UCI Iris数据集K近邻方法建模预测鸢花种类
机器学习入门实践——Iris 数据集 K 近邻方法建模预测鸢花种类
任务介绍:Iris 数据集,采用多分类 KNN 方法建模,通过鸢花外形数据预测鸢花种类。
一、Iris 数据介绍
鸢尾花数据集总共包含150行数据,包含4个特征值及1个目标值。特征值分别为:萼片长度、萼片宽度、花瓣长度、花瓣宽度。结果为三种不同品种的鸢尾花。

二、数据预处理
1、Iris 数据加载
from sklearn import datasets
iris = datasets.load_iris()
print(iris)
2、Iris 数据展示
# 打印特征值名称
print(iris.feature_names)
# 打印训练数据
print(iris.data)
# 打印结果值名称
print(iris.target_names)
# 打印结果数据
print(iris.target)
3、保存训练数据
X = iris.data
4、保存训练结果数据
y = iris.target
三、模型训练
k近邻法(k Nearest Neighbor)是一种用于分类和回归的非参数据建模方法。k近邻算法是最简单的机器学习算法之一。即给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。(这就类似于现实生活中少数服从多数的思想)
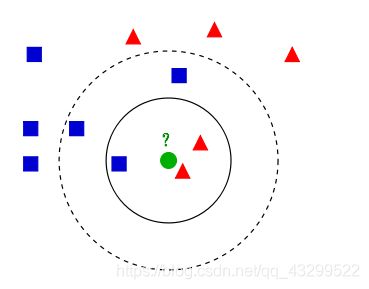
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。下面我们根据k近邻的思想来给绿色圆点进行分类。
-
如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
-
如果K=5,绿色圆点的最邻近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
它的工作机制比较简单:
1、给定一个测试样本
2、计算它到训练样本的距离
3、取离测试样本最近的k个训练样本
4、选出在这k个样本中出现最多的类别,就是预测的结果
距离衡量的标准有很多,常见的有:距离、切比雪夫距离、马氏距离、巴氏距离、余弦值等。
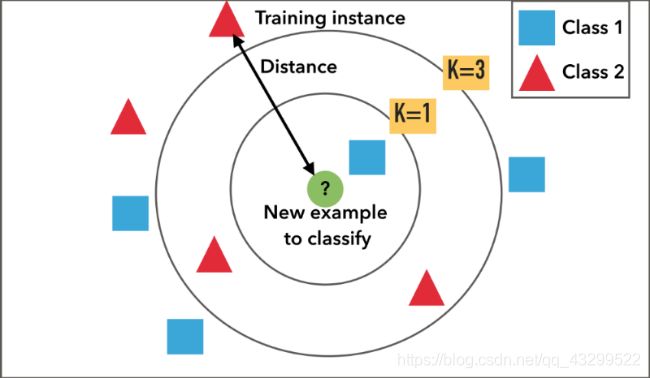
对应上面的流程来看:
1.给定了红色和蓝色的训练样本,绿色为测试样本
2.计算绿色点到其他点的距离
3.选取离绿点最近的k个点
4.选取k个点中,同种颜色最多的类。例如:k=1时,k个点全是蓝色,那预测结果就是Class 1;k=3时,k个点中两个红色一个蓝色,那预测结果就是Class 2
1、调用KNN模型
from sklearn.neighbors import KNeighborsClassifier
2、创建一个KNN模型实例
knn_1 = KNeighborsClassifier(n_neighbors=1)
3、模型训练
knn_1.fit(X, y)
4、模型预测
# 测试数据
x_test = [[5., 3.4, 1.5, 0.2]]
y_pred_1 = knn_1.predict(X)
5、设定一个新的K值进行KNN建模
knn_5 = KNeighborsClassifier(n_neighbors=5)
knn_5.fit(X, y)
y_pred_5 = knn_5.predict(X)
四、模型评估(预测准确率)
目的:通过模型评估对比模型表现、确定合适的模型参数。
方法:计算测试数据集预测准确率以评估模型表现。
1、全数据集训练与预测
accuracy_score:分类准确率分数是指所有分类正确的百分比。
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
其中 normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数。
from sklearn.metrics import accuracy_score
# k=1 时的准确率
print(accuracy_score(y, y_pred_1))
