redis String类型底层数据结构 sds
一. 简单动态字符串
1.1 什么是简单动态字符串?
redis在实现字符串中并没有采用传统C语言中的字符串表示(传统的C语言字符串是一个以空字符结尾的字符数组),而是自己定义了一种叫做简单动态字符串(simple dynamic string, 简称SDS)的抽象类型,并用SDS用作redis默认的字符串表示。
在Redis里面,C字符串只会作为字符串字面量(string literal), 用在一些无须对字符串值进行修改的地方,比如打印日志。但当这个字符串需要被修改的时候,SDS就派上用场了。
举一个栗子,客户端set一个值时:
redis> SET msg "hello world"
OK那么Redis将在数据库中创建了一个新的键值对,其中:
- 键值对的键是一个字符串对象, 对象的底层实现是一个保存着字符串 “msg” 的 SDS 。
- 键值对的值也是一个字符串对象, 对象的底层实现是一个保存着字符串 “hello world” 的 SDS 。
那么为什么要采用SDS呢,有什么好处?
sds.h中找到了sdshdr的结构体:
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
//记录buf数组中已使用的字节数量
uint64_t len;
//分配的buf数组长度,不包括头和空字符结尾
uint64_t alloc;
// 标志位, 最低3位表示类型,另外5个位没有使用
unsigned char flags;
char buf[];
};
通过代码可以看出SDS有5中header类型,之所以要定义不同的类型,是为了让不同的字符串使用不同长度的header,从而节省内存。
SDS结构体的的组成有:
- len: 记录buf数组中已使用的字节数量
- alloc: 分配的buf数组长度,不包括头和空字符结尾
-
flags: 标志位, 最低3位表示header类型,另外5个位没有使用。类型对应下面5中类型,用3个bit位就可以表示。
#define SDS_TYPE_5 0 #define SDS_TYPE_8 1 #define SDS_TYPE_16 2 #define SDS_TYPE_32 3 #define SDS_TYPE_64 4 -
buf[]: 字符数组,用于存放字符串
举个例子:我们在一个SDS中存放了redis字符串,SDS是怎么表示的呢?
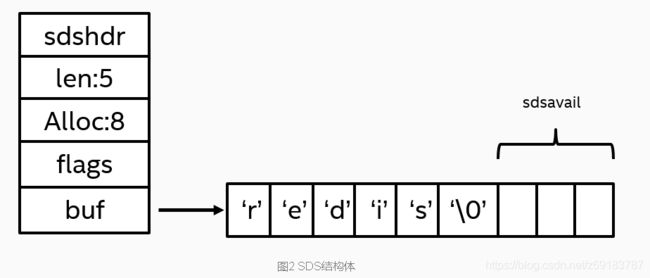
SDS 遵循 C 字符串以空字符结尾的惯例, 保存空字符的 1 字节空间不计算在 SDS 的 len 属性里面, 并且为空字符分配额外的 1 字节空间, 以及添加空字符到字符串末尾等操作都是由 SDS 函数自动完成的, 所以这个空字符对于 SDS 的使用者来说是完全透明的。
遵循空字符结尾这一惯例的好处是, SDS 可以直接重用一部分 C 字符串函数库里面的函数。
1.2 SDS相对C字符串的好处?
因为redis作为内存型数据库的定位就是追求性能,传统的C字符串在满足这些苛刻的性能,效率要求时就显得捉襟见肘了。SDS定义这样的结构体有什么好处?
