无法从套接字读取更多的数据 oracle_从 700+亿美金市值的 Snowflake 看云数据仓库...
为了更广泛的读者需求,取消收费,在上篇付费的用户中会随机选择一名送出《第三选择》一书,多谢大家支持~
成立于2012年,旨在创造一个基于云的弹性数据仓库 SaaS 软件新秀 Snowflake 在今年9月上市发行,截止 10.26日,股价265美元,市值为 744亿美金,有巴菲特投资的第二家科技公司加持,不断刺激大家对于云数据仓库发展前景的想象和探讨,那上市即暴涨触发熔断的 Snowflake 到底有什么过人之处?
Snowflake 是基于 AWS 平台发展起来的云原生数据仓库服务,也就是 Day One,Snowflake 团队就选择公有云作为产品的底层操作系统来设计演进整个方案;亚马逊的创新文化在业界广为流行,“创新有多种方式和各种规模。最激进最具变革性的创新是帮助他人释放创造力以实现梦想。” 相信 Snowflake 不是第一个应云而生的创新,也不是最后一个;
朋友圈很多人也关心并疑问,Snowflake 的出现,亚马逊 Redshift 该如何应对?这些问题也给我带来不少困惑,本质上是对市场上如此众多的数据分析产品如何选型的疑惑,依靠一篇文章根本不够说明火热的数据分析产品,本文首先聚焦 Snowflake 引发的大家对云原生数据仓库的好奇,期待大家能找到自己选择合适的数据分析产品的思路。
- 1 -
DWaaS 数据仓库即服务
数据仓库一直是企业信息化建设的一个重要的部分,比如亚马逊电商在迁移到云数据湖 Andes 之前,拥有运行时间最长、规模最大的 Oracle Data Warehourse 集群(600+ Oracle实例),传统的数据仓库为小规模或固定集群数量机器而设计(特定要求硬件,缺乏弹性),并且依赖复杂的 ETL(Extract-Transform-Load) 工作流,假设进入数据仓库的数据是可预测规模,变化少,而且容易利用业务进行归类整理,数据常常来自内部的 CRM/ERP/OLTP 等系统;
现代化数仓,尤其是面向云构建的数据仓库服务,更多聚焦数据生产者和消费者解耦,计算存储分离,计算资源可弹性伸缩,无限扩展不用担心容量的数据湖存储,数据安全以及较少的运维工作和整体拥有成本;原因是如今的数字化业务,企业的数据积累来源,大头来自于外部不断变化的数据,比如用户行为日志,点击流,移动设备,IoT 传感器设备等半结构化数据(JSON,Avro,Parque等),同时各个行业甚至国家地区对于用户隐私和数据合规监管越来越严格;
每个云原生的数据仓库产品都有各自独特的用户体验和成本模型,比如 AWS 的 Redshift,Athena,EMR;GCP 的 BigQuery;Azure 的SQL Data Warehouse;以及本文提到的独立数据仓库即服务厂商 Snowflake,开源的 ClickHouse 等等;可以说,云原生的数据仓库服务百花齐放,客户拥有更多选择的权利;
这么多云原生的数据仓库服务,到底有哪些区别呢?我们从如下几个维度来分类:
无服务器化的程度:完全自建,托管,一直到 DWaaS(完全 SaaS 化)
核心引擎:关系数据库技术还是 Hadoop/Presto 生态
核心 MPP 架构模式:Shared-Nothing 还是 Sharded-Everything

基于云资源自建数据仓库,通常基于开源方案,比如 ClickHouse、Hadoop 等,用户负责底层资源的创建和管理,所有的配置工作,国内很多客户在 IDC 上采用这种模式,计算存储通常无法解耦,集群规模相对固定无法弹性扩展,数据安全、性能等需要额外的团队资源持续投入;
云厂商提供的解决方案通常是托管方案,Snowflake 和 Amazon Redshift 都是继承 DBMS 技术的全托管 OLAP 数仓系统,Snowflake 更接近无服务器架构,用户只需要配置计算资源相对大小(非详细硬件配置)就可以基于简单易用的 Web 控制台,以自己熟悉的 SQL 语句开始数据分析之旅;之所以称 Snowflake 是无服务器架构,主要有几个非常重要的特性:
第一天开始就以 S3 为数据湖构建整个技术栈,数据存储在对象存储上,自动扩展,按实际使用付费,用户不需要担心存储扩展问题和数据持久性问题;由于采用集中的数据湖存储,也就不存在数据孤岛问题,企业数据更好的融合在一起;
计算存储分离,计算层以 Virtual Warehouse 为单位,同一份数据,不同部门和角色,根据不同的任务类型,可以用多个并行的 Virtual Warehouse 来扩展计算性能,并且该功能在高级版本中是自动实现,不需要客户管理;拉起一个新 Virtual Warehouse集群只需要秒级的耗时;
用户不需要选择、安装和配置任何软件组件
用户不需要任何维护,集群管理和性能调优,一切交给 Snowflake 进行自动化进行
低成本,计算存储分离,计算层可以单独扩展,甚至停止,完全的云原生按使用付费
- 2 -
计算存储分离架构

计算存储分离已经是云原生数仓技术发展的一个非常重要的特性,比如上图中,无论是 Snowflake,BigQuery 还是 Redshift目前都支持计算存储分离架构;
Snowflake 作为一个数仓即服务的 SaaS 解决方案,本身是多租户模型,因此,第一层也是 Snowflake 公开演讲中比较复杂的 Cloud Service 一层(大脑层),包含共享的元数据管理,基础设施管理,认证和访问,事务,查询优化,安全,统计数据,监控等等模块;
而 Snowflake 第一天就选择对象存储作为数仓的存储层,S3的高可用性以及数据持久性很难被超越,所以 Snowflake 放弃自研一套 HDFS或类似的方案;Amazon S3 中的对象是 Immutable 的键值对象,不支持对象文件内容部分更新,但支持对象文件部分读取,通过网络 HTTP/S 请求访问和操作 S3;表以及查询结果在对象存储层被水平拆分成一系列的 Immutable 微分区文件(16MB左右)类似传统数据库的数据页或块,更新操作等同于增加或删除整个文件;每个文件中存储属性或某个列的所有值,并通过一种压缩的列式存储 PAX 或 Hybrid Columnar 格式组织在一起,由于 S3 支持对象数据的分段读取,数据查询可以优化到只读取 Header(列值的指针)以及所需要的列值;某些耗时比较长的查询结果也会临时保存在 S3中,并保障无论多复杂的巨型查询,都能正常跑完,而不至于磁盘空间不足;而整个数据表文件和S3对象对应关系,锁,事务日志等元数据并不是保存在 S3中,而是存储在 Cloud Service 层的一个 Key-Value 存储中;
计算层(肌肉层)基本单位是 Virtual Warehouse(VW),就是一组 EC2 实例,并由独立可扩展的服务来管理(创建,销毁,按需垂直和横向扩展),用户可以在同一时间,运行多个 VM,每个独立的 VW 都可以访问所有数据,但拥有隔离的互不影响的性能;当用户没有分析任务时,可以停止所有的 VW 资源;为了满足不同工作负载对性能的要求,计算大小被标准化成 XS 到 4XL 类似 “T-Shirt” 大小的选项,独立于云平台的计算实例细节,不同的云平台采取不同的价格策略,而且不断迭代;为了降低计算节点跟对象存储之间的网络通信,每个计算节点本地 SSD 缓存部分热点表数据,比如过往查询过的 S3表文件;Snowflake 团队称他们的架构为 “多集群,共享数据架构“。
在 Snowflake 中,用户无法直接访问 VM 计算资源以及 S3 对象存储的数据,只能通过 Snowflake 提供的接口进行交互
- 2.1 -
弹性和隔离

由于采用了计算存储分离架构,Snowflake 支持多维度、各组件独立弹性扩展能力,包括计算、存储以及用户并发的性能需求;
每个查询只在某一个 VW 集群上执行,EC2 工作节点不会跨集群共享,从而满足不同客户对于性能的强有力的隔离和保障,当然有时为了提高工作节点的利用率,降低成本,未来 Snowflake 团队不排除不会跨 VW 共享工作节点;当用户提交一个新的分析查询时,VW 集群中的所有或部分工作节点,会启动新的工作进程,该工作进程的生命周期跟该查询一致;
共享的、无限的数据湖存储意味着用户可以共享和集成所有数据,同时不同用户可以拥有相互独立的 私有计算资源 避免各团队之间不同工作负载的相互影响;比如定期拉起按需的 VW 集群用来处理大批量数据加载,同时不同的组织部门拥有多个 VW 集群用来处理查询分析任务;
