简述/Rationale
自改写代码(self-modifying code / self-mutating code),是非常古老的概念。自改写代码允许在程序执行当中修改构成程序本身的指令。在IBM/360时代以及相应的语言,包括ALGOL 60和COBOL都允许在程序执行的过程中修改自身代码。在今天常见的编程语言中几乎都没有这个功能,同时操作系统也默认禁止这样做,通常的做法是写-运行互斥,即将内存标记为可写或可运行,却不能同时被修改和执行,从而保障系统安全。另外自改写代码造成了缓存的利用率低下,缓存的依据是locality(“程序运行中的大部分是件是在执行它一小部分代码”),如果这一小部分代码被频繁修改,那么缓存的意义就不太大了。因此到今天自改写代码这一概念已经不大流行了。
那么自改写代码本身有什么意义呢?可能最大的意义就在于人工智能了。自改写代码在上世纪七八十年代有过一些在人工智能方面失败的应用。那时是神经网络和基因算法刚刚起步的时候,但是如果没有任何huristic method而单纯让代码自我演进的效率非常低下。所以这些实验随后就终止了。但是我们不妨设想一下,从进入二十一世纪,互联网逐渐普及起来,我们通过代码制造了大量的数据的时候,代码却还是需要人类一行一行敲入,这是一件非常奇怪的事情。计算机的产生旨在减少人类的重复作业,但是编程这一人类活动在大部分情况下都是重复作业。所以这样一个尝试,从某种意义上说就是希望在人工智能不断替代人类工种的进程中,把编程这一活动也替代吧。
道德和伦理/Ethics
这种实验很容易让人联想到人工智能的发展,以及人类未来的走向,也会像克隆人或各种干细胞实验一样上升到伦理道德层次讨论。事实上比蒸汽机更早时,英国的纱厂主开始应用水轮机来纺纱的时候,工人们的恐慌和我们今天所感受到的都是一样的。
我在这里想说的是,技术从古至今都是双刃剑。技术提高了社会生产力,增加了社会总财富的增速,但是也加大了贫富差距。技术让很多事情完成的更快,但是却又为人类带来了更多的事。总体来说,人如果不奴役技术,就会被技术所奴役,这个争斗随着历史进程的发展,变得更加尖锐了。
对于写代码的人来说,自己需要想清楚一些事情。除了代码本身的美学和艺术价值之外,你写代码总是要完成一些事情的。如果你写代码所完成的事情是在帮助你自己,完成向他人及社会提供价值的事(撰文,记账等,然而写代码本身并不是这样一件事),那么计算机是你的工具。如果你不能立刻得出这个答案,那么需要仔细掂量,是你在操作计算机,还是计算机在操作你。你是否正在扮演计算机上面一台低效的代码生成设备。
如果您耐心看到此处,那么衷心希望计算机是您的工具,而您过着充实美好的生活。您是一位计算机使用者,而不是一台设备。请您务必怀着要通透了解并驾驭计算机的心态阅读后文。
实验介绍/Introduction
这个实验的设想是从我个人2014年开始的。当时我正在接触嵌入式系统和FPGA。FPGA吸引人之处莫过于其现场可编程能力,理论上它可以达到运行时更改自身电路结构的能力,但是在实践中非常难操作,FPGA的学习曲线很长,并且在调试过程中会遇到很多来自电路层的不确定性的问题,所以相当耗时。于是我想到,是否可以退而求其次,先在计算机上去实现可以改变自身代码的能力,作为proof of concept,在想法成熟之后再拿到硬件平台上进行下一步的尝试。
与此同时我接触到了Forth语言,一个广泛应用在嵌入式系统上的语言,保持底层的灵活性。和C这样的编译语言不同,Forth实现了一个最小的运行时环境,并且鼓励使用者通过这个环境不断扩充代码。目前只有Forth语言按照这个思想设计。于是这个语言成了实现的自改写代码的首选。然而问题是,目前官方的Forth已经是一个很庞大的系统了,内部的行为很难探究。同时Forth社群都鼓励使用者先用汇编自行实现一个最小的Forth运行时环境。然而汇编语言非常难调试,并且在平台间移植的问题上花了大量时间。实现Forth的项目于去年2月份开始,持续了半年之后便中止了。
所以之后我又做了退而求其次的决定,先去实现一个简陋的计算机emulator,包括实现实现Forth所需的所有指令。目前正在进展的就是这项工作。
代码
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#define MEM_SIZE 256
以下是几个类似汇编的数据类型,均是无符号类型,分别占1/2/4字节。hook是用来接收类型不确定的变量的。
typedef unsigned char byte;
typedef unsigned short word;
typedef unsigned long quad;
typedef void * hook;
定义完数据类型,以下是几个模拟寄存器的变量。Stackeg和ReturnReg以及EntryPointer均是Forth中才会用到的。Memory是我们主要操作的场所,一切数据和代码都在当中。MemPointer是指向内存地址的指针,可以把它理解为instruction pointer。Register数组保存了16个4字节的空间,它们是作为一般数据寄存器用的。Command是一个buffer,用来存储读入的指令。
word StackReg = 0,
ReturnReg = 0,
EntryPointer = 0;
byte Memory[MEM_SIZE];
byte * MemPointer = Memory;
