自监督 ResNets 能否在 ImageNet 上没有标签的情况下超越监督学习?
在本文中将介绍最近一篇推动自监督学习状态向前发展的论文,该论文由 DeepMind 发表,绰号为 ReLICv2。
Tomasev 等人的论文“Pushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?”。提出了对 ReLIC 论文的技术的改进,该论文名为“Representation learning via invariant causal mechanisms”。他们方法的核心是增加了 Kullback-Leibler-Divergence 损失,这是使用经典对比学习目标的概率公式计算的。除此以外还引入了一种新颖的增强方案,并借鉴了其他相关论文的经验。
本文尽量保持简单,以便即使是没有先验知识的读者也可以跟进。
计算机视觉的自监督和无监督预训练
在深入研究论文之前,有必要快速回顾一下自监督预训练的全部内容。如果你对自监督学习有所了解,或者熟悉自监督预训练,可以跳过这一部分。
一般情况下计算机视觉模型一直使用监督学习进行训练。这意味着人类查看图像并为它们创建各种标签,模型可以学习这些标签的模式。例如,人工注释者会为图像分配类标签或在图像中的对象周围绘制边界框。但任何接触过标签任务的人都知道,创建足够的训练数据集的工作量很大。
相比之下,自监督学习不需要任何人工创建的标签,模型自己监督自己学习。在计算机视觉中,对这种自监督进行建模的最常见方法是对图像进行不同的裁剪或对其应用不同的增强,并将修改后的输入传递给模型。这样可以即使图像包含相同的视觉信息但看起来不一样,也就是说让模型知道这些图像仍然包含相同的视觉信息,即相同的对象,这样可以让模型学习相同对象的相似潜在表示(输出向量)。
然后可以在这个预训练模型上进行迁移学习。这些模型会在 10% 的带有标签的数据上进行训练,以执行目标检测和语义分割等下游任务。
论文的贡献
正如许多其他自监督预训练技术的情况一样,ReLICv2 训练过程的第一步也是关于数据增强。在论文中,作者首先提到了使用以前成功的增强方案。
第一个是 SwAV 中使用的增强。与之前的工作相反,SwAV 不仅创建了两种不同的输入图像裁剪,而且最多可以裁剪 6 次。这些可以制作成不同的尺寸,例如 224x244 和 96x96,最成功的数量是两个大尺寸和 6 个小尺寸。如果想了解更多有关 SwAV 增强方案的信息,请阅读原论文。
先前描述的第二组增强来自 SimCLR。这个方案现在几乎被这个领域的所有论文使用。通过应用随机水平翻转、颜色失真、高斯模糊和过度曝光来处理图像。如果您想了解有关 SimCLR 的更多信息,请阅读原论文。
但是 ReLICv2 还提供了一种新颖的增强技术:从图像中的对象中移除背景。为了实现这一点,他们以无监督的方式在一些 ImageNet 数据上训练一个背景去除模型。作者发现这种增强在以 10% 的概率应用时最有效。

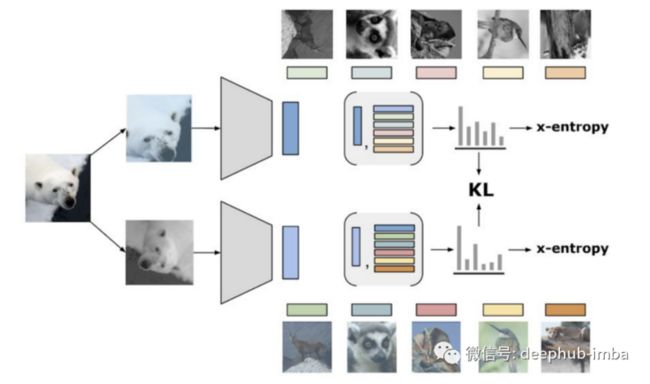
一旦图像被增强并进行了多次裁剪,输出将通过编码器网络和目标网络。当编码器网络使用反向传播进行更新时,目标网络通过类似于 MoCo 框架的动量计算接收更新。
ReLICv2 的总体目标是学习编码器,以便为相同的类生成一致的输出向量。作者制定了一种新颖的损失函数。它们从标准的对比负对数似然开始,其核心具有相似性函数,将锚图像(主要输入图像)与正例(图像的增强版本)和负例(同一图像中的其他图像)进行比较。