# k=5 时的准确率
print(accuracy_score(y, y_pred_5))
训练数据与测试数据相同导致的问题:
1、训练模型的最终目标是为了预测新数据对应的结果
2、最大化训练准确率通常会导致模型复杂化
3、过度复杂模型容易导致训练数据的过度拟合
2、分离训练集数据和测试集数据
1、把数据分成两部分:训练集、测试集
2、使用训练集数据进行模型训练
3、使用测试集数据进行预测,从而评估模型表现
# 数据分离
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
random_state=0)
# 这里的random_state就是为了保证程序每次运行都分割一样的训练集和测试集。否则,同样的算法模型在不同的训练集和测试集上的效果不一样。
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
k = 5
# 分离后数据集的训练与评估
knn_5 = KNeighborsClassifier(n_neighbors=5)
knn_5.fit(X_train, y_train)
y_train_pred = knn_5.predict(X_train)
y_test_pred = knn_5.predict(X_test)
# 计算分离后模型的训练集准确率
print(accuracy_score(y_train, y_train_pred))
# 计算分离后模型的测试集准确率
print(accuracy_score(y_test, y_test_pred))
k = 1
# 分离后数据集的训练与评估
knn_1 = KNeighborsClassifier(n_neighbors=1)
knn_1.fit(X_train, y_train)
y_train_pred = knn_1.predict(X_train)
y_test_pred = knn_1.predict(X_test)
# 计算分离后模型的训练集准确率
print(accuracy_score(y_train, y_train_pred))
# 计算分离后模型的测试集准确率
print(accuracy_score(y_test, y_test_pred))
3、如何确定更合适的 K 值?
- k太小:容易受到异常值的影响
- k太大:计算成本太高
k_range = list(range(1, 26))
score_train = []
score_test = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_train_pred = knn.predict(X_train)
y_test_pred = knn.predict(X_test)
score_train.append(accuracy_score(y_train, y_train_pred))
score_test.append(accuracy_score(y_test, y_test_pred))
# 训练集准确率
for k in k_range:
print(k, score_train[k-1])
# 测试集准确率
for k in k_range:
print(k, score_test[k-1])
4、图形展示
import matplotlib.pyplot as plt
%matplotlib inline
# 展示 K 值与训练数据集预测准确率之间的关系
plt.plot(k_range, score_train)
plt.xlabel('KNN Model')
plt.ylabel('Training Accuracy')

# 展示 K 值与测试数据集预测准确率之间的关系
plt.plot(k_range, score_test)
plt.xlabel('KNN Model')
plt.ylabel('Testing Accuracy')
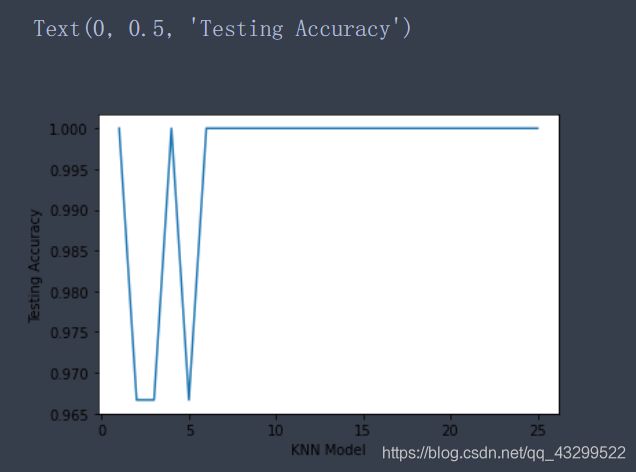
总结
使用准确率进行模型评估的局限性:无法真实反映模型针对各个分类的预测准确率。