MMDetection框架入门教程(完全版)

网上MMDetection的教程看似有很多,但感觉都不成系统,看完一圈下来还是不知道MMDetection要怎么用。这里还是推荐直接跟着官方教程,结合源码学习MMDetection,相关链接汇总如下:
- 官方教程 - MMCV
- 官方教程 - MMDetection
- 官方教程 - 不得不知的 MMDetection 学习路线(个人经验版)
- 西安交大课件 - mmdetection教程(使用篇)
本文会介绍如何在MMDetection中从头开始搭建一套属于自己的算法。前几篇博客算是本人学习过程中的笔记,从源码本身分析了MMDetection的原理,比较细碎,本篇博客会从宏观的角度重新梳理一下MMDetection的使用方法以及流程原理,算是对之前一个月学习过程的总结。
- MMDetection框架入门教程(一):Anaconda3下的安装教程(mmdet+mmdet3d)
- MMDetection框架入门教程(二):快速上手教程
- MMDetection框架入门教程(三):配置文件详细解析
- MMDetection框架入门教程(四):注册机制详解
- MMDetection框架入门教程(五):Runner和Hook详细解析
1. 框架概述
MMDetection是商汤和港中文大学针对目标检测任务推出的一个开源项目,它基于Pytorch实现了大量的目标检测算法,把数据集构建、模型搭建、训练策略等过程都封装成了一个个模块,通过模块调用的方式,我们能够以很少的代码量实现一个新算法,大大提高了代码复用率。
整个MMLab家族除了MMDetection,还包含针对目标跟踪任务的MMTracking,针对3D目标检测任务的MMDetection3D等开源项目,他们都是以Pytorch和MMCV以基础。Pytorch不需要过多介绍,MMCV是一个面向计算机视觉的基础库,最主要作用是提供了基于Pytorch的通用训练框架,比如我们常提到的Registry、Runner、Hook等功能都是在MMCV中支持的。另外,MMCV还提供了通用IO接口、多种CNN网络结构、高质量实现的常见CUDA算子,这里就不进一步展开了。

2. 框架整体流程
2.1 Pytorch
我们使用Pytorch构建一个新算法时,通常包含如下几步:
- 构建数据集:新建一个类,并继承
Dataset类,重写__getitem__()方法实现数据和标签的加载和遍历功能,并以pipeline的方式定义数据预处理流程 - 构建数据加载器:传入相应的参数实例化DataLoader
- 构建模型:新建一个类,并继承
Module类,重写forward()函数定义模型的前向过程 - 定义损失函数和优化器:根据算法选择合适和损失函数和优化器
- 训练和验证:循环从DataLoader中获取数据和标签,送入网络模型,计算loss,根据反传的梯度使用优化器进行迭代优化
- 其他操作:在主调函数里可以任意穿插训练Tricks、日志打印、检查点保存等操作
2.2 MMDetection
使用Pytorch构建一个新算法时,通常包含如下几步:
- 注册数据集:
CustomDataset是MMDetection在原始的Dataset基础上的再次封装,其__getitem__()方法会根据训练和测试模式分别重定向到prepare_train_img()和prepare_test_img()函数。用户以继承CustomDataset类的方式构建自己的数据集时,需要重写load_annotations()和get_ann_info()函数,定义数据和标签的加载及遍历方式。完成数据集类的定义后,还需要使用DATASETS.register_module()进行模块注册。 - 注册模型:模型构建的方式和Pytorch类似,都是新建一个
Module的子类然后重写forward()函数。唯一的区别在于MMDetection中需要继承BaseModule而不是Module,BaseModule是Module的子类,MMLab中的任何模型都必须继承此类。另外,MMDetection将一个完整的模型拆分为backbone、neck和head三部分进行管理,所以用户需要按照这种方式,将算法模型拆解成3个类,分别使用BACKBONES.register_module()、NECKS.register_module()和HEADS.register_module()完成模块注册。 - 构建配置文件:配置文件用于配置算法各个组件的运行参数,大体上可以包含四个部分:datasets、models、schedules和runtime。完成相应模块的定义和注册后,在配置文件中配置好相应的运行参数,然后MMDetection就会通过
Registry类读取并解析配置文件,完成模块的实例化。另外,配置文件可以通过_base_字段实现继承功能,以提高代码复用率。 - 训练和验证:在完成各模块的代码实现、模块的注册、配置文件的编写后,就可以使用
./tools/train.py和./tools/test.py对模型进行训练和验证,不需要用户编写额外的代码。
2.3 流程对比
虽然从步骤上看MMDetection相比Pytorch的算法实现步骤存在挺大差异,但底层的逻辑实现和Pytorch本质上还是一样的,可以参考下图对照着进行理解,其中蓝色部分表示Pytorch流程,橙色部分表示MMDetection流程,绿色部分表示和算法框架无关的通用流程。
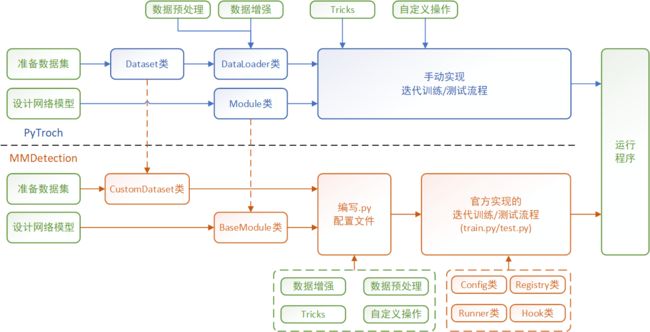
在开始接触MMDetection的算法实现流程之前,必须要先对注册机制和Hook机制有一个大致的了解,推荐先快速阅读,对注册机制和Hook机制先有一个大体上的了解,看完第五章后再回过头来看注册机制和Hook机制的细节部分会有更深的体会。
3. 注册机制
3.1 Registry类