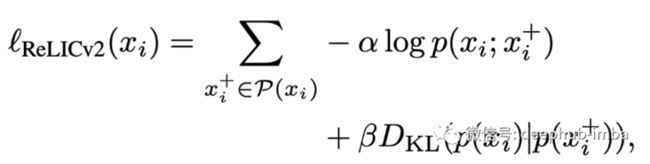
ReLICv2 损失函数由负对数似然和锚视图和正视图的 Kullback-Leibler 散度组成。
这种损失通过对比目标的概率公式得到扩展:锚图像的可能性与正图像的可能性之间的 Kullback-Leibler 散度。这迫使网络学习相似的图像不要靠得太近,不相似图像可以离得远一些,避免发生可能导致学习崩溃的极端聚类,并在集群之间创建更平衡分布。所以这个额外的损失项可以看作类似于一个自监督的模式。对于这个损失函数包含了alpha 和 beta 两个超参数,分别可以对两个损失项进行单独加权。
所有这些的方法的加入被证明是成功的,让我们仔细看看论文中提出的结果。
结果展示
正如论文标题所述,ReLICv2 试图证明的要点是,自监督预训练方法只有在编码器网络都使用相同的网络架构时才具有可比性。对于他们的工作,选择使用经典的 ResNet-50。
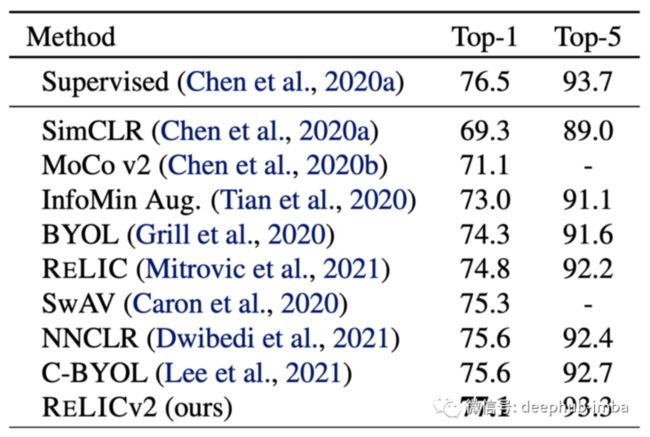
在 ImageNet 下使用不同预训练 ResNet-50 的结果。
当使用相同的 ResNet-50 并在 ImageNet-1K 上训练其线性层同时冻结所有其他权重时,ReLICv2 比现有方法有相当大的优势。与原始 ReLIC 论文相比,引入的改进甚至带来了性能优势。

与不同数据集上的监督预训练模型相比,准确性有所提高。
在比较其他数据集上的迁移学习性能时,ReLICv2 与其他方法(如 NNCLR 和 BYOL)相比,继续表现出令人印象深刻的性能。这进一步表明 ReLICv2 是一种新的、先进的自监督预训练方法。其他论文中不经常提到对其他数据集的评估。
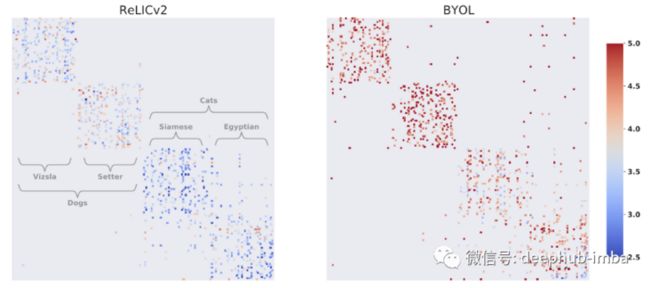
ReLICv2 和 BYOL 学习簇的可视化。点越蓝,越接近对应的类簇。
这个图表显示 ReLICv2 学习的类比其他框架(如 BYOL)更接近。这再次表明与其他方法相比,这些技术有可能创建更细粒度的簇。
最后总结
在本文中介绍了ReLICv2,这是一种新的自我监督预训练方法并显示出非常好的的实验结果。
通过结合对比学习目标的概率公式,并通过添加经过验证的新颖增强方案,该技术能够推动视觉自监督预训练的空间向前发展。
希望本文能让你对 ReLICv2 有一个很好的初步了解,但仍有很多东西需要发现。因此建议阅读原论文,即使您是该领域的新手。你必须从某个地方开始;)希望你喜欢这篇论文的解释。如果对文章有任何意见或发现任何错误,请随时发表评论。
引用:
[1] Mitrovic, Jovana, et al. “Representation learning via invariant causal mechanisms.” arXiv preprint arXiv:2010.07922 (2020).
[2] Tomasev, Nenad, et al. “Pushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?.” arXiv preprint arXiv:2201.05119 (2022).
https://www.overfit.cn/post/10a7118f47604bd090e966e0e20c0173
本文作者:Leon Sick