- 2.2 -
本地缓存
VW 集群中的每个工作节点都在本地磁盘上维护一个热点数据的缓存,缓存的内容是该节点上执行过的查询所访问的 S3 表文件数据;缓存存在的生命周期跟工作节点的生命周期一致,并在不同的查询进程中共享;缓存策略目前采用非常简单的 LRU(Least-Recently-Used)策略进行替换;
为了提高缓存命中率,避免一个 VW 集群不同工作节点中存储冗余的表文件,查询优化器根据表名基于一致性哈希算法将表文件分散存储在所有的工作节点缓存中;访问同一个表的后续或并行查询会在同一个工作节点上访问同样一个表文件缓存数据;
当 VW 的工作节点数量发生变化时,比如节点故障或大小调整,每个节点的缓存的表文件数据不会立刻根据一致性哈希重新分布,而依赖 LRU 算法,最终替换掉节点缓存中的数据;
- 2.3 -
高可用性和持续迭代
当数据分析成为企业核心业务系统的今天,高可用性成为数据仓库非常重要的一个特性;即客户期望一个永远在线没有任何维护时间的数据仓库服务;
Snowflake 通过 故障恢复和在线升级 实现整个系统的高可用;
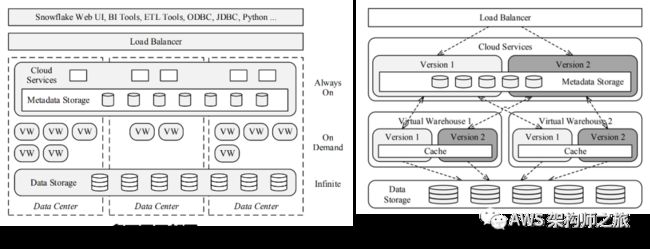
如上图,三层中每个组件服务都是多可用区部署,允许单个服务节点故障并自动恢复的能力;存储层依赖云厂商的对象存储服务,比如 Amazon S3,在一个区域的多个可用区进行数据复制,实现 4个9的可用性以及11个9的数据持久性;类似 S3 的做法,Snowflake 的 Cloud Service 也是多可用区部署,其中有状态的元数据存储也在多可用区进行复制,其它服务都是无状态服务,也部署在多个可用区,并由负载均衡进行请求分发;
如果一个节点故障甚至一个可用区故障,其他节点可以继续该任务,而终端用户几乎不受影响,有可能某些用户查询在这个时刻会失败,重试之后重定向到其它不同的健康节点;
相反对于 VW 集群,不是跨可用区部署,主要是性能方面的考量,高网络吞吐和低延迟对于高性能数仓非常重要;假如某一个工作节点发生故障,正在执行的查询会失败,但失败的查询会透明的重新执行,要么在一个替换故障节点的新节点上执行或剩下的 VW 节点组上继续执行;为了加速故障节点的替换以及新 VW 的快速启动,Snowflake 维护了一个小型的备用节点组;
如果整个可用区发生故障,该可用区中所有 VW 集群的查询都会失败,用户需要在另外一个可用区重新启动 VW 集群来继续完成分析任务,整个可用区故障是一个非常小概率事件;
除了故障恢复,Snowflake 还支持在线升级,正常一周一次;无论是 Cloud Service (大脑层)还是 VW(肌肉层)服务都被设计成允许多个版本同时在线;所有的状态数据(元数据)都利用事务特性的 K-V存储保障一致性,当团队需要更新元数据 Schema 的时候,必须保证向后兼容历史版本;其它服务组件都是无状态服务;如果服务需要升级,团队会先部署一个新版本,同时保留旧版本,用户所有新查询都会落在新版本服务上,并允许旧版本上的查询继续执行完成,一旦旧版本服务上所有查询都执行完成,该服务就会被销毁(类似蓝绿方式进行在线升级);
- 2.4 -
并发处理和事务
大规模分析任务的典型目标场景是大规模读取,批量插入或大规模批量更新;从架构设计上来看,Snowflake 不限制用户并发数量,某一个用户可以并行跑尽可能多的查询分析任务,只需要扩展更多的 VW 集群,或垂直提升 VW 集群计算能力;
Snowflake 的并发控制是完全由第一层大脑层 Cloud Service 来实现,并且基于 Snapshot Isolation(SI) 实现 ACID 事务特性,SI 下,事务处理所有读请求在事务启动时看到的一致的数据快照;SI 是基于 MVCC(multi-version concurrency control)多版本并发控制实现的,意味着每次更新或修改数据库对象都将保留一段时间,也就是会存在多个数据库对象版本;选择 MVCC 是匹配 S3 对象存储特征的一个自然结果,因为 S3 对文件的修改只能通过替换整个文件实现;