MMDetection作为MMCV的下游项目,继承了MMCV的模块管理方式——注册机制。简单来说,注册机制就是维护几张查询表,key是模块的名称,value是模块的句柄,每张查询表都管理一批功能相似的不同模块。我们每新建一个模块,都要根据模块实现的功能将对应的key-value查询对保存到对应的查询表中,这个保存的过程就称为“注册”。当我们想要调用某个模块时,只需要根据模块名称从查询表中找到对应的模块句柄,然后就能完成模块初始化或方法调用等操作。MMCV通过Registry类来实现字符串(key)到类(value)的映射。
Registry的构造函数如下所示,变量self._module_dict就是上面提到的“查询表”,注册的模块都会存到这个字典类型的变量里,新建一个Registry实例就是新建一张查询表。另外,Registry还支持继承机制。
from mmcv.utils import Registry
class Registry:
# 构造函数
def __init__(self, name, build_func=None, parent=None, scope=None):
# 注册器的名称
self._name = name
# 使用module_dict管理字符串到类的映射
self._module_dict = dict()
# 使用children管理注册器的子类
self._children = dict()
# build_func按照如下优先级初始化:
# 1. build_func: 优先使用指定的函数
# 2. parent.build_func: 其次使用父类的build_func
# 3. build_from_cfg: 默认从config dict中实例化对象
if build_func is None:
if parent is not None:
self.build_func = parent.build_func
else:
self.build_func = build_from_cfg
else:
self.build_func = build_func
# 设置父类-子类的从属关系
if parent is not None:
assert isinstance(parent, Registry)
parent._add_children(self)
self.parent = parent
else:
self.parent = None
模块的注册通过Registry的成员函数register_module()来实现,register_module()内部又会调用另一个私有函数_register_module(),模块注册的核心功能其实是在_register_module()中实现的。核心代码也很简单,就是将传入的module_name和module_class保存到字典self._module_dict中。
def _register_module(self, module_class, module_name=None, force=False):
# 如果未指定模块名称则使用默认名称
if module_name is None:
module_name = module_class.__name__
# 为了支持在nn.Sequentail中构建pytorch模块, module_name为list形式
if isinstance(module_name, str):
module_name = [module_name]
for name in module_name:
# 如果force=False, 则不允许注册相同名称的模块
# 如果force=True, 则用后一次的注册覆盖前一次
if not force and name in self._module_dict:
raise KeyError(f'{name} is already registered in {self.name}')
# 将当前注册的模块加入到查询表中
self._module_dict[name] = module_class
在我们通过字符串获取到一个模块的句柄后,可以通过self.build_func函数句柄来实例化这个模块。build_func可以人为指定,也可以从父类继承,一般来说都是默认使用build_from_cfg()函数,即使用配置参数cfg来初始化该模块。配置参数cfg是一个字典,里面的type字段是模块名称的字符串,其他字段则对应模块构造函数的输入参数。
def build_from_cfg(cfg, registry, default_args=None):
args = cfg.copy()
# 将cfg以外的外部传入参数也合并到args中
if default_args is not None:
for name, value in default_args.items():
args.setdefault(name, value)
# 获取模块名称
obj_type = args.pop('type')
if isinstance(obj_type, str):
# get函数返回registry._module_dict中obj_type对应的模块句柄
obj_cls = registry.get(obj_type)
if obj_cls is None:
raise KeyError(f'{obj_type} is not in the {registry.name} registry')
elif inspect.isclass(obj_type):
# type值是模块本身
obj_cls = obj_type
else:
raise TypeError(f'type must be a str or valid type, but got {type(obj_type)}')
# 模块初始化, 返回模块实例
try:
