2020-09-25

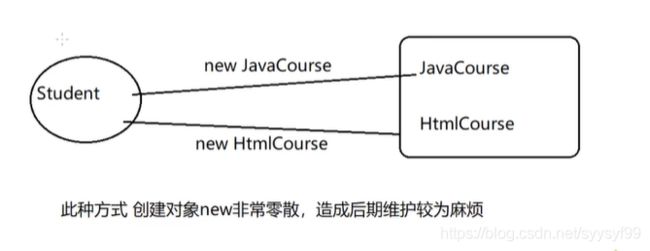
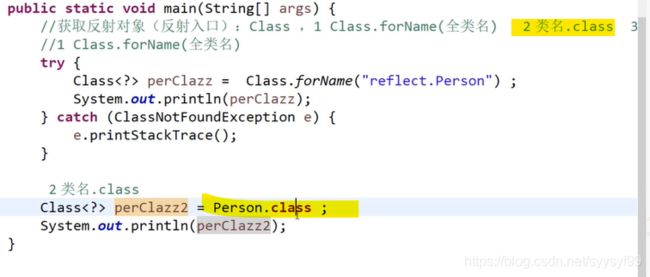
第一种方式:最原始的方式

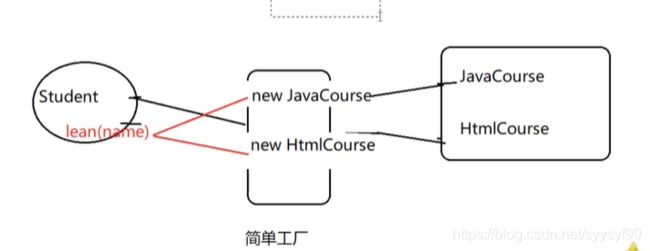
改进:第二种方式:简单工厂


改进:第三种方式:简单工厂方法中工厂是自己写的,第三种Spring IOC,工厂不需要自己写。
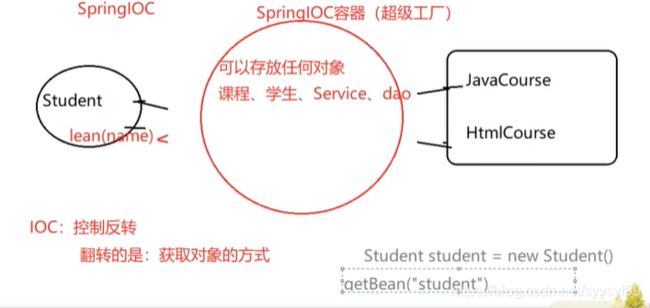
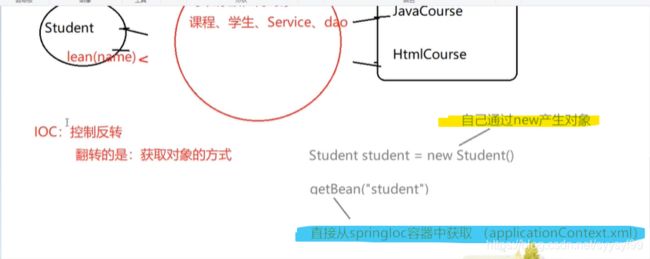


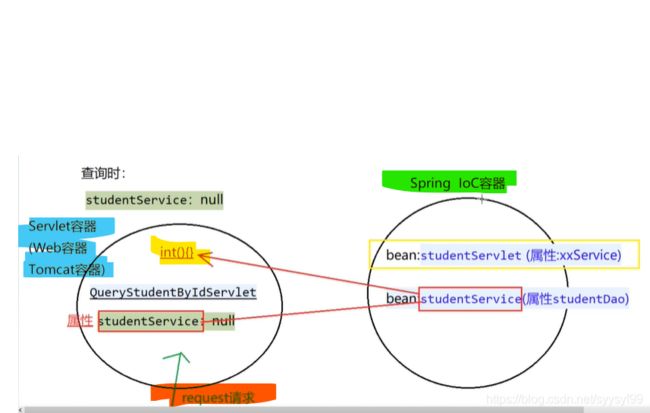
上图箭头的方向就表示了:将属性值value注入给属性name,将属性注入给bean(id),将bean注入给容器。


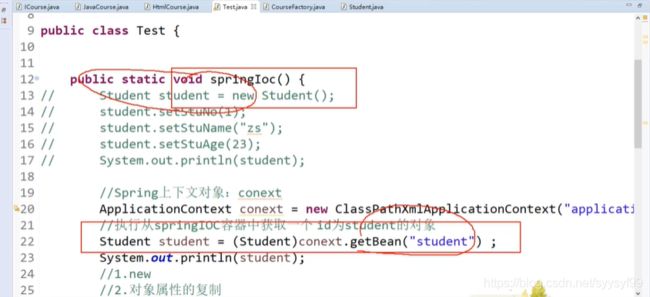
上面程序中被注释掉的部分是第二种方法:简单工厂。后来更新的代码是用的SpringIOC容器。

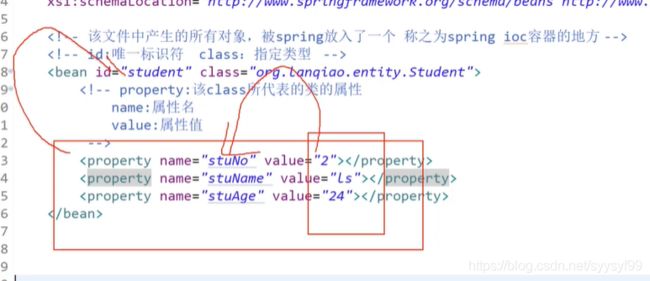
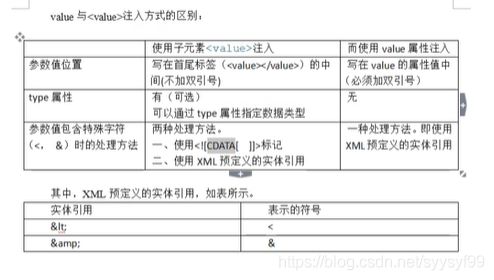
set注入底层是反射,通过属性值调用set方法。set注入使用到property标签。

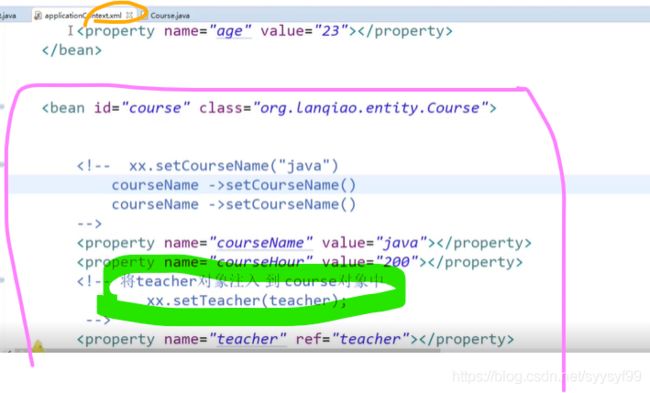





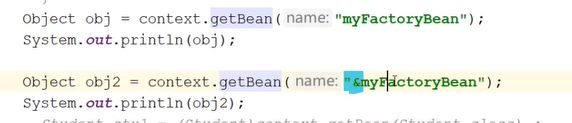
增加上图绿色指定的那条语句。
![]()
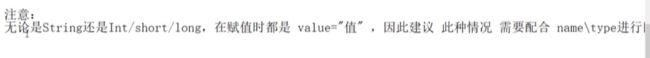

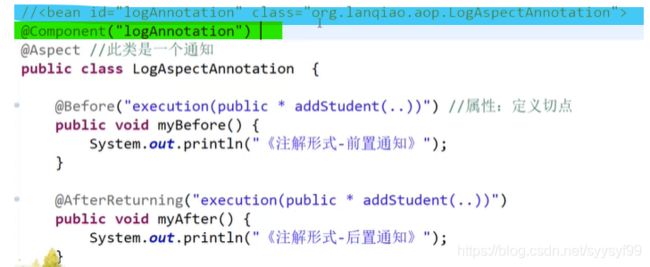






第二种方式即上图中的方式b。是在第一种方式a的基础上,实现类不需要写了,因为第二种方法是实现的接口,但是配置是仍然需要配置的,property标签。

具体解释注解形式时在容器中存bean:

如上图,三层组件对应的三个不同的注解:@Controller @Service @Repository。这三个注解都可以用@Component注解来代替。
如果是三层组件,这三层组件如何放入IOC容器:
(1)给三层组件分别加上注解。
bean只关心两个值:一个是id值,一个是class类型。





上图中的方法一适用于@Bean+方法返回值的情况。

上图中的方法二适用于:扫描器+三层注解。具体例子如下:
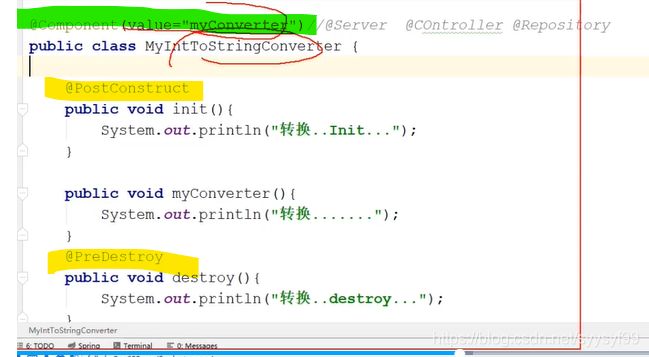
上图中类需要用三层组件的注解如@Controller或者@Service或者@Repository或者@Component来修饰。然后类中被@PostConstruct修饰的方法是初始化方法,被@PreDestroy修饰的方法是销毁方法。




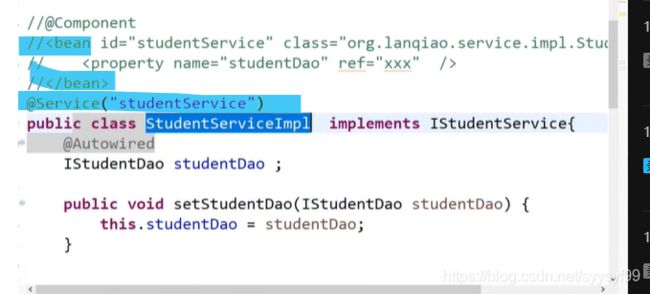
上图中的注解等同于被注释掉的bean标签的内容。其中bean标签中的property标签的内容等同于在类中Autowired注解的作用。
解释SpringIOC容器,如果使用了xml配置文件的话,那么IOC容器就是指的这个配置xml文件。
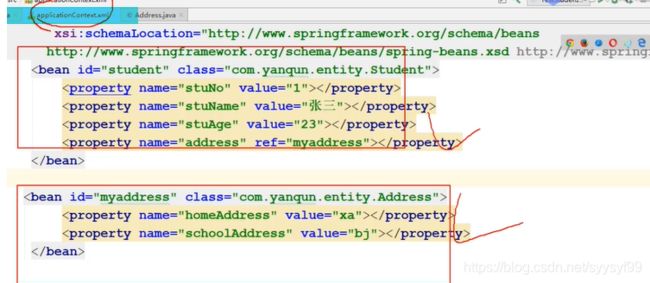
如上图所示,IOC容器就是指的xml文件,图中xml文件即IOC容器中配置了两个Bean。
第二种方式:可以利用注解的方式将bean注入到IOC容器。那么被@Configuration注释的配置类就是IOC容器。配置类被注入到IOC容器,其id值就是类名的首字母小写。
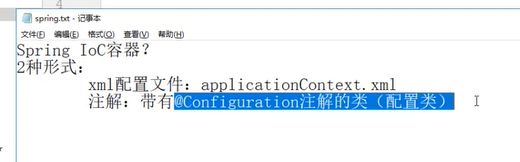
IOC容器的作用:
1.存bean:
(1)如果是xml文件,就是在xml文件中写入bean标签。
(2)如果是注解,往容器中存bean是通过@Bean注解+方法的返回值,把方法的返回值注入到容器。
2.取bean
(1)如果是xml文件,那么取bean是通过容器中的上下文对象来获取的。
(2)如果是注解,取bean的思路与(1)是类似的,区别在于使用的方法及方法中参数的区别。


xml文件取bean的具体例子:

注解时存bean的具体例子:无参数

注解时存bean的具体例子:有参数
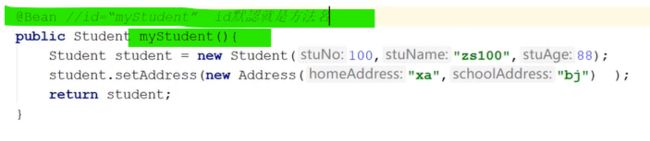
下图中Bean的id值就是方法名,如果不想要是方法名的话,可以在@Bean注解后面添加括号,括号里进行id值的赋值。

