【spark2】【源码学习】【分区数】spark读取 本地/可分割/单个 的文件时是如何划分分区
大数据计算中很关键的一个概念就是分布式并行计算,意思就是将一份原始数据切分成若干份,然后分发到多个机器或者单个机器多个虚拟出来的内存容器中同时执行相同的逻辑,先分发(map),然后聚合(reduce)的一个过程。
那么问题是原始文件是怎么切分的呢,在spark读取不同的数据源,切分的逻辑也是不同的。
首先spark是有改变分区的函数的,分别是Coalesce()方法和rePartition()方法,但是这两个方法只对shuffle过程生效,包括参数spark.default.parallelism也只是对shuffle有效,所以spark读取数据的时候分区数是没有固定的一个参数来设定的,会经过比较复杂的逻辑计算得到的。
这次先看下spark读取 【本地】【可分割】【单个】 的文件,注意括起来的词,因为不同的数据源spark的处理是不一样的。
一、spark读取代码
这里直接复用spark源码中的example【JavaWordCount】
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount " );
System.exit(1);
}
SparkSession spark = SparkSession
.builder()
.appName("JavaWordCount")
.getOrCreate();
spark.sparkContext().setLogLevel("WARN");
// JavaRDD lines = spark.read().textFile(args[0]).javaRDD();
JavaRDD<String> lines = spark.sparkContext().textFile(args[0], 2).toJavaRDD();
System.out.println("lines.getNumPartitions(): " + lines.getNumPartitions());
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
List<Tuple2<String, Integer>> output = counts.collect();
// for (Tuple2 tuple : output) {
// System.out.println(tuple._1() + ": " + tuple._2());
// }
spark.stop();
}
}
二、textFile()方法
spark 提供的读取文件api,发现textFile最后是new一个HadoopRDD返回的。
testFile的两个参数:
path:就是读取文件的路径,可以是精确文件名,也可以是一个目录名
minPartitions: 最小分区数,这个不是确定的最后分区数,这个参数在后面计算分区数时用到。
# SparkContext.scala
/**
* Read a text file from HDFS, a local file system (available on all nodes), or any
* Hadoop-supported file system URI, and return it as an RDD of Strings.
* @param path path to the text file on a supported file system
* @param minPartitions suggested minimum number of partitions for the resulting RDD
* @return RDD of lines of the text file
*/
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
print("\n>>>>>> pgx code <<<<<<\n")
print("defaultParallelism: " + defaultMinPartitions)
print("\n")
print("minPartitions: " + minPartitions)
print("\n>>>>>> pgx code <<<<<<\n")
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
/** Get an RDD for a Hadoop file with an arbitrary InputFormat
*
* @note Because Hadoop's RecordReader class re-uses the same Writable object for each
* record, directly caching the returned RDD or directly passing it to an aggregation or shuffle
* operation will create many references to the same object.
* If you plan to directly cache, sort, or aggregate Hadoop writable objects, you should first
* copy them using a `map` function.
* @param path directory to the input data files, the path can be comma separated paths
* as a list of inputs
* @param inputFormatClass storage format of the data to be read
* @param keyClass `Class` of the key associated with the `inputFormatClass` parameter
* @param valueClass `Class` of the value associated with the `inputFormatClass` parameter
* @param minPartitions suggested minimum number of partitions for the resulting RDD
* @return RDD of tuples of key and corresponding value
*/
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {
assertNotStopped()
// This is a hack to enforce loading hdfs-site.xml.
// See SPARK-11227 for details.
FileSystem.getLocal(hadoopConfiguration)
// A Hadoop configuration can be about 10 KB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobConf, path)
new HadoopRDD(
this,
confBroadcast,
Some(setInputPathsFunc),
inputFormatClass,
keyClass,
valueClass,
minPartitions).setName(path)
}
三、从action追踪代码
因为spark的transform算子不会引发计算,所以我们直接tracked down 最后引发计算的action 算子 collect()
# JavaRDDlike.scala
/**
* Return an array that contains all of the elements in this RDD.