return obj_cls(**args)
except Exception as e:
raise type(e)(f'{obj_cls.__name__}: {e}')
考虑到registry参数需要指向当前注册器本身,我们一般是调用Registry类的build()方法而不是self.build_func。
def build(self, *args, **kwargs):
return self.build_func(*args, **kwargs, registry=self)
下面是一个小例子,模拟了网络模型的注册和调用过程。注意一下,我们打印Registry对象时,实际上打印的是self._module_dict中的values。
# 实例化一个注册器用来管理模型
MODELS = Registry('myModels')
# 方式1: 在类的创建过程中, 使用函数装饰器进行注册(推荐)
@MODELS.register_module()
class ResNet(object):
def __init__(self, depth):
self.depth = depth
print('Initialize ResNet{}'.format(depth))
# 方式2: 完成类的创建后, 再显式调用register_module进行注册(不推荐)
class FPN(object):
def __init__(self, in_channel):
self.in_channel= in_channel
print('Initialize FPN{}'.format(in_channel))
MODELS.register_module(name='FPN', module=FPN)
print(MODELS)
""" 打印结果为:
Registry(name=myModels, items={'ResNet': , 'FPN': })
"""
# 配置参数, 一般cfg从配置文件中获取
backbone_cfg = dict(type='ResNet', depth=101)
neck_cfg = dict(type='FPN', in_channel=256)
# 实例化模型(将配置参数传给模型的构造函数), 得到实例化对象
my_backbone = MODELS.build(backbone_cfg)
my_neck = MODELS.build(neck_cfg)
print(my_backbone, my_neck)
""" 打印结果为:
Initialize ResNet101
Initialize FPN256
<__main__.ResNet object at 0x000001E68E99E198> <__main__.FPN object at 0x000001E695044B38>
"""
3.2 注册机制小结
注册机制是一种模块管理手段,按照不同的模块功能对模块进行分组管理,每个分组都由一张查询表维护,查询表记录了模块名称(字符串)到模块本身(本身)的映射关系,将映射关系记录到查询表的过程称为 “注册”。一旦模块完成注册,只要根据模块名称就能很方便的索引到具体的模块句柄,之后就可以按照正常程序流程,对模块进行初始化和使用。一个模块的注册到使用包含5个步骤:
- 新建一个类,实现自定义功能
- 将该类注册到对应的查询表中(
register_module) - 在配置文件中指定该模块的初始化参数
- 通过build函数对模块进行实例化(
build_from_cfg) - 使用该实例对象执行功能函数
4. Hook机制
4.1 Hook类
MMDetection的整个算法过程就像一个黑盒子:给定输入后(配置文件),黑盒子就会吐出算法结果。整个过程封装度非常高,几乎不需要手写什么代码,但是我们如何在算法执行过程中加入自定义操作呢?这就是Hook机制的作用。
简单来说,Hook可以理解为一种触发器,可以在程序预定义的位置执行预定义的函数。MMCV根据算法的生命周期预定义了6个可以插入自定义函数的位点,用户可以在每个位点自由地插入任意数量的函数操作,如下图所示:

这6个位置基本涵盖了自定义操作可能出现的位置,MMCV已经实现了部分常用Hook,其中默认Hook不需要用户自行注册,通过配置文件配置对应的参数即可;定制Hook则需要用户在配置文件中手动配置custom_hooks字段进行注册。
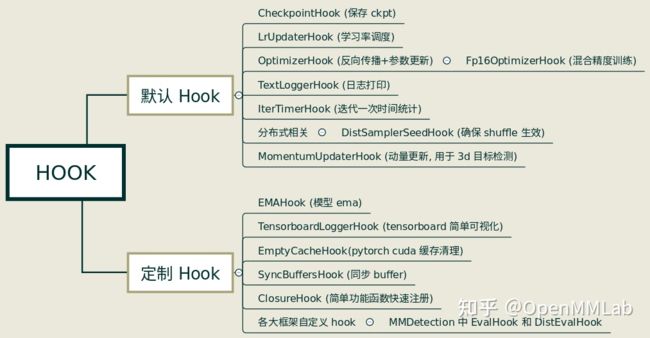
Hook类本身代码很少,只提供了预定义位置的接口函数,任何自定义的Hook都需要继承Hook类,然后根据需要重写对应的接口函数。比如检查点保存操作通常发生在每次迭代或epoch后,所以我们需要重写after_train_iter和after_train_epoch。
class Hook:
def before_run(self, runner):
pass
def after_run(self, runner):
pass
def before_epoch(self, runner):
pass
def after_epoch(self, runner):
pass
def before_iter(self, runner):
pass
def after_iter(self, runner):
pass
@HOOKS.register_module()
class CheckpointHook(Hook):
def __init__(self,
interval=-1,
by_epoch=True,
save_optimizer=True,
out_dir=None,
max_keep_ckpts=-1,
**kwargs):
...
def after_train_iter(self, runner):
...
def after_train_epoch(self, runner):
...
