Redis知识点整理(详讲)
Redis整理
方便工作中复习,学习巩固。
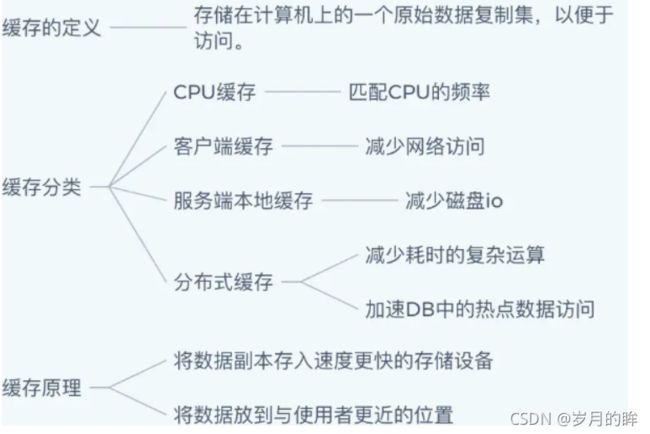
缓存Cache
缓存的概念
- 缓存是存储在计算机上的一个原始数据复制集,以便于访问。
- Web项目常见的缓存场景
缓存击穿
- 概念:
- 对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据
- 原因:
- 缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,该key没有命中,大量请求穿透到数据库服务器
- 解决方案:
- 对于热点数据,慎重考虑过期时间,确保热点期间key不会过期,甚至有些可以设置永不过期。
- 使用互斥锁(比如Java的多线程锁机制),第一个线程访问key的时候就锁住,等查询数据库返回后,把值插入到缓存后再释放锁

缓存雪崩
- 概念:
- 大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
- 缓存服务器宕机,也算做缓存雪崩。
- **原因:**大量缓存在同一时间失效;大量请求落到后端DB上;
- 解决方案:
- 不同的key,设置不同的过期时间(随机值),让缓存失效的时间点尽量均匀;
- 使用高可用的分布式缓存集群,确保缓存的高可用性
- 做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2。
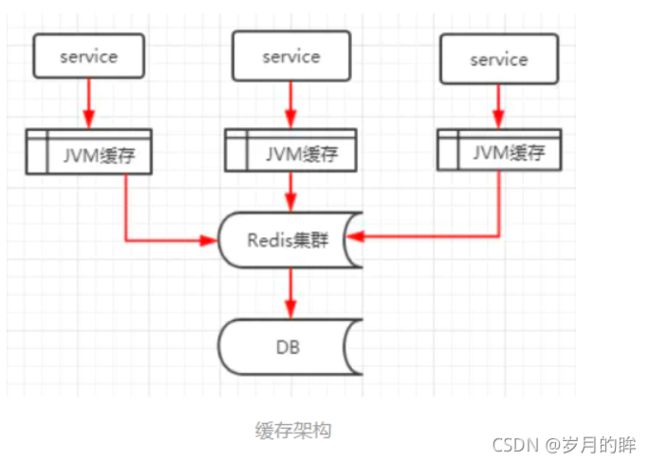
缓存穿透
- 概念:
- 访问一个一定不存在的key,缓存不起作用,请求会穿透到DB,流量大时DB会挂掉
- 原因: key被高并发访问;该key没有命中,去后端DB获取;大量请求穿透到数据库服务器
- 解决方案:
- 布隆过滤器
- 使用一个足够大的bitmap,用于存储可能访问的key,不存在的key直接被过滤,避免对底层数据存储系统造成压力;
- 访问key未在DB查询到值,也将空值写进缓存,但可以设置较短过期时间

- 布隆过滤器
缓存一致性
- 概念:
- 当数据时效性要求很高时,需要保证缓存中的数据与数据库中的保持一致,需要保证缓存节点和副本中的数据也保持一致,不能出现差异现象。(集群同步)
- 原因:
- 对同一个数据进行读写,在数据库层面并发的读写并不能保证完成顺序;
- 发生了写请求A,A的第一步淘汰了cache;A的第二步写数据库,发出修改请求;
- 发生了读请求B,B的第一步读取cache,发现cache中是空的;B的第二步读取数据库,发出读取请求,
- 如果A的第二步写数据还没完成,读出了一个脏数据放入cache;
- 解决方案:
- 一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。
Redis的介绍

官网
- http://www.redis.cn/
- https://redis.io/
Redis简介
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings),散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了复制(replication),LUA脚本(Lua scripting),LRU驱动事件(LRU eviction),事务(transactions)和不同级别的 磁盘持久化(persistence), 并通过Redis哨兵(Sentinel) 和自动分区(Cluster)提供高可用性(high availability)