*
* @note this method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*/
def collect(): JList[T] =
rdd.collect().toSeq.asJava
collect()方法是调用了SparkContext对象的runJob方法
# RDD.scala
/**
* Return an array that contains all of the elements in this RDD.
*
* @note This method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
SparkContext对象中的runJob的方法调用自身另外一个runJob方法,开始执行任务
我们主要关注分区数,所以继续追踪runJonb的第三个参数 【0 until rdd.partitions.length】
# SparkContext.scala
/**
* Run a job on all partitions in an RDD and return the results in an array.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @return in-memory collection with a result of the job (each collection element will contain
* a result from one partition)
*/
def runJob[T, U: ClassTag](rdd: RDD[T], func: Iterator[T] => U): Array[U] = {
runJob(rdd, func, 0 until rdd.partitions.length)
}
SparkContext对象执行runJob时,需要从rdd对象中拿partitions (0 until rdd.partitions.length)
rdd对象中的partitions方法调用了 getPartitions来获取分区数
// RDD.scala
/**
* Get the array of partitions of this RDD, taking into account whether the
* RDD is checkpointed or not.
*/
final def partitions: Array[Partition] = {
checkpointRDD.map(_.partitions).getOrElse {
if (partitions_ == null) {
stateLock.synchronized {
if (partitions_ == null) {
partitions_ = getPartitions
partitions_.zipWithIndex.foreach { case (partition, index) =>
require(partition.index == index,
s"partitions($index).partition == ${partition.index}, but it should equal $index")
}
}
}
}
partitions_
}
}
这个 getPartitions方法有多个实现类, 因为前面看到textFile最终创建的是一个HadoopRDD,所以这里看的是HadoopRDD.scala中的getPartitions()
我们可以看到getPartitions()方法中,返回的数组是有inputSplits决定
inputSplits 又是来自allInputSplits
所以val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)这行代码是计算分区数的关键代码
minPartitions就是我们在调用textFile()方法时传入的第二个参数。
// HadoopRDD.scala
// getPartitions的实现类
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
// add the credentials here as this can be called before SparkContext initialized
SparkHadoopUtil.get.addCredentials(jobConf)
try {
val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)
print("\n>>>>>> pgx code <<<<<<\n")
print("allInputSplits.size: " + allInputSplits.size)
print("\n")
print("minPartitions: " + minPartitions)
print("\n>>>>>> pgx code <<<<<<\n")
val inputSplits = if (ignoreEmptySplits) {
allInputSplits.filter(_.getLength > 0)
} else {
allInputSplits
}
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) {
array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
} catch {
case e: InvalidInputException if ignoreMissingFiles =>
logWarning(s"${jobConf.get(FileInputFormat.INPUT_DIR)} doesn't exist and no" +
s" partitions returned from this path.", e)
Array.empty[Partition]
}
}
上面说到val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)是计算分区数的关键代码,所以我们这里就跳转到getSplits(jobConf, minPartitions)来看下这个方法里面做的事情
这是一个接口,有很多个实现类,单纯看的话可能不知道选用哪个实现类。
我是通过debug的方式跟着走,发现这里的实现类是FileInputFormat.java。
// InputFormat.java
/**
* Logically split the set of input files for the job.
*
* Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.
*
* Note: The split is a logical split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <input-file-path, start, offset> tuple.
*
* @param job job configuration.
* @param numSplits the desired number of splits, a hint.
* @return an array of {@link InputSplit}s for the job.