所有针对某个表的写操作(插入,更新,删除和合并)都通过增加或删除一整个新版本表文件;表文件的增加和删除是通过 Cloud Service 中的元数据库进行管理,允许同一个表的同一个版本的文件可以高效被处理;基于多版本的 Snapshot 机制还有助于实现 Time Travel(按时间点还原)以及克隆(cloning)特性;
- 3 -
半结构化数据和 Schema-Less 支持
Snowflake 扩展了标准的 SQL 类型来支持半结构化数据:VARIANT、ARRAY 和 OBJECT;VARIANT 可以保存任何标准的 SQL 数据类型(日期,字符串等)以及 ARRAY 和 OBJECT(Map)类型,比如类似 MongoDB 文档型对象 JSON,XML或 Avro/ORC/Parquet等;ARRAY 和 OBJECT 是 VARIANT 的进一步具体化;底层都是一样的格式,自描述,压缩的二进制序列化,支持高效的键值查询,以及高效的数据类型测试,对比以及哈希计算;
大家通过以下一段 SQL (摘自附录参考资料)来体会一下:
CREATE TABLE “SINGLE_VARIANT_DB”.”POC”.DEVICEINFO_VAR (V VARIANT);
CREATE FILE FORMAT "MULTI_COLUMN_DB"."POC".ORC_AUTO
TYPE = 'ORC'
COMPRESSION = 'AUTO';
COPY INTO "SINGLE_VARIANT_DB"."POC”.DEVICEINFO_VAR
from @ORC_SNOWFLAKE/tblorc_deviceinfo
FILE_FORMAT = ORC_AUTO
ON_ERROR = 'continue';
这种扩展有不少优势,对比 Redshift/BigQuery 等数据仓库,要求用户必须先定义数据 Schema 再通过 ETL 将半结构化数据转化匹配所定义的 Schema,才能加载进数据仓库进行分析,数据提供方和消费者之间通过数据 Schema 紧密耦合在一起;而 Snowflake 支持用户 ELT 方式,将加载 Load提到转化 Transform之前,因此用户可以直接先将半结构化数据加载到数据仓库中,在需要的时候,再进行类型转化,被称为“Schema Later”的处理方式;从 ETL 变成 ELT,减少了由于数据 Schema 变化导致 ETL 逻辑变更,从而涉及多个部门协调耗时的问题;另外一方面,在需要实施类型转换的时候,可以直接利用 Snowflake 提供的并行大规模处理能力,包含所有复杂的 SQL 操作,比如 Join,Sort或 Aggregation等等;
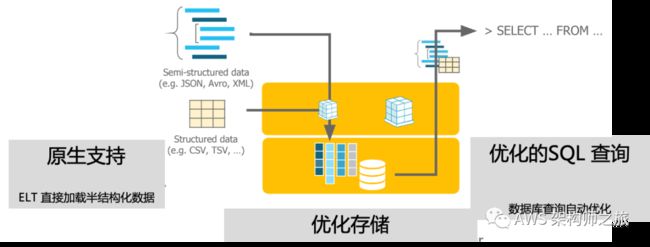
但 Redshift 以及 BigQuery 都内置支持直接查询存储在对象存储上的半结构化数据文件,以 Redshift Spectrum 为例,支持类似 Parquet/ORC/RCFile/OpenCSV/AVRO等,并支持Gzip,Bzip2和Snappy压缩格式;
“Redshift Spectrum 可以帮助客户通过Redshift直接查询S3中的数据。Redshift Spectrum采用了无服务器架构,所以客户不需要额外配置或管理任何资源,而只需为Redshift Spectrum的用量付费。使用方面,Redshift Spectrum享有和Amazon Redshift一样的复杂查询的优化机制、本地数据的快速读取以及对标准SQL的支持。我们做了一个实验,在对一个EB的数据做涉及四个表的 join,filter和group的查询时,1000个节点的Hive集群预估需要耗时5年,而 Redshift Spectrum只用了173秒。”
- 4 -
数据安全和合规
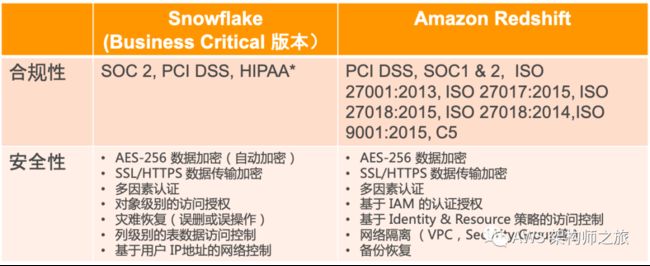
数据安全对客户而言非常重要,云原生数仓安全性,至少需要考量网络访问安全,账号和用户认证授权,对象(用户,数据库,表等)访问安全,数据安全以及合规认证;Snowflake 以及其它云数据仓库服务都提供了访问控制(数据湖基于 Policy 最小权限设定,内置 SQL 的基于角色的访问控制等),数据加密,数据传输加密,多因素认证机制保障客户数据安全;