quad Register[16];
byte Command[8];
接下来,trans模仿了CPU的transfer指令,将一个地址上的内容复制到另一个地址上(并改写)。注意到声明为void *类型的hook是不能直接使用的,所以我们将此地址加上我们所需要的偏置,然后再dereference。Size指出需要连续搬运多少个字节,但需要注意的是,Size是不能直接拿来用的,因为当我们逐个字节搬运时使用的是下标。譬如要连续搬运两个字节的话,是要搬运指定地址开始的第0个和第1个。因此我们使用一个递减的while循环,从Size - 1开始到0结束。
这是种不大常见的写法,涉及到对C寻址的理解。我们常见的写法是array[index],来得到一个名为array数组的第index位置的值。但事实上,array[index]等价于*(array + index)也等价于index[array]。也就是说,array是一个指针,指针可以像普通整型数一样做加减运算。这个指针加上了一个index作为偏移量,然后通过dereference操作得到实际的值。按照默认的方法,我们无法重新cast指针的类型,而hook是一个void *类型,必须经过cast才能使用。所以在下文中(byte *)(Dest + DestOff + c)是先将指针cast为byte类型(单字节),然后再进行dereference,而没有直接按照Dest[DestOff+c]的形式。
void trans(hook Source, word SourceOff, hook Dest, word DestOff, word Size) {
int c = Size - 1;
while (c >=0) {
*((byte *)(Dest + DestOff + c)) = *((byte *)(Source + SourceOff + c));
c --;
}
}
在trans的基础上我们设计了四个更具体的操作,assign用于将一个常量赋于指定地址,clone用于在两个地址之间转移。最后两个是用来和数据寄存器交互的。
word assign(hook Source, word Off, word Size) {
trans(Source, 0, Memory, Off, Size);
return Off + Size;
}
void clone(word Source, word Dest, word Size) {
trans(Memory, Source, Memory, Dest, Size);
}
void to_reg(word Source, word Reg, word Size){
trans(Memory, Source, Register, Reg*4, Size);
}
void from_reg(int Reg, word Dest, word Size){
trans(Register, Reg*4, Memory, Dest, Size);
}
有了这几个像汇编指令一样的东西,我们就可以创造一些生成代码的工具。以下这些工具的功能类似于汇编语言中的assembler directive,它们是辅助汇编器生成一些代码,但不会直接成为可以被执行的CPU指令。但从我们所实现的机器来看,它们还是有本质的区别。assembler directive是在编译时执行的,所生成的内容都保存在了汇编之后的二进制文件中,在运行时直接被载入对应的段内。我们此处完成的则更像是汇编代码的一部分,它们是在程序载入后才开始进行的工作。但是对于接下来要完成的工作,它们都相当于初始化的一部分,所以没有影响。
那么assign_char_const是将一个字节从内存偏移Offset处开始写入,重复times次。assign_string是我们所完成的string结构,包含一个记录长度的字节,以及后面字符串内容。Entry结构会在后面的例子中描述。
word assign_char_const(word Offset, const byte c, word times) {
byte copy = c;
int counter = times - 1;
while (counter >= 0) {
trans(©, 0, Memory, Offset + counter, 1);
counter --;
}
return Offset + times;
}
word assign_string(word Offset, byte* String) {
byte length = strlen(String);
byte afterByte = assign(&length, Offset, sizeof(byte));
byte finalLen = assign(String, afterByte, length);
return finalLen;
}
word assign_entry_name(word Offset, byte* String, word PaddedLen) {
byte padCopy = PaddedLen;
byte strLength = strlen(String);
byte addedByte = assign(&padCopy, Offset, sizeof(byte));
byte addedStr = assign(String, addedByte, strLength);
