Hive基本语法、基本原理和优化方法
目录
背景
一、Hive基础篇
1.1 怎么来的?
1.2 hive是什么?
1.3 hive怎么用?
1.3.1 常用DDL举例
1.3.2 常用DML举例--insert的方式
1.3.3 常用query--关联/聚合/去重/排序举例
1.3.4 常用函数
二、Hive原理篇
2.1 hive编译和执行
2.1.1 hive系统架构
2.1.2 hive编译过程
2.1.3 hive查询执行流程
2.2 job调度
2.3 job执行引擎(MapReduce原理)
2.4 核心算子原理
2.4.1 Hive join原理
2.4.2 Hive group by原理
2.4.3 Hive distribute by 原理
2.4.4 Hive 排序
三、Hive优化篇
3.1 MAP阶段优化
3.2 Shuffle阶段优化
3.3 Reduce阶段优化
背景
当下很多企业都用hive数据仓库工具,本文介绍了hive的来源、基本原理和使用优化,方便初学者学习使用(初稿:后续会持续更新)。
一、Hive基础篇
1.1 怎么来的?
互联网时代,搜索引擎、电子商务、社交网络等会产生庞大的数据量,数据存储和分析面临挑战,存储扩容困难,统计分析复杂。
Google的三篇论文,它为大数据体系架构奠定了理论基础,Google是全球搜索引擎公司,它的数据迅速增长,为了满足庞大的储存需求,它设计并实现了GFS,分布式文件系统。解决了数据存储的问题,还需要对大规模数据集分析计算,Google设计了,MapReduce编程模型,可以对TB级数据做并行运算。
有了这个理论基础之后,Doug Cutting等人受到了启发,他们实现MapReduce计算框架,并和分布式文件系统结合再一起,有了一个很好的应用,最后它成为一套独立的软件,命名为Hadoop。
Hadoop解决了大数据存储和计算的问题,但是MapReduce编程不方便,HDFS上的文件没有Schema,统计分析比较困难,为了解决这个问题,Facebook一帮大牛搞了这个hive。

1.2 hive是什么?
基于Hadoop的一个数据仓库工具;
结构化数据映射成表,通过类SQL语言查询和分析数据,称为HiveQL(HQL);
Hive将SQL编译转化为MapReduce job,通过Hadoop集群执行。
hive是Hadoop生态体系中的一员。
上面多次提到MapReduce(MR),思考MR是什么?hive和MR的区别
下面从三个方面概述一下区别,如表:
| 对比项 |
hive |
MapReduce |
|---|---|---|
| 原理 |
HQL => MapReduce 任务 |
Map => Sort/Shuffle/Merge => Reduce |
| 编程方式 |
类似SQL的查询分析 |
创建MapReduce作业,实现两个回调函数:Mapper和Reducer |
| 易用性 |
门槛较低,接近于SQL分析 |
原始的API,实现复杂处理工作非常困难和费力 |
1.3 hive怎么用?
基本语法(这里可以和我们熟悉的MySQL,oracle类比学习),它可以分为四类,第一类DDL(主要对库表操作),第二类DML(主要是数据插入),第三类Query(就是常用的select,from,where等),第四类DCL(是权限控制),DCL平时用的较少,我们重点介绍DDL,DML和Query。
1.3.1 常用DDL举例
如下图:DDL的一个使用举例,创建一个内部分区表,添加字段,查看表字段,修改注释。这里要注意我们工作中经常用到分区表,存储格式一般是ORC。(思考列存储的优势)这里也列了常见存储格式,并简单比对了常用的存储格式。常用列存储有ORC,parquet,行存储是textfile,列存储相比行存储压缩比更高,读取效率更高。
思考内部表和外部表区别?
