(论文笔记09.Feature analysis for data-driven APT-related malware discrimination(CCF B)2021)
本文主要研究恶意软件,重点是区别APT相关恶意软件和非APT恶意软件之前的关系,并且寻找其中的可解释性。
1. Introduction
-
分类:
在研究与apt相关的恶意软件时考虑不同类型的特征将会很有趣,这不仅是为了提高准确性,也是为了更好地了解其本质。因此,本工作提出使用静态、动态和网络相关的特征、可解释的和通过领域知识选择的特征,以及知名的机器学习技术来分析apt相关的恶意软件与无任何已知关联的通用恶意软件的可识别性。 -
已有的数据包:
一个包含apt相关和非apt通用恶意软件的大数据集已经收集并公开提供(martin -里拉斯等人,2020年)。该恶意软件数据集共包含19457个恶意软件分析样本(1497个APT样本和17960个非APT类型的恶意软件),以及从静态、动态和网络流量分析中提取的字段处理中获得的1944个特征。 -
对数据集使用机器学习技术:
利用ML技术从不同角度对数据集进行分析,以更好地理解APT恶意软件的特征。首先进行探索性分析,获取数据结构的知识。执行后,特征选择过程使用不同的过滤器和嵌入式技术找到一个具有高区分度的特征来决定是否属于APT恶意软件。特征选择提供了一套修剪后的的相关特征集,然后通过成熟的分类算法进行分类。
2 .Related work
检测恶意软件的发展
1)网络流量
一般来说,比较常用的检测APT恶意软件的方法是通过分析APT样本产生的网络流量
2)静态分析
关于可执行文件的分析,一种常见的方法是静态分析,静态分析可以遵循以原始二进制文件的某些特性为中心的不同分析路径。这种方法直接使用原始字节或其他低级元素来构建特征,例如,从字节序列获得的n-gram(属于字符串语义匹配)。尽管这些特性很容易计算,但它们通常提供的可解释信息很少,而且可能存在一些局限性。
3)动态分析
动态分析也称为行为分析,它在一个受控制和监控的环境中执行恶意软件,观察其行为及其与其他资源的交互,可能提供那些静态分析无法发现的恶意软件的信息。然而,由于恶意软件的恶意行为通常取决于环境,需要观察的时间也不明确,因此很难模拟出合适的条件来揭示恶意软件的恶意行为。
4)机器学习技术
将机器学习(ML)技术应用于恶意软件样本的自动检测或分类是文献中一个常见的主题(Gandotra et al., 2014),但很少有作品将静态和动态分析的特征结合起来,而且很少有人去分析这种分类的可解释性。最近在一般的恶意软件检测和分类中提出的先进技术可以对从动态分析中获得的事件序列进行建模,例如,深度神经网络还没有应用在APT相关的恶意软件检测上。
5)恶意软件数据集
第一个数据集:在微软分类挑战中使用的数据集(Ronen等人,2018年)侧重于恶意软件的静态特征,包含9个不同的恶意软件家族的2万多个样本
第二个数据集:Anderson和Roth(2018)收集的数据集是一个110万个样本的大集合,这些样本分析了从Windows可执行样本的静态分析中再次获得的一组特征。
第三个数据集:Laurenza等人(2017)描述了一个有趣的数据集,其中有标记为apt相关的恶意软件和通用的恶意软件,但是它只包括了静态特征。
3.数据集
3.1 数据收集
对于收集的数据情况如下图所示:
静态分析:使用基于Python PEFile库的Python脚本对整个数据集进行静态分析(Mulder等人,2011),
动态分析:而从VirusTotal获得的报告中提取动态分析信息(包括网络流量特征)。
最终的分析使用的样本数量较低,因为并非所有收集到的样本都曾被VirusTotal分析过

3.2 Proposed features, encoding and preprocessing
我们希望这些数据集具有自然可解释的特性,使其在探索性分析中更容易被专家所理解。所以特征选择如下:
从相应的分析报告中选择了总共19个数据字段,并将其作为特征包含在目标数据集中。其中,静态分析提取9个,动态分析提取7个,网络流量分析相关特征提取3个。
3.2.1静态分析部分
1)Packers(包装器,多类,多值):