byte padded = assign_char_const(addedStr, ' ', PaddedLen - strLength);
return padded;
}
word assign_entry(word Offset, byte* EntryName, word(* Content)(word)) {
word OffCopy = Offset;
word afterAssigned = assign_entry_name(Offset, EntryName, 15);
word afterAddingContent = Content(afterAssigned);
word finalEntryLength = assign(&OffCopy, afterAddingContent, sizeof(word));
return finalEntryLength;
}
word test_content(word Offset) {
byte test[] = "@CONTENT";
word afterAssigned = assign_string(Offset, test);
return afterAssigned;
}
接下来为了让输出好看一些,我们设置不同的前景色和背景色。以下是ANSI颜色代码标准,但是在terminal不同的color scheme下会显示出不同效果。
//fonts color
#define FBLACK "\033[30;"
#define FRED "\033[31;"
#define FGREEN "\033[32;"
#define FYELLOW "\033[33;"
#define FBLUE "\033[34;"
#define FPURPLE "\033[35;"
#define FDGREEN "\033[36;"
#define FGRAY "\033[37;"
#define FCYAN "\x1b[36m"
////background color
#define BBLACK "40m"
#define BRED "41m"
#define BGREEN "42m"
#define BYELLOW "43m"
#define BBLUE "44m"
#define BPURPLE "45m"
#define D_BGREEN "46m"
#define BWHITE "47m"
#define NONE "\033[0m"
#define BOLD "\033[1m"
#define UNDERLINED "\033[4m"
这可能是对我来说帮助最大的部分,我能很方便地查看memory map,而且颜色和布局能帮很大的忙。其中ASCII字符部分(0x32以上)会按字符来显示,而其余的数字则都显示为十六进制数。未来这部分代码会继续扩充。
void print_mem() {
for (int iter = 1; iter <= MEM_SIZE; iter ++) {
if (0x20 <= Memory[iter-1]) {
printf(BOLD FYELLOW BBLACK " %c " NONE, Memory[iter-1]);
} else {
if(Memory[iter-1] == 0x00)
printf(FDGREEN BBLACK "%02X " NONE, Memory[iter-1]);
else
printf(BOLD FGREEN BBLACK "%02X" NONE " ", Memory[iter-1]);
}
if (!(iter % 16) )
printf("\n");
}
}
那么接下来我们就做试验了。
int main() {
byte c = 0x40;
//assign(&c, 0, 1);
//clone(0, 1, sizeof(byte));
//clone(0, 2, sizeof(word));
//word offset = 0x20;
//byte example[] = "example";
//assign_entry(offset, example, test_content);
print_mem();
return 0;
}
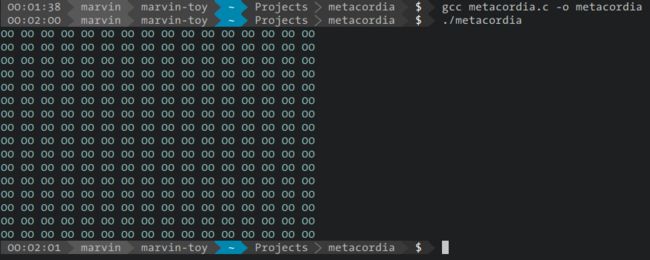
这是没有做任何事时的memory map。当我们解除了第一行注释时,我们把ASCII码为0x40的字符放在了内存的第一个位置上,也就是那个@。
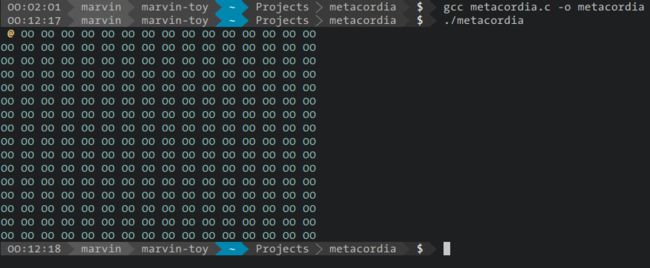
当我们继续解除后续两行注释时,我们知道我们先将内存中位置0的内容copy到了位置1,继而又把位置0和1两个字节的内容复制到了以位置2开头的区域,也就是2和3,于是我们会看到
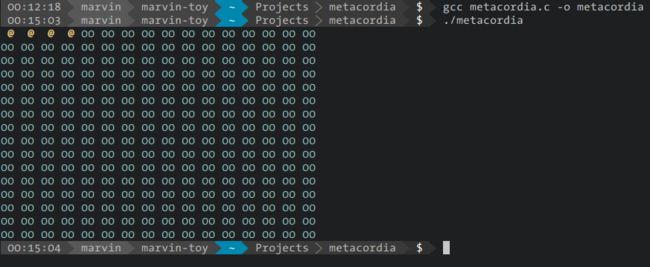
把最后三行注释解除,我们会看到
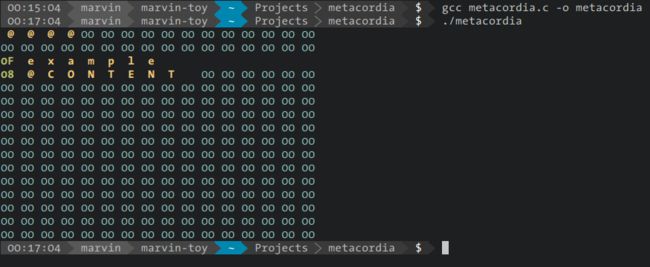
有兴趣的读者可以思考一下这是如何得到的,以及末尾“CONTENT"后面为什么多了一个空格。
完整代码见于(这里)[https://coding.net/u/marv/p/metacordia/git/blob/4fa7a763497b28af76f21b4315d4f71dba6ff2b9/metacordia.c]