1)概念本质上
内部表数据自己的管理的在进行表删除时数据和元数据一并删除。
外部表只是对HDFS的一个目录的数据进行关联,外部表在进行删除时只删除元数据, 原始数据是不会被删除的。
2)应用场景上
外部表一般用于存储原始数据、公共数据,内部表一般用于存储某一个模块的中间结果数据。
3)存储目录上
外部表:一般在进行建表时候需要手动指定表的数据目录为共享资源目录,用location关键字指定。
内部表:无严格的要求,一般使用的默认目录。
1.3.2 常用DML举例--insert的方式
1. 单条数据插入,同mysql的单条数据插入,一次只能插入一条数据
insert into table tablename values();
insert into table student values(1303,2345,"xh",23,45,10);
2.单重数据插入 一次性插入多条数据,将sql查询语句的查询结果进行插入
insert into table tablename select ....
insert into table student select * from student_external where yuwen>80;
3.多重数据插入 对表扫描一次将数据插入到多个表中或者是同一个表的多个分区中
from tablename
insert into table table1 select ... where ...
insert into table table2 select ... where ..
4.静态分区插入和动态分区插入(思考动态分区为什么会有小文件问题)
insert into table tablename partition(分区字段(动态:分区字段不需要给值/静态:分区给值)) select … from table
动态分区产生小文件的原因分析:
假设有1000个task(或map),假定我们用的是二级分区,一级分区有5个值,二级分区有10个值,这时候要产生5*10=50个分区,再往hive中写数据的时候,每个task(写任务)极端情况下(每一个task中有每个分区的部分数据)会产生50个文件,累计会产生50*1000=5万个文件,就会带来大量小文件。
1.3.3 常用query--关联/聚合/去重/排序举例
1、关联/聚合/去重

注意:hive中的join只支持等值join,也就是说join on中的on里面表之间连接条件只能是=,不能是<,>等符号。此外,on中的等值连接之间只能是and,不能是or(如果在on 里添加非表之间的条件可以是非等号)。
inner join(内连接)只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。
left outerjoin(左外连接)在等值连接的基础上加上主表中的未匹配数据。
right outerjoin(右外连接)在等值连接的基础上加上被连接表的不匹配数据 。
Full outer join(全外连接)是在等值连接的基础上将左表和右表的未匹配数据都加上。
left semi join(左半连接)是IN/EXISTS子查询的一种更高效的实现。
(1)限制是JOIN子句中右边的表只能在ON子句中设置过滤条件,在WHERE子句、SELECT 子句或其他地方过滤都不行。
(2)只传递表的join key给map阶段,因此left semi join中最后select的结果只许出现左表。
(3)因为left semi join是in(keySet)的关系,遇到右表重复记录,左表会跳过,而join 则会一直遍历。这就导致右表有重复值得情况下left semi join只产生一条,join会产生多条,也会导致 left semi join 的性能更高。
1.3.4 常用函数
Hive中有这些函数,比如:数学函数、集合、日期函数等,本文我们重点介绍工作中常用的,窗口函数、行列转函数和自定义函数。
1、Hive函数如下表:
| 分类 |
样例 |
| 数学函数 |
abs、acos、asin、atan、bin、bround、cbrt、ceil、conv、cos、degrees、e、exp、factorial、floor、greatest、hex、least、ln、log2、log10、log、negative、pi、pmod、positive、pow、radians、rand、round、round、shiftleft、shiftright、shiftrightunsigned、sign、sin、sqrt、tan、unhex、width_bucket |
| 集合函数 |
size、map_keys、map_values、array_contains、sort_array |
| 类型转换函数 |
binary、cast |
| 日期函数 |