Spring Bean的作用域,基本只使用单例和原型两个作用域。




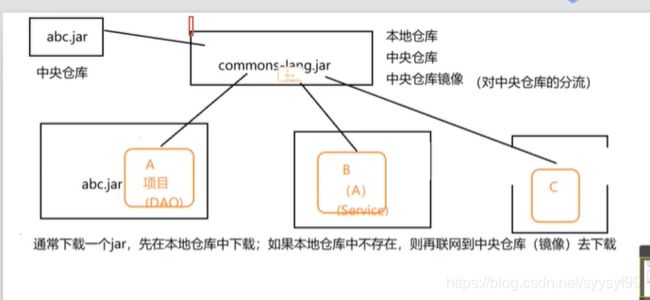


上图中蓝色部分gav指的是groupId以及artifactId以及version。




zookeeper原生API使用不便。Curator比我们上一篇介绍的zkclient更加的强大,其帮助我们在zookeeper原生API基础上进行封装、实现一些开发细节,包括接连重连、反复注册Watcher和NodeExistsException等。阿里开源的RPC框架的新版本用的就是Curator。Curator还提供了Zookeeper的各种应用场景:分布式锁、Master选举机制和分布式计数器等。
ACL全称为Access Control List 即访问控制列表,用于控制资源的访问权限。zookeeper利用ACL策略控制节点的访问权限,如节点数据读写、节点创建、节点删除、读取子节点列表、设置节点权限等。
当前查找maven中央仓库时,curator的最新版本已经到了4.0.1,但是3.X和4.X版本是只支持zookeeper3.5.X的,而2.X是支持zookeeper的3.4.X的,由于我安装的是zookeeper的3.4.6所以选用的curator的2.X的最新版本2.12.0,我项目中添加的依赖如下
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
添加recipes的pom依赖后,自动添加了framework和client的依赖,所以我们项目中添加一个curator-recipes的依赖就够了

curator API使用介绍
使用Fluent风格的Api创建连接
//1 重试策略:初试时间为1s 重试10次
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(CONNECT_ADDR)
.connectionTimeoutMs(SESSION_OUTTIME)
.retryPolicy(retryPolicy)
.namespace("super")
.build();
上面的创建方法中,有一个namespace(“super”)的方法,其实就是命名空间。为了实现不同的Zookeeper业务之间的隔离,需要为每个业务分配一个独立的命名空间(NameSpace),即指定一个Zookeeper的根路径(官方术语:为Zookeeper添加“Chroot”特性)。例如(上面的例子)当客户端指定了独立命名空间为“/super”,那么该客户端对Zookeeper上的数据节点的操作都是基于该目录进行的。通过设置Chroot可以将客户端应用与Zookeeper服务端的一颗子树相对应,在多个应用共用一个Zookeeper集群的场景下,这对于实现不同应用之间的相互隔离十分有意义。
当创建会话成功,得到client的实例,然后可以直接调用其start( )方法启动客户端:client.start();
curator API使用介绍:crud操作zookeeper节点
1.添加节点
下面代码创建了一个临时节点,如果不指定withMode默认为持久化节点。creatingParentsIfNeeded()方法表示如果父节点不存在,会帮助我们自动创建父节点,而不会去报错。
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).
forPath("/ephemeral/a", "创建临时节点".getBytes());
2.修改节点
下面代码对节点内容进行了修改,withVersion(1000)方法指定了节点的版本号,如果版本号不匹配则无法更新节点数据
client.setData().withVersion(1000).forPath("/persistent", "新内容".getBytes());
4.删除节点
下面代码为强制删除当前节点。guaranteed()接口是一个保障措施,只要客户端会话有效,那么Curator会在后台持续进行删除操作,直到删除节点成功。
client.delete().guaranteed().forPath("/persistent");
curator API使用介绍:事务
CuratorFramework的实例包含inTransaction( )接口方法,调用此方法开启一个ZooKeeper事务. 可以复合create, setData, check, and/or delete 等操作然后调用commit()作为一个原子操作提交。
client.inTransaction().check().forPath("/a")
.and()
.create().forPath("/a","a".getBytes())
.and()
.setData().forPath("/b", "b".getBytes())
.and().commit();
curator API使用介绍:异步接口操作
我们上面给出的crud等方法都是同步的,Curator提供异步接口,引入了BackgroundCallback接口用于处理异步接口调用之后服务端返回的结果信息。BackgroundCallback接口中一个重要的回调值为CuratorEvent,里面包含事件类型、响应吗和节点的详细信息等(可以查看一下CuratorEvent的源码)。注意:BackgroundCallback的异步回调是一次性的,只在当前操作有效,后面再对该节点进行inBackground()的操作,也不会再触发回调。
ExecutorService pool = Executors.newCachedThreadPool();
client.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT)
.inBackground(new BackgroundCallback() {
@Override
public void processResult(CuratorFramework client,
CuratorEvent event) throws Exception {
System.out.println("code:" + event.getResultCode());
System.out.println("type:" + event.getType());
System.out.println("线程为:" + Thread.currentThread().getName());
}
}, pool)
.forPath("/super/c3","c3内容".getBytes());
上面是一个异步创建节点的样例,其中使用到了线程池(如果inBackground()方法不指定线程池,那么会默认使用Curator的EventThread去进行异步处理)。
curator参考
Curator框架 的分布式锁
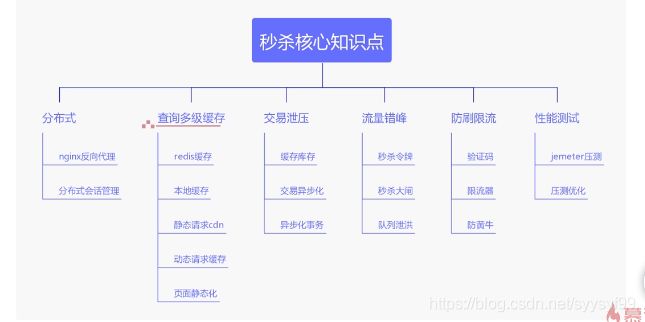
秒杀系统架构
真正要靠zk去实现多服务器自动拉取更新的配置文件等功能是非常难的,如果没有curator,直接去写的话基本上能把你累哭,就好比连Mybatis或者jpa都没有,让你用原生的代码去写个网站一样,你可以把curator当做一个比较强大的工具,有了它操作zk不再是事。
Curator

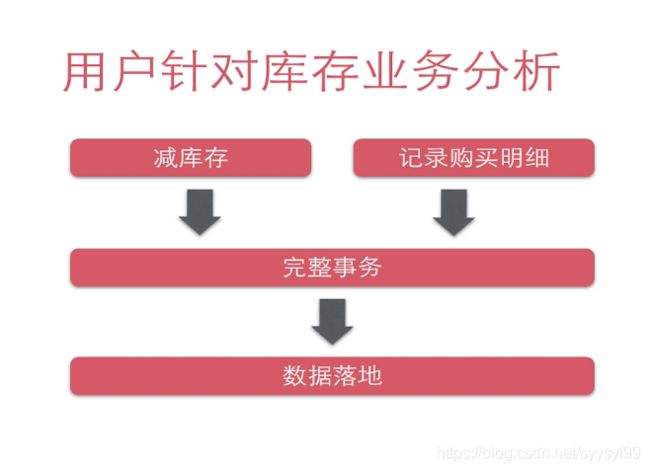
1 秒杀业务分析
正常电子商务流程
(1)查询商品;
(2)创建订单;
(3)扣减库存;
(4)更新订单;
(5)付款;
(6)卖家发货;
如何进行下单前置检查下单服务器检查本机已处理的下单请求数目:如果超过10条,直接返回已结束页面给用户;如果未超过10条,则用户可进入填写订单及确认页面;检查全局已提交订单数目:已超过秒杀商品总数,返回已结束页面给用户;未超过秒杀商品总数,提交到子订单系统;
减库存的操作有两种选择,尝试扣减库存,扣减库存成功才会进行下单逻辑:update auction_auctions set
quantity = quantity-#count#
where auction_id = #itemId# and quantity >= #count#
3 秒杀架构原则尽量将请求拦截在系统上游传统秒杀系统之所以挂,请求都压倒了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,流量虽大,下单成功的有效流量甚小【一趟火车其实只有2000张票,200w个人来买,基本没有人能买成功,请求有效率为0】。读多写少,使用缓存,这是一个典型的读多写少的应用场景【一趟火车其实只有2000张票,200w个人来买,最多2000个人下单成功,其他人都是查询库存,写比例只有0.1%,读比例占99.9%】,非常适合使用缓存。
4.1 前端层设计首先要有一个展示秒杀商品的页面,在这个页面上做一个秒杀活动开始的倒计时,在准备阶段内用户会陆续打开这个秒杀的页面, 并且可能不停的刷新页面。这里需要考虑两个问题:第一个是秒杀页面的展示我们知道一个html页面还是比较大的,即使做了压缩,http头和内容的大小也可能高达数十K,加上其他的css, js,图片等资源,如果同时有几千万人参与一个商品的抢购,一般机房带宽也就只有1G10G,网络带宽就极有可能成为瓶颈,所以这个页面上各类静态资源首先应分开存放,然后放到cdn节点上分散压力,由于CDN节点遍布全国各地,能缓冲掉绝大部分的压力,而且还比机房带宽便宜
web服务器之间时间不同步可以采用统一时间服务器的方式,比如每隔1分钟所有参与秒杀活动的web服务器就与时间服务器做一次时间同步。
浏览器层请求拦截
(1)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求;
(2)JS层面,限制用户在x秒之内只能提交一次请求;
4.2 (1)同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面(2)同一个item的查询,做页面缓存,x秒内到达站点层的请求,均返回同一页面如此限流,又有99%的流量会被拦截在站点层。
4.3 服务层设计站点层的请求拦截,只能拦住普通程序员,高级黑客,假设他控制了10w台肉鸡(并且假设买票不需要实名认证),这下uid的限制不行了吧?怎么整?(1)大哥,我是服务层,我清楚的知道小米只有1万部手机,我清楚的知道一列火车只有2000张车票,我透10w个请求去数据库有什么意义呢?对于写请求,做请求队列,每次只透过有限的写请求去数据层,如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完”;(2)对于读请求,还用说么?cache来抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的;如此限流,只有非常少的写请求,和非常少的读缓存的请求会透到数据层去,又有99.9%的请求被拦住了。用户请求分发模块:使用Nginx或Apache将用户的请求分发到不同的机器上。用户请求预处理模块:判断商品是不是还有剩余来决定是不是要处理该请求。用户请求处理模块:把通过预处理的请求封装成事务提交给数据库,并返回是否成功。数据库接口模块:该模块是数据库的唯一接口,负责与数据库交互,提供RPC接口供查询是否秒杀结束、剩余数量等信息。
用户请求预处理模块
经过HTTP服务器的分发后,单个服务器的负载相对低了一些,但总量依然可能很大,如果后台商品已经被秒杀完毕,那么直接给后来的请求返回秒杀失败即可,不必再进一步发送事务了,示例代码可以如下所示:
package seckill;
import org.apache.http.HttpRequest;
/**
* 预处理阶段,把不必要的请求直接驳回,必要的请求添加到队列中进入下一阶段.
*/
public class PreProcessor {
// 商品是否还有剩余
private static boolean reminds = true;
private static void forbidden() {
// Do something.
}
public static boolean checkReminds() {
if (reminds) {
// 远程检测是否还有剩余,该RPC接口应由数据库服务器提供,不必完全严格检查.
if (!RPC.checkReminds()) {
reminds = false;
}
}
return reminds;
}
/**
* 每一个HTTP请求都要经过该预处理.
*/
public static void preProcess(HttpRequest request) {
if (checkReminds()) {
// 一个并发的队列
RequestQueue.queue.add(request);
} else {
// 如果已经没有商品了,则直接驳回请求即可.
forbidden();
}
}
}
并发队列的选择Java的并发包提供了三个常用的并发队列实现,分别是:ConcurrentLinkedQueue、LinkedBlockingQueue和ArrayBlockingQueue。ArrayBlockingQueue是初始容量固定的阻塞队列,我们可以用来作为数据库模块成功竞拍的队列,比如有10个商品,那么我们就设定一个10大小的数组队列。ConcurrentLinkedQueue使用的是CAS原语无锁队列实现,是一个异步队列,入队的速度很快,出队进行了加锁,性能稍慢。LinkedBlockingQueue也是阻塞的队列,入队和出队都用了加锁,当队空的时候线程会暂时阻塞。由于我们的系统入队需求要远大于出队需求,一般不会出现队空的情况,所以我们可以选择ConcurrentLinkedQueue来作为我们的请求队列实现:
package seckill;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ConcurrentLinkedQueue;
import org.apache.http.HttpRequest;
public class RequestQueue {
public static ConcurrentLinkedQueue<HttpRequest> queue = new ConcurrentLinkedQueue<HttpRequest>();
}
用户请求模块
package seckill;
import org.apache.http.HttpRequest;
public class Processor {
/**
* 发送秒杀事务到数据库队列.
*/
public static void kill(BidInfo info) {
DB.bids.add(info);
}
public static void process() {
BidInfo info = new BidInfo(RequestQueue.queue.poll());
if (info != null) {
kill(info);
}
}
}
class BidInfo {
BidInfo(HttpRequest request) {
// Do something.
}
}
数据库模块
数据库主要是使用一个ArrayBlockingQueue来暂存有可能成功的用户请求。
package seckill;
import java.util.concurrent.ArrayBlockingQueue;
/**
* DB应该是数据库的唯一接口.
*/
public class DB {
public static int count = 10;
public static ArrayBlockingQueue<BidInfo> bids = new ArrayBlockingQueue<BidInfo>(10);
public static boolean checkReminds() {
// TODO
return true;
}
// 单线程操作
public static void bid() {
BidInfo info = bids.poll();
while (count-- > 0) {
// insert into table Bids values(item_id, user_id, bid_date, other)
// select count(id) from Bids where item_id = ?
// 如果数据库商品数量大约总数,则标志秒杀已完成,设置标志位reminds = false.
info = bids.poll();
}
}
}
面试总结:int 占4个字节。
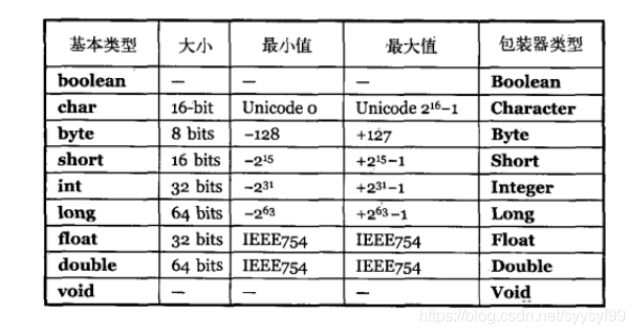
Byte b=1,c=2;Byte a=b+c;有什么错:
b+c的结果是int型,byte存储时为1个字节。Byte a=b+c 是指把一个int型的数装在byte里面,装不进去。引起了异常。而如果是b+=a;因为在运算的时候会进行类型转换,所以不会出现异常。
幻读。
hashmap红黑树转链表的时候,为了避免出现频繁转换,所以当长度变为6的时候才会变为链表。而从链表变红黑树是长度为8。
单机mysql能承载的并发为几百。当并发量不大的时候,用数据库的行锁实现减库存,在数据库里用sql语句实现减库存,而不是用java代码实现。redis单机能支持几万的并发。
@PostConstruct
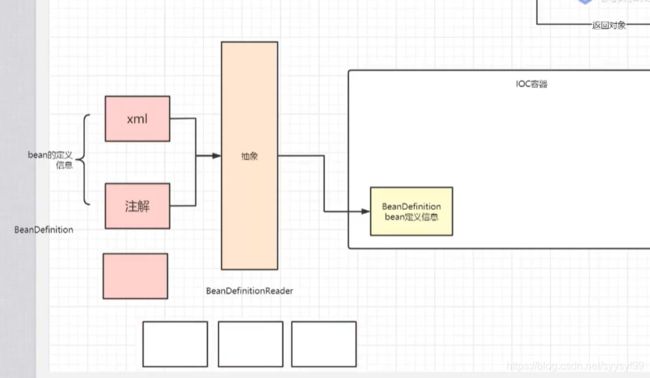