关于数据加密,Snowflake 使用 AWS CloudHSM 来安全地生成,保存和使用根密钥,CloudHSM 是一个硬件设备,根密钥只在该硬件设备上保存;除了数据加密,Snowflake 还提供 S3 对象存储层基于 IAM Policy 的安全隔离,每个租户基于角色的的层级权限控制;
- 5 -
成本模型
Snowflake 目前同时支持 AWS /Azure 和 GCP 但从官网介绍可以看到,由于起源在 AWS 平台,区域分布和所支持的功能也是最完整的;
从顶层的价格设计来说,基于所有的主流云原生数据仓库都支持按需和预留容量两种价格体系;按需(pay-as-you-go)和我们熟悉的 AWS 等云服务商提供的按需付费是一致的,对于 Snowflake 用户每个月最低消费是 25美金,对象存储通常 40美金/TB/月 起步;预留容量,客户可以提前购买一定量的 Snowflake 资源,该模式的价格比按需要便宜;
Snowflake 的成本主要包含三个方面:Virtual Warehouse(计算成本),Data Storage(数据存储成本),以及多租户的 Cloud Service成本;
- 5.1 -
VW 计算成本
前文提到 VW 被设计成不同的 “T-Shirt“ 大小供客户选择,每种大小类型,单位成本标准化成 Snowflake 的 Credit 数值,如下:
| XS | S | M | L | XL | 2XL | 3XL | 4XL |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
举例你选了并启动了一个 L 的 VW 集群,每个小时会消耗 8个 Snowflake 的 Credit,假定你跑在 AWS US East (Northern Virginia)区域,Standard 版本也就是起步版本的最低按需单价是 2美金/Credit,也就是按需单位成本在 16美金/小时;
而同样区域的 Redshift RA3.4xlarge (12vCPU,96GB内存)的机器,每小时单价为 3.26美金,如果按照 Snowflake 的 VW 集群成本倒推 Redshift 集群数量,那么一个 L 大小的 VW 集群,相当于同区域 5台 RA3.4xlarge 的 Redshift集群,总按需成本在 16.3美金/小时;
- 5.2 -
数据存储成本
主要是对象存储的成本,Snowflake 和 Redshift 类似,收取的是压缩后的数据存储大小的费用,而 BigQuery 是计算的非压缩数据大小所占的存储量;同样 AWS US East (Northern Virginia)区域,Snowflake 收取 40美金/TB/月,而 Redshift Managed Storage(S3)是 24.576美金/TB/月;
- 6 -
总结
这是一个最好的时代,云原生的数据仓库服务百花齐放,留给我们的就是花时间欣赏和体验就行!
参考资料:
Analytics Challenges — Modern BI Architectures (Part 4)
Amazon Redshift 官方文档
A Deep Dive Into Google BigQuery Architecture
Snowflake Vs Redshift: Data Warehouse Comparison
The Snowflake Elastic Data Warehouse
Snowflake’s Cloud Data Warehouse — What I Learned and Why I’m Rethinking the Data Warehouse
挖掘EB级别数据的价值 – Redshift Spectrum介绍及最佳实践
Using DBT to Execute ELT Pipelines in Snowflake
10 Minute Beginner’s Guide to Snowflake Cloud Data Warehouse
Snowflake Pricing: A Detailed Guide for 2020
本站点所有文章,仅代表个人想法,不代表任何公司立场,所有数据都来自公开资料,转载请注明出处