恶意软件开发者可以使用包装器来避免反病毒检测或混淆目的。不同的包装器可以同时使用,本文选择了在一般恶意软件中24个最具有代表性的包装器作为特征。
2)Number of Packers by file(包装器的数量,数值):APT恶意软件样本通常被认为比一般恶意软件样本更复杂,因此可以预期包装者的数量比一般非APT属于恶意软件样本的数量要高,以此作为特征可以判别两种恶意软件之间的关系。
3)Type of detected malware (被检测的恶意软件的种类,多类):这是一个分类特性与以下可能的值:木马,间谍软件,僵尸网络,蠕虫,后门,广告软件,下载,黑客工具,病毒,rootkit或密码窃取。这是卡巴斯基给出的恶意软件的类型。
4)Imports(导入,多类,多值):每个Windows可执行文件都需要使用库函数来实现其功能。通过分析恶意软件实例导入的这些库函数,我们可以大致了解运行的示例将会做什么。选择了200个最典型的**导入函数名(imported function names)**作为特征,
5)imported function names(导入函数的数量):大量的导入可能表明恶意软件样本更复杂。通常,手工编写的APT恶意软件样本比那些由自动化的恶意软件开发工具创建的更复杂,导入函数的数量也越多。
6)Overlays(重叠):重叠是PE文件中没有被PE头覆盖的部分。使用了一个二进制0.1来表示是否有重叠,作为一个特征。
7)Suspicious APIs(可疑的 API,多类,多值):从PEFile Python模块获得可疑api列表,并使用Alazab(2010),Vasilescu等人(2014),Wang等人(2009)提到的函数进行扩展。这产生了一个包含212个典型可疑函数的列表。
8)Language(语言,多类,多值):在Windows PE32可执行文件的资源目录表中发现的不同语言有时可以解释APT的起源及其与其他APT的关系。共有123种语言被视为数据集的特性
9)Number of resources(资源数量,数值):该特性表示在恶意软件可执行文件的 资源目录表中发现的不同资源条目。
3.2.2动态分析部分
1)Anti-debug techniques(反调试技术,多类,多值):许多恶意软件样本使用不同的技术来避免检测和调试。
2)Started Services(初始的服务,多类,多值):从动态分析过程中,可以获得恶意软件运行时打开的Windows服务列表。
3)Suspicious DLLs(可疑的DLL,多类,多值):在所有最初下载的恶意软件样本中,获取了最一般导入DLL文件的列表。选择了100个最常出现的DLL文件作为单独的特征。
4)File-related features(与文件相关的特征,多类,多值):Files_opened, Files_removed,
Files_written, Files_read:这些特性代表了一个二进制目录列表,在恶意软件执行期间,文件被创建、访问、写入和/或删除,在这个过程中不考虑文件名或扩展名。
3.3.3网络流量分析
1)Country of IP addresses for DNS, TCP and UDP traffic(IP地址与流量,多类,多值):从动态分析报告中,我们恢复了访问的IP地址,并运行了一个地理位置脚本来获取与这些IP地址相关的国家代码,这可能会提供有关APT中涉及的组的起源的信息。
3.3.4 最后处理
这19个字段中有一些是多值类别变量,即它们的值是n≥0类别的列表。进一步的分析需要一个编码过程。为此目的,每个字段的K最典型值被保存并编码为二进制特征,使用一种类似于一热编码的方案。这种n - k编码的结果是,预处理后的数据集总共产生了2144个个体特征,其中大部分是二进制特征。
经过一系列的删减和去除没用的数据,留下的特征和种类如下表所示:

最后,对字段的值进行标准化。在这些预处理步骤之后,结果数据集包含总共19547个实例(17960个普通恶意软件和1497个apt相关恶意软件)和1941列。
4.Method (处理数据)
4.1探索性数据分析
1)首先,对预处理数据集的每一对特征之间的线性相关性进行分析。使用的方法是基于Pearson
coefficients (or Pearson’s R).