所有的IOC容器都是BeanFactory的子类。
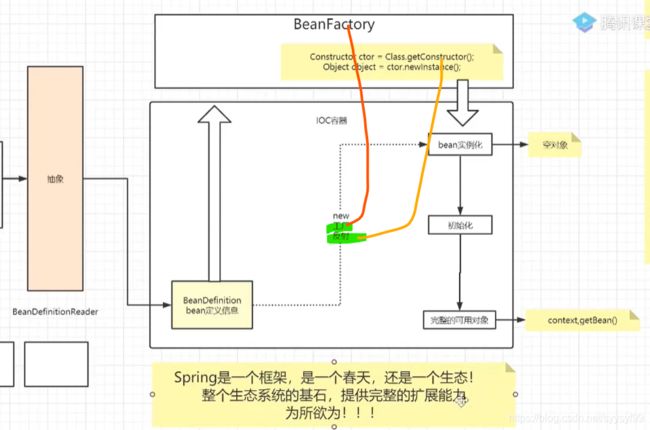
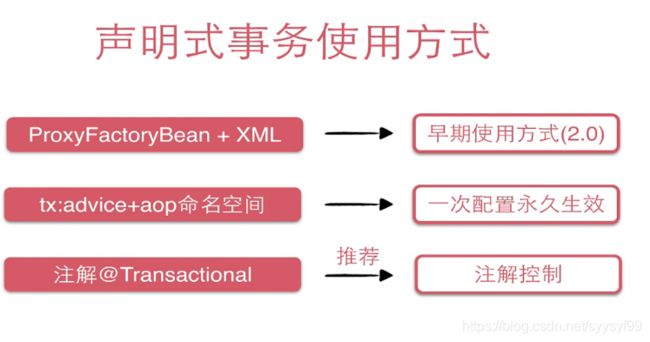
支持事务在service层。

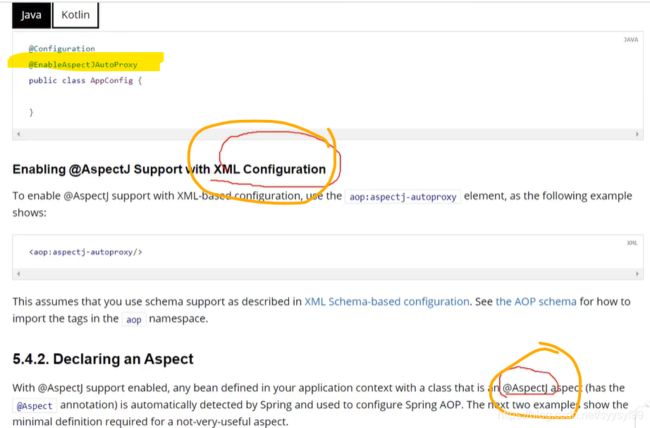
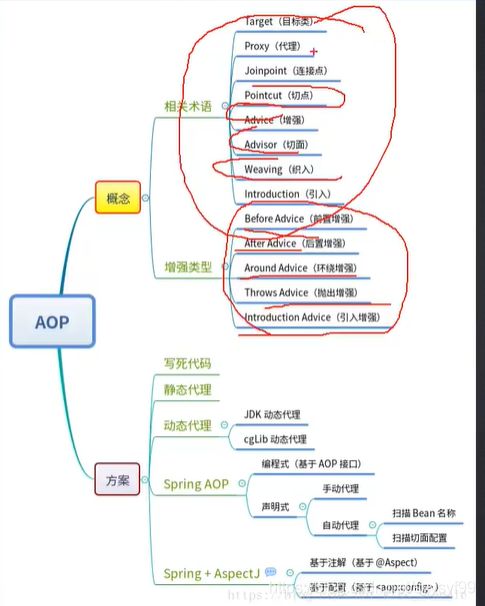
AOP:
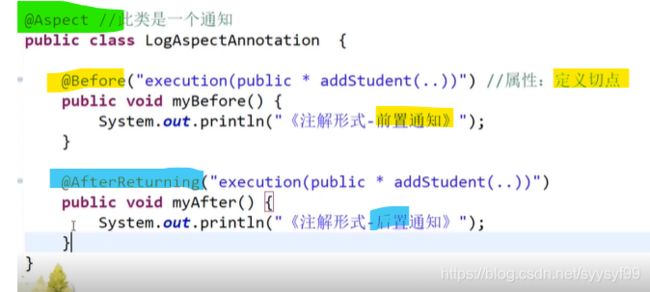
假如在一个项目的很多方法里,都需要写计算这个方法执行时间的代码,所以会造成代码的冗余,除了像这里提到的日志代码,还有事务,Spring事务的底层也是AOP实现,比如下单操作,先下订单,再扣减库存,若扣减库存失败,那么下订单的操作也需要回滚,由于下订单和扣减库存两个操作是针对不同的对象处理,所以代码一般是分开写的。还有权限控制也是AOP实现。
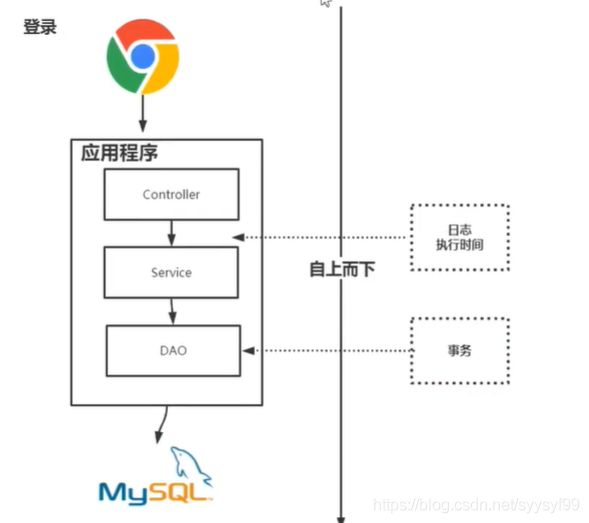
像上图,在执行登录操作时,需要统计日志执行时间,但是统计日志执行时间与登录操作的逻辑是无关的,所以用AOP来实现解耦。
IOC:
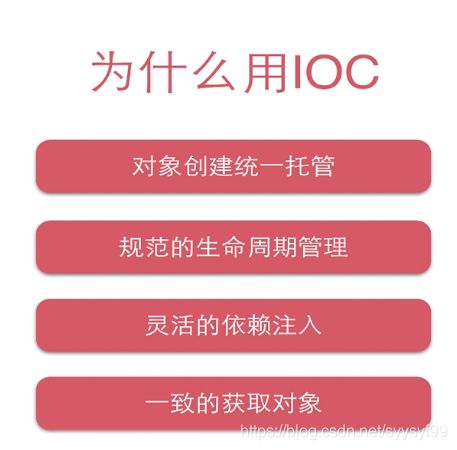
如下图,如果要创建A对象,因为存在依赖关系,所以需要new B对象,以及D对象,而且new B对象则需要new C对象。同样的在new C对象的时候,又需要new 一个D对象,可以发现需要多次通过构造方法去创建new 对象,当需要创建的对象很多时,需要减少对象创建的次数,通过单例+工厂的方式。并且用外部传参(依赖注入)的方式去维护复杂的依赖关系,外部传参的三种方式:(1)构造器(2)setter方法(3)反射(对属性进程处理)。IOC容器就是解决这两个问题(1.对象的创建。2.维护依赖关系),统一管理对象创建以及生命周期的维护,自动维护依赖关系。
把单例对象在IOC容器中缓存,当业务需要时,去容器取。
IOC的使用方式:把Bean交给容器管理的装配方式
下图是IOC容器管理类的过程:
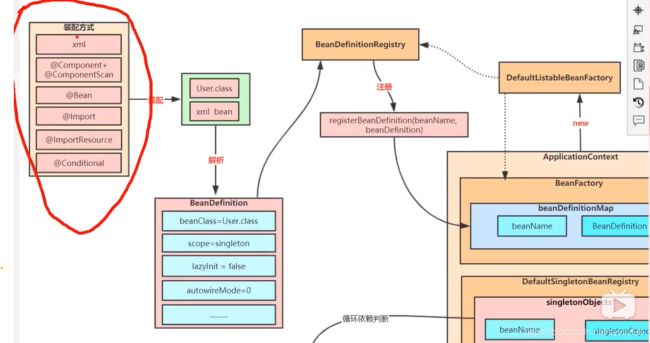
Bean Definition是去承载Bean的属性。

Spring MVC

AOP IOC Spring MVC视频
并查集划分一下相连的子图,然后如果子图不存在环,那么我把他按照拓扑顺序做成一条链一定可以,需要V-1条边。否则,做成一条环,需要V条边。
leetcode59
【动态规划】带权值区间调度问题


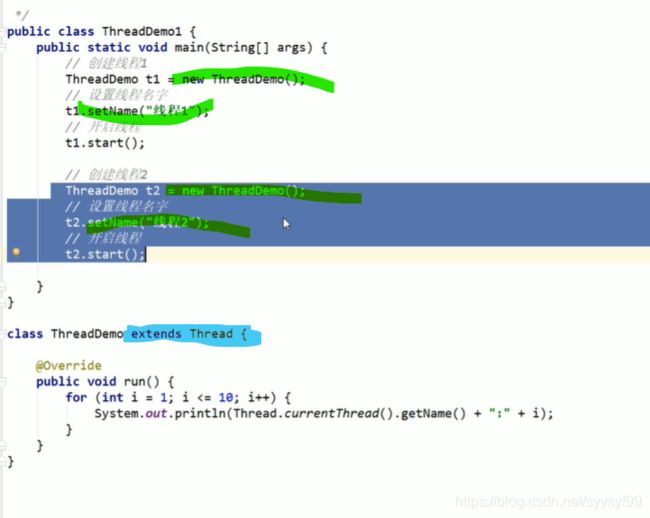

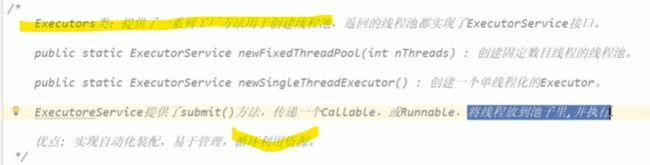
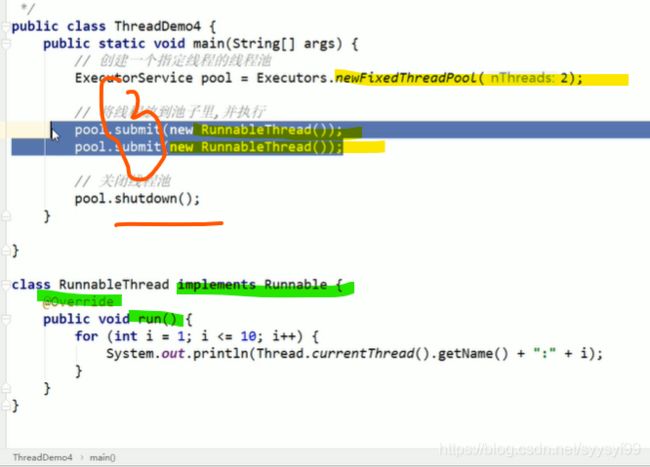
统一实现该接口的实例可以贡献资源,如上面代码,创建出的实现接口Runnable的实例作为了两个线程的参数,实现了资源共享。
执行结果:
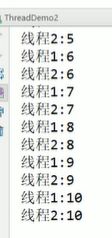
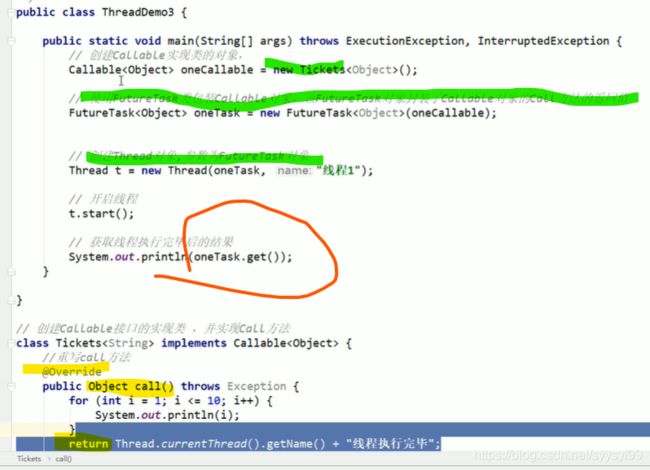
上图中因为call()有返回值,所以在主函数里面通过oneTask调用ger()来获得call()的返回值。


