学习笔记七:transformer总结(1)
文章目录
-
- 一、attention
-
- 1.1循环神经网络的不足:
- 1.2 attention在机器翻译的优点
- 1.3 self Attention和循环神经网络对比
- 1.4为什么求内积之后除以 d \sqrt{d} d
- 1.5 slef-attention过程
- 1.6 多头注意力可视化
- 二、transformers
-
- 2.1 自注意力模型的缺点及transformer的提出
- 2.2 模型具体结构
-
- 2.2.1 Encoder Layer
- 2.2.2 Transformer layer组成Encoder
- 2.2.3 TransformerDecoderLayer
- 2.2.4 TransformerDecoderLayer组成Decoder
- 2.2.5 Transformer
- 3.2 模型输出流程
- 3.3 灾难性遗忘
一、attention
1.1循环神经网络的不足:
- 长距离衰减问题
- 解码阶段,越靠后的内容,翻译效果越差
- 解码阶段缺乏对编码阶段各个词的直接利用
1.2 attention在机器翻译的优点
- 使用全部token信息而非最后时刻的context信息。由此在解码时每时刻可以计算attention权重,让输出对输入进行聚焦的能力,找到此时刻解码时最该注意的词。
- attention的计算是序列各tokens的v向量和attention权重加权求和,每个词关注到所有词,一步到位,不存在长距离衰减
- 可以关注到不同位置的词语,而且使用多头和多层注意力、加入FFNN,表达能力更强。
1.3 self Attention和循环神经网络对比
LSTM:非词袋模型,含有顺序信息,无法解决长距离依赖,无法并行,没有注意力机制
Self Attention:词袋模型,不含位置信息,没有长距离依赖,可以并行,有注意力机制。
1.4为什么求内积之后除以 d \sqrt{d} d
上面计算相似度s=
对于两个d维向量q,k,假设它们都采样自“均值为0、方差为1”的分布。Attention是内积后softmax,主要设计的运算是 e q ⋅ k e^{q⋅k} eq⋅k,我们可以大致认为内积之后、softmax之前的数值在 − 3 d -3\sqrt{d} −3d到 3 d 3\sqrt{d} 3d这个范围内,由于d通常都至少是64,所以 e 3 d e^{3\sqrt{d}} e3d比较大而 e − 3 d e^{-3\sqrt{d}} e−3d比较小,softmax函数进入饱和区。这样会有两个影响:
- 带来严重的梯度消失问题,导致训练效果差。
- softmax之后,归一化后计算出来的结果a要么趋近于1要么趋近于0,Attention的分布非常接近一个one hot分布了,加权求和退化成胜者全拿,则解码时只关注注意力最高的(attention模型还是希望别的词也有权重)
相应地,解决方法就有两个:(参考苏剑林《浅谈Transformer的初始化、参数化与标准化》)
- 像NTK参数化那样,在内积之后除以 d \sqrt{d} d,使q⋅k的方差变为1,对应 e 3 e^3 e3, e − 3 e^{−3} e−3都不至于过大过小,这也是常规的Transformer如BERT里边的Self Attention的做法。对公式s=
s = < q , k > d k e y s=\frac{ - 另外就是不除以 d \sqrt{d} d,但是初始化q,k的全连接层的时候,其初始化方差要多除以一个d,这同样能使得使q⋅k的初始方差变为1,T5采用了这样的做法。
1.5 slef-attention过程
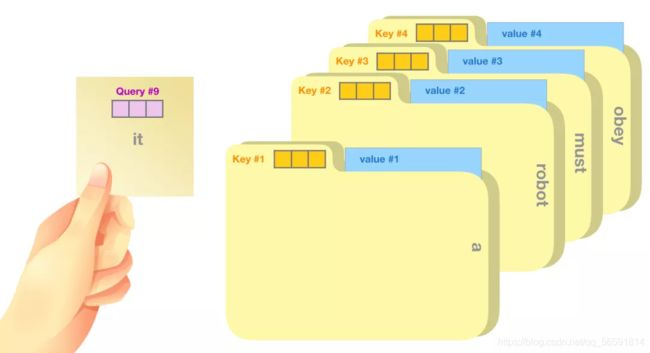
一个粗略的类比是把它看作是在一个文件柜里面搜索
| 向量 | 含义 |
|---|---|
| Query | 一个便签,上面写着你正在研究的主题 |
| Key | 柜子里的文件夹的标签 |
| Value | 文件夹里面的内容 |
首先将主题便签与标签匹配,会为每个文件夹产生一个分数(attention score)。然后取出匹配的那些文件夹里面的内容 Value 向量。最后我们将每个 Value 向量和分数加权求和,就得到 Self Attention 的输出。
1.6 多头注意力可视化
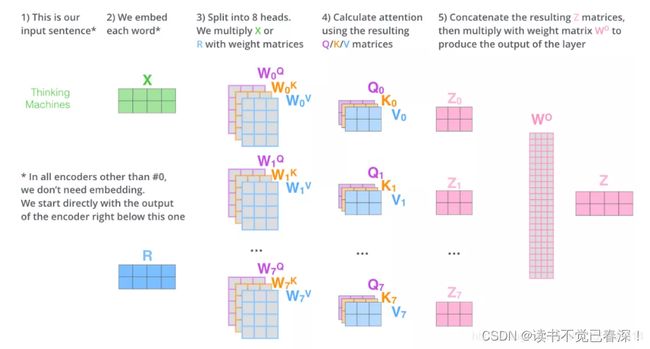
下面以head=8举例说明如下:
- 输入 X 和8组权重矩阵 W Q W^Q WQ, W K W^K WK W V W^V WV相乘,得到 8 组 Q, K, V 矩阵。进行attention计算,得到 8 组 Z 矩阵(特就是head)
- 把8组矩阵拼接起来,乘以权重矩阵 W O W^O WO,得到最终的矩阵 Z。这个矩阵包含了所有 attention heads(注意力头) 的信息。
- 矩阵Z会输入到 FFNN (Feed orward Neural Network)层。(前馈神经网络层接收的也是 1 个矩阵,而不是8个。其中每行的向量表示一个词)
多头注意力结果串联在一起维度可能比较高,所以通过 W O W^{O} WO进行一次线性变换,实现降维和各头信息融合的目的,得到最终结果。
在前面的讲解中,我们的 K、Q、V 矩阵的序列长度都是一样的。但是在实际中,K、V 矩阵的序列长度是一样的(加权求和),而 Q 矩阵的序列长度可以不一样。
这种情况发生在:在解码器部分的Encoder-Decoder Attention层中,Q 矩阵是来自解码器下层,而 K、V 矩阵则是来自编码器的输出。
二、transformers
2.1 自注意力模型的缺点及transformer的提出
自注意力模型有如下问题:.
- 在计算自注意力时,没有考虑输入的位置信息,因此无法对序列进行建模;.
- 输入向量 T ,同时承担了Q、K、V三种角色,导致其不容易学习;
- 只考虑了两个输入序列单元之间的关系,无法建模多个输入序列单元之间更复杂的关系;