from_unixtime、unix_timestamp、to_date、year、quarter、month、day、hour、minute、second、weekofyear、extract、datediff、date_add、date_sub、from_utc_timestamp、to_utc_timestamp、current_date、current_timestamp、add_months、last_day、next_day、trunc、months_between、date_format |
| 条件判断函数 |
if、isnull、isnotnull、nvl、coalesce、case、nullif、assert_true |
| 字符串函数 |
ascii、base64、character_length、chr、concat、context_ngrams、concat_ws、decode、elt、encode、field、find_in_set、format_number、get_json_object、in_file、instr、length、locate、lower、lpad、ltrim、ngrams、octet_length、parse_url、printf、regexp_extract、regexp_replace、repeat、replace、reverse、rpad、rtrim、sentences、space、split、str_to_map、substr、substring_index、translate、trim、unbase64、upper、initcap、levenshtein、soundex |
| 数据脱敏函数 |
mask、mask_first_n、mask_last_n、mask_show_first_n 、mask_show_last_n、mask_hash |
| 杂项函数 |
java_method、reflect、hash、current_user、logged_in_user、current_database、md5、sha1、sha、crc32、sha2、aes_encrypt、aes_decryp、version |
| 窗口函数 |
cume_dist、dense_rank、first_value、lag、last_value、lead、ntil、percent_rank、rank、row_number |
| 行列转化 |
lateral view explode、concat_ws、collect_set |
| 自定义函数 |
UDF、UDAF、UDTF |
2、开窗函数应用举例
窗口函数就是通过一套语法实现分组聚合的函数,这里的语法就是函数+over从句(分组、排序和窗口字句),下面我们通过一些案例分别介绍,排序、取值和计算相关的窗口函数。

应用场景:用于分组排序、动态Group By、Top N、累计计算、层次查询。
(1)分组排序举例
| 分组排序 | 解释 |
|---|---|
| ROW_NUMBER() | 从1开始,按照顺序,生成分组内记录的序列 |
| RANK() | 生成分组内的排名,排名相等在名次会中留下空位 |
| DENSE_RANK() | 生成分组内的排名,排名相等在名次中不会留下空位 |
SELECT user_id,
course,
score,
ROW_NUMBER() OVER(PARTITION BY course ORDER BY score) as rn,
RANK() OVER(PARTITION BY course ORDER BY score) as rk,
DENSE_RANK() OVER(PARTITION BY course ORDER BY score) as dr
FROM student_score
(2)取值相关计算举例
| 取值相关函数 | 解释 |
|---|---|
| FIRST_VALUE(col) | 取分组内排序后,截止到当前行,第一个col值 |
| LAST_VALUE(col) | 取分组内排序后,截止到当前行,最后一个col值 如果order的值变化了,基本上也就是当前行的值了,如果没有变化就取相同order系列中的最后一项。 由于排序的值可能相同但要取的列值可能不同,所以FIRST/LAST这俩函数的返回值均是不确定的。 |
| LEAD(col,n,DEFAULT) | 用于统计窗口内往下第n行值。 参数1:列名; 参数2:往下第n行(可选,默认为1); 参数3:默认值(当往下第n行为NULL时,取默认值,不指定为NULL) |
| LAG(col,n,DEFAULT) | 与lead相反,用于统计窗口内往上第n行值。 参数1:列名; 参数2:往上第n行(可选,默认为1); 参数3:默认值(当往上第n行为NULL时,取默认值,不指定为NULL) |