*/
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
这里就跳转到上面说的getSplits()接口的实现类FileInputFormat.java
在这个实现类里面,就做了很多事情了, 基本上可以看出spark在读取本地可分割文件的时候切分的分区大小是怎么算出来的
long splitSize = computeSplitSize(goalSize, minSize, blockSize);这里就是用三个size来算出用哪个作为分块大小的。
其中
goalSize:【所有要读取文件大小】/【numSplits】 这个是可知的
numSplits:是textFile()第二个参数传进来的minPartition
minSize:mapreduce.input.fileinputformat.split.minsize这个参数设置,默认是1 这个是可知的
blockSize: 这个对本地文件,hdfs文件都不同的,本地文件默认是32M,下面代码说到。 这个这是要走一遍复杂逻辑计算出来的
// FileInputFormat.java
// InputSplit的实现类
/** Splits files returned by {@link #listStatus(JobConf)} when
* they're too big.*/
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
Stopwatch sw = new Stopwatch().start();
FileStatus[] files = listStatus(job);
// Save the number of input files for metrics/loadgen
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits.toArray(new FileSplit[splits.size()]);
}
这个方法就是上面调用来计算出splitSize的方法。
接收3个参数,分别是3个不同的分块大小
1、先比较 goalSize和blockSize,取小的那个
2、在将step1中的和minSize比较,取大的那个总结:
1、因为minSize值为1,所以几乎不考虑,除非设置了参数 【mapreduce.input.fileinputformat.split.minsize】
2、那么其实就是比较goalSize和blockSize,取小的那个作为splitSizeps.
blockSize的默认值是32M(后面会追踪源码说明32M怎么来的)
goalSize呢,则是用读取文件总大小/我们调用textFile时设置的minPartitions
重点,也就是说
如果我们设置的minPartitions,goalSize小于32M,那么分区数就是我们设置的minPartitions
如果我们设置的minPartitions,goalSize大于32M,那么分区数文件总大小/32
// FileInputFormat.java
// InputSplit的实现类
protected long computeSplitSize(long goalSize, long minSize, long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
上面说到,计算splitSize中的goalSize和minSize都知道了,只有bolckSize还没看出来怎么来的。
通过代码long blockSize = file.getBlockSize();看出blockSize来自于file这个对象,而这个file是来自于files的数组,files又是从FileStatus[] files = listStatus(job);这句代码来的。我们跟着debug进入listStatus()这个方法看下。
关键代码
当数据是一个文件时:ListlocatedFiles = singleThreadedListStatus(job, dirs, inputFilter, recursive);
当数据是多个文件时:LocatedFileStatusFetcher locatedFileStatusFetcher = new LocatedFileStatusFetcher(job, dirs, recursive, inputFilter, false);
后面跳转到 singleThreadedListStatus 这个方法继续看
// mapred/FileInputForm.java
/** List input directories.
* Subclasses may override to, e.g., select only files matching a regular
* expression.
*
* @param job the job to list input paths for
* @return array of FileStatus objects
* @throws IOException if zero items.
*/
protected FileStatus[] listStatus(JobConf job) throws IOException {
Path[] dirs = getInputPaths(job);
if (dirs.length == 0) {
throw new IOException("No input paths specified in job");
}
// get tokens for all the required FileSystems..
TokenCache.obtainTokensForNamenodes(job.getCredentials(), dirs, job);
// Whether we need to recursive look into the directory structure
boolean recursive = job.getBoolean(INPUT_DIR_RECURSIVE, false);
// creates a MultiPathFilter with the hiddenFileFilter and the
// user provided one (if any).