2)其次,提出了一种降维过程来获得数据集的可视化表示,从而更好地解释数据集,将1941个特征降维到3维,进行可视化投影。可以使用以下两种方法来实现:
- PCA使用正交变换将高维空间转换为低维空间的不相关变量保持最高的方差(Shlens, 2014)。
- T-SNE是一种基于概率分布的计算成对相似性矩阵的原始高维空间的低维嵌入空间和最小化它们之间的分歧,它是一种降维技术,特别适合于保存局部结构,为真实的高维数据集提供了良好的可视化特征。此外,它是一种非线性方法,不像PCA那样强的假设。
- Nassar和Safa(2019)以及David和Netanyahu(2015)已经将T-SNE应用于恶意软件分析领域。
4.2 Feature selection and classification(特征选择和分类)
问题:
1)很明显,一个依赖于大约2000个特性的检测工具可能很难部署到生产环境中,在生产环境中,系统的实用性和轻量级是至关重要的。
2)另一方面,众所周知,在高维空间中分析和组织数据时出现的现象被称为“维数诅咒”(维数太多,容易导致过拟合训练)
3)特征选择过程的目的是获取最具代表性的恶意软件特征,以区分apt所属的恶意软件样本和其他与apt无关的恶意软件样本
可以使用的方法:
其中两种方法为滤波法((variance和χ 2 statistical test)。一个是嵌入式技术(tree-based estimator)
1)variance方差是一种简单的基线方法,它假设具有较低方差的特征是无趣的,基于方差选择出来的特征,它不一定选择高度区别性的特征。
2)χ 2 statistical test显示与目标类别的依赖关系(比如分类的恶意软件是apt相关的还是通用)。
3) tree-based estimator基于树的估计器:计算基于impurity-based feature importances杂质的特征重要性进行分类。这三种技术的应用让我们摒弃了不相关的特性。
4种常用的分类算法:
1 ) Logistic regression:用logistic或s型函数的输入的线性函数来模拟一类的后验概率
2 ) K-NN (k-nearest neighbors):是一种用于分类的非参数方法。一个对象是由它的邻居的多数投票来分类的,该对象被分配到它的k个最近的邻居中最常见的类。
3 ) Random Forest:这是一个简单而强大的分类集成方法。随机森林是一种利用许多决策树的聚合来减少方差和控制分类过拟合的算法(Breiman, 2001)。它创建了几个树,这些树是通过随机选择输入变量来生长的。通过对概率预测求平均得到预测类。
4 )SVM classifier:SVM分类器是一个有监督的学习模型,它的目标是找到一个超平面,使类之间的边界最大化,同时允许最小数量的错误分类(软边界)。超平面由被称为支持向量的数据点的一个小子集确定,通常使用径向基函数或多项式核将数据映射到更容易分离的高维空间。然而,由于这种情况下的特征数量相对较大,因此选择了线性核,因为它期望通过更简单的优化过程提供良好的性能.
5. Experimental results(实验结果)
5.1 Correlation analysis(联合分析)
1)services started 启动服务中的一些特征之间的正相关性最强。
2)导入的函数imported functions和可疑的dll-imported functions之间的正相关性较小。
3)函数和dll之间以及服务和文件之间的相关性也较低。
这意味着通常一些服务是由APT恶意软件一起启动的。这些相关性可以通过以下事实来解释:一组服务通常是一起启动的,由特定导入的函数或同时创建或读取特定文件的服务启动。
4)还有一些行为是恶意软件常见的:如创建读取/写入文件,通过网络发送数据,检查anti软件的存在.
5.2 Dimensionality reduction(维度缩减)
为了获得数据集的可视化表示,将原始数据集降维到三维空间:
使用PCA的结果如下:
从可视化的角度来看是失败的。大多数实例,包括那些与apt相关的恶意软件,沿着一个轴被投射成一个密集的组。不令人满意的结果可能是由于算法强加的强线性假设
使用t-SNE的结果如下:
5.3 Feature selection(特征选择)
使用的方法:
variance方差:选择了 237个特征
χ 2 statistical test:选择了21个特征
tree-based estimator基于树的估计器:选择了56个特征