- 自注意力计算结果互斥,无法同时关注多个输入
解决如下:
- 加入位置编码信息,具体使用sin/cos函数,将一个位置索引值映射到一个 d 维向量上。尝试用位置嵌入(可学习的Position Embeddings(cite))来代替固定的位置编码,结果发现两种方法产生了几乎相同的效果。于是我们选择了正弦版本,因为它可以使模型外推到,比训练集序列更长的序列。
- 输入X经过三个不同参数矩阵映射为不同的向量矩阵QKV(线性变换)
- 多层自注意力,建模多个输入序列不同单元的高阶信息。加入FFNN层通过非线性变换、前后两个linear层增强语义信息。通过残差连接和norm,使模型学习的更快。残差连接解决深层网络退化问题,norm使训练数据分布更加稳定,增强网络稳定性,加快收敛速度;使异常值不那么异常,减少过拟合。
- 多头自注意力:学习不同语义空间下的语义信息,表达能力更强,,可以进行多语义匹配,也相当于多个卷积核提取不同类型的特征。解决注意力互斥问题。
2.2 模型具体结构
可以看出每一层都是计算之后(attention计算或者linear计算)dropout,再Add,再Norm。唯一不同是FFNN层第一层linear计算后激活,再dropout,再linear第二层。
2.2.1 Encoder Layer
Self-Attention模型的作用是提取语义级别的信息(不存在长距离依赖),而FFNN是在各个时序上对特征进行非线性变换,提高网络表达能力。

encoder层前向传播代码表示为:
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
#attention层:
src = positional_encoding(src, src.shape[-1])
src2 = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
#FFNN层:
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
2.2.2 Transformer layer组成Encoder
class TransformerEncoder(nn.Module):
r'''
参数:
encoder_layer(必备)
num_layers: encoder_layer的层数(必备)
norm: 归一化的选择(可选)
例子:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
>>> src = torch.randn((10, 32, 512))
>>> out = transformer_encoder(src)
'''
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layer = encoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = positional_encoding(src, src.shape[-1])
for _ in range(self.num_layers):
output = self.layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
# 例子
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
src = torch.randn((10, 32, 512))
out = transformer_encoder(src)
print(out.shape)
# torch.Size([10, 32, 512])
2.2.3 TransformerDecoderLayer
- 相比encoder多了Encoder-Decoder Attention层,用来帮解码器把注意力集中到输入序列的合适位置。其个decoder block的Encoder-Decoder Attention层输入k、v值都是encoder最后层的输出memory。
- 在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词,即屏蔽掉未来时刻的信息。具体是用mask下三角矩阵实现的,它会将我们想要屏蔽的单元格设置为负无穷大或者一个非常大的负数。先正常通过qk计算attention score,再乘以mask矩阵。这样进行softmax计算时,屏蔽位置的attention权重为0。
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
参数:
tgt: 目标语言序列(必备)
memory: 从最后一个encoder_layer跑出的句子(必备)
tgt_mask: 目标语言序列的mask(可选)
memory_mask(可选)
tgt_key_padding_mask(可选)
memory_key_padding_mask(可选)
'''
#1.self-attention层
tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
#Encoder-Decoder Attention层
tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
#3.FFNN层
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
# 可爱的小例子
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
memory = torch.randn((10, 32, 512))
tgt = torch.randn((20, 32, 512))
out = decoder_layer(tgt, memory)
print(out.shape)