Redis性能
下面是官方的bench-mark数据:
测试完成了50个并发执行100000个请求。设置和获取的值是一个256字节字符串。
结果:读的速度是110000次/s,写的速度是81000次/s
Redis历史简介
2008年,意大利一家创业公司Merzia的创始人Salvatore Sanfilippo为了避免MySQL的低性能,亲自定做一个数据库,并于2009年开发完成,这个就是Redis.
从2010年3月15日起,Redis的开发工作由VMware主持。
从2013年5月开始,Redis的开发由Pivotal赞助。
说明:Pivotal公司是由EMC和VMware联合成立的一家新公司**。**Pivotal希望为新一代的应用提供一个原生的基础,建立在具有领导力的云和网络公司不断转型的IT特性之上。Pivotal的使命是推行这些创新,提供给企业IT架构师和独立软件提供商。
支持语言

支持的数据类型
string、hash、list、set、sorted set
Redis的安装(SingleNode)
安装依赖
yum -y install gcc-c++ autoconf automake

下载并上传
解压
tar -zxvf redis-5.0.3.tar.gz
预编译和安装
切换到解压目录
cd redis-5.0.3/
## 编译源代码
make MALLOC=libc
## 创建redis的安装目录
mkdir -p /opt/sxt/redis
## 如果需要指定安装路径,需要添加PREFIX参数**
make PREFIX=/opt/sxt/redis/ install


Redis-cli:客户端
Redis-server:服务器端
前台启动
##redis服务默认端口号为6379
./redis-server

后台启动
-
复制redis.conf至安装路径下
-
## 创建一个配置文件目录 mkdir -p /opt/sxt/redis/conf ## 拷贝配置文件到目录中 cp ~/redis-5.0.3/redis.conf /opt/sxt/redis/conf
-
-
修改安装路径下的redis.conf,将
daemonize修改为yes

- 启动时,指定配置文件路径即可

windows客户端访问
安装Redis客户端

修改配置文件redis.conf
注释掉bind 127.0.0.1可以使所有的ip访问redis,若是想指定多个ip访问,但并不是全部的ip访问,可以bind设置

关闭保护模式,修改为no

添加访问认证
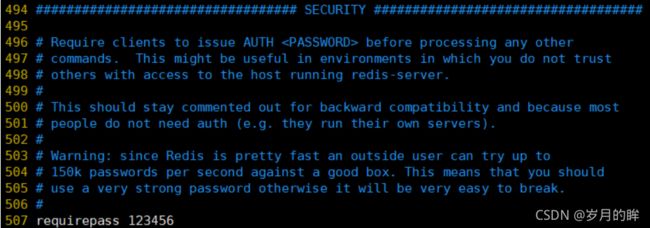
我们可以修改默认数据库的数量 默认16,修改database 32则默认为32个数据库

修改后kill -9 XXXX杀死redis进程,重启redis

再次建立连接 -> 成功

Redis的命令
Redis-cli连接Redis
-h:用于指定ip
-p:用于指定端口
-a:用于指定认证密码
![]()
PING命令返回PONG
![]()
指定database

Redis-cli操作Redis
操作Key
exists 查询key是否存在
keys 查询是否存在指定的key
type 查询key的数据类型
scan 扫描当前库中所有的key
操作String
set:添加一条String类型数据
get:获取一条String类型数据
mset:添加多条String类型数据
mget:获取多条String类型数据
incr:在value基础上加1
decr:在value基础上减1

操作hash
hset:添加一条hash类型数据
hget:获取一条hash类型数据
hmset:添加多条hash类型数据
hmget:获取多条hash类型数据
hgetAll:获取指定所有hash类型数据
hdel:删除指定hash类型数据(一条或多条)

操作list
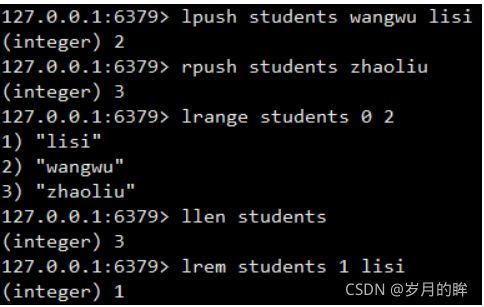
lpush:左添加(头)list类型数据
rpush:右添加(尾)类型数据
lrange: 获取list类型数据start起始下标 end结束下标 包含关系
llen:获取条数
lrem:删除列表中几个指定list类型数据
lrem key count value
count > 0 从前向后删除count个value
count <0 从后向前删除 绝对值(count) 个value
count = 0 删除所有的value
操作set
sadd:添加set类型数据
smembers:获取set类型数据
scard:获取条数
srem:删除数据

