爬虫学习日记第六篇(异步爬虫之多进程、线程池和实战项目爬取新发地价格行情)
文章目录
-
- 异步爬虫的方式:
- 多线程、多进程
-
- 多线程
- 自定义线程类
- 多进程
- 线程池的简单使用
- 线程池项目实战
异步爬虫的方式:
1、多线程、多进程(不建议):
好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步执行
弊端:无法无限制的开启多线程或者多进程
2、线程池、进程池:
好处:可以降低系统对进程或者线程创建和销毁的一个频率,从而很好的降低系统的开销
弊端:池中线程或进程的数量是有上限的
多线程、多进程
多线程
from threading import Thread
def func():
for i in range(1000):
print("func",i)
if __name__=="__main__":
t=Thread(target=func) #创建线程并给线程安排任务
t.start()
for i in range(1000):
print("main",i)
from threading import Thread
t=Thread(target=func)
t.start()
#这里比如给func函数增加个参数
t=Thread(target=func,args=(‘周杰伦’,)) #线程传参,args传入的必须是元组
自定义线程类
from threading import Thread
class MyThread(Thread):
def run(self):
for i in range(1000):
print("子线程",i)
if __name__=="__main__":
t=MyThread()
t.start()
for i in range(1000):
print("主线程",i)
多进程
(一般不建议使用多进程,消耗资源比多线程大得多)
from multiprocessing import Process
def func():
for i in range(1000):
print("子进程",i)
if __name__=="__main__":
p=Process(target=func)
p.start()
for i in range(1000):
print("主进程",i)
from multiprocessing import Process
p=Process(target=func)
p.start()
线程池的简单使用
应该是两种不同线程池
第一种
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
def fn(name):
for i in range(1000):
print(name,i)
if __name__=="__main__":
#创建线程池
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(fn,name=f"线程{i}")
#等待线程池中的任务全部执行完毕,才继续执行(守护)
print('123')
第二种
import time
#导入线程池模块对应的类
from multiprocessing.dummy import Pool
start_time=time.time()
def get_page(str):
print("正在下载:"+str)
time.sleep(2)
print("下载成功:"+str)
name_list=['aa','bb','cc','dd','ee','ff']
#实例化一个线程池对象
pool=Pool(processes=6)
#将列表中每一个列表元素传递给get_page进行处理
pool.map(get_page,name_list)
end_time=time.time()
print(end_time-start_time)
线程池项目实战
爬取新发地价格行情
http://www.xinfadi.com.cn/priceDetail.html
有四十多万条数据
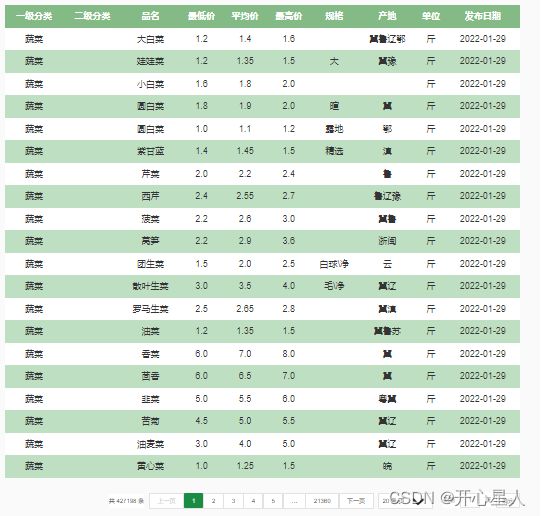
首先页面数据是动态加载出来的
抓ajax包
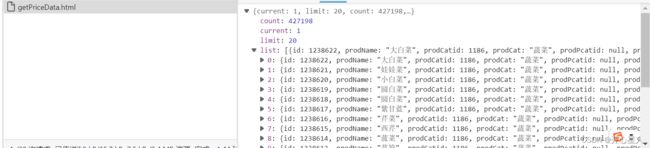
不管在第几页current都会是1
对这个ajax包发起请求,携带参数current=3试一下,没问题,拿到了数据
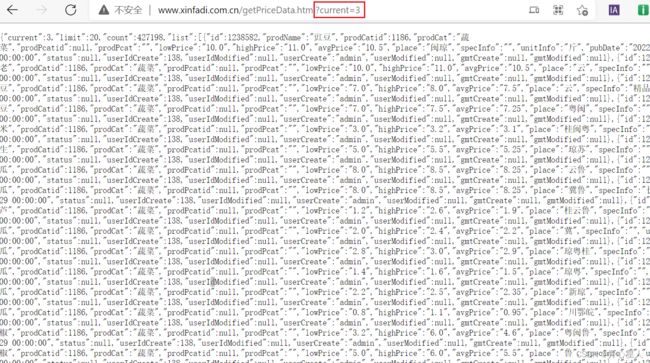
好了可以写代码了
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
f=open("data.csv","w",encoding='gb18030', errors='ignore')
f.write('prodName,avgPrice,highPrice,lowPrice,place,prodCat')
def download_one_page_data(url):
response = requests.get(url=url)
list_data = response.json()['list']
for i in list_data:
ls = [str(i['prodName']),str(i['avgPrice']),str(i['highPrice']),str(i['lowPrice']), str(i['place']),str(i['prodCat'])]
f.write(",".join(ls) + "\n")
if __name__=="__main__":
with ThreadPoolExecutor(500) as t:
for i in range(1, 2130):
# 把下载任务提交给线程池
t.submit(download_one_page_data, f"http://www.xinfadi.com.cn/getPriceData.html?current={i}")
print(f"第{i}页数据下载成功")
视频学习链接1、视频学习链接2,我是跟着这两个视频学习的