SELECT user_id,
course,
score,
ROW_NUMBER() OVER(PARTITION BY course ORDER BY score ASC) AS rn,
FIRST_VALUE(score) OVER(PARTITION BY course ORDER BY score ASC) AS first_scorea,
FIRST_VALUE(score) OVER(PARTITION BY course ORDER BY score DESC) AS first_scored,
FIRST_VALUE(user_id) OVER(PARTITION BY course ORDER BY score ASC) AS first_usera,
FIRST_VALUE(user_id) OVER(PARTITION BY course ORDER BY score DESC, user_id ASC) AS first_userda,
LAST_VALUE(score) OVER(PARTITION BY course ORDER BY score) AS last_scorea,
LAST_VALUE(user_id) OVER(PARTITION BY course ORDER BY score ASC,user_id ASC RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS last_user_upcr,
LAST_VALUE(user_id) OVER(PARTITION BY course ORDER BY score ASC,user_id ASC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_user_upuf,
LAG(score,1,0) OVER(PARTITION BY course ORDER BY score) AS lag_1_0
FROM student_score
ORDER BY course,
rn
(2)计算相关窗口函数举例
上面例子中over从句,在这里我们统一说一下相关语法
OVER从句
1、使用标准的聚合函数COUNT、SUM、MIN、MAX、AVG
2、使用PARTITION BY语句,使用一个或者多个原始数据类型的列
3、使用PARTITION BY与ORDER BY语句,使用一个或者多个数据类型的分区或者排序列
4、使用窗口规范,窗口规范支持以下格式:
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING注意点:(1)理解ROWS BETWEEN含义,也叫做WINDOW子句:
PRECEDING:往前,FOLLOWING:往后,CURRENT ROW:当前行,UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点;
(2)[ORDER BY后]缺失和[ORDER BY+窗口从句]都缺失区别:
当ORDER BY后面缺少窗口从句条件,窗口规范默认是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
当ORDER BY和窗口从句都缺失, 窗口规范默认是 ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
(3)ROWS和RANGE区别:
ROWS是物理窗口,与当前行的值(order by key的key的值)无关,只与排序后的行号相关(对行操作范围,返回对行范围)。
RANGE是逻辑窗口,与当前行的值有关(order by key的key的值),在key上操作range范围(对值操作range范围,返回对应值分为)。
SELECT user_id,
course,
score,
ROW_NUMBER() OVER(PARTITION BY course ORDER BY score ASC) AS rn,
-- 组内score总和
SUM(score) OVER(PARTITION BY course) AS sum_p_score,
-- 截止当前score值和
SUM(score) OVER(PARTITION BY course ORDER BY score ASC) AS sum_po_score,
-- 截止当前score值和,order by后缺失默认如下
SUM(score) OVER(PARTITION BY course ORDER BY score ASC RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS sum_po_range_score,
-- 截止当前行,score值的和