# torch.Size([20, 32, 512])
2.2.4 TransformerDecoderLayer组成Decoder
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = tgt
for _ in range(self.num_layers):
output = self.layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
# 可爱的小例子
decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8)
transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6)
memory = torch.rand(10, 32, 512)
tgt = torch.rand(20, 32, 512)
out = transformer_decoder(tgt, memory)
print(out.shape)
# torch.Size([20, 32, 512])
2.2.5 Transformer

class Transformer(nn.Module):
r'''
参数:
d_model: 词嵌入的维度(必备)(Default=512)
nhead: 多头注意力中平行头的数目(必备)(Default=8)
num_encoder_layers:编码层层数(Default=8)
num_decoder_layers:解码层层数(Default=8)
dim_feedforward: 全连接层的神经元的数目,又称经过此层输入的维度(Default = 2048)
dropout: dropout的概率(Default = 0.1)
activation: 两个线性层中间的激活函数,默认relu或gelu
custom_encoder: 自定义encoder(Default=None)
custom_decoder: 自定义decoder(Default=None)
lay_norm_eps: layer normalization中的微小量,防止分母为0(Default = 1e-5)
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)(Default:False)
例子:
>>> transformer_model = Transformer(nhead=16, num_encoder_layers=12)
>>> src = torch.rand((10, 32, 512))
>>> tgt = torch.rand((20, 32, 512))
>>> out = transformer_model(src, tgt)
'''
def __init__(self, d_model: int = 512, nhead: int = 8, num_encoder_layers: int = 6,
num_decoder_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1,
activation = F.relu, custom_encoder: Optional[Any] = None, custom_decoder: Optional[Any] = None,
layer_norm_eps: float = 1e-5, batch_first: bool = False) -> None:
super(Transformer, self).__init__()
if custom_encoder is not None:
self.encoder = custom_encoder
else:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
encoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers)
if custom_decoder is not None:
self.decoder = custom_decoder
else:
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
decoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
self.batch_first = batch_first
def forward(self, src: Tensor, tgt: Tensor, src_mask: Optional[Tensor] = None, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
参数:
src: 源语言序列(送入Encoder)(必备)
tgt: 目标语言序列(送入Decoder)(必备)
src_mask: (可选)
tgt_mask: (可选)
memory_mask: (可选)
src_key_padding_mask: (可选)
tgt_key_padding_mask: (可选)
memory_key_padding_mask: (可选)
形状:
- src: shape:`(S, N, E)`, `(N, S, E)` if batch_first.
- tgt: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
- src_mask: shape:`(S, S)`.
- tgt_mask: shape:`(T, T)`.
- memory_mask: shape:`(T, S)`.
- src_key_padding_mask: shape:`(N, S)`.
- tgt_key_padding_mask: shape:`(N, T)`.
- memory_key_padding_mask: shape:`(N, S)`.