List<PathFilter> filters = new ArrayList<PathFilter>();
filters.add(hiddenFileFilter);
PathFilter jobFilter = getInputPathFilter(job);
if (jobFilter != null) {
filters.add(jobFilter);
}
PathFilter inputFilter = new MultiPathFilter(filters);
FileStatus[] result;
int numThreads = job
.getInt(
org.apache.hadoop.mapreduce.lib.input.FileInputFormat.LIST_STATUS_NUM_THREADS,
org.apache.hadoop.mapreduce.lib.input.FileInputFormat.DEFAULT_LIST_STATUS_NUM_THREADS);
Stopwatch sw = new Stopwatch().start();
if (numThreads == 1) {
List<FileStatus> locatedFiles = singleThreadedListStatus(job, dirs, inputFilter, recursive);
result = locatedFiles.toArray(new FileStatus[locatedFiles.size()]);
} else {
Iterable<FileStatus> locatedFiles = null;
try {
LocatedFileStatusFetcher locatedFileStatusFetcher = new LocatedFileStatusFetcher(
job, dirs, recursive, inputFilter, false);
locatedFiles = locatedFileStatusFetcher.getFileStatuses();
} catch (InterruptedException e) {
throw new IOException("Interrupted while getting file statuses");
}
result = Iterables.toArray(locatedFiles, FileStatus.class);
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Time taken to get FileStatuses: " + sw.elapsedMillis());
}
LOG.info("Total input paths to process : " + result.length);
return result;
}
上面的关键代码跳转到这个方法中继续往下,通过debug看到
FileStatus[] matches = fs.globStatus(p, inputFilter);中返回的maches对象中包含了blockSize,所以继续看fs.globStatus()这个方法
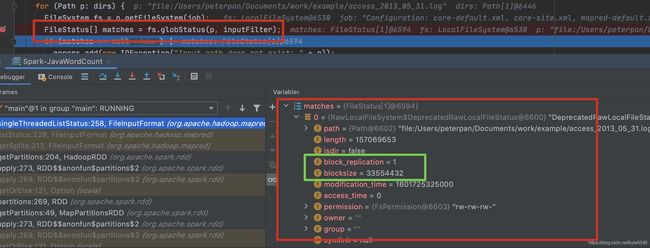
// mapred/FileInputForm.java
private List<FileStatus> singleThreadedListStatus(JobConf job, Path[] dirs,
PathFilter inputFilter, boolean recursive) throws IOException {
List<FileStatus> result = new ArrayList<FileStatus>();
List<IOException> errors = new ArrayList<IOException>();
for (Path p: dirs) {
FileSystem fs = p.getFileSystem(job);
FileStatus[] matches = fs.globStatus(p, inputFilter);
if (matches == null) {
errors.add(new IOException("Input path does not exist: " + p));
} else if (matches.length == 0) {
errors.add(new IOException("Input Pattern " + p + " matches 0 files"));
} else {
for (FileStatus globStat: matches) {
if (globStat.isDirectory()) {
RemoteIterator<LocatedFileStatus> iter =
fs.listLocatedStatus(globStat.getPath());
while (iter.hasNext()) {
LocatedFileStatus stat = iter.next();
if (inputFilter.accept(stat.getPath())) {
if (recursive && stat.isDirectory()) {
addInputPathRecursively(result, fs, stat.getPath(),
inputFilter);
} else {
result.add(stat);
}
}
}
} else {
result.add(globStat);
}
}
}
}
if (!errors.isEmpty()) {
throw new InvalidInputException(errors);
}
return result;
}
从上面的代码跳转到FileSystem.java的globStatus()
这个方法是new了一个Globber对象,并且调用了glob()方法
我们看下glob()这个方法做了什么事情
// FileSystem.java
/**
* Return an array of FileStatus objects whose path names match pathPattern
* and is accepted by the user-supplied path filter. Results are sorted by
* their path names.
* Return null if pathPattern has no glob and the path does not exist.
* Return an empty array if pathPattern has a glob and no path matches it.
*
* @param pathPattern
* a regular expression specifying the path pattern
* @param filter
* a user-supplied path filter
* @return an array of FileStatus objects
* @throws IOException if any I/O error occurs when fetching file status
*/
public FileStatus[] globStatus(Path pathPattern, PathFilter filter)
throws IOException {
return new Globber(this, pathPattern, filter).glob();
}
跳转到Globber.java中的blob(),通过debug,在循环components的时候,到最后的文件层级后,通过FileStatus childStatus = getFileStatus(new Path(candidate.getPath(), component));返回的childStatus带有blockSize信息,所以我们接着跳转到Globber.java中的getFileStatus()继续看
glob返回的是FileStatus[]
这个方法就是在做处理读取文件的事情了
大概做的事情
1、判断schemeString scheme = schemeFromPath(pathPattern);
2、判断权限String authority = authorityFromPath(pathPattern);
3、将路径按层级切分成数组List(原因不明)components = getPathComponents(absPattern.toUri().getPath());
4、区分 window和其他系统的路径,再进行new FileStatusif (Path.WINDOWS && !components.isEmpty()
5、然后循环处理components, 一堆逻辑…
// Globber.java
public FileStatus[] glob() throws IOException {
// First we get the scheme and authority of the pattern that was passed
// in.