下图是一些重要特征:
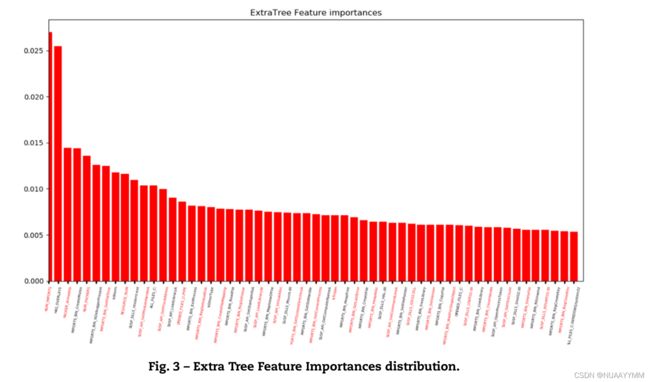
论文给的图就看不清楚。。。。
下面解释上表中比较重要的一些特征项:
1)IMPORTS_GetFileTime:恶意软件经常使用的一种伪装技术是时间践踏,即修改可执行文件的创建和或修改时间的实践(Esposito和Peterson, 2013)。为了执行这项技术,需要同时导入GetFileTime和SetFileTime函数。专业的APT开发人员将从他们的样本中删除尽可能多的信息,因此可以更改尽可能多的时间戳。高达26.4%的apt相关样本导入此功能,而只有2.8%的非apt恶意软件使用此功能
2)IMPORTS_ CreateMutex:互斥对象Mutex被各种可执行程序使用,以了解它们已经在不同的进程中运行。如果已经创建了具有特定名称的互斥锁,它们就不会再执行自己。一旦可执行文件结束,互斥量就消失了。这个导入的函数经常被恶意软件使用。有趣的是,APT示例似乎更倾向于使用这个函数,尽管互斥对象可以通过其他方式创建。根据我们的分析,33%的apt相关样本使用这个导入的功能,而只有5.2%的非apt恶意软件使用它。
3)**HAS_OVERLAYS.:**一般来说,恶意软件样本将从覆盖加载可疑代码到内存。当前的反软件解决方案通常检测覆盖中的可疑代码,将可执行文件标记为可疑代码。因此,APT恶意软件样本不太容易添加可执行代码的覆盖。在我们的数据集中,大约30%的普通恶意软件样本包含覆盖,而只有20%的apt -belong恶意软件使用覆盖。
4)**NUM_IMPORTS:**似乎属于APT活动的恶意软件往往有更多的导入功能。事实上,apt所属的样本平均有26.3个导入函数,而非apt所属的普通恶意软件平均有22个导入函数。(其实这个差别就没那么大了)
5.4 Classification 分类
使用了之前提到的4种二分类算法,效果都比较好,效果图如下所示:
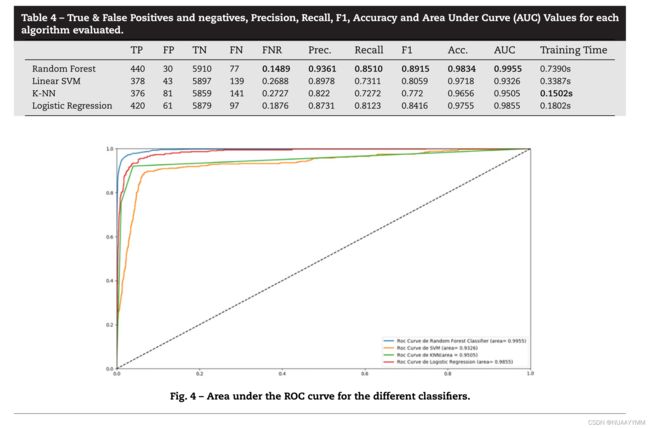
但是这种效果好的前提是假设了恶意软件的的特点是不发展的,是一个静态的,但是实际情况中恶意软件是不断发展的,所以基于这种方法是不能够对新出现的未见过的恶意软件进行正确的分类的。
通过分析发现似乎:APT活动中使用的恶意软件通常比普通恶意软件更复杂
1)与APT相关的样本往往比一般的恶意软件有更少的包装。由于奇怪或多个包装程序的存在是可执行程序恶意性质的最明显的证据之一,APT开发人员可能会更努力地避免使用它们,以便看起来像正常的可执行程序。
2)在APT相关的样本中,避免逆向工程是更多见的方法。它们通过导入的函数(如IsdebuggerPresent)检测它们是在沙箱或虚拟环境中运行的
3)APT相关的恶意软件似乎在可执行文件中的资源较少,使得它们更不容易被杀毒软件检测出来
4)APT相关的恶意软件似乎也更经常使用GetFileTime导入请求他们的文件名和版本,这可能是因为APT活动上下文中恶意软件定期更新的可能性更高。
其他需要考虑的问题:
1)分类器在计算资源方面的性能:一个操作系统最终可以用数百万个样本进行训练,需要考虑计算性能。
2)从恶意软件样本中提取特征及其后续预处理的努力还没有被解决,这是一个重要的点,因为利用上述特征进行分类的在线恶意软件检测器需要不断地从新样本中提取这些特征。虽然静态分析可以快速获得,但动态分析在短时间内可能是一个挑战。
3) It would also be necessary to conduct research inclassification algorithms that are suited for incremental learning, to adapt to the expected concept drift.(增量学习)
6.Conclusion
未来:
1)未来的工作应该着眼于利用这项工作的贡献来开发数据驱动系统,以自动检测apt相关的恶意软件,为此,有必要解决从静态和动态分析中有效提取提议特征的技术挑战(动态分析难以获得),为此,还必须考虑添加其他特征,平衡其潜在的可辨别性和获取难度,从这个意义上说,更彻底地调查apt相关恶意软件产生的网络流量似乎是合理的(因为网络流量相对好获得)。
2)另一方面,评估所提方法的泛化能力也很重要。对一个全新数据集的评估可能会导致对恶意软件发展趋势的了解。
3)研究能够从新的恶意软件实例中进行增量学习的算法将是一件有趣的事情。
遗憾的是本文的数据集似乎并没有公开?