[src/tgt/memory]_mask确保有些位置不被看到,如做decode的时候,只能看该位置及其以前的,而不能看后面的。
若为ByteTensor,非0的位置会被忽略不做注意力;若为BoolTensor,True对应的位置会被忽略;
若为数值,则会直接加到attn_weights
[src/tgt/memory]_key_padding_mask 使得key里面的某些元素不参与attention计算,三种情况同上
- output: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
注意:
src和tgt的最后一维需要等于d_model,batch的那一维需要相等
例子:
>>> output = transformer_model(src, tgt, src_mask=src_mask, tgt_mask=tgt_mask)
'''
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
def generate_square_subsequent_mask(self, sz: int) -> Tensor:
r'''产生关于序列的mask,被遮住的区域赋值`-inf`,未被遮住的区域赋值为`0`'''
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def _reset_parameters(self):
r'''用正态分布初始化参数'''
for p in self.parameters():
if p.dim() > 1:
xavier_uniform_(p)
# 小例子
transformer_model = Transformer(nhead=16, num_encoder_layers=12)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)
print(out.shape)
# torch.Size([20, 32, 512])
总结一下,其实经过位置编码,多头注意力,Encoder Layer和Decoder Layer形状不会变的,而Encoder和Decoder分别与src和tgt形状一致



2.2.3 最后的线性层和 Softmax 层
Decoder 最终的输出是一个向量,其中每个元素是浮点数。输出向量经过线性层(普通的全连接神经网络)映射为一个更长的向量,这个向量称为 logits 向量。

三、GPT-2
- BERT全称是“Bidirectional Encoder Representation from Transformers“,即双向Transformer解码器。
- “自回归(auto-regression)”:这类模型的实际工作方式是,在产生每个 token 之后,将这个 token 添加到输入的序列中,形成一个新序列。然后这个新序列成为模型在下一个时间步的输入,这种做法可以使得 RNN 非常有效。
- gpt2的训练方式是生成文本,类似解码。bert是用masker-ML训练,是提取特征建立语言模型。
- GPT-2 能够处理 1024 个 token。GPT-2 和传统的语言模型一样,一次输出一个 token。但若是一直选择模型建议的单词,它有时会陷入重复的循环之中,唯一的出路就是点击第二个或者第三个建议的单词。GPT-2 有一个 top-k 参数,可以用来选择top-1之外的其他词。
- GPT-2 的每一层都保留了它自己对第一个 token 的解释,而且会在预测第二个 token 时使用它,但是不会反过来根据后面的token重新计算前面的token。
3.2 模型输出流程
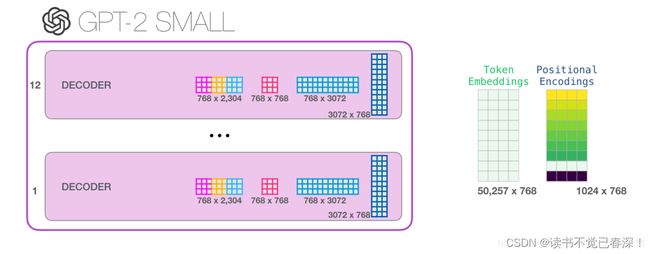
输入一共会经过四个矩阵(QKV多头矩阵、多头结果拼接转换矩阵W0,两层全连接的矩阵)
W0:经过一个线性映射得到想要的维度,随后输入全连接网络。
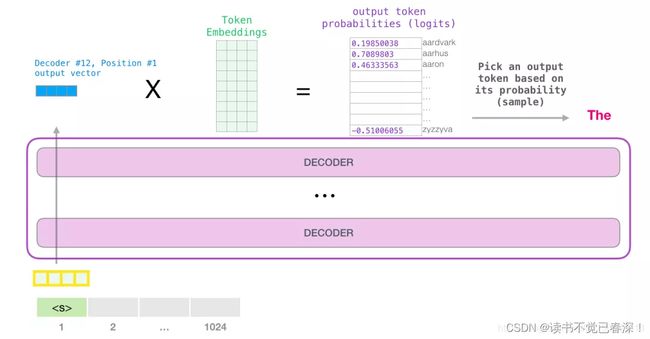
输入token embedding向量序列流过decoder得到的输出向量和嵌入矩阵相乘,得到选词概率logits。
类似于根据输出向量和词表词向量计算相似度(相乘得到)。
3.3 灾难性遗忘
为了进一步提升精调后模型的通用性以及收敛速度,可以在下游任务精调时加入一定权重的预训练任务损失。这样做是为了缓解在下游任务精调的过程中出现灾难性遗忘( Catastrophic Forgetting )问题。
因为在下游任务精调过程中, GPT 的训练目标是优化下游任务数据上的效果,更强调特殊性。因此,势必会对预训练阶段学习的通用知识产生部分的覆盖或擦除,丢失一定的通用性。通过结合下游任务精调损失和预训练任务损失,可以有效地缓解灾难性遗忘问题,在优化下游任务效果的同时保留一定的通用性。
损失函数=精调任务损失+λ \lambdaλ预训练任务损失
一般设置λ = 0.5 \lambda=0.5λ=0.5,因为在精调下游任务时,主要目的还是优化有标注数据集的效果,即优化精调任务损失。预训练任务损失的加入只是为了提升精调模型的通用性,其重要程度不及精调任务损失。