query_then_fetch".equals(searchType)) {
return SearchType.DFS_QUERY_THEN_FETCH;
} else if ("dfs_query_and_fetch".equals(searchType)) {
return SearchType.DFS_QUERY_AND_FETCH;
} else if ("query_then_fetch".equals(searchType)) {
return SearchType.QUERY_THEN_FETCH;
} else if ("query_and_fetch".equals(searchType)) {
return SearchType.QUERY_AND_FETCH;
} else if ("scan".equals(searchType)) {
return SearchType.SCAN;
} else if ("count".equals(searchType)) {
return SearchType.COUNT;
} else {
throw new ElasticsearchIllegalArgumentException("No search type for [" + searchType + "]");
}
}
}
解析的请求参数:
- index:
请求的索引名 - source
- search_type:
搜索类型,默认为QUERY_THEN_FETCH - query_cache
- scroll:
如果是scroll请求,会出入scroll id - type:
索引的type - routing:
路由信息 - preference:
搜索偏好,包括对分片、副本和节点的偏好
2.对查询query参数的解析,将解析的结果放入SearchRequest对象中
public class RestSearchAction extends BaseRestHandler {
public static SearchSourceBuilder parseSearchSource(RestRequest request) {
SearchSourceBuilder searchSourceBuilder = null;
QuerySourceBuilder querySourceBuilder = RestActions.parseQuerySource(request);
if (querySourceBuilder != null) {
searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(querySourceBuilder);
}
int from = request.paramAsInt("from", -1);
if (from != -1) {
if (searchSourceBuilder == null) {
searchSourceBuilder = new SearchSourceBuilder();
}
searchSourceBuilder.from(from);
}
...
return searchSourceBuilder;
}
}
Query支持的参数:
- q:
查询词 - from:
返回结果的起始位置 - size:
返回结果数 - explain:
展示打分的详细过程 - version:
请求的版本号 - timeout:
超时时间 - terminate_after
- fields:
要返回的字段列表 - fielddata_fields:
fielddata中的字段列表 - track_scores:
强制返回文档得分 - sort:
指定排序字段 - stats
- suggest_field
在解析完搜索参数后,就要调用 client.search() 执行搜索
3.3 经过层层封装,最终执行的是NodeClient.execute()方法,然后从action获取对应的
TransportAction,执行其execute()方法
public class NodeClient extends AbstractClient {
@SuppressWarnings("unchecked")
@Override
public > void execute(Action action, Request request, ActionListener listener) {
headers.applyTo(request);
TransportAction transportAction = actions.get((ClientAction)action);
transportAction.execute(request, listener);
}
}
actions是在ActionModule中进行配置的,SearchAction对应的TransportSearchAction,该类最终继承TransportAction类
TransportSearchAction对应的类图如下:

public class ActionModule extends AbstractModule {
@Override
protected void configure() {
registerAction(SearchAction.INSTANCE, TransportSearchAction.class,
TransportSearchDfsQueryThenFetchAction.class,
TransportSearchQueryThenFetchAction.class,
TransportSearchDfsQueryAndFetchAction.class,
TransportSearchQueryAndFetchAction.class,
TransportSearchScanAction.class
);
}
public void registerAction(GenericAction action, Class> transportAction, Class... supportTransportActions) {
actions.put(action.name(), new ActionEntry<>(action, transportAction, supportTransportActions));
}
}
因此获取到TranportSearchAction执行其execute()方法,其实是执行父类TransportAction的execute()方法
public abstract class TransportAction extends AbstractComponent {
public final void execute(Request request, ActionListener listener) {
...
if (filters.length == 0) {
try {
doExecute(request, listener);
} catch(Throwable t) {
logger.trace("Error during transport action execution.", t);
listener.onFailure(t);
}
} else {
RequestFilterChain requestFilterChain = new RequestFilterChain<>(this, logger);
requestFilterChain.proceed(actionName, request, listener);
}
}
protected abstract void doExecute(Request request, ActionListener listener);
}
TransportAction的execute是抽象方法,因此实际执行的是TranportSearchAction的doExecute()方法
public class TransportSearchAction extends HandledTransportAction {
@Override
protected void doExecute(SearchRequest searchRequest, ActionListener listener) {
if (optimizeSingleShard && searchRequest.searchType() != SCAN && searchRequest.searchType() != COUNT) {
try {
...
if (shardCount == 1) {
searchRequest.searchType(QUERY_AND_FETCH);
}
} catch (IndexMissingException|IndexClosedException e) {
} catch (Exception e) {
logger.debug("failed to optimize search type, continue as normal", e);
}
}
if (searchRequest.searchType() == DFS_QUERY_THEN_FETCH) {
dfsQueryThenFetchAction.execute(searchRequest, listener);
} else if (searchRequest.searchType() == SearchType.QUERY_THEN_FETCH) {
queryThenFetchAction.execute(searchRequest, listener);
} else if (searchRequest.searchType() == SearchType.DFS_QUERY_AND_FETCH) {
dfsQueryAndFetchAction.execute(searchRequest, listener);
} else if (searchRequest.searchType() == SearchType.QUERY_AND_FETCH) {
queryAndFetchAction.execute(searchRequest, listener);
} else if (searchRequest.searchType() == SearchType.SCAN) {
scanAction.execute(searchRequest, listener);
} else if (searchRequest.searchType() == SearchType.COUNT) {
countAction.execute(searchRequest, listener);
}
}
}
在TransportSearchAction中,其实只做了两件事:
- 如果请求的索引只有一个分片,那么将search_type设置为QUERY_AND_FETCH
- 根据search_type,将search request交给对应的子类执行
各个SearchType的特点如下:
- DfsQueryThenFetchAction: 计算分布式词频以获得更准确的评分
- DfsQueryAndFetchAction: 请求针对单分片时,计算分布式词频以获得更准确的评分
- QueryThenFetchAction:
3.1 在第一阶段,查询被转发到所有涉及的分片,每个分片执行搜索并生成该分片的本地结果排序列表,每个分片都向协调节点返回足够的信息,以允许它合并并将分片级别结果重新排序为具有最大长度大小的全局排序结果集
3.2 在第二阶段期间,协调节点仅从相关分片请求文档内容(以及突出显示的片段,如果有的话) - QueryAndFetchAction: 当query_then_fetch请求仅针对单个分片时,会自动选择该模式,两个阶段query和fetch都在一次过程执行
- ScanAction: Scan请求
- CountAction: Count请求
对Search具体的执行逻辑,我将以QUERY_THEN_FETCH为例,在下篇博客中详细讲解