数据结构与算法——初识(概念)
终于到了数据结构和算法的阶段了,前段时间被校招题虐的惨惨的,毅然决定要好好学数据结构和算法了,希望和我一起参加校招的朋友们也加油啊!
数据结构在开发中是很重要的,不对应该是非常重要的,一定要好好学,如果想搞开发的话。在今后的大部分程序中,不管是一个小的系统也好,大的软件也好,都离不开我们的数据结构和算法的运用,我们完全可以说:程序=数据结构+算法。
数据结构和算法是两个概念,这是单独的两门课,在今后的博客中我会继续整理笔记,前期是数据结构的内容,后期是算法的内容,今天这篇文章,我只想先介绍一下数据结构和算法这两个概念。
数据结构
数据结构也是分两个部分,一个是数据部分,一个是结构部分:
数据:但凡能够被计算机存储、识别和计算的东西都叫数据,但是这些数据都是以二进制存储的。如:
硬盘中的:MP3、JPG、doc、AVI、EXE、TXT
内存中的:变量、常量、数组、对象、字节码
而结构则是数据与数据之间的一种或多种特定的关系。
虽然两者在概念上是独立的,但是在数据结构里面,少其一则程序的结构就是不完整的,因此 数据结构就是数据+数据之间的关系,两者的结合,组成数据结构,让我们的程序更加完整。
那么数据结构主要解决什么样的问题呢?——将零散的数据“整齐划一”,方便后续操作。如在前期阶段学习的时候,学到过数组,将一堆分散的变量,定义到数组里面,变成一堆连续的变量,方便对整体进行操作。因此,学习数据结构让我们对数据有一个比较方便的管理方式。
数据的结构也分两种:
逻辑结构:是指数据元素之间的相互关系,是我们想象出来的,并没有实质性的将其存储在计算机中
集合结构:集合结构中的数据元素除了同属于一个集合外,他们之间没有其他关系
线性结构:线性结构中的数据元素之间是一对一的关系
树形结构:树形结构中的数据元素之间存在一种一对多的层次关系
图形结构:也叫网状结构,其数据元素是多对多的关系
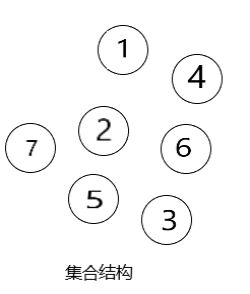
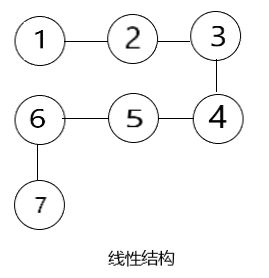
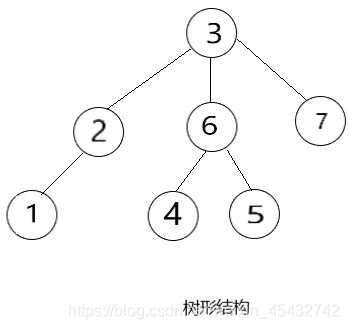
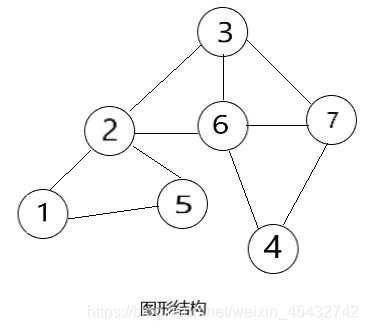
由上图可知,树形结构是图形结构的一个特殊结构,线性结构是树形结构的一种特殊结构,当线性结构被打乱,元素之间没有了关联,就成了集合结构。因此,我们将由集合结构开始逐步向难,一走到底!