和其他模块不同,当我们定义好一个Hook(并注册到HOOKS注册器中)之后,还需要注册到Runner中才能使用,前后一共进行两次注册。第一次注册到HOOKS是为了程序能够根据Hook名称找到对应的模块,第二次注册到Runner中是为了程序执行到预定义位置时能够调用对应的函数。
Runner是MMCV用来管理训练过程的一个类,它内部会维护一个list类型变量self._hooks,我们需要把训练过程会调用的Hook实例对象按照优先级顺序全部添加到self._hooks中,这个过程通过Runner.register_hook()函数实现。MMCV预定义了几种优先级, 数字越小表示优先级越高, 如果觉得默认的分级方式颗粒度过大, 也可以直接传入0~100的整数进行精细划分。
def register_hook(self, hook, priority='NORMAL'):
"""预定义优先级
+--------------+------------+
| Level | Value |
+==============+============+
| HIGHEST | 0 |
+--------------+------------+
| VERY_HIGH | 10 |
+--------------+------------+
| HIGH | 30 |
+--------------+------------+
| ABOVE_NORMAL | 40 |
+--------------+------------+
| NORMAL | 50 |
+--------------+------------+
| BELOW_NORMAL | 60 |
+--------------+------------+
| LOW | 70 |
+--------------+------------+
| VERY_LOW | 90 |
+--------------+------------+
| LOWEST | 100 |
+--------------+------------+
"""
hook.priority = priority
# 插入法排序将Hooks按照priority大小升序排列
inserted = False
for i in range(len(self._hooks) - 1, -1, -1):
if priority >= self._hooks[i].priority:
self._hooks.insert(i + 1, hook)
inserted = True
break
if not inserted:
self._hooks.insert(0, hook)
将Hook实例加入到self._hooks中之后,然后就可以在预定义位置调用call_hook()来调用各个Hook实例中的对应方法。call_hook()称为回调函数。
# 开始运行时调用
self.call_hook('after_train_epoch')
while self.epoch < self._max_epochs:
# 开始 epoch 迭代前调用
self.call_hook('before_train_epoch')
for i, data_batch in enumerate(self.data_loader):
# 开始 iter 迭代前调用
self.call_hook('before_train_iter')
self.model.train_step()
# 经过一次迭代后调用
self.call_hook('after_train_iter')
# 经过一个 epoch 迭代后调用
self.call_hook('after_train_epoch')
# 运行完成前调用
self.call_hook('after_train_epoch')
调用call_hook()时会遍历self._hooks中所有Hook实例,并根据fn_name调用Hook实例的指定成员函数。比如fn_name='before_train_epoch'时,call_hook()会挨个调用所有Hook的before_train_epoch()函数。而且由于self._hooks已经按照优先级进行过排序,call_hook()会先调用优先级高的Hook方法。
def call_hook(self, fn_name):
for hook in self._hooks:
getattr(hook, fn_name)(self)
4.2 Hook机制小结
Hook是一种设置在程序固定位置的触发器,当程序执行到预设位点时则会触发断点,执行Hook函数的流程,结束后再回到断点位置继续执行主流程的代码。实现一个Hook包含5个步骤:
- 定义一个类,继承Hook基类
- 根据自定义Hook的功能有选择地重写Hook基类中对应的函数
- 注册自定义Hook模块到HOOKS查询表中(
register_module) - 实例化Hook模块并注册到Runner中(
register_hook) - 使用回调函数调用重写的Hook函数(
call_hook)
5. 算法实现流程
2.2节提到,使用MMDetection实现一个新算法,包含注册数据集、注册模型、构建配置文件、训练/验证这四个步骤。要理解MMDetection的算法实现流程,必须要吃透Config、Registry、Runner和Hook这四个类。
5.1 注册数据集
定义自己的数据集时,需要新写一个继承CustomDataset的Dataset类,然后重写load_annotations()函数和get_ann_info()函数。官方文档上说,用户如果要使用CustomDataset,要将现有数据集转换成MMDetection兼容的格式(COCO格式或中间格式) 。但我看了一下底层的代码并没有发现有这个限制,只要你的数据格式能和你实现的load_annotations()和get_ann_info()对应上即可。
"""
中间数据格式:
[
{
'filename': 'a.jpg', # 图片路径
'width': 1280, # 图片尺寸
'height': 720,
'ann': { # 标注信息
'bboxes': (n, 4), # 标注框坐标(x1, y1, x2, y2)
'labels': (n, ), # 标注框类别
'bboxes_ignore': (k, 4), # 不关注的标注框坐标(可选)
'labels_ignore': (k, ) # 不关注的标注框类别(可选)
}
},
...