操作sorted set(底层用的是跳跃链表)
sorted set是通过分数值来进行排序的,分数值越大,越靠后。
zadd:添加sorted set类型数据
zrange:获取sorted set类型数据
zcard:获取条数
zrem:删除数据
zadd需要将 Float或者 Double类型分数值参数,放置在值参数之前
zscore|ZINCRBY:ZINCRBY key increment member 为有序集key的成员member的score值加上增量increment

操作namespace


操作失效时间
Redis 有四个不同的命令可以用于设置键的生存时间(键可以存在多久)或过期时间(键什么时候会被删除) :
expired 英 /ɪkˈspaɪəd/ adj. 过期的;失效的
EXPIRE :用于将键key的生存时间设置为ttl秒。---->例如 Expire zhangsan 300s
PEXPIRE :用于将键key 的生存时间设置为ttl` 毫秒。—>例如 PExpire zhangsan 3000ms
EXPIREAT :用于将键key的过期时间设置为timestamp所指定的秒数时间戳。例如–>EXPIREAT zhangsna 时间戳
PEXPIREAT :用于将键key的过期时间设置为timestamp所指定的毫秒数时间戳。如->EXPIREAT key 时间戳
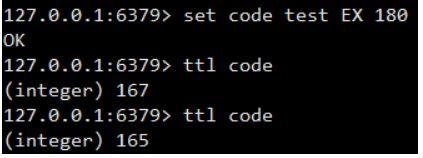
TTL:获取的值为-1说明此key没有设置有效期,当值为-2时证明过了有效期。
方法一
方法二

方法三
第一个参数:key
第二个参数:value
第三个参数:
NX是key不存在时才set,防止覆盖
XX是key存在时才set,不创建新的key
第四个参数:EX是秒,PX是毫秒

删除
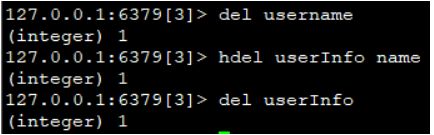
del:用于删除数据(通用,适用于所有数据类型)
hdel:用于删除hash类型数据
Redis的事务机制
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
Redis事务的主要作用就是串联多个命令防止别的命令插队
-
Multi、Exec、discard
- 输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,
- 输入Exec后,Redis会将之前的命令队列中的命令依次执行。
- 组队的过程中可以通过discard来放弃组队、

-
事务的错误处理
- 组队阶段某个命令出现了报告错误,执行时整个的所有队列会都会被取消。
- 执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。
-
事务锁的机制
- 悲观锁
- 乐观锁
- Redis就是利用这种check-and-set机制实现事务的
数据的持久化
redis是一个内存数据库,数据保存在内存中,虽然内存的数据读取速度快,但是很容易发生丢失。Redis还为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Append Only File)
RDB(Redis DataBase)
-
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照,这是默认的持久化方式
-
这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb
-
RDB提供了三种触发机制:save、bgsave、自动化
-
save触发方式
- 该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
-
- 该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
-
bgsave触发模式
- 执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。
- Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。