该释放的没有释放掉就发生内存泄漏,然后这些对象积累过多后就发生内存溢出。
定位内存泄漏的最佳视频
Java中的内存泄漏:Java内存泄漏

JMAP定位内存泄漏以及Jstack定位死锁
内存溢出的原因:申请的Java内存超出了Java中的可用内存。
内存溢出的常见场景:6种


配置的堆很小。


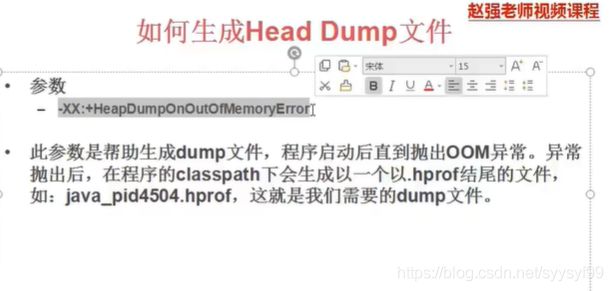
解释:-XX表示这个参数是HotSpot虚拟机私有的参数。+表示开启。
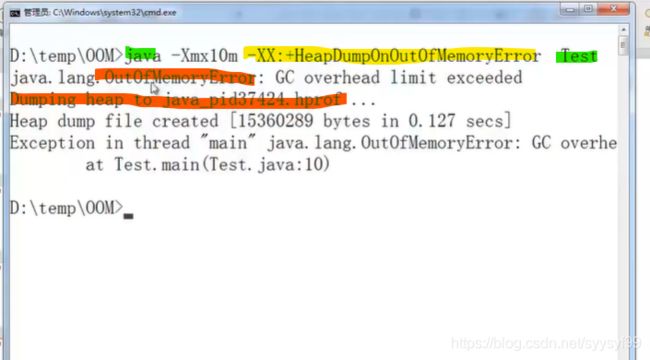

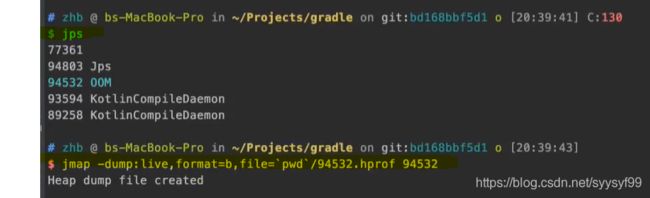
上面给出了两种方法,第二种方法就是在启动时忘记在命令中添加第一种方法的参数,现在已经启动了,此时,可以新开一个终端,运行jps,在终端输入jps,jps就是看当前所有Java进程的PID的,就会在面板上看到正在运行的程序的PID。然后在终端输入方法二的命令。下图最后一条命令。


MAT是eclipse的memory analyzer。
jmap jps jstack jvisualvm这些工具都在java的安装目录下的bin文件夹。
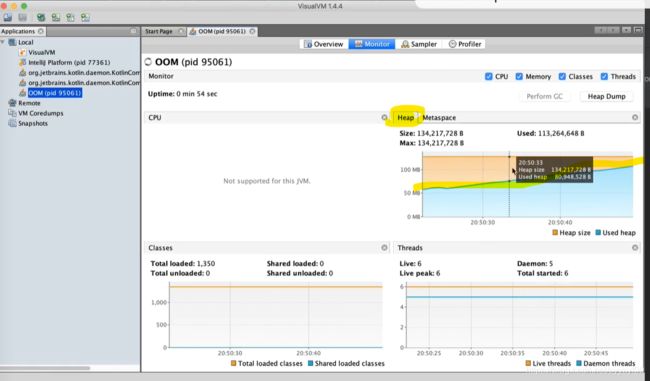
上图是用jvisualvm工具检测出现OOM的程序得到的监测图,右上角是heap的图,正常情况是:上下波动,现在是:斜线上升。
用jvisualvm打开之前dump下来的文件。
retain size表示把这个对象释放掉后可以释放出的空间。
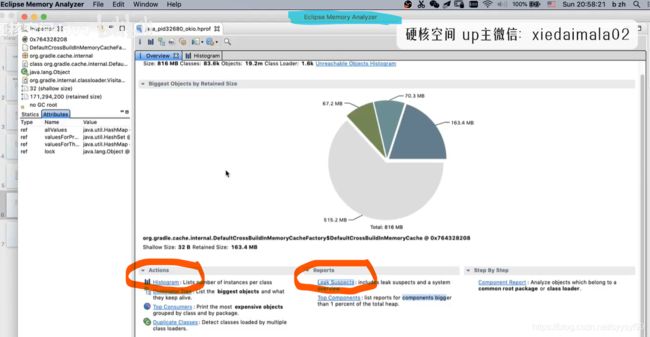
一般只用看上图的直方图和可能的泄漏这两项就够了。
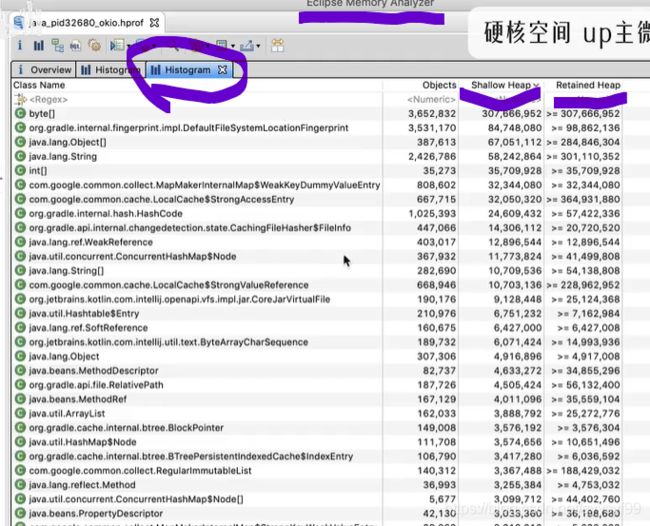
上图中的shallow heap指的是对象本身所占的内存空间,retained heap指的是该对象若释放后可能会释放的总空间(如果有对象仅仅只引用了这个被释放掉的空间,那么就会随之释放)
首先看还有哪些class对象还活着。
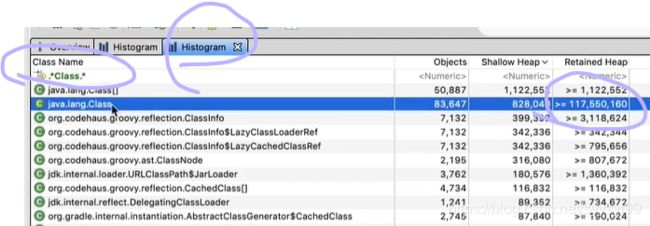
第二条,一般class对象不会占用内存那么多,所以这个很大可能是内存溢出的原因。
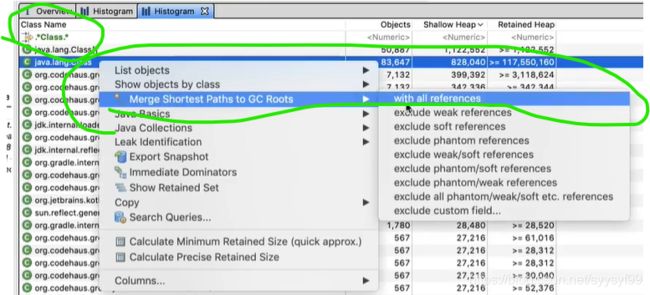
一个对象没被释放的原因是,GC Root与该对象间存在引用链。
下图所使用的选项是:把到Gc root的路径合并起来。因为没有被释放的对象很大可能到GC Root的路径存在相似。那些本该被释放的对象,正因为GC Root存在不应该存在的引用链指向了它们,
终端输入:jstack PID
然后在面板上就可以看到处于阻塞状态的线程。定位到了死锁。定位死锁
Linux中的内存泄漏
数据库调优
假设你有8个球,其中一个略微重一些,但是找出这个球的唯一方法是将两个球放在天平上对比。最少要称多少次才能找出这个较重的球?
答:最少要两次
先从8个球中拿出六个球,天平两端各三个,若平衡,则较重的那个球在剩余的两个里,把剩余的两个球放在天平上,较重的那端就是较重的球;若不平衡,则将6个球中较重一端的其中两个放在天平上,若平衡,则剩余的那个就是较重的球;若不平衡,较重的那端,就是较重的球。
面经
面经
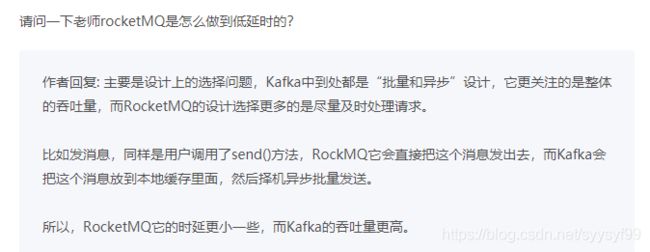
RabbitMQ 一个比较有特色的功能是支持非常灵活的路由配置,和其他消息队列不同的是,它在生产者(Producer)和队列(Queue)之间增加了一个 Exchange 模块,你可以理解为交换机。
这个 Exchange 模块的作用和交换机也非常相似,根据配置的路由规则将生产者发出的消息分发到不同的队列中。
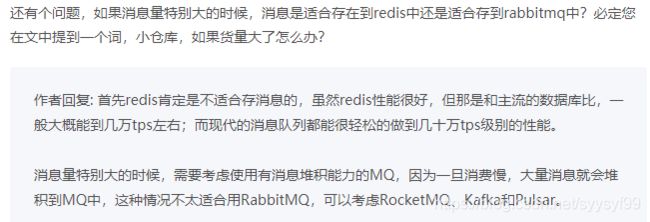
RabbitMQ 的几个问题。第一个问题是,RabbitMQ 对消息堆积的支持并不好,在它的设计理念里面,消息队列是一个管道,大量的消息积压是一种不正常的情况,应当尽量去避免。当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降。第二个问题是,RabbitMQ 的性能是我们介绍的这几个消息队列中最差的,根据官方给出的测试数据综合我们日常使用的经验,依据硬件配置的不同,它大概每秒钟可以处理几万到十几万条消息。其实,这个性能也足够支撑绝大多数的应用场景了,不过,如果你的应用对消息队列的性能要求非常高,那不要选择 RabbitMQ。最后一个问题是 RabbitMQ 使用的编程语言 Erlang,基于 RabbitMQ 做一些扩展和二次开发什么的,建议你慎重考虑一下可持续维护的问题。






消息队列的使用场景:

如何设计一个秒杀系统?这个问题可以有一百个版本的合理答案,但大多数答案中都离不开消息队列。秒杀系统需要解决的核心问题是,如何利用有限的服务器资源,尽可能多地处理短时间内的海量请求。我们知道,处理一个秒杀请求包含了很多步骤,例如:风险控制;库存锁定;生成订单;短信通知;更新统计数据。如果没有任何优化,正常的处理流程是:App 将请求发送给网关,依次调用上述 5 个流程,然后将结果返回给 APP。对于对于这 5 个步骤来说,能否决定秒杀成功,实际上只有风险控制和库存锁定这 2 个步骤。只要用户的秒杀请求通过风险控制,并在服务端完成库存锁定,就可以给用户返回秒杀结果了,对于后续的生成订单、短信通知和更新统计数据等步骤,并不一定要在秒杀请求中处理完成。所以当服务端完成前面 2 个步骤,确定本次请求的秒杀结果后,就可以马上给用户返回响应,然后把请求的数据放入消息队列中,由消息队列异步地进行后续的操作。处理一个秒杀请求,从 5 个步骤减少为 2 个步骤,这样不仅响应速度更快,并且在秒杀期间,我们可以把大量的服务器资源用来处理秒杀请求。秒杀结束后再把资源用于处理后面的步骤,充分利用有限的服务器资源处理更多的秒杀请求。
如何避免过多的请求压垮我们的秒杀系统?
使用消息队列隔离网关和后端服务,以达到流量控制和保护后端服务的目的。加入消息队列后,整个秒杀流程变为:网关在收到请求后,将请求放入请求消息队列;后端服务从请求消息队列中获取 APP 请求,完成后续秒杀处理过程,然后返回结果。
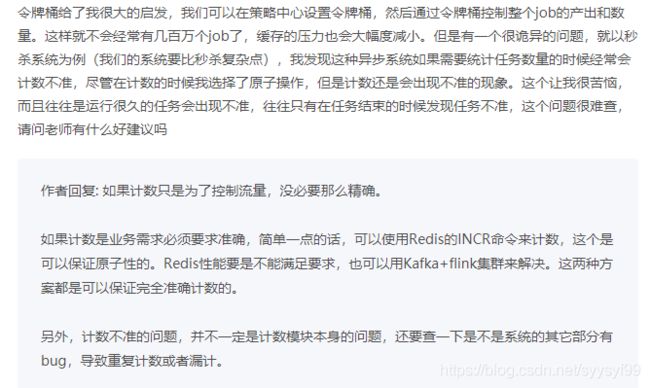
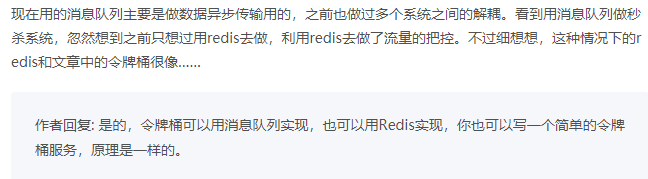
秒杀开始后,当短时间内大量的秒杀请求到达网关时,不会直接冲击到后端的秒杀服务,而是先堆积在消息队列中,后端服务按照自己的最大处理能力,从消息队列中消费请求进行处理。对于超时的请求可以直接丢弃,APP 将超时无响应的请求处理为秒杀失败即可。运维人员还可以随时增加秒杀服务的实例数量进行水平扩容,而不用对系统的其他部分做任何更改。这种设计的优点是:能根据下游的处理能力自动调节流量,达到“削峰填谷”的作用。但这样做同样是有代价的:增加了系统调用链环节,导致总体的响应时延变长。上下游系统都要将同步调用改为异步消息,增加了系统的复杂度。那还有没有更简单一点儿的流量控制方法呢?如果我们能预估出秒杀服务的处理能力,就可以用消息队列实现一个令牌桶,更简单地进行流量控制。令牌桶控制流量的原理是:单位时间内只发放固定数量的令牌到令牌桶中,规定服务在处理请求之前必须先从令牌桶中拿出一个令牌,如果令牌桶中没有令牌,则拒绝请求。这样就保证单位时间内,能处理的请求不超过发放令牌的数量,起到了流量控制的作用。
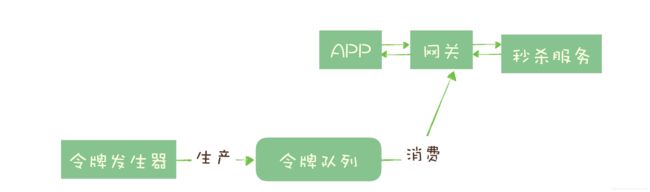
实现的方式也很简单,不需要破坏原有的调用链,只要网关在处理 APP 请求时增加一个获取令牌的逻辑。令牌桶可以简单地用一个有固定容量的消息队列加一个“令牌发生器”来实现:令牌发生器按照预估的处理能力,匀速生产令牌并放入令牌队列(如果队列满了则丢弃令牌),网关在收到请求时去令牌队列消费一个令牌,获取到令牌则继续调用后端秒杀服务,如果获取不到令牌则直接返回秒杀失败。
订单是电商系统中比较核心的数据,当一个新订单创建时:支付系统需要发起支付流程;风控系统需要审核订单的合法性;客服系统需要给用户发短信告知用户;经营分析系统需要更新统计数据;……这些订单下游的系统都需要实时获得订单数据。随着业务不断发展,这些订单下游系统不断的增加,不断变化,并且每个系统可能只需要订单数据的一个子集,负责订单服务的开发团队不得不花费很大的精力,应对不断增加变化的下游系统,不停地修改调试订单系统与这些下游系统的接口。任何一个下游系统接口变更,都需要订单模块重新进行一次上线,对于一个电商的核心服务来说,这几乎是不可接受的。所有的电商都选择用消息队列来解决类似的系统耦合过于紧密的问题。引入消息队列后,订单服务在订单变化时发送一条消息到消息队列的一个主题 Order 中,所有下游系统都订阅主题 Order,这样每个下游系统都可以获得一份实时完整的订单数据。
消息队列最常被使用的三种场景:异步处理、流量控制和服务解耦。当然,消息队列的适用范围不仅仅局限于这些场景,还有包括:作为发布 / 订阅系统实现一个微服务级系统间的观察者模式;连接流计算任务和数据;用于将消息广播给大量接收者。简单的说,我们在单体应用里面需要用队列解决的问题,在分布式系统中大多都可以用消息队列来解决。同时我们也要认识到,消息队列也有它自身的一些问题和局限性,包括:引入消息队列带来的延迟问题;增加了系统的复杂度;可能产生数据不一致的问题。
减库存操作一般有如下几个方式:下单减库存,即当买家下单后,在商品的总库存中减去买家购买数量。下单减库存是最简单的减库存方式,也是控制最精确的一种,下单时直接通过数据库的事务机制控制商品库存,这样一定不会出现超卖的情况。但是你要知道,有些人下完单可能并不会付款。付款减库存,即买家下单后,并不立即减库存,而是等到有用户付款后才真正减库存,否则库存一直保留给其他买家。但因为付款时才减库存,如果并发比较高,有可能出现买家下单后付不了款的情况,因为可能商品已经被其他人买走了。预扣库存,这种方式相对复杂一些,买家下单后,库存为其保留一定的时间(如 10 分钟),超过这个时间,库存将会自动释放,释放后其他买家就可以继续购买。在买家付款前,系统会校验该订单的库存是否还有保留:如果没有保留,则再次尝试预扣;如果库存不足(也就是预扣失败)则不允许继续付款;如果预扣成功,则完成付款并实际地减去库存。
从用户或是产品的角度来看一下,秒杀的流程是什么样的。首先,你需要一个秒杀的 landing page,在这个秒杀页上有一个倒计时的按钮。一旦这个倒计时的时间到了,按钮就被点亮,让你可以点击按钮下单。一般来说下单时需要你填写一个校验码,以防止是机器来抢。从技术上来说,这个倒计时按钮上的时间和按钮可以被点击的时间是需要后台服务器来校准的,这意味着:前端页面要不断地向后端来请求,开没开始,开没开始……每次询问的时候,后端都会给前端一个时间,以校准前端的时间。一旦后端服务器表示 OK 可以开始,后端服务会返回一个 URL。这个 URL 会被安置在那个按钮上,就可以点击了。点击后,如果抢到了库存,就进入支付页面,如果没有则返回秒杀已结束。
技术上的挑战就是怎么应对这 100 万人同时下单请求?100 万的同时并发会导致我们的网站瞬间就崩溃了,一方面是 100 万人同时请求,我们的网络带宽不够,另一方面是理论上来说要扛 100 万的 TPS,需要非常多的机器。但是最恐怖的是,所有的请求都会集中在同一条数据库记录上,无论是怎么分库分表,还是使用了分布式数据库都无济于事,因为你面对的是单条的热点数据。
要让 100 万用户能够在同一时间打开一个页面,这个时候,我们就需要用到 CDN 了。数据中心肯定是扛不住的,所以,我们要引入 CDN。在 CDN 上,这 100 万个用户就会被几十个甚至上百个 CDN 的边缘结点给分担了,于是就能够扛得住。然后,我们还需要在这些 CDN 结点上做点小文章。一方面,我们需要把小服务部署到 CDN 结点上去,这样,当前端页面来问开没开始时,这个小服务除了告诉前端开没开始外,它还可以统计下有多少人在线。每个小服务会把当前在线等待秒杀的人数每隔一段时间就回传给我们的数据中心,于是我们就知道全网总共在线的人数有多少。假设,我们知道有大约 100 万的人在线等着抢,那么,在我们快要开始的时候,由数据中心向各个部署在 CDN 结点上的小服务上传递一个概率值,比如说是 0.02%。于是,当秒杀开始的时候,这 100 万用户都在点下单按钮,首先他们请求到的是 CDN 上的这些服务,这些小服务按照 0.02% 的量把用户放到后面的数据中心,也就是 1 万个人放过去两个,剩下的 9998 个都直接返回秒杀已结束。于是,100 万用户被放过了 0.02% 的用户,也就是 200 个左右,而这 200 个人在数据中心抢那 100 个 iPhone,也就是 200 TPS,这个并发量怎么都应该能扛住了。
2008 年奥运会抢票把服务器抢挂了是可以使用秒杀这个解决方案的。而 12306 则不行,因为他们完全不知道用户来是要买哪张火车票的。不知道这个信息,很不好过滤用户,而且用户在买票前需要有很多查询操作,然后在查询中选择自己的车票。对此,12306 最好的应对方式,除了不要一次把所有的票放出来,而是分批在不同的时间段把票放出来,这样可以让人们不要集中在一个时间点来抢票,做到人肉分流,可以降低一些并发度。另外,我一直觉得,12306 最好是用预售的方式,让大家把自己的购票先输入到系统中。系统并不真正放票,而是把大家的需求都收集好,然后做整体统筹安排,该增加车次的增加车次,该加车厢的加车厢,这样可以确保大家都能走。实在不行,那就抽签了。
GC调优
死锁的定位与修复