]
"""
class CustomDataset(Dataset):
CLASSES = None
def __init__(self,
ann_file, # 文件路径
pipeline, # 数据预处理pipeline
classes=None, # 检测类别
data_root=None, # 文件根路径
img_prefix='',
seg_prefix=None,
proposal_file=None,
test_mode=False, # 为True的话将不会加载标注信息
filter_empty_gt=True): # 为True的话将会过滤没有标注框的图像(只在test_mode=False的条件下有效)
self.ann_file = ann_file
self.data_root = data_root
self.img_prefix = img_prefix
self.seg_prefix = seg_prefix
self.proposal_file = proposal_file
self.test_mode = test_mode
self.filter_empty_gt = filter_empty_gt
self.CLASSES = self.get_classes(classes)
# 调用load_annotations函数加载样本和标签
self.data_infos = self.load_annotations(self.ann_file)
# 用户可以通过重写_filter_imgs()函数在训练过程中实现自定义的样本过滤功能
if not test_mode:
valid_inds = self._filter_imgs()
self.data_infos = [self.data_infos[i] for i in valid_inds]
# 根据pipeline对样本进行预处理
self.pipeline = Compose(pipeline)
在Pytorch中Dataset的遍历是通过重写__getitem__()函数实现的,但MMDetection的CustomDataset虽然是Dataset的子类,却没有要求我们重写__getitem__()函数,原因是为了方便训练模式和测试模式下的数据管理,MMDetection已经重写了__getitem__()函数,可以根据当前运行模式调用prepare_train_img()或prepare_test_img(),两者的区别在于是否加载训练标签。所以我们只需要重写load_annotations()和get_ann_info()函数,剩下的部分交给MMDetection就可以了。
def __getitem__(self, idx):
if self.test_mode:
return self.prepare_test_img(idx)
else:
return self.prepare_train_img(idx)
# 返回预处理后的训练样本及标签
def prepare_train_img(self, idx):
img_info = self.data_infos[idx]
# 调用get_ann_info获取训练标签
ann_info = self.get_ann_info(idx)
results = dict(img_info=img_info, ann_info=ann_info)
return self.pipeline(results)
# 返回预处理后的测试样本
def prepare_test_img(self, idx):
img_info = self.data_infos[idx]
results = dict(img_info=img_info)
return self.pipeline(results)
完成自定义的Dataset类后别忘记加上@DATASETS.register_module()将当前模块注册到DATASETS表中。
5.2 注册模型
网络模型的定义比较简单,相比Pytorch只有两个区别:
- 继承的父类从
Module变成了BaseModule - 需要按照backbone、neck和head的结构将模型拆解成3个部分,分别定义并注册到
BACKBONES、NECKS以及HEADS当中。
5.3 构建配置文件
2.2节有提到,在MMDetection框架下,我们不需要另外实现迭代训练/测试流程的代码,只需要执行现成的train.py或test.py即可。但MMDetection怎么知道我们需要哪些模块呢?这就是配置文件起到的作用。
5.3.1 配置文件的构成
配置文件是由一系列变量定义组成的文本文件,其中dict类型的变量表示一个个的模块,dict变量必须包含type字段,表示模块名称,其它字段则和模块构造函数的参数一一对应,届时用于该模块的初始化(见第本文3章的build_from_cfg()函数)。该模块必须是已经注册的,否则后续MMDetection无法根据type值找到对应的模块。配置文件除了dict类型的变量以外,还可以是其他任意类型,一般是辅助dict变量定义的中间变量,比如:
test_pipeline = [
dict(type='LoadMultiViewImageFromFiles', to_float32=True),
dict(type='NormalizeMultiviewImage', **img_norm_cfg),
dict(type='PadMultiViewImage', size_divisor=32)
]
evaluation = dict(interval=2, pipeline=test_pipeline)
配置文件也支持继承操作,通过_base_变量来实现。_base_是一个list类型变量,里面存储的是要继承的配置文件的路径。在解析配置文件的时候,文件解析器以递归的方式(其他配置文件也可能包含_base_变量)解析所有配置文件。任何配置文件往上追溯都会继承以下四个文件,分别对应数据集(datasets)、模型(models)、训练策略(schedules)和运行时的默认配置(default_runtime):
_base_ = [
'mmdetection/configs/_base_/models/fast_rcnn_r50_fpn.py', # models
'mmdetection/configs/_base_/datasets/coco_detection.py', # datasets
'mmdetection/configs/_base_/schedules/schedule_1x.py', # schedules
'mmdetection/configs/_base_/default_runtime.py', # defualt_runtime
]
如果你对上面继承这4个基础配置文件的配置文件进行打印,可以看到如下内容,这也是任何一个完整配置文件都应该包含的配置信息。当然,你也可以任意增加自定义的配置信息。所以我们平常新建一个配置文件的时候,一般都是继承这4个基础配置文件,然后在此基础上进行针对性调整。
# 1. 模型配置(models) =========================================
model = dict(
type='FastRCNN', # 模型名称是FastRCNN
backbone=dict( # BackBone是ResNet
type='ResNet',
...,
),
neck=dict( # Neck是FPN
type='FPN',
...,
),
roi_head=dict( # Head是StandardRoIHead
type='StandardRoIHead',
...,
loss_cls=dict(...), # 分类损失函数
loss_bbox=dict(...), # 回归损失函数
),
train_cfg=dict( # 训练参数配置
assigner=dict(...), # BBox Assigner
sampler=dict(...), # BBox Sampler
...