获取字符串长度复杂度为O(1)
传统的C字符串并没有记录字符串长度,而想获取字符串长度时就需要遍历一遍字符串,复杂度为O(N),导致随着字符串长度变长,获取字符串长度的操作复杂度也会增加。如下图所示:
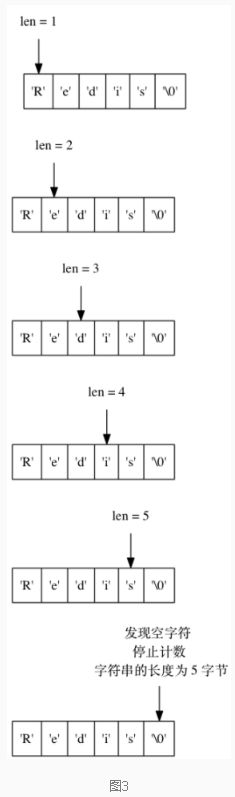
和C字符串不同,因为SDS在len属性中记录了SDS 身的长度,写代码时只要直接获取len属性值,就可以知道字符串长度,所以获取一个SDS长度的复杂度仅为 O(1) 。
防止缓冲区溢出(buffer overflow)
传统C字符串由于不记录自身长度,在对字符串进行操作的时候容易带来缓冲区溢出。
比如 strcpy()函数:strcpy()函数将源字符串复制到缓冲区。如果源字符串碰巧来自用户输入,且没有专门限制其大小,则有可能会造成缓冲区溢出。
再比如/strcat函数,将src字符串拼接到dest字符串后面。strcat假定用户在执行这个函数时, 已经为dest分配了足够多的内存, 可以容纳src字符串中的所有内容,而一旦这个假定不成立时,就会产生缓冲区溢出。
举个例子,如果内存中s1,s2两个字符串是紧邻的:
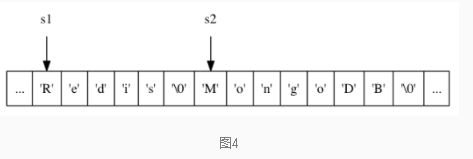
如果过程中,用户想对s1进行扩展
strcat(s1, "Cluster");
由于没有注意到s预分配的空间大小,执行以后会导致s1的内容缓冲到s2,以至于s2的内容被意外修改成Cluster,这种错误对数据库的使用过程致命的。
而SDS在sdscat时会预先检查空间是否足够,不够的话会通过sdsMakeRoomFor自动为要拼接的字符串扩展空间.
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
减少因修改字符串带来的内存重分配次数
因为 C 字符串的长度和底层数组的长度之间存在着这种关联性, 所以每次增长或者缩短一个 C 字符串, 程序都总要对保存这个 C 字符串的数组进行一次内存重分配操作:
- 如果程序执行的是增长字符串的操作, 比如拼接操作(append), 那么在执行这个操作之前, 程序需要先通过内存重分配来扩展底层数组的空间大小 —— 如果忘了这一步就会产生缓冲区溢出。
- 如果程序执行的是缩短字符串的操作, 比如截断操作(trim), 那么在执行这个操作之后, 程序需要通过内存重分配来释放字符串不再使用的那部分空间 —— 如果忘了这一步就会产生内存泄漏。
因为内存重分配涉及复杂的算法, 并且可能需要执行系统调用, 所以它通常是一个比较耗时的操作:
在一般程序中, 如果修改字符串长度的情况不太常出现, 那么每次修改都执行一次内存重分配是可以接受的。但是 Redis 作为数据库, 经常被用于速度要求严苛、数据被频繁修改的场合, 如果每次修改字符串的长度都需要执行一次内存重分配的话, 那么光是执行内存重分配的时间就会占去修改字符串所用时间的一大部分, 如果这种修改频繁地发生的话, 可能还会对性能造成影响。
为了避免 C 字符串的这种缺陷, SDS 通过已使用空间解除了字符串长度和底层数组长度之间的关联,在更改字符串的时候可以只更改len属性,而不重新分配内存。
SDS对于内存操作实现了空间预分配和惰性空间释放两种优化策略。
1.空间预分配
我们上面提到过,在对字符串进行增长操作时,会使用一个sdsMakeRoomFor函数来扩展字符串。
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}sdsMakeRoomFor是sds实现中很重要的一个函数。关于它的实现代码,我们需要注意的是:
- 如果原来字符串中的空余空间够用(avail >= addlen),那么它什么也不做,直接返回。sdsMakeRoomFor是sds实现中很重要的一个函数。关于它的实现代码,我们需要注意的是:
- 如果需要分配空间,它会比实际请求的要多分配一些,以防备接下来继续追加。它在字符串已经比较长的情况下要至少多分配SDS_MAX_PREALLOC个字节,这个常量在sds.h中定义为(1024*1024)=1MB。
- 按分配后的空间大小,可能需要更换header类型(原来header的alloc字段太短,表达不了增加后的容量)。
- 如果需要更换header,那么整个字符串空间(包括header)都需要重新分配(s_malloc),并拷贝原来的数据到新的位置。