限流手段
整合rabbitMQ
接着上面连接开发邮件通知服务
支付宝秒杀
数据库文档
添加链接描述
Explain 与 SQL语句一起使用时, 会显示优化器关于SQL执行的信息。MySQL会解释:
(1)如何处理语句
(2)如何连接表
(3)表的加载顺序
(4)sql 的查询类型
(5)哪些索引被实际使用
(6)表与表间的引用关系
(7)表中有多少行被优化器查询
Explain 执行计划包含字段: id、select_type、table、partitions、type、possible_keys、key、key_len、ref、rows、filtered、Extra 12个字段。
EXPLAIN为SELECT语句中使用的每个表返回一行信息 ,按照MySQL在处理语句时读取它们的顺序列出输出的表。MySQL使用嵌套循环连接方法解析所有连接,意味着MySQL从第一个表中读取一行,然后在第二个表,第三个表中找到匹配的行,依此类推。处理完所有表后,MySQL输出选定的列,回溯,直到找到一个表,其中存在更多匹配的行。从该表中读取下一行,然后继续下一个表。
explain执行计划
秒杀项目SpringBoot
Spring Boot:内置tomcat启动和外部tomcat部署
springboot的web项目的启动分为:
一.使用内置tomcat启动
启动方式:
1、IDEA中main函数启动
2、mvn springboot-run 命令
3、java -jar XXX.jar
二.使用外置tomcat运行
用外置tomcat需要把项目打成war包,拷贝到webapp运行。
第一步:
![]()
第二步:新建一个tomcat
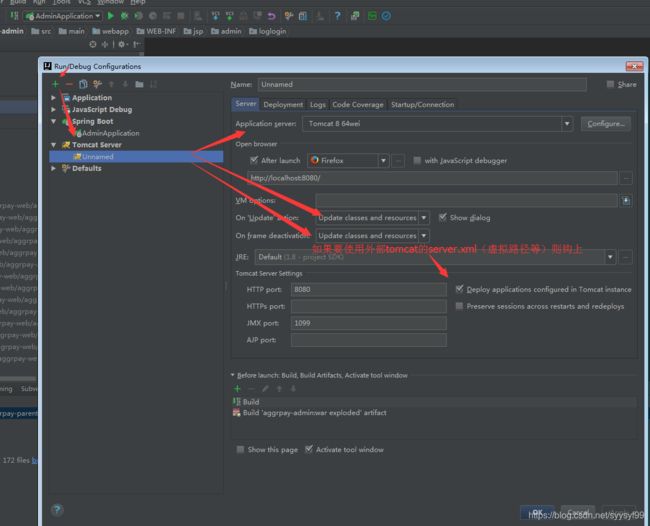
第三步:加上要部署的war包
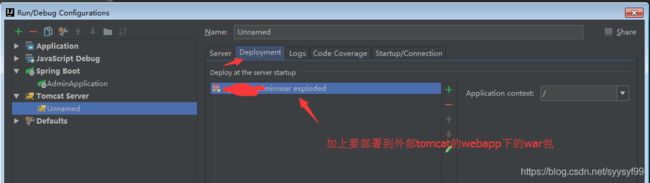
第四步:指定war包输出的位置
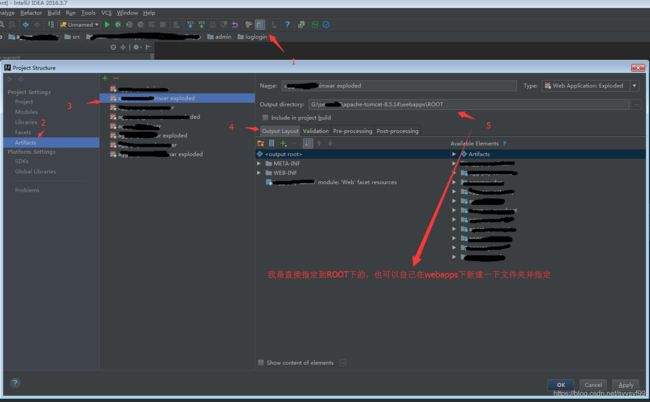
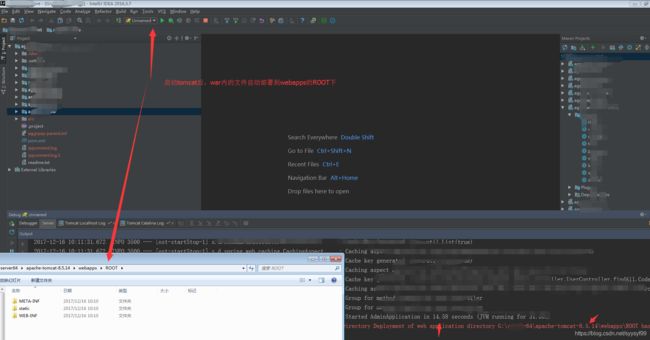
第五步:启动tomcat,访问页面
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.1.6.RELEASE</version>
</dependency>
@SpringBootApplication
public class MySpringbootTomcatStarter{
public static void main(String[] args) {
SpringApplication.run(MySpringbootTomcatStarter.class);
}
}
开发阶段使用内置tomcat够用。
发布的时候,打包(war)然后部署在生产的tomcat中。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<!-- 移除嵌入式tomcat插件 -->
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
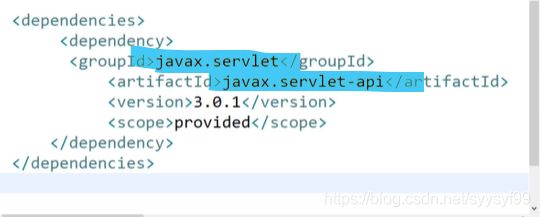
<!--添加servlet-api依赖--->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
更新main函数,继承SpringBootServletInitializer,重写configure()。
@SpringBootApplication
public class MySpringbootTomcatStarter extends SpringBootServletInitializer {
public static void main(String[] args) {
SpringApplication.run(MySpringbootTomcatStarter.class);
}
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder builder) {
return builder.sources(this.getClass());
}
}
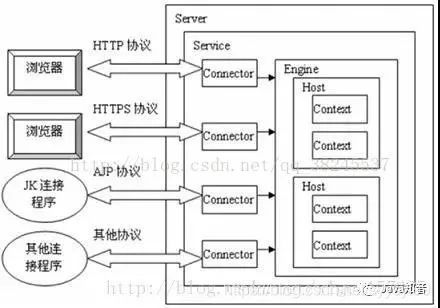
如上图,一个tomcat包含一个Server,
一个Server包含多个Service,
一个Service有一个Container,有多个Connector,一个服务可以处理多个连接。
多个Connector和一个Container形成一个Service,
有了Service可以对外提供服务,Service要提供服务必须提供一个宿主环境Server,整个tomcat的生命周期由Server控制。
“Navicat”是可创建多个连接的数据库管理工具,管理 MySQL或 MongoDB 等不同数据库。它可以让用户连接到本地或远程服务器,协助用户管理数据。
“Secure SHell (SSH)”是一个通过网络登录其他电脑的程序,在远程服务器运行命令,和从一台机器移动文件到另一台。
在一个 Telnet 会话,所有的通讯,包括用户名和密码,会用纯文本传输,让任何人都能监听你的会话及窃取密码或其他信息。这种会话也容易受到会话劫持,一旦你验证,恶意用户就能接管这种会话。SSH 的目的是防止这种漏洞,并允许你在不影响安全性的情况下访问远程服务器的 shell。
HTTP 隧道和 SSH 隧道不能同时运作。当你选用了 HTTP 隧道,SSH 隧道就会禁用,反之亦然。
HTTP 隧道是一种连接到服务器的方法,使用与网络服务器相同的通讯协定(http://)和相同的端口(端口 80)。这是当你的互联网服务供应商不允许直接连接,但允许创建 HTTP 连接时使用。
添加链接描述
SQL注入指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序查询语句的结尾添加SQL语句,实现非法操作。
Maven在某个统一的位置存储所有项目的共享的构件,这个统一的位置,我们就称之为仓库。(仓库就是存放依赖和插件的地方)
maven的本地仓库,在安装maven后并不会创建,它是在第一次执行maven命令的时候才被创建
maven本地仓库的默认位置:无论是Windows还是Linux,在用户的目录下都有一个.m2/repository/的仓库目录,这就是Maven仓库的默认位置。
LinkedList的poll()相当于是removeFirst()
统计了一下长沙这边的互联网企业,如下:其实可以去boss直聘上查询哈
长沙智能驾驶研究院
开易科技
聚时科技
三一重工
中兴
中车
深信服
中联重科
华锐金融
华为
道通科技
拓维
千视通
盈峰环境
数字政通
public class Student{
static final String school="xx五小";//类的静态变量存储在方法区,类的实例变量存储在堆区。static关键字才对变量的存储区域造成影响。
final String grade="三年级";//非final的成员变量在堆里,final类型的成员变量存放在方法区的常量池中。常量是用final修饰的成员变量,常量在类编译时期载入类的常量池中。
public void getStudentInfo(String name){
final String address = "第五教学楼三楼";//final修饰的局部变量(方法内)也可以称为不可变变量。(存储在栈中)
}
}
自然连接要求两个表有共同属性(列),自然连接的结果是参与操作的两个表的共同属性上进行等值连接后,去除重复属性后所得的新表。和内连接常常可以替换。

自然连接
SELECT XSB.* , CJB.课程号, CJB.成绩
FROM XSB , CJB
WHERE XSB.学号= CJB.学号
接口不能被private和protected修饰。
因为接口是需要被实现的,连接口中的方法都只能是抽象方法或者被default和static修饰。
添加链接描述
添加链接描述
(10*49.3)的类型是double型。对于浮点型数据而言如果数字后没有任何字母,计算机默认为double类型。所以49.3的类型为double型。而10为int型,先自动转换为double型,然后再与49.3进行乘运算,所得结果为double类型。
public class Student{
static final String school="xx五小";//类的静态变量存储在方法区,类的实例变量存储在堆区。static关键字才会对变量的存储区域造成影响。
final String grade="三年级";//非final的成员变量在堆里,final类型的成员变量存放在方法区的常量池中。常量是用final修饰的成员变量,常量在类编译时期载入类的常量池中。
public void getStudentInfo(String name){
final String address = "第五教学楼三楼";//final修饰的局部变量(方法内)也可以称为不可变变量,不叫常量,常量是用final修饰的成员变量。(final修饰的局部变量存储在栈中)
}
}
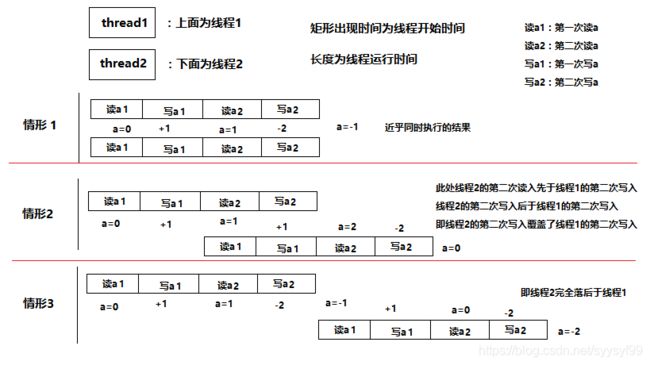
假设 a 是一个由线程 1 和线程 2 共享的初始值为 0 的全局变量,则线程 1 和线程 2 同时执行下面的代码,最终 a 的结果不可能是
boolean isOdd = false;
for(int i=1;i<=2;++i)
{
if(i%2==1)isOdd = true;
else isOdd = false;
a+=i*(isOdd?1:-1);
}
每个线程对a 均做了两次读写操作,分别是 “ +1 ” 和 “ -2 ”
而题目问了是最终a 的结果,所以 a 的结果取决于各自线程对 a 的先后读写的顺序
结论:a的可能取值为-1、0、-2
参考:解答
Byte b=1,c=2;Byte a=b+c;有什么错:
b+c的结果是int型,存储时bai需要2个字节du,byte存储时为1个zhi字节。Byte a=b+c 是指把一个int型的数装在byte里面。这相当于dao 把一个卡车放在一个只能允许小汽车进入的停车厂,它装不进去。所以引起了异常。而如果是b+=a;因为在运算的时候会进行类型转换,所以不会出现异常。
添加链接描述
把改成了${mybatis-version},我把版本信息单独写在了里面,方便给jar包升级和降级。
pom.xml中依bai赖的jar包会自动实现du从中央仓库下载到本地仓库。
Java8、JDK8、JDK1.8都是同一个东西
静态变量存放在方法区,静态代码块对于定义在它后面的静态变量可以赋值,但是不能访问。
public class Demo{
static{
i=3;//这步正确,因为可以对定义在后面的变量进行赋值
System.out.print(i);//这句代码错误,因为不能访问定义在后面的静态变量。
}
private static int i;
}
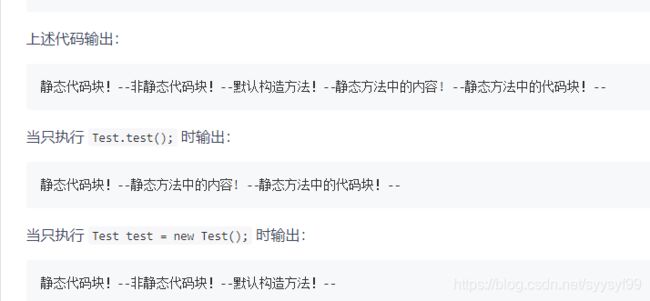
执行顺序:静态代码块——非静态代码块——构造方法。
静态内部类:static修饰类只能修饰内部类,静态内部类与非静态内部类的最大区别:非静态内部类在编译完成后,会隐含保留着一个引用,该引用指向创建它的外围类,但是静态内部类却没有,意味着,静态内部类的创建不需要依赖外围类,静态内部类不能使用任何外围类的非static成员变量和方法。
构造器中使用的super()调用父类的构造方法时,语句要放在构造器的首行。
this.super不能用在static方法中,静态方法属于类范畴,this.super属于对象范畴。
静态代码块是自动执行,静态方法是调用才会执行。
非静态代码块和构造函数的区别:
(1)非静态代码块是给所有对象统一初始化,构造函数是给对应的对象初始化。
(2)构造函数可以多个,运行哪个构造函数就会建立什么样的对象,但无论建立哪个对象,都会先执行相同的构造代码块,构造代码块中定义的是不同对象共性的初始化内容。
使用maven是为了更好的帮项目管理包依赖,maven的核心就是pom.xml。当我们需要引入一个jar包时,在pom文件中加上就可以从仓库中依赖到相应的jar包。
创建一个parent项目,打包类型为pom,parent项目中不存放任何代码,只是管理多个项目之间公共的依赖。
maven的pom文件中中各个标签的含义:
一般是项目的java文件所在的包名,其确定了在项目install的时候的打包路径
<groupId>com.xxx.yy</groupId>
确定了被打jar包的所属项目文件夹名
<artifactId>dip-dubbo-api</artifactId>
表示项目的地址,在maven生成的文档中使用
<url>http://maven.apache.org</url>
打包的类型,可以是jar(package)或war(install)等
<packaging>jar</packaging>
描述这个POM文件是遵从哪个版本的项目描述符
<modelVersion>4.0.0</modelVersion>
正常项目,最好都写上,不写具体版本号时,如果项目复杂度较低,依赖的开源项目少,那就还好。如果项目复杂度高,依赖了很多的大的开源项目,那这些项目里自身又依赖了其它jar时,内部依赖jar极有可能出现版本冲突问题。在版本冲突出现时,早期不写具体版本号的写法,就会发现坑到死。
写pom.xml文件时使用
项目中遇到的问题:
1.IDEA 中无法编译lombok的解决方法
2.springboot 新增模块之后,需要设置java文件夹为Sources Root
3.springboot Failed to introspect annotated methods
4.Spring Boot 启动:No active profile set, falling back to default profiles: default
5.No MyBatis mapper was found
使用了数据源还报错很有可能配置文件没有读入,可以去编译文件下看看配置文件在不在,资源文件夹一定要写为resources而不能写成resource,具体原因参见spring boot启动时读取配置文件的方式。错因:配置文件没有编译到classes 路径下。
6.排查 Cannot determine embedded database driver class for database type NONE
解法二
解法三
mapper文件夹下的数据库表对应的接口和entity文件夹下的数据库表对应的类以及mappers下的数据库表对应的xml文件是逆向工程自动生成的。
mybatis-generator插件可自动生成实体类和mapper还有xml配置文件。在IDEA中只需修改插件中的generatorConfig.xml文件,然后运行配置文件就可以得到说需要的类,接口,xml文件。
mybatis逆向工程1
mybatis逆向工程2
mybatis逆向工程3
mybatis逆向工程-最简单
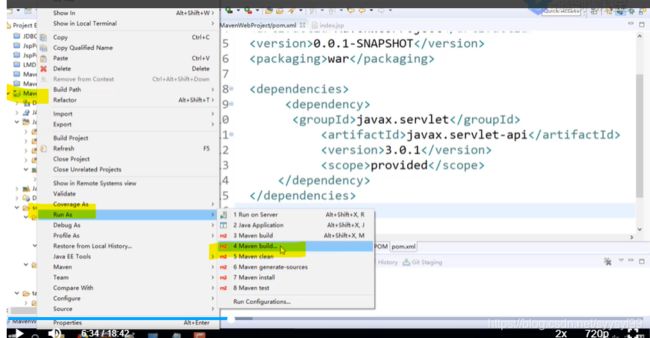
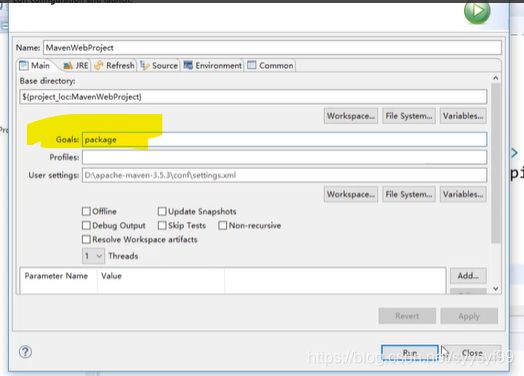
7.maven插件使用异常:generate failed:
8.Mybatis generator Could not create connection to database server
9.generate failed: Exception getting JDBC Driver问题
10.查看本地MySQL的安装路径以及查看mysql版本
11.grep换成 findstr
12.启动mysql:输入 net start mysql;
停止mysql:输入 net stop mysql;
windows下不能直接重启(restart),只能先停止,再启动。
13.Access denied for user ‘XXX’@‘localhost’ (using password: YES)解答1
14.java中键值用(‘)单引号,列名(`)反单引号。就是上面一排数字键最左边~符号那个,切换英文输入法即为反单引号。
15.在入门学习Java Web的时候,例如引入了commons-io.jar,书上、教程之类的会让我们把这个jar包放入WEB-INF/lib下,因为这样项目会引用到。而idea比较特殊,不管是maven引入依赖或者是手动在moduies里面添加,只是说明这个项目引用了jar包,而并没有放进所谓的“正确的地方”。那么结果是,我们的代码没有问题,因为能够获取这个jar,而项目在跑的时候却根本找不到这个包,所以只能抛出异常 java.lang.ClassNotFoundException。看一下项目的输出位置,默认的是在idea目录下:out/artifacts,可以看到自己的项目,而里面WEB-INF文件夹下,一个classes,一个lib。classes放的是字节码文件,而lib里面就是jar包。
16.ibatis.exceptions.PersistenceException:
17.JDBC连接Mysql 8.0.12版本的几个注意事项
Could not get JDBC Connection
18.社区版IDEA配置Tomcat
19.CannotGetJdbcConnectionException异常