-
自动触发
-
自动触发是由我们的配置文件来完成的。
-
#配置文件 # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed save 900 1 save 300 10 save 60 10000 #配置文件的意义 服务器在 900 秒之内,对数据库进行了至少 1 次修改 服务器在 300 秒之内,对数据库进行了至少 10 次修改 服务器在 60 秒之内,对数据库进行了至少 10000 次修改 -
stop-writes-on-bgsave-error
-
# However if you have setup your proper monitoring of the Redis server # and persistence, you may want to disable this feature so that Redis will # continue to work as usual even if there are problems with disk, # permissions, and so forth. # 默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。 stop-writes-on-bgsave-error yes -
rdbcompression
# Compress string objects using LZF when dump .rdb databases? # For default that's set to 'yes' as it's almost always a win. # If you want to save some CPU in the saving child set it to 'no' but # the dataset will likely be bigger if you have compressible values or keys. # 默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。rdbcompression yes-
rdbchecksum
-
# RDB files created with checksum disabled have a checksum of zero that will# tell the loading code to skip the check. # 默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗rdbchecksum yes -
dbfilename
-
# The filename where to dump the DB# 设置快照的文件名,默认是 dump.rdbdbfilename dump.rdb -
dir
-
# The working directory.# The DB will be written inside this directory, with the filename specified# above using the 'dbfilename' configuration directive.# The Append Only File will also be created inside this directory.# Note that you must specify a directory here, not a file name.# 设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名dir ./
-
-
-
RDB的优势和劣势
- 优势:
- RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
- 生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- 劣势
- 当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,
- 父进程修改内存子进程不会反应出来,
- 所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
- 优势:
AOF(Append Only File)
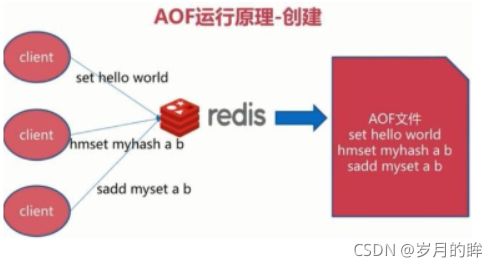
- 全量备份总是耗时的,有时候我们提供一种更加高效的方式AOF,工作机制很简单,redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。
-
rewrite策略
- 重写日志,减少日志文件的大小,redis提供了bgrewriteaof命令。
- 将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。
- 将整个内存中的数据库内容用命令的方式重写了一个新的aof文件
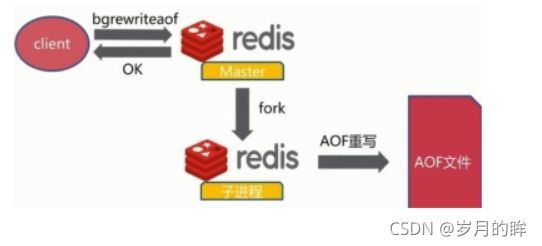
-
AOF配置信息
############################## APPEND ONLY MODE ###############################
# By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
appendonly no
# The name of the append only file (default: "appendonly.aof")appendfilename "appendonly.aof"
# Redis supports three different modes:
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log. Slow, Safest.
# everysec: fsync only one time every second. Compromise.
# appendfsync always
appendfsync everysec
# appendfsync no
# 重写的时机-条件
# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
-
AOF的触发策略
- 每修改同步always
- 同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
- 每秒同步everysec:
- 异步操作,每秒记录 如果一秒内宕机,有数据丢失
- 不同no:
- 从不同步
- 每修改同步always
-
AOF的优势和劣势
- 优势
- AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
- AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
- AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
- AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。
- 劣势
- 对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
- AOF支持的写QPS会比RDB支持的写QPS低
- QPS:Queries Per Second意思是“每秒查询率”
- **TPS:**是TransactionsPerSecond的缩写,也就是事务数/秒
- 优势
RDB和AOF的选择
- 成年人不做选择题
- 如果同时使用AOF和RDB,那么启动时以AOF为恢复数据的模板
- 选择的话,两者加一起才更好。
- 因为两个持久化机制你明白了,剩下的就是看自己的需求了,需求不同选择的也不一定,但是通常都是结合使用

主从复制集群
Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。

搭建主从服务器
-
在Redis主配置文件文件夹中创建配置文件
-
主节点配置文件
## 导入一个通用配置文件
include /opt/sxt/redis/conf/redis.conf
## 当前主服务器端口
port 7100
## 设置主服务密码
requirepass 123456
## 当前主服务进程ID
pidfile /var/run/redis_7100.pid
## 当前主服务RDB文件名称
dbfilename dump7100.rdb
## 当前主服务文件存放路径
dir /opt/sxt/redis/conf/
-
从节点需要配置
- 直接在配置文件中添加(永久)
##导入一个通用配置文件
include /opt/sxt/redis/conf/redis.conf
##当前主服务器端口
port 7200
##当前主服务进程ID
pidfile /var/run/redis_7200.pid
##当前主服务RDB文件名称
dbfilename dump7200.rdb
##当前主服务文件存放路径
dir /opt/sxt/redis/conf/
##同步master节点的网络信息(低版本必须使用slaveof,高版本推荐使用replicaof)
replicaof 127.0.0.1 7100
##设置master节点的密码信息
masterauth 123456
##从节点只做读的操作,保证主从数据的一致性
slave-read-only yes
-
在redis客户端命令行中输入(临时)
- replicaof 127.0.0.1 7100
- config set masterauth 123456
-
结束从服务器的命运(结束)
- slaveof no one
数据同步机制
Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。
- 全量同步
- Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;

- 增量同步
- Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
- 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
- 主从复制的异步特性
- 主从复制对于主redis服务器来说是非阻塞的
- 这意味着当从服务器在进行主从复制同步过程中,主redis仍然可以处理外界的访问请求;
- 主从复制对于从redis服务器来说也是非阻塞的
- 这意味着,即使从redis在进行主从复制过程中也可以接受外界的查询请求,只不过这时候从redis返回的是以前老的数据
- 主从复制对于主redis服务器来说是非阻塞的
服务器断线重连
- Redis 2.8开始,如果遭遇连接断开,重新连接之后可以从中断处继续进行复制,而不必重新同步
- 部分同步的实现依赖于在master服务器内存中给每个slave服务器维护了一份同步日志和同步标识
- 每个slave服务器在跟master服务器进行同步时都会携带自己的同步标识和上次同步的最后位置
- 当主从连接断掉之后,slave服务器隔断时间(默认1s)主动尝试和master服务器进行连接
- 如果从服务器携带的偏移量标识还在master服务器上的同步备份日志中
- 那么就从slave发送的偏移量开始继续上次的同步操作
- 如果slave发送的偏移量已经不再master的同步备份日志中,则必须进行一次全量更新