SUM(score) OVER(PARTITION BY course ORDER BY score ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS sum_po_row_score,
-- 往前2行 + 当前行score值的和
SUM(score) OVER(PARTITION BY course ORDER BY score ASC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum_row_p2_score,
-- 分组排序和sum的字段不一样
SUM(user_id) OVER(PARTITION BY course ORDER BY score ASC) AS sum_user
FROM student_score
ORDER BY course,
rn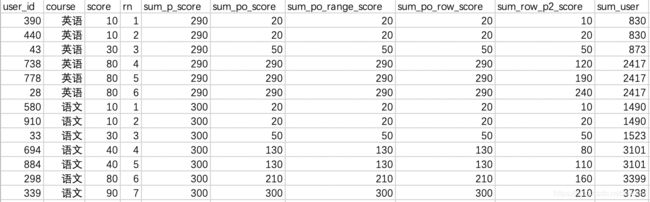
3、行列转化函数
讲完窗口函数之后,我们再介绍行列转化函数,这是行列转化的基本语法。结合这个样例我们一起看一下,列转行,通过我们的语法把tag转成了new_tag,行转列是它的逆向操作,根据group by的key,将new_tag转化为tag_col。
列转行 (对某列拆分,形成新列) :lateral view explode(split(column, ',')) num
行转列(根据主键,对某列进行合并) : concat_ws(',',collect_set(column)) 
3、自定义函数
Hive自带的函数很多,但是也不能满足我们的所有需求,hive为我们提供了UDF,用户自定义函数,我们实现函数后进行注册就可以使用。
(1)如何开发UDF
继承GenericUDF
实现evaluate函数
(2)UDF的原理
临时函数和Hive Session绑定
class_name的查找路径在Hive的classpath
ADD JAR 语句,把jar包增加到classpath中
(3)Hive同样支持UDAF和UDTF
思考UDF、UDAF和UDTF的区别
UDF:用户自定义(普通)函数,只对单行数值产生作用;一进一出。
UDAF:User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数;多进一出。
UDTF:User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行;一进多出。
二、Hive原理篇
下面主要介绍hive原理,首先是编译、执行过程,也就是sql转化为MapReduce job的过程和MR任务执行流程;其次介绍job调度(一般采用yarn做资源管理器);再介绍MapReduce原理;最后介绍一些核心算子的执行原理。
2.1 hive编译和执行
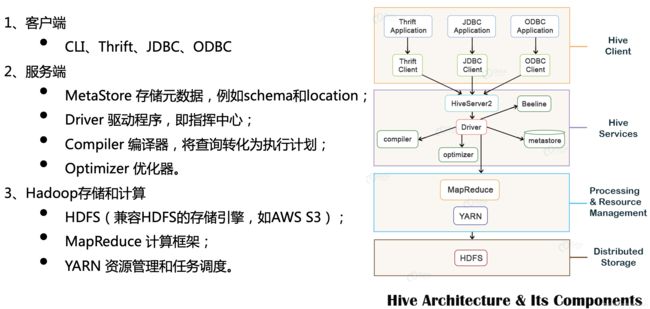
2.1.1 hive系统架构
hive的架构和编译原理,这是hive的整体架构。分成三部分,首先是客户端,我们可以通过hive client、jdbc或者odbc,连接到我们的服务端hiveserver2,driver驱动程序会接收SQL,通过编译器和优化器编译优化,这个过程会访问元数据,最后生成job,通过yarn调度,在Hadoop集群执行,最后把结果保存到HDFS上。
2.1.2 hive编译过程

2.1.3 hive查询执行流程
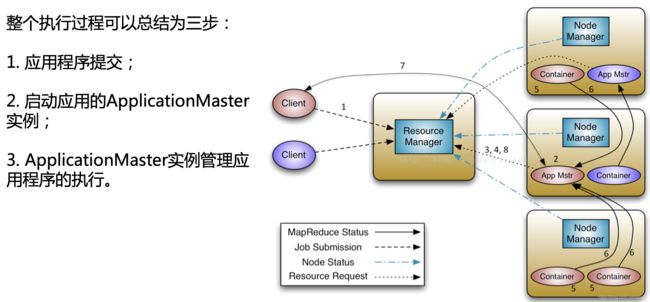
2.2 job调度
Application在Yarn中的执行过程,如需了解详细执行过程请点击:Yarn的执行过程细分
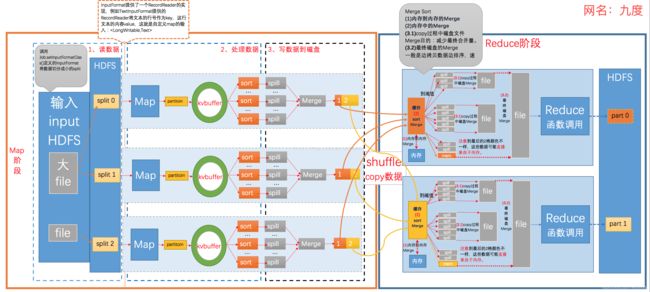
2.3 job执行引擎(MapReduce原理)
MapReduce过程详解及其性能优化
Hadoop作业称为Job,Job分为Map、Shuffle和Reduce阶段,MAP和Reduce的Task都基于JVM进程运行的。
MAP阶段:从HDFS读取数据,split文件产生task,通过对应数量的Map处理,map输出的每一个键值对通过key的hash值计算一个partition,数据通过环形缓冲区,sort、spill、merge生成data和index文件;
Reduce阶段:reduce通过Shuffle Copy属于自己的那部分数据,然后sort、spill、merge形成一个大文件,调用reduce函数进行处理。
2.4 核心算子原理
2.4.1 Hive join原理
join原理--MapJoin
join原理--Reduce Join,又叫Common Join
