数据访问层组件设计以及选型意识流 第二次封装以及各种牢骚
我们的组件已经相对可用了,可我们的用户是挑剔的,有的用户提出了三个要求:
1. 加入分布式事务的支持
2. 我不想写任何SQL,我就是想做一些简单的单表数据库操作,能不能自动生成SQL语句?
3. 我想要像EF或者NH那样的父对象的SAVE调用会把子对象都SAVE的功能,我称为级联SQL操作。
我们本次的封装将实现这些需求。
首先分析一下,
实现第一个需求,我不想动原来的任何方法的接口,因此我想到了线程本地存储的概念。
另外,分布式事务,我这里单指数据库分布式事务,就是说,一个事务里访问了 A数据库,也访问了B数据库,分布式事务维持一个本地事务的列表,当所有本地事务都符合提交条件时,才提交分布式事务。
因此,我写了一个TransactionScope类,这个应该和EF里的做法类似。代码如下:
using System.Collections.Generic;
using System.Data;
using System.Linq;
using System.Runtime.Remoting.Messaging;
namespace DianPing.BA.Framework.DAL
{
public class TransactionScope :IDisposable
{
public IEnumerable<IDbTransaction> Transactions { get; set; }
public TransactionScope()
{
Transactions = new List<IDbTransaction>();
CallContext.SetData( " TransactionScope ", this);
}
public void RollBack()
{
try
{
foreach ( var tran in Transactions.Reverse())
{
if (tran.Connection.State != ConnectionState.Closed)
{
tran.Rollback();
tran.Connection.Close();
tran.Connection.Dispose();
tran.Dispose();
}
}
}
catch
{
// TODO: 记个日志啥的
}
Transactions = new List<IDbTransaction>();
}
public void Comit()
{
try
{
foreach ( var tran in Transactions)
{
if (tran.Connection.State != ConnectionState.Closed)
{
tran.Commit();
tran.Connection.Close();
tran.Connection.Dispose();
tran.Dispose();
} }
}
catch
{
// TODO: 记个日志啥的
}
Transactions = new List<IDbTransaction>();
}
public void Dispose()
{
try
{
foreach ( var tran in Transactions)
{
if (tran.Connection.State != ConnectionState.Closed)
{
tran.Rollback();
tran.Connection.Close();
tran.Connection.Dispose();
tran.Dispose();
}
}
}
catch
{
// TODO: 记个日志啥的
}
Transactions = new List<IDbTransaction>();
CallContext.FreeNamedDataSlot( " TransactionScope ");
}
}
}
使用时只需要:
{
try{
// 数据库操作
}
catch (Exception e)
{
// TODO: 记了条日志
transactionScope.RollBack();
}
}
实现第二个需求:
自动生成简单SQL语句而已,有何难?
哥马上创建了一个DACBase<T> 类,简单的查询你就不要创建自己的DAC类了,直接用它吧:

好了,第二个需求搞定,现在来看看第三个需求,我一直觉得实体对象中应该是贫血的,不应该有操作,最好不要有级联数据操作。
比如说,所谓的级联Select,就是这样的吧:
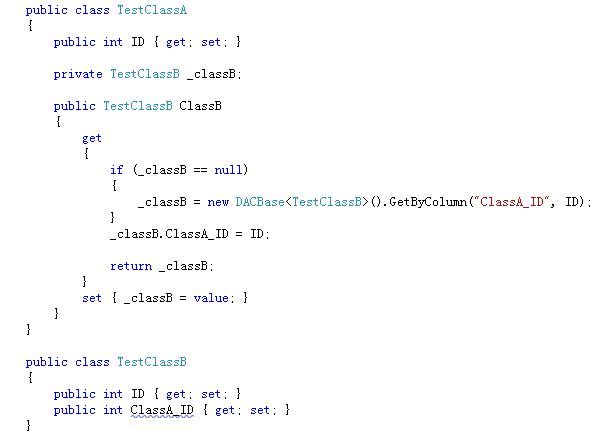
TestClassA的ClassB属性存的不是ClassB的主键,而是直接存的实体,然后在属性的GET方法中做了手脚。这就是级联SELECT.
那么级联Insert和Update呢?
请看DACBase<T> 的InsertCascade和UpdateCascade方法。

我还创建了 DACBaseObject类来辅助。
{
private static readonly DACBase< object> DACBase = new DACBase< object>();
public static int Insert( object record)
{
return DACBase.InsertCascade(record);
}
public static void Update( object record)
{
DACBase.UpdateCascade(record);
}
}
也许,我们已经超越了IBitas和DAAB很多了,可是我们的用户永远都是得寸进寸的。
现在用户又提出了更高的要求:
我完全不像写SQL语句,我就想操作数据库就想操作内存数据一样,不关心数据库,只关心业务。
这,不是把我们的组件往重量级OR Mapping的方向逼吗?
我一直以为,重量级OR Mapping与轻量级的区别是:有没有实现数据库表间关系的Mapping.
要实现这个,很复杂,具体一点,自动生成多表查询的语句,很复杂!你想想,你依据什么生成这种语句啊,还不是表与表、实体对象与实体对象间的一对多、多对多的关系?