控制台进入mysql都需要在mysql的安装目录下的bin文件夹下输入mysql -u root -p
表中的列对应实体中的属性
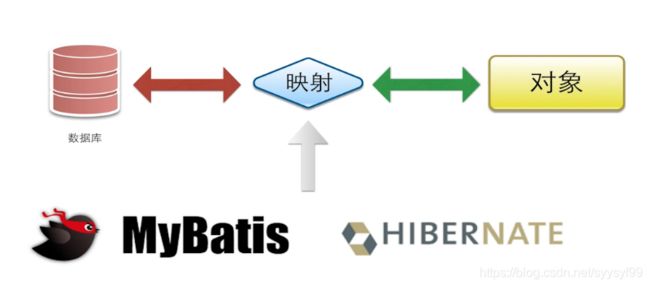

MyBatis完成的工作就是通过你给的参数以及SQL,封装得到Entity或者List返回给你。
MyBatis提供了两种方式来让我们写SQL:
(1)写在XML中
(2)写在注解里
有了MyBatis后,DAO层只需要写出接口即可,不需要写实现类:
有了MyBatis后,mapper自动实现DAO接口。mapper中存放SQL的映射。
XML 注释:CTRL + SHIFT + /,撤销注释:CTRL + SHIFT + \。
SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作。
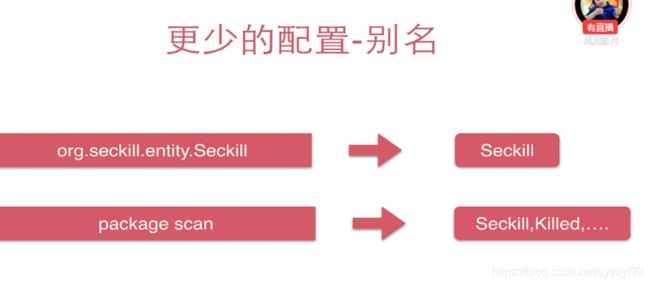
Java中通常需要用包名+类名来指示,而MyBatis中只需要给出类名,这是因为MyBatis会自动实现包扫描,它会扫描指定包下所有的类,把所有的类名存储到别名系统中。
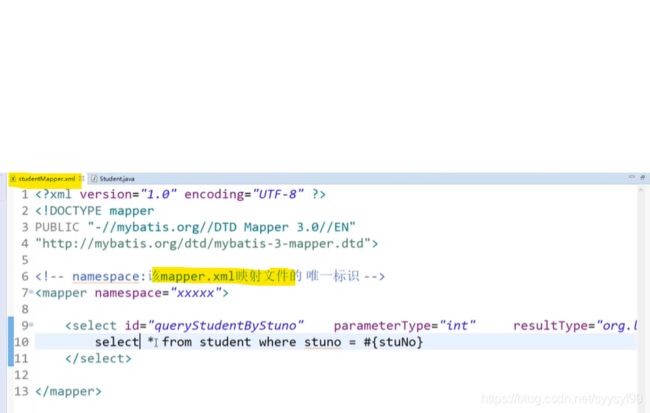
当有很多如下图的xml文件时,是一个很重的维护成本,mybatis会自动扫描配置文件,所以不需要我们来维护这份配置。
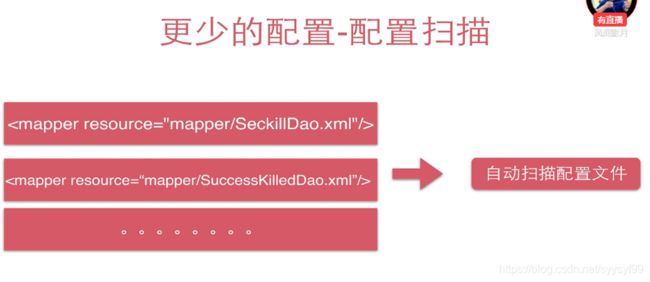
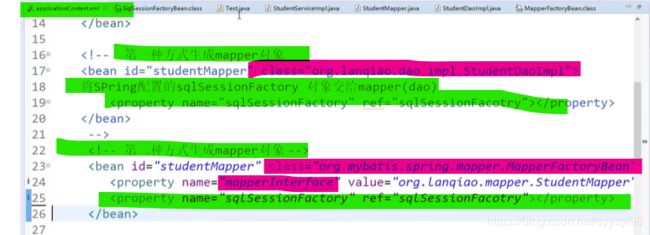
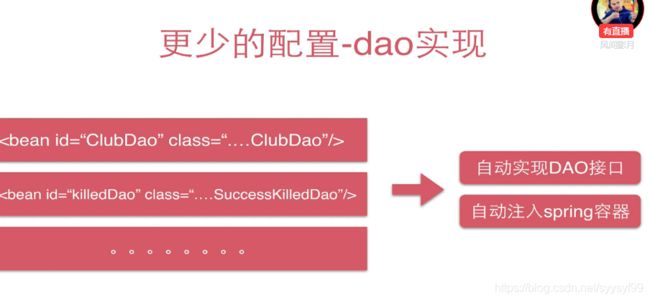
DAO实现后的实例放置到Spring容器中就要如下图所示一样操作,当有很多的DAO实现时,需要写很多这样的配置,如下图。MyBatis会自动帮我们实现DAO接口,也就是说接口的方法实现不需要自己写。DAO的接口实现就是mapper。而且MyBatis和Spring整合之后,这些实现类可以自动注入到Spring容器中。
spring4.1.7的官方文档:
docs.spring.io/spring/docs/4.1.7.RELEASE/spring-framework-reference

dto数据传输层,与entity的区别:entity是业务的封装,而dto关注的是web和service之间的数据传递。
只有运行期异常才会自动回滚。
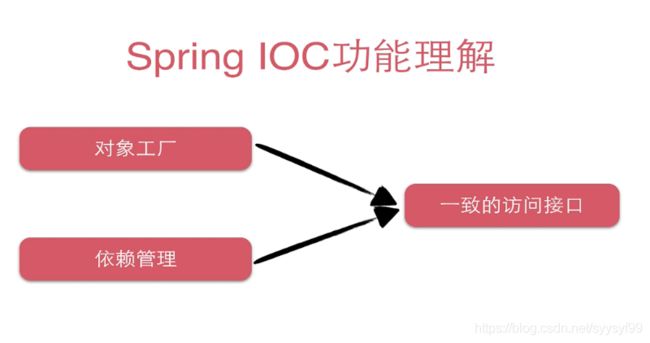
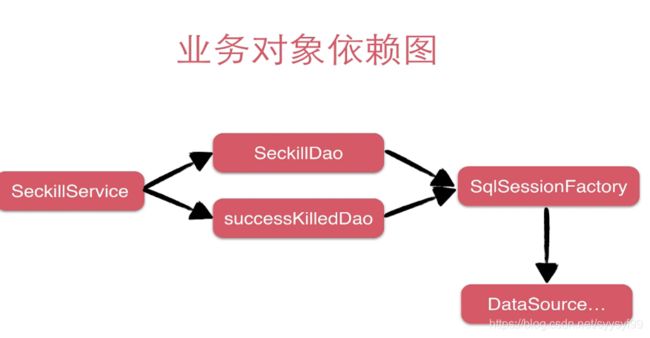
通过IOC使得可以在容器中得到任意对象的实例,而且这些实例一般都是单例的。


通过包扫描,扫描那些加入了注解的类、service、dao,将其注入到Spring容器中。
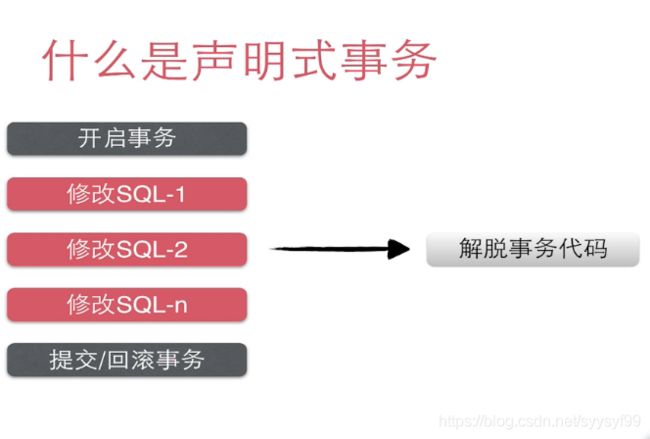
如上图,声明式子事务也就是说,不关心什么时候开启事务,什么时候提交事务,这些交给第三方框架实现。







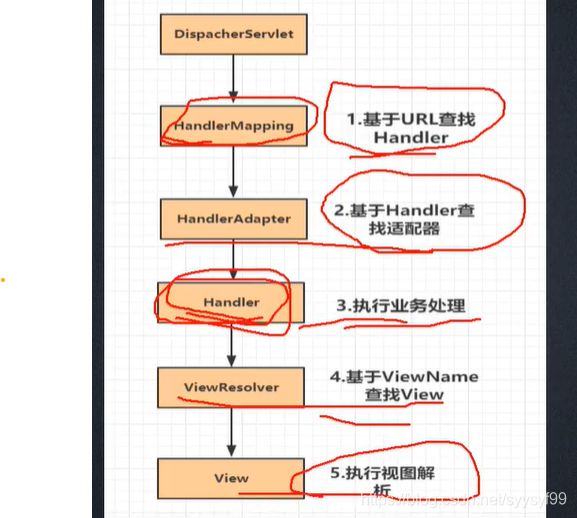
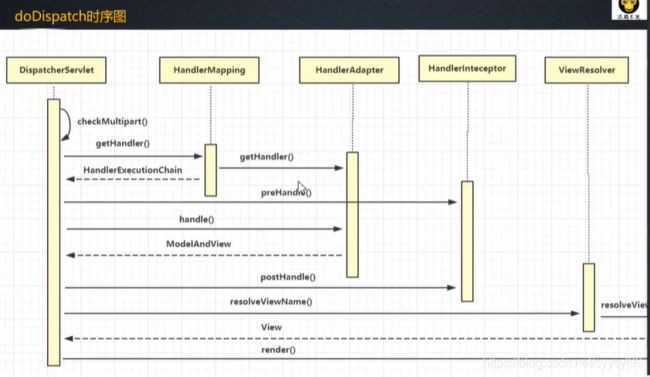
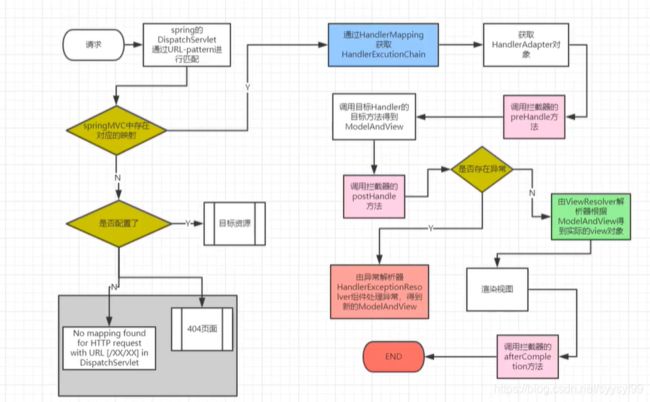
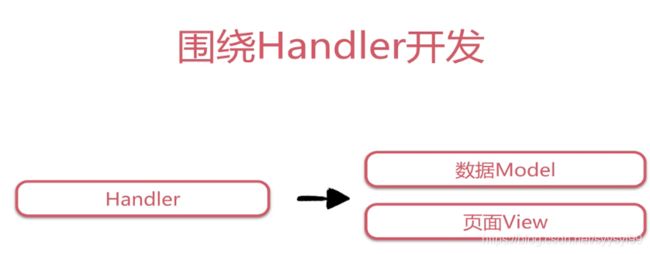
使用Spring MVC是围绕Handler开发。
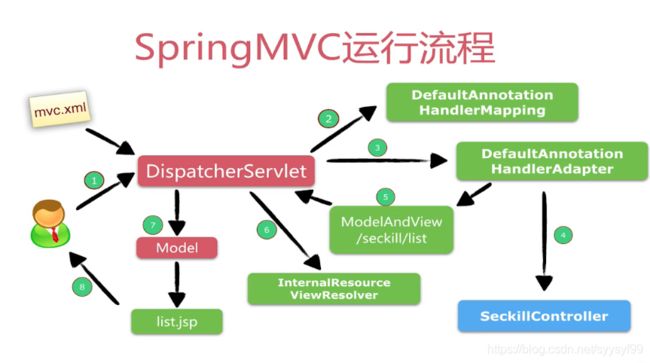
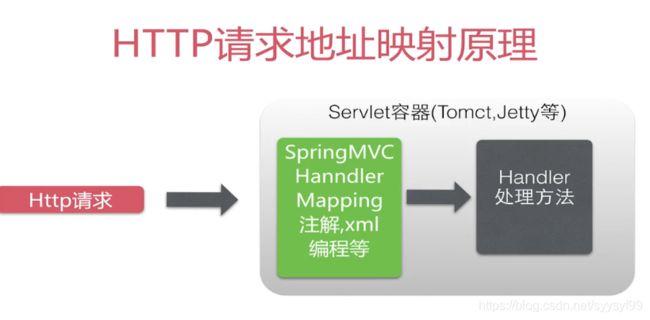
如果实际是使用的JSON,那么把上图中的jsp换成JSON。在实际开发的时候是只用管上图中的蓝色部分,上图中的剩下部分用注解方便地映射URL。