Redis的哨兵
Redis的主从复制模式下,一旦主节点由于故障不能提供服务,需要手动将从节点晋升为主节点,同时还要通知客户端更新主节点地址
Sentinel哨兵是redis官方提供的高可用方案,可以用它来监控多个Redis服务实例的运行情况
哨兵功能与作用
- 监控(monitoring):
- Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notifation):
- 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障转移(Automatic failover):
- 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。

哨兵工作原理
- 在redis sentinel中,一共有3个定时任务,通过这些任务,来发现新增节点和节点的状态。
- 每10秒每个sentinel节点对master节点和slave节点执行info操作
- 每2秒每个sentinel节点通过master节点的channel(sentinel:hello)交换信息
- 每1秒每个sentintel节点对master节点和slave节点以及其余的sentinel节点执行ping操作
- 主观下线(SDOWN):当前sentintel节点认为某个redis节点不可用。
- 如果一个实例(instance)距离最后一次有效回复PING命令的时间超过down-after-milliseconds所指定的值,那么这个实例会被Sentinel标记为主观下线。
- 如果一个主服务器被标记为主观下线,那么正在监视这个主服务器的所有Sentinel节点,要以每秒一次的频率确认主服务器的确进入了主观下线状态。
- 客观下线(ODOWN)一定数量sentinel节点认为某个redis节点不可用。
- 如果一个主服务器被标记为主观下线,并且有足够数量的Sentinel(至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断,那么这个主服务器被标记为客观下线。
- 在一般情况下,每个Sentinel会以每10秒一次的频率,向它已知的所有主服务器和从服务器发送INFO命令。当一个主服务器被Sentinel标记为客观下线时,Sentinel向下线主服务器的所有从服务器发送INFO命令的频率,会从10秒一次改为每秒一次。
- Sentinel和其他Sentinel协商主节点的状态,如果主节点处于SDOWN状态,则投票自动选出新的主节点。将剩余的从节点指向新的主节点进行数据复制。
- 当没有足够数量的Sentinel同意主服务器下线时,主服务器的客观下线状态就会被移除。当主服务器重新向Sentinel的PING命令返回有效回复时,主服务器的主观下线状态就会被移除。
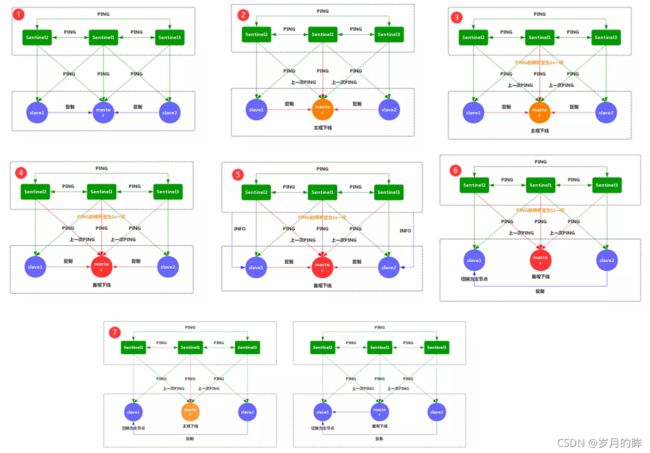
故障转移流程
-
哨兵内部领导者选举
-
1). 每个做主观下线的sentinel节点向其他sentinel节点发送上面那条命令,要求将它设置为领导者。
2). 收到命令的sentinel节点如果还没有同意过其他的sentinel发送的命令(还未投过票),那么就会同意,否则拒绝。
3). 如果该sentinel节点发现自己的票数已经过半且达到了quorum的值,就会成为领导者。
4). 如果这个过程出现多个sentinel成为领导者,则会等待一段时间重新选举。
-
-
Master选举
- 选择slave-priority最高的slave节点
- 选择复制偏移量最大的节点
- 选runId最小的(启动最早)
-
状态更换
- 选举出新的master节点,其余的节点变更为新的master节点的slave节点
- 原有的master节点重新上线,成为新的master节点的slave节点
-
通知客户端
- 当所有节点配置结束后,sentinel会通知客户端节点变更信息。
- 客户端连接新的master节点
哨兵环境搭建
-
搭建多台计算机的主从集群
-
Host 端口 节点分类 Sentinel 192.168.204.161 20601 master 20600 192.168.204.162 20601 slave 20600 192.168.204.163 20601 slave 20600 -
Master节点
-
## 导入一个通用配置文件
include /opt/sxt/redis/conf/redis.conf
## 当前主服务器IP和端口
bind 0.0.0.0
port 20601
## 去掉安全模式
protected-mode no
## 设置主服务密码
requirepass 123456
## 当前主服务进程ID
pidfile /var/run/redis_20601.pid
## 当前主服务RDB文件名称
dbfilename dump20601.rdb