),
test_cfg =dict( # 测试参数配置
nms=dict(...), # NMS后处理
...,
)
)
# 2. 数据集配置(datasets) =========================================
dataset_type = '...' # 数据集名称
data_root = '...' # 数据集根目录
img_norm_cfg = dict(...) # 图像归一化参数
train_pipeline = [ # 训练数据处理Pipeline
...,
]
test_pipeline = [...] # 测试数据处理Pipeline
data = dict(
samples_per_gpu=2, # batch_size
workers_per_gpu=2, # GPU数量
train=dict( # 训练集配置
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json', # 标注问加你
img_prefix=data_root + 'train2017/', # 图像前缀
pipline=trian_pipline, # 数据预处理pipeline
),
val=dict( # 验证集配置
...,
pipline=test_pipline,
),
test=dict( # 测试集配置
...,
pipline=test_pipline,
)
)
# 3. 训练策略配置(schedules) =========================================
evaluation = dict(interval=1, metric='bbox')
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
# 4. 运行配置(runtime) =========================================
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
另外还有一些可选的配置参数,比如custom_imports,用于导入用户自定义的模块,当配置文件解析器解析到该字段时,会调用import_modules_from_strings()函数将字段imports包含的模块导入到程序中。
custom_imports = dict(imports=['os.path', 'numpy'], # list类型, 需要导入的模块名称
allow_failed_imports=False) # 如果设为True, 导入失败时会返回None而不是报错
5.3.2 配置文件的修改
修改配置文件时会遇到2种情况:
- 修改已有dict的某个参数:直接重写对应的参数
- 需要删掉原有dict的所有参数,然后用一组全新的参数代替:增加
_delete_=True字段
以修改学习率和更换优化器为例解释这两种情况下应该怎么修改配置文件:
# 从_base_中继承的原始优化器
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
# 修改学习率
optimizer = dict(lr=0.001)
# 修改后optimizer变成
optimizer = dict(type='SGD', lr=0.001, momentum=0.9, weight_decay=0.0001)
# 将原来的SGD替换成AdamW
optimizer = dict(_delete_=True, type='AdamW', lr=0.0001, weight_decay=0.0001)
# 替换后optimizer变成
optimizer = dict(type='AdamW', lr=0.0001, weight_decay=0.0001)
5.3.3 配置文件的解析
解析配置文件其实是train.py和test.py要做的事,这里放到和构建配置文件一块讲了,逻辑上会更通畅一些。
一般使用Config类来管理配置文件。使用Config.fromfile(filename)来读取配置文件(也可以直接传入一个dict),返回一个Config类实例cfg,然后可以通过print(cfg.pretty_text)的方式来打印配置文件信息,或者通过cfg.dump(filepath)来保存配置文件信息。
from mmcv import Config
cfg = Config.fromfile('../configs/test_config.py')
fromfile()函数源码如下,其核心函数是_file2dict()。_file2dict()会根据文本顺序,按照key = value的格式解析配置文件,得到一个名为cfg_dict的字典,如果存在_base_字段,还会对_base_包含的每个文件路径再调用一次_file2dict()函数,将文件中包含的配置参数加入到cfg_dict中,实现配置文件的继承功能。需要注意的是,_file2dict()内部会对_base_中不同文件包含的键值进行校验,不同基础配置文件中不允许出现重复的键值,否则Config不知道以哪个配置文件为准。
def fromfile(filename,
use_predefined_variables=True,
import_custom_modules=True):
cfg_dict, cfg_text = Config._file2dict(filename,
use_predefined_variables)
# import_modules_from_strings()是根据字符串列表导入对应的模块
if import_custom_modules and cfg_dict.get('custom_imports', None):
import_modules_from_strings(**cfg_dict['custom_imports'])
return Config(cfg_dict, cfg_text=cfg_text, filename=filename)
调用_file2dict()解析得到的cfg_dict格式如下,配置文件中的文本信息全部转换成了变量存储在一个字典类型之中。

另外有两点需要补充一下,其一是构造Config对象的时候,会将python的dict数据类型转换为ConfigDict类型进行处理。ConfigDict是第三方库addict中Dict的子类(Dict又是pythondict的子类),因为python原生的dict类型不支持.属性的访问方式,特别是dict内部嵌套了多层dict的时候,如果按照key的访问方式,代码写起来非常低效,而Dict类通过重写__getattr__()的方式实现了.属性的访问方式。所以继承了Dict的ConfigDict也支持使用.属性的方式访问字典中的各个成员值。
from mmcv import ConfigDict
model = ConfigDict(dict(backbone=dict(type='ResNet', depth=50)))
print(model.backbone.type) # 输出 'ResNet'
其二,为了兼容配置文件名中出现小数点的情况,_file2dict()会在C盘下创建一个临时文件夹进行操作,如果C盘有访问权限设置,可能会出现报错,不过这个问题只会出现在Windows系统下。