补充上图的(2):?表示一个字符,*表示匹配任意多个字符,**表示匹配任意URL路径(可以是空的)。
RESTful的URL设计和Spring MVC的注解映射优雅地匹配。


上图中的具体例子,占位符通过PathVariable注解绑定到方法的参数。也就是说会把传入的URL中的占位符secKillId部分作为方法参数传入到方法中。绿色部分表示只允许GET请求。黄色部分Model表示主要是Model承载返回给用户的数据。model.addAttribute()是通过传入的key-value对去映射。页面就通过key-value对拿到model中的数据。最后一行语句是默认返回的JSP页面,把数据传递给detail.jsp,做数据替换。

上图中produces的值是HTTP response的Header。ResponseBody注解就是表示返回的数据是JSON格式,会把数据result封装成JSON格式后返回。

上图中require=false,表示不强制匹配,如果没有传入cookie的话就不会匹配,也不会报错。



jQuery是JS中的一个库,项目中倒计时的实现和访问cookie的功能实现都是借助这个库。
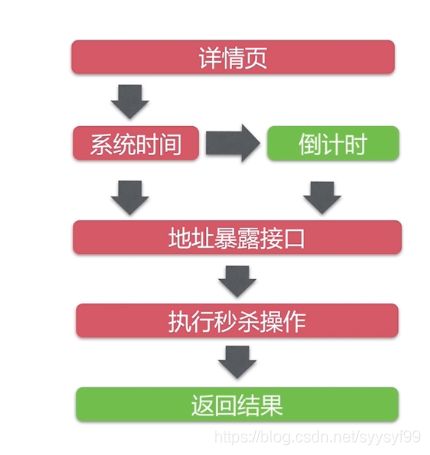
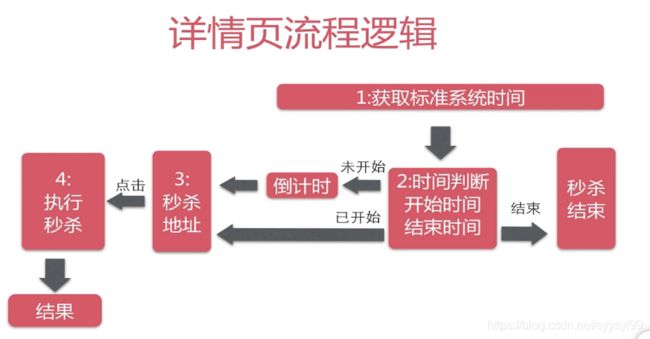
红色部分代表可能会出现高并发的地方,绿色部分没有影响。
项目中单独获取系统时间就是为了后面高并发优化做铺垫。
详情页应该部署在CDN节点上。CDN会把详情页静态化处理,也就是说那些秒杀详情页不在秒杀系统上了,而是在CDN节点上。静态资源也会部署到CDN上。也就是说访问详情页和访问静态资源是不用访问秒杀系统的。就是因为不访问系统,所以拿不到系统时间,所以才需要单独获取系统时间。
(1)详情页通过部署在CDN节点上来进行优化。
(2)系统时间的获取耗时很短,不需要优化
(3)倒计时部署在js上,与浏览器性能无关,不需要优化。
(4)秒杀条件达成后,都需要通过Restful接口来访问后端。这是一个高并发的点。
所以待优化的点:地址暴露接口与执行秒杀操作。
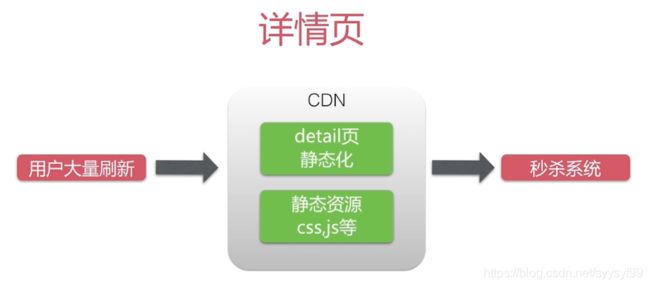
CDN是加速用户获取数据的系统,这个数据可以是静态资源也可以是动态资源。大部分的视频加速也是利用CDN,例如优酷视频等。



一次性维护成本低:当秒杀地址有变化时,就修改数据库和缓存即可。或者干脆不改,等查询时再修改。
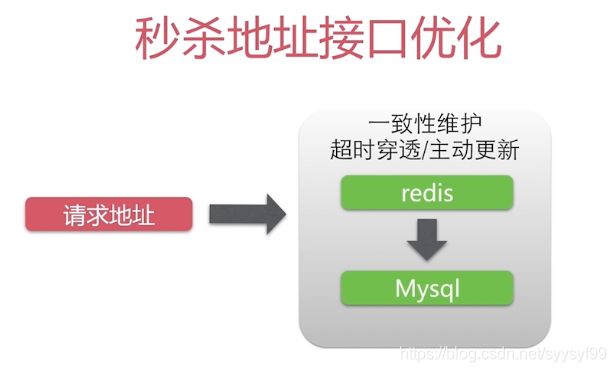
当请求地址时,会先访问redis,当redis中数据过期,才会穿透redis去访问mysql。拿到秒杀对象后,判断系统时间与秒杀开启时间、秒杀结束时间来做判断,来决定返回数据如何,决定要不要暴露秒杀地址。


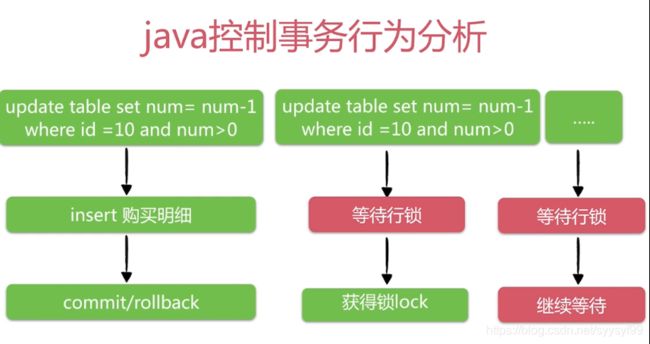

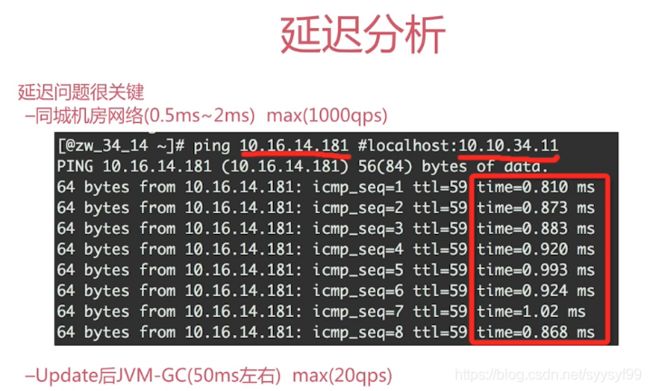
性能瓶颈表现在:对同一行数据的操作是串行化的,因为对mysql操作需要获得行锁才能操作,只有等获取到锁的线程释放后,其他线程才能执行,所以表现为串行化。然后在获得锁后,对该行数据操作时,由于存在网络延迟和GC,当GC时可能需要暂停其他线程(对数据库操作的线程),所以这些耗时加起来构成了性能瓶颈。




待优化的点:地址暴露接口与执行秒杀操作。

DAO数据访问对象。访问数据库或者访问redis等存储的包都放在dao路径下。
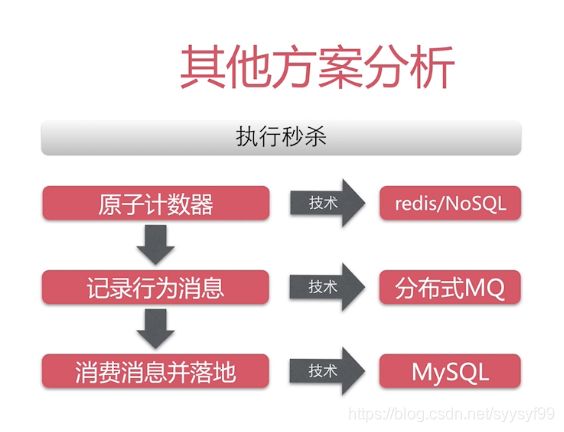
秒杀的优化:
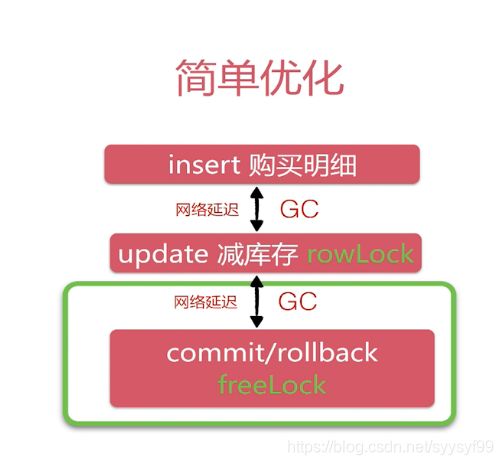
对比上图和之前的图,可以发现优化点在:把SQL语句的顺序进行了调换,这是因为insert语句发生冲突的概率小,可以不用加锁,而减库存update的冲突发生概率大,需要加锁,所以调换顺序后,加锁可以在第二步SQL语句才加锁,减小了加锁的时间。

密码是加密的字符串,一般不跟主表创建在一起。
model有三层,第一层是dataobject,这是与数据库完完全全映射,数据库的表中有什么字段,这个dataobject里就有哪些字段,不含有逻辑,是最简单的ORM映射。
在service层要有一个model概念,这个才是真正意义上Spring MVC交互模型的概念。
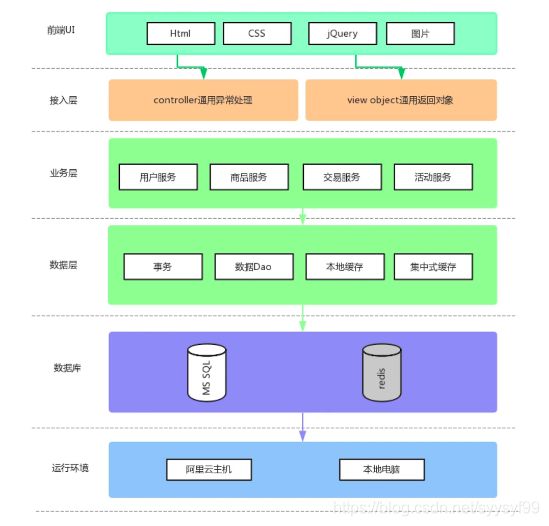
前后端分离的设计方式,如上图通过HTML+CSS+jQuery+图片+merolic框架完成了用户注册、登录、商品展示、下单交易、秒杀倒计时,
在接入层使用Spring MVC的Controller,定义了对应的view Object,返回了通用的对象,在Controller层通过通用异常处理,结合通用返回对象,返回了前后端分离的JSON dataStatus模型。
在业务层中使用MyBatis接入,以及Model层领域模型的概念,完成用户服务、商品服务、交易服务、活动服务。
数据层使用transactional注解完成事务的切面,用数据库、MyBatis的DAO完成对数据的操作。