String scheme = schemeFromPath(pathPattern);
String authority = authorityFromPath(pathPattern);
// Next we strip off everything except the pathname itself, and expand all
// globs. Expansion is a process which turns "grouping" clauses,
// expressed as brackets, into separate path patterns.
String pathPatternString = pathPattern.toUri().getPath();
List<String> flattenedPatterns = GlobExpander.expand(pathPatternString);
// Now loop over all flattened patterns. In every case, we'll be trying to
// match them to entries in the filesystem.
ArrayList<FileStatus> results =
new ArrayList<FileStatus>(flattenedPatterns.size());
boolean sawWildcard = false;
for (String flatPattern : flattenedPatterns) {
// Get the absolute path for this flattened pattern. We couldn't do
// this prior to flattening because of patterns like {/,a}, where which
// path you go down influences how the path must be made absolute.
Path absPattern = fixRelativePart(new Path(
flatPattern.isEmpty() ? Path.CUR_DIR : flatPattern));
// Now we break the flattened, absolute pattern into path components.
// For example, /a/*/c would be broken into the list [a, *, c]
List<String> components =
getPathComponents(absPattern.toUri().getPath());
// Starting out at the root of the filesystem, we try to match
// filesystem entries against pattern components.
ArrayList<FileStatus> candidates = new ArrayList<FileStatus>(1);
// To get the "real" FileStatus of root, we'd have to do an expensive
// RPC to the NameNode. So we create a placeholder FileStatus which has
// the correct path, but defaults for the rest of the information.
// Later, if it turns out we actually want the FileStatus of root, we'll
// replace the placeholder with a real FileStatus obtained from the
// NameNode.
FileStatus rootPlaceholder;
if (Path.WINDOWS && !components.isEmpty()
&& Path.isWindowsAbsolutePath(absPattern.toUri().getPath(), true)) {
// On Windows the path could begin with a drive letter, e.g. /E:/foo.
// We will skip matching the drive letter and start from listing the
// root of the filesystem on that drive.
String driveLetter = components.remove(0);
rootPlaceholder = new FileStatus(0, true, 0, 0, 0, new Path(scheme,
authority, Path.SEPARATOR + driveLetter + Path.SEPARATOR));
} else {
rootPlaceholder = new FileStatus(0, true, 0, 0, 0,
new Path(scheme, authority, Path.SEPARATOR));
}
candidates.add(rootPlaceholder);
for (int componentIdx = 0; componentIdx < components.size();
componentIdx++) {
ArrayList<FileStatus> newCandidates =
new ArrayList<FileStatus>(candidates.size());
GlobFilter globFilter = new GlobFilter(components.get(componentIdx));
String component = unescapePathComponent(components.get(componentIdx));
if (globFilter.hasPattern()) {
sawWildcard = true;
}
if (candidates.isEmpty() && sawWildcard) {
// Optimization: if there are no more candidates left, stop examining
// the path components. We can only do this if we've already seen
// a wildcard component-- otherwise, we still need to visit all path
// components in case one of them is a wildcard.
break;
}
if ((componentIdx < components.size() - 1) &&
(!globFilter.hasPattern())) {
// Optimization: if this is not the terminal path component, and we
// are not matching against a glob, assume that it exists. If it
// doesn't exist, we'll find out later when resolving a later glob
// or the terminal path component.
for (FileStatus candidate : candidates) {
candidate.setPath(new Path(candidate.getPath(), component));
}
continue;
}
for (FileStatus candidate : candidates) {
if (globFilter.hasPattern()) {
FileStatus[] children = listStatus(candidate.getPath());
if (children.length == 1) {
// If we get back only one result, this could be either a listing
// of a directory with one entry, or it could reflect the fact
// that what we listed resolved to a file.