- 如果不需要更换header(原来的header够用),那么调用一个比较特殊的s_realloc,试图在原来的地址上重新分配空间。s_realloc的具体实现得看Redis编译的时候选用了哪个allocator(在Linux上默认使用jemalloc)。但不管是哪个realloc的实现,它所表达的含义基本是相同的:它尽量在原来分配好的地址位置重新分配,如果原来的地址位置有足够的空余空间完成重新分配,那么它返回的新地址与传入的旧地址相同;否则,它分配新的地址块,并进行数据搬迁。参见http://man.cx/realloc。
划重点:在扩展SDS空间之前, SDS API 会先检查未使用空间是否足够, 如果足够的话, API 就会直接使用未使用空间, 而无须执行内存重分配。通过这样的空间预分配策略, Redis可以减少连续执行字符串增长操作所需的内存重分配次数。
2.惰性空间释放
惰性空间释放用于优化 SDS 的字符串缩短操作: 当 SDS 的 API 需要缩短 SDS 保存的字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是把缩短后的长度记录在len属性中,剩余空间用于未来扩展字符串用。
例如这个sdstrim函数,
/* Example:
*
* s = sdsnew("AA...AA.a.aa.aHelloWorld :::");
* s = sdstrim(s,"Aa. :");
* printf("%s\n", s);
*
* Output will be just "Hello World".
*/
sds sdstrim(sds s, const char *cset) {
char *start, *end, *sp, *ep;
size_t len;
sp = start = s;
ep = end = s+sdslen(s)-1;
while(sp <= end && strchr(cset, *sp)) sp++;
while(ep > sp && strchr(cset, *ep)) ep--;
len = (sp > ep) ? 0 : ((ep-sp)+1);
if (s != sp) memmove(s, sp, len);
s[len] = '\0';
sdssetlen(s,len);
return s;
}
可以看出程序结束时并没有reallocate内存空间,而是修改结构体中len的属性。
当用户真正想free掉空闲空间时,可以使用sdsRemoveFreeSpace函数:
sds sdsRemoveFreeSpace(sds s) {
void *sh, *newsh;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
size_t len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
type = sdsReqType(len);
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+len+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
newsh = s_malloc(hdrlen+len+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, len);
return s;
}
可以存放二进制数据
C 字符串中的字符必须符合某种编码(比如 ASCII), 并且除了字符串的末尾之外, 字符串里面不能包含空字符, 否则最先被程序读入的空字符将被误认为是字符串结尾 —— 这些限制使得 C 字符串只能保存文本数据, 而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
因此, 为了确保 Redis 可以适用于各种不同的使用场景, SDS 的 API 都是二进制安全的(binary-safe): 所有 SDS API 都会以处理二进制的方式来处理 SDS 存放在 buf 数组里的数据, 程序不会对其中的数据做任何限制、过滤、或者假设 —— 数据在写入时是什么样的, 它被读取时就是什么样。
这也是我们将 SDS 的 buf 属性称为字节数组的原因 —— Redis 不是用这个数组来保存字符, 而是用它来保存一系列二进制数据。
总结(划重点)
SDS相对于传统的C字符串的优点:
| C字符串 | SDS |
|---|---|
| 获取字符串长度的复杂度为 O(N) | 获取字符串长度的复杂度为 O(1) |
| 操作字符串函数不安全,可能造成缓冲区溢出 | 安全的操作字符串API,避免缓冲区溢出 |
| 修改字符串长度 N 次必然需要执行 N 次内存重分配 | 修改字符串长度 N 次最多需要执行 N 次内存重分配 |
| 只能保存文本数据 | 可以保存文本以及图片、音频、视频、压缩文件这样的二进制数据。 |