NH实现了这个,但它很多方面都被诟病,在乎性能和灵活性的开发团队是不用它的,这就是为什么IBITAS现在在JAVA阵营使用量越来越高的原因。
EF也实现了这个,而且有两种方式:
一种还是配置,只不过它的配置不全是在文件里,而还有给实体加一些丑陋的Attribute,另外读取Attribute信息耗资源的。
另一种是CODE FIRST,直接先写代码,然后生成服务代码要求的数据库 ,这明显只适用于完全从0开始的项目。
EF还有一个弱点是:它生成语句完全和LINQ TO SQL类似,都是基于LAMADA表达式树的解析,关于表达式树,具体请参看
表达式树解析对大部分开发者而言是个黑盒子,虽然源代码据说也公开了,但是没几个人真去读它,或者说读得懂它,对于很多像我这样的"打破沙锅问到底"的开发人员,直接放弃。
(PS: 我真的是这种人,我08年曾把ASP.NET MVC当时版本的源代码全部看完了才认可它的,不相信的去看我08年关于MVC的博文)
依据表达式树生成SQL语句的一个大问题是扩展问题,比如 我要用EF访问PostgreSQL的数据库,我怎么办?我并不知道,但是直觉告诉我,要修改表达式树生成SQL的逻辑了,直接杯具了吧!!!!
这是EF的致命弱点。
PS: 查了一下, EF貌似也是支持 PostgreSQL, http://stackoverflow.com/questions/1211475/entity-framework-postgresql 具体怎么样支持我就真不知道了,这个链接只是把读者引向
另外,把数据库关系Mapping管理起来,势必会带来复杂性,就算你做得再好,也只是说你处理方式好,并不是你的复杂性就不在了。
复杂性带来的问题是
说了这么多重量级OR Mapping的不好,我的目的只有一个,就是说服老板放弃使用重量级的OR Mapping工具,其实也很简单,你去查查有多少公司和团队在寻求轻量级的数据访问解决方案。有多少公司正在或者已经在放弃使用Hibernate而转向IBITAS或者其他的组件。再查查有多少大型的公司在用EF. 查查哪些团队的血泪史吧。
在查查在博客园中有多少大牛在说着LINQ TO SQL已死,ObjectSpace已死(EF前称),为什么?
还有就是微软企业库里为什么DAAB没有变成EF? 你可以说 微软企业库 是鸡肋,对, 我承认,可是,既然 微软企业库 是鸡肋, EF是好东西,那么微软为什么不把DAAB换成 EF从而让企业库不那么鸡肋呢??
原因只有一个: 他们不敢!多少人对EF这个东西 没有信任的,微软自己都不信任!
结论是:如果 微软企业库 是鸡肋,那么EF其实更鸡肋,出来也好几年了,离死不远了,等着瞧吧。
其实有时候自私的认为,EF我也能用,我干嘛引火上身要推荐自己的组件?到时候还有费时费力做技术支持。对自己没半点好处啊。
等到团队对EF有怨言或者 EF不能做某些事 的时候再 推出自己的东西来收拾残局最符合个人的利益。 好吧,老衲很傻。
我放弃争论是因为我不善于“舌战群儒”, 在争论的时候我的思路是混乱的,上次有人说微软企业库 是鸡肋,我居然无言以对。。。
其实归根结底,微软最错误的做法是: 它总是擅自为用户做决定,总是把用户当傻瓜,推出傻瓜式的产品,总认为你不需要了解得更深。
两大开发阵营摸爬滚打N年加比较就得出以上的结论。我想如果我是与一些JAVA阵营的团队去说EF,EF早就被枪毙了!
这里将一个刚刚发生的事:
我们公司最近组织了一次名叫Hackson的24小时极限编程竞赛,9个团队参加,我所在的团队应该本事最不被看好的。拿大家的话说,是被挑剩下的人。
我被挑剩下是因为之前我一心扑在某个基础组件的开发上,前期对该活动不闻不问,所以没人选。
我们选用的主题大概就是为销售人员提供一个最有价值的小工具, 拿到一些商业分析的结果去和客户谈生意,既然是商业分析,那么就离不开BI数据,这可是个难点。这个数据只有一个Provider, 没有基础组件的支持。
我们的结果很有意思,
多个团队自己杜撰数据(或者让销售录入数据,复杂的录入界面啊,想让销售做录入员),
多个团队直接用一个作业用那个Provider抓取数据,存放在自己的SQL SERVER数据库中(那是数据仓库海量数据啊,你居然拷贝一份?如果你不完全拷贝一份,你的数据就是不完整的)
他们为什么这么做?我认为他们用EF的是不想让人看到他们居然直接用了BI数据的Provider(我们的比赛也看代码质量的)
只有一个团队在用真实完整的数据说话(这个团队也许也是公认配合最好的团队,更是唯一一个超额提前完成任务的,完成了原计划两倍以上的任务),那就是我所在的团队 ,我花了半个小时就把那个BI数据的Provider封装在我们的数据访问组件里,完全没改任何一行现有代码,只是加了一个实现。(开闭原则)
有几个团队想把大家的目光引到花哨的界面上来,引到团队合作精神(感到啊)上来 ,但是,怎么能掩盖他们的数据是不完整的这个致命伤呢?数据不真实完整,真个程序的价值是不是就等于0?
让销售录入大量信息,可能吧,好吧,如果我是一个销售,我肯定是个懒销售!
回过头来,我在想怎么绕过数据关系Mapping, 又支持不写任何SQL语句就能做开发。
这就引入了下一篇的主题了,敬请期待。
PS:
一,也许我错了,让销售录入信息可能是只有我这样的懒销售才感到头痛,大部分销售是不会头痛的,他们可以一边谈客户一边录入,可以在家打开笔记本录入~~