物理结构:是指数据的逻辑结构在计算机中的存储形式
顺序存储结构:开辟一组连续的空间存储数据(查找快,增删慢)
通常用数组来实现,数组中空间本身是连续的,保证了数据之间的关系
链式存储结构:开辟一组随机的空间存储数据(增删快,查找慢)
通常用节点来实现,节点不仅要存储数据,还要存储下一个节点的位置以保证数据之间的关系
因此我们要根据应用场景的不同,灵活的选择最合适的数据结构,比如手机通讯录,我们通常是要查找比较快的,所以他一般是用顺序存储,也就是数组存储的。当然计算机中还有很多数据结构的应用,如:计算机文件系统,函数栈,游戏地图(找最短路径)等等,可见——这里再次强调数据结构的重要性。
算法
算法的概念是:解决特定问题求解步骤的描述,在计算机中表现为指令的有序系列,并且每条指令表示一个或多个操作。简单来说,就是求解一个问题的步骤。
如求1+2+...+100的和,在没有学习循环的时候我们可以用公式来求解,而公式求解也有几种:
方法一:常规公式求法 方法二:等差数列求和法
int N=100; int N=100;
int sum =(N+1)*N/2; int sum = N*1+(N*(N-1))/2
在学习循环之后,我们就可以用循环来做:
方法三:使用循环求解
int sum =0;
int N=100;
for(int i=1;i<=N;i++){
sum=sum+i;
}
因此可见,一个问题的求解步骤并不是唯一的,那么是不是我们就可以随便选择这个问题的求解步骤了呢?显然不是的,现在的程序强调的都是最优最优,因此我们要选择一个最优的算法运用到我么的程序中。
那么如何评价一个算法的好坏以及是否达到最优?——设计算法要提高程序运行的效率,这里效率大都指算法的执行时间,这里提供两种方法:
事后统计方法:这种方法主要是通过已经设计好的程序和数据,利用计算机计时器对不同算法程序的运行时间进行比较,从而确定算法效率的高低。但是这样会有很多缺陷:
必须事先编好程序,在进行运行,如果程序处理的数据量较大,则会花费大量的时间和精力(计算一年都不成问题)
时间的比较主要依赖于计算机硬件和软件环境
算法的测试数据设计困难,在数量较小的时候,不管什么算法其运行时间都是很微小的,相差几乎为零,如果数据量大了,算法的优越性就出来了,但是这样又会耗费时间
(所以该种方式一般不予采纳)
事前分析估算方法:这种方法主要在计算机程序编制前,依据统计方法对算法进行估算,一个高级程序语言编写的程序在计算机上运行时所消耗的时间取决于下列因素:
算法采用的策略、方法(决定算法好坏的根本)
编译产生的代码质量(软件来支持)
问题的输入规模
机器执行指令的速度(硬件性能)
也就是说,抛开这些与计算机硬件、软件有关的因素, 一个程序的运行时间,依赖于算法的好坏和问题的输入规模(即数据入量的多少)。在分析程序的运行时间时,最重要的是把程序看成是独立于程序设计语言的算法或一系列步骤,因此我们引入算法时间复杂度的概念。
时间复杂度
算法时间复杂度:是衡量算法好坏的一个标准。
官方定义:一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),存在一个正常数c使得fn*c>=T(n)恒成立。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
But!常见的几个时间复杂度也就几个:常数阶O(1)、线性阶O(n)、对数阶O(logn)、平方阶O(n²)、立方阶O(n³)、O(nlogn)、常数指数阶O(2^n)、指数阶O(n^n)、阶乘阶O(n!)。
其中的关系是:O(1) 如上面的例子,计算前100项和: 方法一:常规公式求法 方法二:等差数列求和法 int N=100; // 执行1次 int N=100; //执行一次 int sum =(N+1)*N/2; // 执行1次 int sum = N*1+(N*(N-1))/2 //执行一次 因此上面两种算法的每条语句执行次数为常数,时间复杂度为常数阶O(1) 但是在循环中: 方法三:使用循环求解 int sum =0; //执行一次 int N=100; //执行一次 for(int i=1;i<=N;i++){ //执行N+1次 sum=sum+i; //执行N次 } 随着N的增大,循环里面执行的次数越多,那么此算法的执行次数为2N+3次,但是是时间复杂度为O(n),因为随着N的不断增大,这个3就显得微不足道了,如果N达到足够大,这个系数2也显得微不足道,因为数量级是一样的,因此最后的时间复杂度为O(n)。 所以,在计算时间复杂度时,忽略常数,只保留幂的最高次,且忽略幂高项的系数(我们考虑的时间复杂度都是最坏的情况) 至此数据结构和算法的概念已经介绍完了,然后后面的内容就是伴随着大量的代码讲解数据的结构,希望自己,也希望和我一起学习的人,都能坚持下去,我们一定会成为大佬的!