## 当前主服务文件存放路径
dir /opt/sxt/redis/conf/
## 设置master节点的密码信息
masterauth 123456
## 设置时候后台启动
daemonize no
- Slave节点
## 导入一个通用配置文件
include /opt/sxt/redis/conf/redis.conf
## 当前主服务器IP和端口
bind 0.0.0.0
port 20601
## 去掉安全模式
protected-mode no
## 设置主服务密码
requirepass 123456
## 当前主服务进程ID
pidfile /var/run/redis_20601.pid
## 当前主服务RDB文件名称
dbfilename dump20601.rdb
## 当前主服务文件存放路径
dir /opt/sxt/redis/conf/
## 同步master节点的网络信息(低版本必须使用slaveof,高版本推荐使用replicaof)
replicaof 192.168.204.161 20601
## 设置master节点的密码信息
masterauth 123456
## 从节点只做读的操作,保证主从数据的一致性
slave-read-only yes
## 设置时候后台启动
daemonize no
- 三台计算机分别启动Redis
- redis-server /opt/sxt/redis/conf/redis20601.conf
- 一个稳健的RedisSentinel集群,应该使用至少三个Sentinel实例,并且保证将这些实例放到不同的机器上,甚至不同的物理区域
## redis-sentinel /opt/sxt/redis/conf/sentinel.conf
## 设置哨兵的接口
port 20600
## sentinel monitor 关键字
## master20601 给主从服务器集群起一个名字(监控主服务器,从服务器的信息也就获取了)
## 192.168.204.161 20601 主服务器的IP和端口
## 2主服务器失效的统计数,超过2票就认为失效
sentinel monitor master20601 192.168.204.161 20601 2
## 设置主服务器密码
sentinel auth-pass master20601 123456
## 主服务器下线超过10秒就进行切换(默认30S)
sentinel down-after-milliseconds master20601 10000
## 故障转移超时时间
sentinel failover-timeout master20601 180000
## 故障转移时,允许有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长
sentinel parallel-syncs master20601 1
## 关闭安全校验
protected-mode no
Redis的高可用
在Redis中,实现高可用的技术主要包括持久化、复制、哨兵和集群,下面简单说明它们的作用,以及解决了什么样的问题:
-
持久化:持久化是最简单的高可用方法。它的主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
-
复制:复制是高可用Redis的基础,哨兵和集群都是在复制基础上实现高可用的。
- 复制主要实现了数据的多机备份以及对于读操作的负载均衡和简单的故障恢复。
- 缺陷是故障恢复无法自动化、写操作无法负载均衡、存储能力受到单机的限制。
-
哨兵:在复制的基础上,哨兵实现了自动化的故障恢复。缺陷是写操作无法负载均衡,存储能力受到单机的限制。
-
集群:通过集群,Redis解决了写操作无法负载均衡以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
集群设计思想
- cluster可以说是sentinel和主从模式的结合体,通过cluster可以实现主从和master重选功能
- 不同节点分别管理不同的key
- 同一个Key的操作只让一个master去处理
- 为了保证master节点的(单点故障和效率)问题,每个主节点至少准备一个slave节点
- 集群是一个可以在多个 Redis 节点之间进行数据共享的设施
- 集群不支持那些需要同时处理多个键的 Redis 命令
一致性Hash
业务场景
- 一个电商平台,需要使用Redis存储商品的图片资源,存储的格式为键值对,key值为图片名称,Value为该图片所在的文件服务器的路径,我们需要根据文件名,查找到文件所在的文件服务器上的路径,我们的图片数量大概在3000w左右,按照我们的规则进行分库,规则就是随机分配的,我们以每台服务器存500w的数量,部署12台缓存服务器,并且进行主从复制