//
// Unfortunately, we can't just compare the returned paths to
// figure this out. Consider the case where you have /a/b, where
// b is a symlink to "..". In that case, listing /a/b will give
// back "/a/b" again. If we just went by returned pathname, we'd
// incorrectly conclude that /a/b was a file and should not match
// /a/*/*. So we use getFileStatus of the path we just listed to
// disambiguate.
if (!getFileStatus(candidate.getPath()).isDirectory()) {
continue;
}
}
for (FileStatus child : children) {
if (componentIdx < components.size() - 1) {
// Don't try to recurse into non-directories. See HADOOP-10957.
if (!child.isDirectory()) continue;
}
// Set the child path based on the parent path.
child.setPath(new Path(candidate.getPath(),
child.getPath().getName()));
if (globFilter.accept(child.getPath())) {
newCandidates.add(child);
}
}
} else {
// When dealing with non-glob components, use getFileStatus
// instead of listStatus. This is an optimization, but it also
// is necessary for correctness in HDFS, since there are some
// special HDFS directories like .reserved and .snapshot that are
// not visible to listStatus, but which do exist. (See HADOOP-9877)
FileStatus childStatus = getFileStatus(
new Path(candidate.getPath(), component));
if (childStatus != null) {
newCandidates.add(childStatus);
}
}
}
candidates = newCandidates;
}
for (FileStatus status : candidates) {
// Use object equality to see if this status is the root placeholder.
// See the explanation for rootPlaceholder above for more information.
if (status == rootPlaceholder) {
status = getFileStatus(rootPlaceholder.getPath());
if (status == null) continue;
}
// HADOOP-3497 semantics: the user-defined filter is applied at the
// end, once the full path is built up.
if (filter.accept(status.getPath())) {
results.add(status);
}
}
}
/*
* When the input pattern "looks" like just a simple filename, and we
* can't find it, we return null rather than an empty array.
* This is a special case which the shell relies on.
*
* To be more precise: if there were no results, AND there were no
* groupings (aka brackets), and no wildcards in the input (aka stars),
* we return null.
*/
if ((!sawWildcard) && results.isEmpty() &&
(flattenedPatterns.size() <= 1)) {
return null;
}
return results.toArray(new FileStatus[0]);
}
从上面的glob()跳转过来,这个getFileStatus做了个fs的判空,这个fs其实是上面new Globber对象时传的值,所以不会为空。所以继续跳转进去看
return new Globber(this, pathPattern, filter).glob();
// Globber.java
private FileStatus getFileStatus(Path path) throws IOException {
try {
if (fs != null) {
return fs.getFileStatus(path);
} else {
return fc.getFileStatus(path);
}
} catch (FileNotFoundException e) {
return null;
}
}
跳转到FilterFileSystem.java,
public class FilterFileSystem extends FileSystem {}我们看到FilterFileSystem.java 集成了 FileSystem.java
一个不太理解的地方:在FileSystem.java new 的Globber, 参数传递的是this, 到后面调用Globber.java中的fs.getFileStatus,会最终调用了FilterFileSystem的getFileStatus,而不是FileSystem的getFileStatus
return new Globber(this, pathPattern, filter).glob();—FileSystem.java
// FilterFileSystem.java
/**
* Get file status.
*/
@Override
public FileStatus getFileStatus(Path f) throws IOException {
return fs.getFileStatus(f);
}
跳转到RawLocalFileSystem.java
dereference 这个布尔值 在调用方法时就是代码写死时ture的
getFileStatus >> getFileLinkStatusInternal >> deprecatedGetFileStatus
最终我们在deprecatedGetFileStatus()这个方法中找到bolckSize的来源
new DeprecatedRawLocalFileStatus(pathToFile(f),getDefaultBlockSize(f), this);中的getDefaultBlockSize(f)
// RawLocalFileSystem.java
@Override
public FileStatus getFileStatus(Path f) throws IOException {
return getFileLinkStatusInternal(f, true);
}
/**
* Public {@link FileStatus} methods delegate to this function, which in turn
* either call the new {@link Stat} based implementation or the deprecated
* methods based on platform support.