5.3.4 配置文件小结
简单回顾一下,配置文件是一个包含多个dict变量的文本文件,每个dict对应一个具体的模块(该模块必须已经注册),dict必须要有type字段,其他字段和该模块的构造参数相对应。当对调用build()函数对模块进行实例化的时候,会根据type字符串的值从查询表中找到对应的模块句柄,并使用dict中其他字段的值作为构造参数对该模块进行初始化。
5.4 训练和测试
用MMDetection实现一个算法包含四个步骤,第一第二步注册数据集和模型的目的是构建基础模块(数据流和模型),第三步构建配置文件的目的是指定需要的模块以及模块的输入参数,接下来第四步就是根据配置文件把事先定义好的模块一个个拎出来,传入指定的输入参数,然后按照算法流程依次串起来。
5.4.1 train.py文件
我们先过一遍官方提供的train.py代码(我只保留了核心功能代码),然后再介绍MMDetection是如何使用Runner和Hook来调度整个训练流程的,这样理解起来会更快一些。
train.py的主调函数做了4件事情,一个是利用Config类对我们第三步构建好的配置文件进行解析,然后对模型和数据集进行初始化,最后将模型和数据集传入train_detector()函数,准备开始训练流程。
def main():
# Step1: 解析配置文件, args.config是配置文件路径(如何解析配置文件可以参考本文4.3.3节)
cfg = Config.fromfile(args.config)
# Step2: 初始化模型, 函数内部调用的是DETECTORS.build(cfg)
model = build_detector(cfg.model)
# 初始化模型权重
model.init_weights()
# Step3: 初始化训练集和验证集, 函数内部调用build_from_cfg(cfg, DATASETS), 等价于DATASETS.build(cfg)
datasets = [build_dataset(cfg.data.train)]
if len(cfg.workflow) == 2:
val_dataset = copy.deepcopy(cfg.data.val)
val_dataset.pipeline = cfg.data.train.pipeline # 验证集在训练过程中使用train pipeline而不是test pipeline
datasets.append(build_dataset(val_dataset))
# Step4: 传入模型和数据集, 准备开始训练模型
train_detector(model, datasets, cfg)
train_detector()函数主要是构建了dataloader,初始化了优化器以及runner和hooks,最后调用runner.run开始正式的迭代训练流程。其中涉及到了Runner的概念,不过这里先不展开,我们只要知道Runner也是一个模块,负责模型的迭代训练。
def train_detector(model, dataset, cfg):
# 获取Runner类型, EpochBasedRunner或IterBasedRuner
runner_type = 'EpochBasedRunner' if 'runner' not in cfg else cfg.runner['type']
# Step1: 获取dataloader, 因为dataset列表里包含了训练集和验证集, 所以使用for循环的方式构建dataloader
# build_dataloader()会用DataLoader类进行dataloader的初始化
data_loaders = [
build_dataloader(
ds,
cfg.data.samples_per_gpu, # batch_size
runner_type=runner_type) for ds in dataset
]
# Step2: 封装模型, 为了进行分布式训练
model = MMDataParallel(model.cuda(cfg.gpu_ids[0]), device_ids=cfg.gpu_ids)
# Step3: 初始化优化器
optimizer = build_optimizer(model, cfg.optimizer)
# Step4: 初始化Runner
runner = build_runner(
cfg.runner,
default_args=dict(model=model, optimizer=optimizer)
# Step5: 注册默认Hook(注册到runner._hooks列表中)
runner.register_training_hooks(cfg.lr_config, optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
# Step6: 注册自定义Hook(注册到runner._hooks列表中)
if cfg.get('custom_hooks', None):
custom_hooks = cfg.custom_hooks
for hook_cfg in cfg.custom_hooks:
hook_cfg = hook_cfg.copy()
priority = hook_cfg.pop('priority', 'NORMAL')
hook = build_from_cfg(hook_cfg, HOOKS)
runner.register_hook(hook, priority=priority)
# Step7: 开始训练流程
if cfg.resume_from:
# 恢复检查点
runner.resume(cfg.resume_from)
elif cfg.load_from:
# 加载预训练模型
runner.load_checkpoint(cfg.load_from)
# 调用run()方法, 开始迭代过程
runner.run(data_loaders, cfg.workflow)
虽然官方train.py文件写的很长,但是把核心代码扒出来一看,其实都是我们在Pytorch中熟悉的操作。整个train.py的流程如下图所示
- 首先解析传入的配置文件,并实例化配置文件中的各个模块;
- 然后使用datasets构造
data_loader,这里model使用了MMDataParallel进行了一层封装,主要是为了后续进行分布式训练; - 然后使用data_loader和optimizer初始化一个Runner类对象
runner; - 注册训练过程中需要使用的Hooks
- 根据配置文件指定的工作流
workflow执行runner.run()函数进行迭代训练

下面对runner.run()函数内部进行展开介绍。
5.4.2 Runner类
Runner分为EpochBasedRunner和IterBasedRunner,顾名思义,前者以epoch的方式管理流程,后者以iter的方式管理流程,它们都是BaseRunner的子类。EpochBasedRunner和IterBasedRunner本身没有重写构造函数,直接继承了BaseRunner的构造函数:
class BaseRunner(metaclass=ABCMeta):
def __init__(self,
model, # [torch.nn.Module] 要运行的模型