- 使用Hash的方式,每一张图片在进行分库的时候都可以定位到特定的服务器
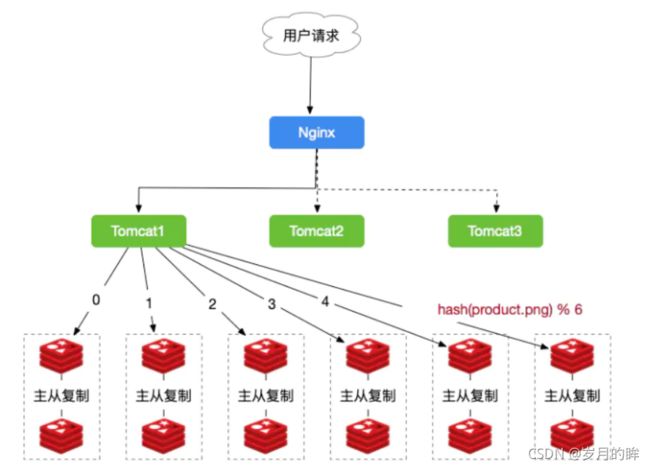
-
问题:
- Redis服务器变动时,所有缓存的位置都会发生改变
- Redis缓存服务器6台增加到了8台
- Redis缓存服务器6台的服务器集群中出现故障时减少到5台
- Redis服务器变动时,所有缓存的位置都会发生改变
算法原理
- 取模
- 一致性的Hash算法是对
2的32方取模 - 整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1
- 这个由2^32个点组成的圆环称为Hash环
- 一致性的Hash算法是对
- 服务器
- 将各个服务器使用Hash进行一个哈希,这样每台机器就能确定其在哈希环上的位置
- 数据
- 数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置
- 定位
- 沿环顺时针“行走”,第一台遇到的服务器就是数据应该定位到的服务器
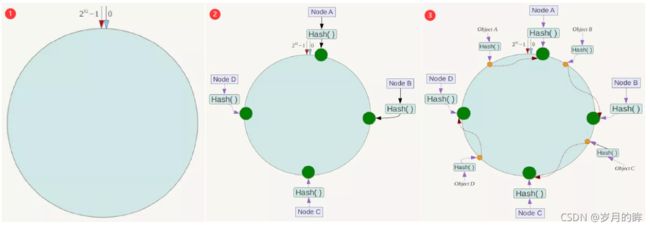
算法容错性
-
当我们添加服务器或者删除服务器
-
它只影响处理节点的下一个节点
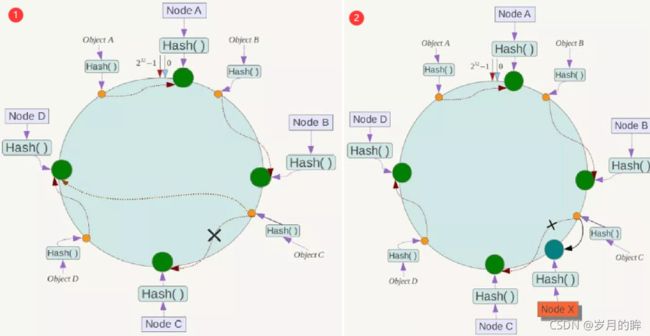
数据倾斜与虚拟节点
-
均匀一致性hash的目标是如果服务器有N台,客户端的hash值有M个,
-
那么每个服务器应该处理大概M/N个用户的。也就是每台服务器负载尽量均衡

Redis的Slot槽
- Redis集群使用数据分片(sharding)而非一致性哈希(consistencyhashing)来实现:
- 一个Redis集群包含16384个哈希槽(hashslot),数据库中的每个键都属于这16384个哈希槽的其中一个,集群使用公式CRC16(key)%16384来计算键key于哪个槽,其中CRC16(key)语句用于计算键key的CRC16校验和
- 将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞,所以无论是添加新节点还是移除已存在节点,又或者改变某个节点包含的哈希槽数量,都不会造成集群下线。
- 对象保存到Redis之前先经过CRC16哈希到一个指定的Node上
- 每个Node被平均分配了一个Slot段,对应着0-16383,Slot不能重复也不能缺失,否则会导致对象重复存储或无法存储。
- Node之间也互相监听,一旦有Node退出或者加入,会按照Slot为单位做数据的迁移
- Node1如果掉线了,0-5640这些Slot将会平均分摊到Node2和Node3上
- 优缺点
- 优点:
- 将Redis的写操作分摊到了多个节点上,提高写的并发能力,扩容简单。
- 缺点:
- 每个Node承担着互相监听、高并发数据写入、高并发数据读出,工作任务繁重
- 优点:

搭建集群环境
节点分布
-
Host Master Slave 192.168.204.161 30601 30602 192.168.204.162 30601 30602 192.168.204.163 30601 30602
配置文件
## 导入默认配置文件
include /opt/sxt/redis/conf/redis.conf
## 当前主服务器Host和端口
bind 0.0.0.0
port 30601
## 后台模式运行
daemonize no
## 关闭保护模式
protected-mode no
## 设置主服务密码
requirepass 123456
## 设置从服务器密码
masterauth 123456
## 当前主服务进程ID
pidfile /var/run/redis_30601.pid
## 当前主服务RDB文件名称
dbfilename dump30601.rdb
## 当前主服务文件存放路径
dir /opt/sxt/redis/conf/
## 开启aof持久化方式
appendonly yes
## 设置AOF文件名字
appendfilename "appendonly30601.aof"
##集群相关
cluster-enabled yes
cluster-config-file nodes-30601.conf
cluster-node-timeout 5000
## 导入默认配置文件
include /opt/sxt/redis/conf/redis.conf
## 当前主服务器Host和端口
bind 0.0.0.0
port 30602
## 后台模式运行
daemonize no
## 关闭保护模式
protected-mode no
## 设置主服务密码
requirepass 123456
## 设置从服务器密码
masterauth 123456
## 当前主服务进程ID
pidfile /var/run/redis_30602.pid
## 当前主服务RDB文件名称
dbfilename dump30602.rdb
## 当前主服务文件存放路径
dir /opt/sxt/redis/conf/
## 开启aof持久化方式
appendonly yes
## 设置AOF文件名字
appendfilename "appendonly30602.aof"
##集群相关
cluster-enabled yes
cluster-config-file nodes-30602.conf
cluster-node-timeout 5000
- 分别启动6个节点
redis-server /opt/sxt/redis/conf/redis20601.conf
redis-server /opt/sxt/redis/conf/redis20602.conf
构建集群
# --cluster-replicas 1 表示主从配置比,1表示的是1:1,前三个是主,后三个是从
# 若配置文件中设置的密码,则还需要加上-a passwod
redis-cli --cluster create 192.168.204.161:30601 192.168.201.102:30601
192.168.201.103:30601
192.168.204.161:30602 192.168.201.102:30602 192.168.201.103:30602 --cluster-replicas 1 -a 123456

- 查看集群信息
redis-cli -h 127.0.0.1 -p 20601 -a 123456
# 查看集群信息
cluster info
# 查看节点列表
cluster nodes
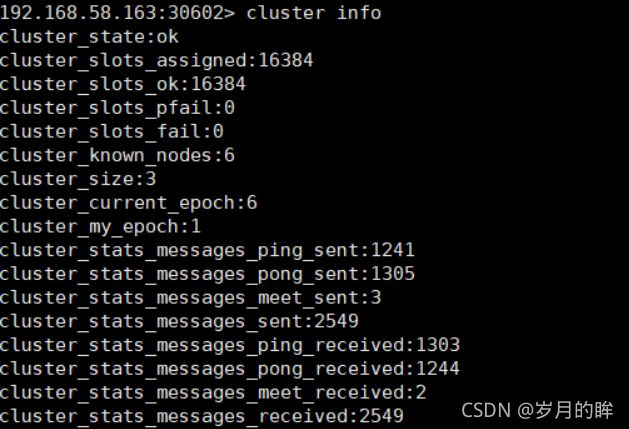

访问集群
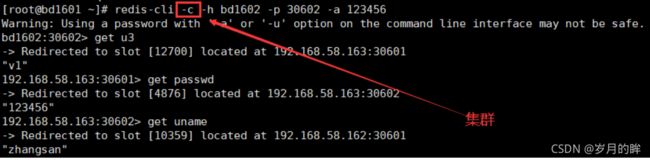
- redis-cli -h bd1602 -p 30602 -a 123456

- redis-cli -c -h bd1602 -p 30602 -a 123456
Redis的常见场景
用户回复频率控制
- 项目的社区功能里,不可避免的总是会遇到垃圾内容,一觉醒来你会发现首页突然会被某些恶意的帖子和广告刷屏了,如果不采取适当的机制来控制就会导致用户体验受到严重的影响
- 控制广告垃圾贴的策略很多,高级一点的可以通过AI,最简单的方式是通过关键词扫描,还有比较常用的一种方式是频率控制,限制单个用户内容的生产速度,不通等级的用户会有不同的频率控制参数
- 使用Redis来实现频率控制(青铜1小时3贴 白银1小时5贴 黄金1小时8贴)
斗鱼日榜

24小时热销榜
- 如果小说榜单只有10个位置,那么对于第11名小说太不公平
- 那么如果借助于10个位置显示前20名的小说???

统计每日活跃用户
-
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
-
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
摇一摇快速获取距离
- GEO功能在Redis3.2版本提供,支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能.geo的数据类型为zset.
- https://blog.csdn.net/qq_34206560/article/details/91049218
云村的重逢/致爱梵高,自由旋转的向日葵