*
* @param f Path to stat
* @param dereference whether to dereference the final path component if a
* symlink
* @return FileStatus of f
* @throws IOException
*/
private FileStatus getFileLinkStatusInternal(final Path f,
boolean dereference) throws IOException {
if (!useDeprecatedFileStatus) {
return getNativeFileLinkStatus(f, dereference);
} else if (dereference) {
return deprecatedGetFileStatus(f);
} else {
return deprecatedGetFileLinkStatusInternal(f);
}
}
@Deprecated
private FileStatus deprecatedGetFileStatus(Path f) throws IOException {
File path = pathToFile(f);
if (path.exists()) {
return new DeprecatedRawLocalFileStatus(pathToFile(f),
getDefaultBlockSize(f), this);
} else {
throw new FileNotFoundException("File " + f + " does not exist");
}
}
跳转到FileSystem.java的getDefaultBlockSize()
这里! 终于看到了默认值32M的设置
/** Return the number of bytes that large input files should be optimally
* be split into to minimize i/o time. The given path will be used to
* locate the actual filesystem. The full path does not have to exist.
* @param f path of file
* @return the default block size for the path's filesystem
*/
public long getDefaultBlockSize(Path f) {
return getDefaultBlockSize();
}
/**
* Return the number of bytes that large input files should be optimally
* be split into to minimize i/o time.
* @deprecated use {@link #getDefaultBlockSize(Path)} instead
*/
@Deprecated
public long getDefaultBlockSize() {
// default to 32MB: large enough to minimize the impact of seeks
return getConf().getLong("fs.local.block.size", 32 * 1024 * 1024);
}
跳转到Configuration.java的getLong()
这个方法是用来获取配置参数的,
传入一个参数的key,和一个默认值,如果拿到参数key配置有值,那么返回这个参数值,否则返回默认值
上面的调用getConf().getLong("fs.local.block.size", 32 * 1024 * 1024);