batch_processor=None, # 该参数一般不使用
optimizer=None, # [torch.optim.Optimizer] 优化器, 可以是一个也可以是一组通过dict配置的优化器
work_dir=None, # [str] 保存检查点和Log的目录
logger=None, # [logging.Logger] 训练中使用的日志记录器
meta=None, # [dict] 一些信息, 这些信息会在logger hook中记录
max_iters=None, # [int] 训练epoch数
max_epochs=None): # [int] 训练迭代次数
BaseRunner的任何子类都需要实现run()、train()、val()和save_checkpoint()四个方法,这也是Runner的核心方法,接下来就以EpochBasedRunner类为例对这四个函数进行详细分析。
run()函数
run()是Runner类的主调函数,会根据workflow指定的工作流,对data_loaders中的数据进行处理。目前MMCV支持训练和验证两种工作流,对于EpochBasedRunner而言,workflow配置为[('train', 2),('val', 1)]表示先训练2个epoch,然后验证一个epoch;[('train', 1)]表示只进行训练,不进行验证。如果是IterBasedRunner,[('train', 2),('val', 1)]则表示先训练2个iter,然后验证一个iter。然后getattr(self, mode)会根据不同mode调用self.train()函数和self.val()函数。
def run(self, data_loaders, workflow, max_epochs=None, **kwargs):
while self.epoch < self._max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
# 如果mode='train', 则调用self.train()函数
# 如果mode='val', 则调用self.val()函数
epoch_runner = getattr(self, mode)
for _ in range(epochs):
if mode == 'train' and self.epoch >= self._max_epochs:
break
# 运行train()或val()
epoch_runner(data_loaders[i], **kwargs)
train()和val()函数
train()和val()函数循环调用run_iter()完成一个epoch流程。函数开头的self.model.train()和self.model.eval()实际上调用的是torch.nn.module.Module的成员函数,将当前模块设置为训练模式或验证模式,两种不同模式下batchnorm、dropout等层的操作会有区别。然后由于测试过程不需要梯度回传,所以val函数加了一个装饰器@torch.no_grad()。
def train(self, data_loader, **kwargs):
# 将模块设置为训练模式
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(self.data_loader)
for i, data_batch in enumerate(self.data_loader):
self.run_iter(data_batch, train_mode=True, **kwargs)
self._iter += 1
self._epoch += 1
@torch.no_grad()
def val(self, data_loader, **kwargs):
# 将模块设置为验证模式
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
for i, data_batch in enumerate(self.data_loader):
self.run_iter(data_batch, train_mode=False)
def run_iter(self, data_batch, train_mode, **kwargs):
if self.batch_processor is not None:
outputs = self.batch_processor(self.model, data_batch, train_mode=train_mode, **kwargs)
elif train_mode:
outputs = self.model.train_step(data_batch, self.optimizer, **kwargs)
else:
outputs = self.model.val_step(data_batch, self.optimizer, **kwargs)
self.outputs = outputs
train()和val()的核心函数是run_iter(),根据train_mode参数调用model.train_step()或model.val_step(),这两个函数最终都会指向我们自己模型的forward()函数,返回模型的前向推理结果(一般是Loss值)。Runner到我们自己的模型中间还会经过MMDataParallel、BaseDetector、SingleStageDetector(或TwoStageDetector)四个类,最终调用我们自己模型的forward()函数,执行推理过程。
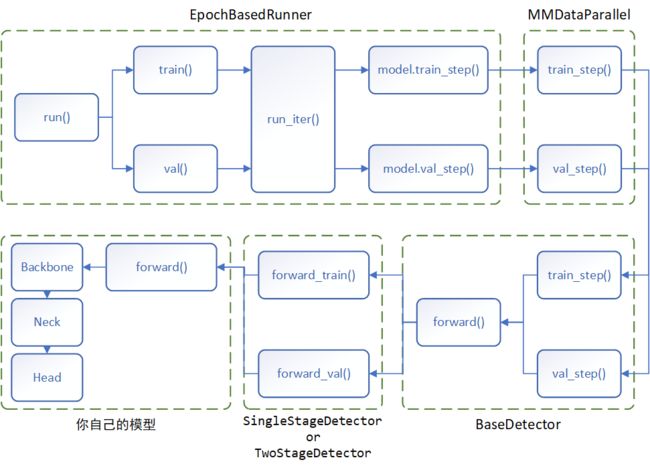
细心的同学可能会问,怎么从头到尾没看到梯度反传优化这一步骤?MMDetection的梯度优化是通过一个实现了after_train_iter()的Hook实现的,其优先级为ABOVE_NORMAL。
@HOOKS.register_module()
class OptimizerHook(Hook):
def after_train_iter(self, runner):
runner.optimizer.zero_grad()
runner.outputs['loss'].backward()
if self.grad_clip is not None:
grad_norm = self.clip_grads(runner.model.parameters())
if grad_norm is not None:
# Add grad norm to the logger
runner.log_buffer.update({'grad_norm': float(grad_norm)},
runner.outputs['num_samples'])
runner.optimizer.step()
save_checkpoint()函数
save_checkpoint()函数比较简单,就不过多说明了,最终是调用torch.save将检查点按下列格式保存成文件。
checkpoint = {
'meta': dict(), # 环境信息(比如epoch_num, iter_num)
'state_dict': dict(), # 模型的state_dict()
'optimizer': dict()) # 优化器的state_dict()
}