1. Map阶段:构建(key(tag),value),key这里后面的数字是tag,后面在reduce阶段用来区分来自于那个表的数据,对key求hashcode设为hivekey;
2. Shuffle阶段:如果key在不同机器上,会通过网络传输把hivekey相同的数据汇集到一台机器;
3. Reduce阶段:把tag=1的内容,都加到tag=0的后面,合并输出。

2.4.2 Hive group by原理
默认设置了hive.map.aggr=true,会在mapper端先group by一次,最后把结果merge起来,为了减少reducer处理的数据量。
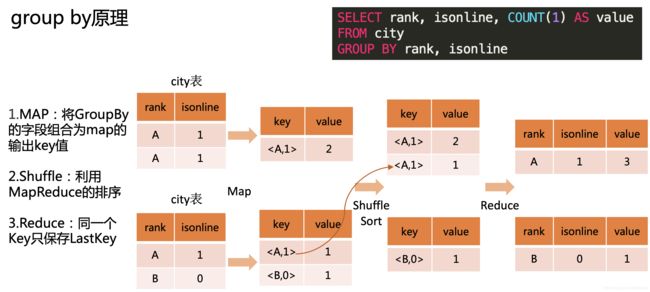
2.4.3 Hive distribute by 原理
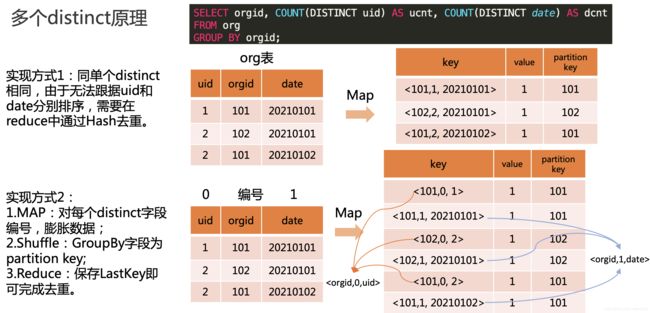
只有一个distinct实现原理如下图:

有多个distinct字段,有两种实现方式,第一种同上,第二种对不同distinct字段编号膨胀,group by字段作为partition key,最后在reduce阶段保存LastKey区分不同的key。
2.4.4 Hive 排序
order by 是全局排序,可能性能会比较差,orderby生成一个reduce,数据量比较大是有性能瓶颈;
sort by分区内有序,往往配合distribute by来确定该分区都有那些数据;
distribute by确定了数据分发的规则,满足相同条件的数据被分发到一个reducer,常用于解决小文件问题;
cluster by当distribute by和sort by字段相同时,可以使用cluster by代替distribute by和sort by,但是cluster by默认是升序,不能指定排序方向。
三、Hive优化篇
为什么要做优化?答:用更少的资源,在相对较短的时间完成。
hive job性能优化流程:
- explain查看执行计划;
- 查看执行日志定位那个stage执行时间太长;
- 查看job日志定位map阶段慢还是reduce阶段慢;
- 分析原因,资源不足、抓取失败、数据倾斜、reduce数量太少等;
- 针对不同的场景解决短板。
3.1 MAP阶段优化
MAP阶段常见问题:启动Mapper数太多,启动等待资源时间太长
什么决定了Mapper数量??(上游小文件太多;split太小,切分的太多。)
(1)输入文件数目
(2)输入文件的大小
(3)配置参数
mapreduce.input.fileinputformat.split.minsize //启动map最小的split size大小
mapreduce.input.fileinputformat.split.maxsize //启动map最大的split size大小
dfs.block.size //block块大小
splitSize = Math.max(minSize, Math.min(maxSize, blockSize));
解决方案:
1、合并小文件
设置合并器:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 执行Map前进行小文件合并
set hive.merge.mapFiles=true;
set hive.merge.mapredFiles=true;
set mapred.min.split.size.per.node=100000000; -- 一个节点上split的至少的大小 ,决定了多个data node上的文件是否需要合并
set mapred.min.split.size.per.rack=100000000; -- 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并
2、设置合理的切分大小
set mapred.max.split.size=256000000 // mapred切分的大小
set mapred.min.split.size=2560000003.2 Shuffle阶段优化
Shuffle是通过网络传输数据的
优化点:
(1)减少传输数据量:过滤异常数据或只选取需要的列(列裁剪)。
(2)广播小表,实现Map join。
试用场景,大表和小表join
hive.auto.convert.join=true;//设置自动选择Mapjoin( 默认为true)
set hive.mapjoin.smalltable.filesize=25000000;//mapjoin阈值设置(默认25M一下认为是小表)
3.3 Reduce阶段优化
数据倾斜:Key的分布不均匀,大量数据被分配到了个别Reduce上处理。
解决方案:
1、MapJoin,大表和小表join,广播小表。
2、参数调优
3、把key打散
(1)加随机数膨胀
(2)倾斜key单独处理