也就是如果配置了【fs.local.block.size】这用这个值,没有配置则默认32M
/**
* Get the value of the name property as a long.
* If no such property exists, the provided default value is returned,
* or if the specified value is not a valid long,
* then an error is thrown.
*
* @param name property name.
* @param defaultValue default value.
* @throws NumberFormatException when the value is invalid
* @return property value as a long,
* or defaultValue.
*/
public long getLong(String name, long defaultValue) {
String valueString = getTrimmed(name);
if (valueString == null)
return defaultValue;
String hexString = getHexDigits(valueString);
if (hexString != null) {
return Long.parseLong(hexString, 16);
}
return Long.parseLong(valueString);
}
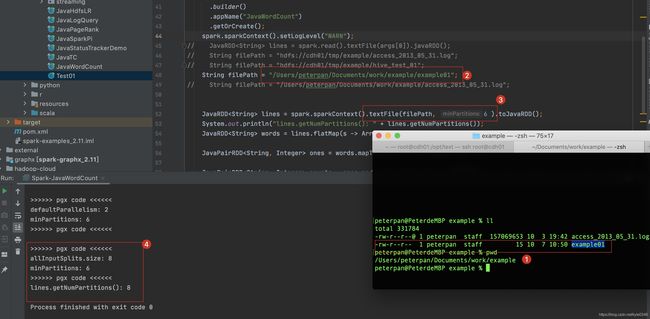
注意:本文仅针对数据源是【本地】【可分割】【单个】文件
四、总结
如果我们设置的minPartitions,goalSize小于32M,那么分区数就是我们设置的minPartitions (这个结论不严谨,参考文末后记)
如果我们设置的minPartitions,goalSize大于32M,那么分区数文件总大小/32
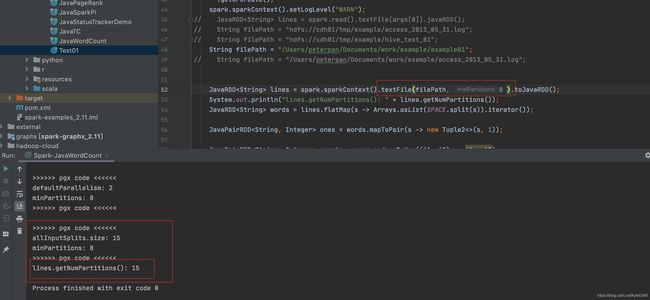
五、测试样例
测试样例
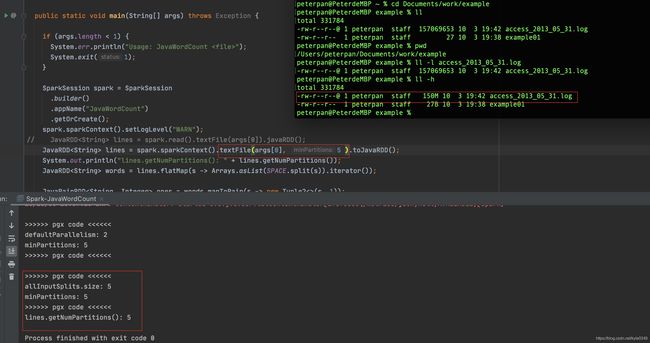
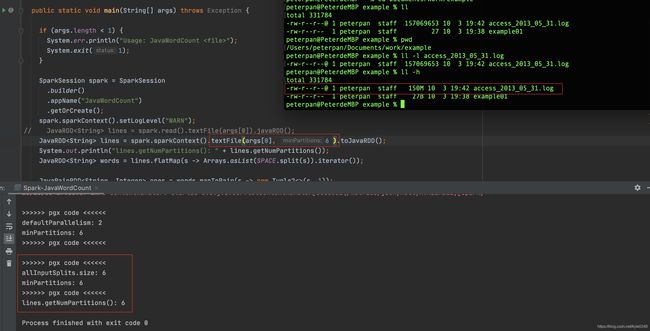
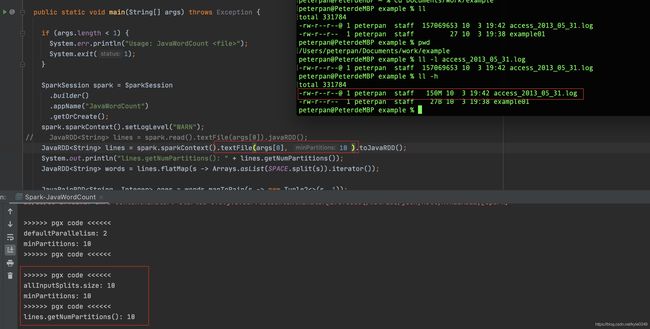
文件是150M的文件
minpartitions=4时 150/4=37.5M, 所以采用blockSize=32M来做分区吗则150M/32M=4.6,所以最后是5个分区
minpartitions=5时 就没啥区别了
minpartitions=6时 150/6=25M,所以最后分区数是6
minpartitions=10时 150/10=15M,所以最后分区数是10
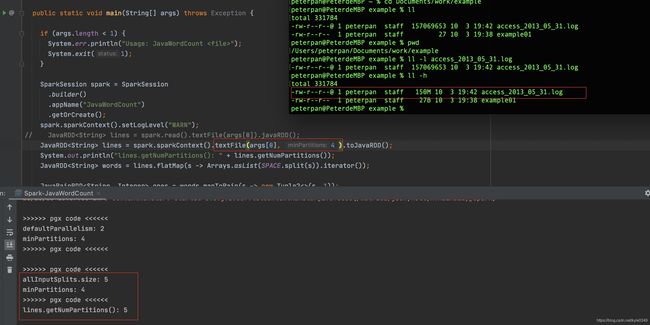
后记
偶然遇到这样一种情况,读取一个15byte大小的文件, minPartitions设置为6,最后的返回的rdd分区数是8。
后来发现原因是long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
这行代码除出来得到小数的情况是直接向下取整,也就是直接去除小数位保留整数。
这就好解释了, 15/6=2.5 向下取整即2,也就是goalSize=2远小于32M,并>1,所以splitSize=2
然后计算分区数: 15/2=7.5, 这里是向上取整 即8。所以最后得到的分区数是8
=====
再用minParttions=8测试一下,因为15/8=1.875,所以预计分区数是15/1=15。结果验证前面推测是对的