第一章 【数据分析师---数据可视化1】 matplotlib
数据分析可视化1
- 第一章
-
- 第一节 matplotlib
- 第二节 绘制折线图
-
- color的选择
- 一张图中绘制两条线:
- 图片保存
- 风格样式
- fmt格式
- 第三节 绘制柱状图(离散数据)
-
- 直方图和条形图的区别
- 统计数的技巧
- 绘制柱状图
-
- 简单柱状图
- 分组柱状图
- 堆叠柱状图
- 第四节 绘制直方图(连续数据)
- 第五节 绘制堆叠图
-
- 第一种分组图:
- 第二种堆叠图:
- 第三种 df.plot:
- 第四种 plt.stackplot:
- 第六节 绘制带有阴影面积的折线图
- 第七节 绘制pie饼图
-
- 简单饼图
- 花样饼图
- 第八节 绘制散点图
-
- 基础知识
- 实战
- 第八节 时序数据可视化
-
- 基础知识
- 实战
- 第九节 实时数据可视化(不太明白实用性,提问课问问)
-
- 实时数据绘制以及模块调用
- 第十节 图表的多重绘制(subplot)
-
- 第一种方式:plt.subplots()绘制子图
- 第二种方式:fig.add_subplot 绘制子图
- 第三种方式 plt.subplot2grid 绘制子图
- 附官网网址
第一章
第一节 matplotlib
from matplotlib import pyplot as plt
x = [0,1,2,3,4,5]
y = [0,1,9,3,4,5]
plt.plot(x,y)
设置X Y轴以及中文标题
- 显示x轴标题:plt.xlabel(“X轴”)
- 显示y轴标题:plt.ylabel(“Y轴”)
- 显示图像标题:plt.title(“这是我的第一个图表”)
- 设置中文字体显示:plt.rcParams[‘font.sans-serif’]=[‘SimHei’]
第二节 绘制折线图
plt.plot(x,y,marker=".",markersize="15",color="",linewidth="",markeredgecolor="",mew="",markerfacecolor="")
marker/markersize/markeredgecolor/mew/markerfacecolor:标记/标记大小/标记边缘的颜色/标记边缘的宽度/标记里面的颜色
color/linewidth(lw):线的颜色、粗细(默认为2)
color的选择
谷歌浏览器,F12或者ctrl+shift+I element style
一张图中绘制两条线:
针对x轴相同,y值不同的情况
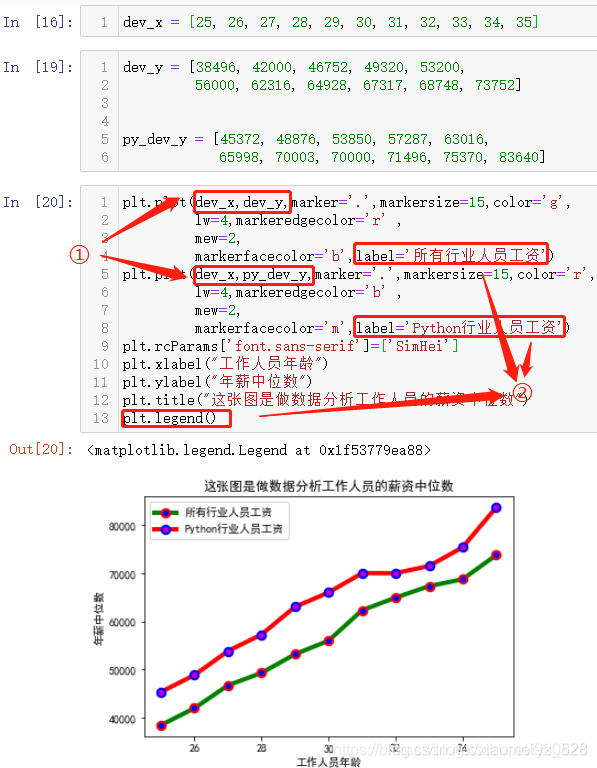
plt.legend()和label标签联合使用
图片保存
plt.savefig() (jupter中需要放在上述代码同一个执行单元中,jupter中执行完一个单元即忘记)
风格样式
plt.style.available 风格获取
plt.style.use(“”) 风格使用
plt.xkcd() 卡通模式 需要配合特殊的字体使用或者全英文使用,与中文不匹配
plt.rcdefaults() jupter中去掉卡通模式,不去掉变不回来
fmt格式
![]()

plt.plot(x,y,"bo")
第三节 绘制柱状图(离散数据)
直方图和条形图的区别
直方图:
统计报告,统一数据,连续的。各个长条衔接在一起,表示数据间的数学关系;
条形图
各长条间有空隙,区分不同的类
统计数的技巧
统计一个列表中不同元素的个数
from collections import Counter
cnt=Counter()
list1=["A","B",'A',"B","D","D"]
for i in list1:
cnt.update(i)
结果 :
Counter({'A': 2, 'B': 2, 'D': 2}) #cunt对象,类似字典格式
有一数据如下:
lang=data.LanguagesWorkedWith
lang[:5]
0 HTML/CSS;Java;JavaScript;Python
1 C++;HTML/CSS;Python
2 HTML/CSS
3 C;C++;C#;Python;SQL
4 C++;HTML/CSS;Java;JavaScript;Python;SQL;VBA
cnt=Counter()
for i in lang:
cnt.update(i.split(";"))
结果:
Counter({'HTML/CSS': 55466,
'Java': 35917,
'JavaScript': 59219,
'Python': 36443,
'C++': 20524,
'C': 18017,
'C#': 27097,
'SQL': 47544,
'VBA': 4781,
'R': 5048,
'Bash/Shell/PowerShell': 31991,
'Ruby': 7331,
'Rust': 2794,
'TypeScript': 18523,
'WebAssembly': 1015,
'Other(s):': 7920,
'Go': 7201,
'PHP': 23030,
'Assembly': 5833,
'Kotlin': 5620,
'Swift': 5744,
'Objective-C': 4191,
'Elixir': 1260,
'Erlang': 777,
'Clojure': 1254,
'F#': 973,
'Scala': 3309,
'Dart': 1683})
x y轴绘制
lang_x=[]
lang_y=[]
for i in cnt:
lang_x.append(i)
lang_y.append(cnt[i])
绘制柱状图
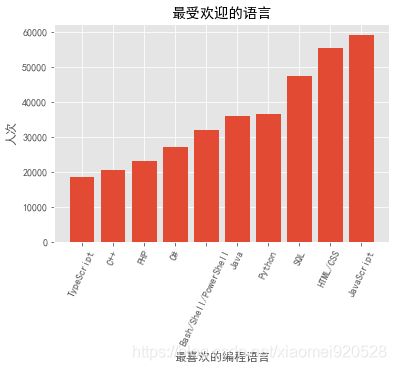
简单柱状图
plt.bar(lang_x,lang_y)
plt.figure(figsize=(6,4)) #大小
plt.bar(lang_x,lang_y)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("最受欢迎的语言")
plt.xlabel("最喜欢的编程语言")
plt.ylabel("人次")
想排序分布数据就要是排序好的
lang_x=[]
lang_y=[]
for i in cnt.most_common(10):
print (i)
lang_x.append(i[0])
# # print(cnt[i])
lang_y.append(i[1])
如果想要X轴的文字不相互堆叠
方法一:
plt.barh(lang_x,lang_y)
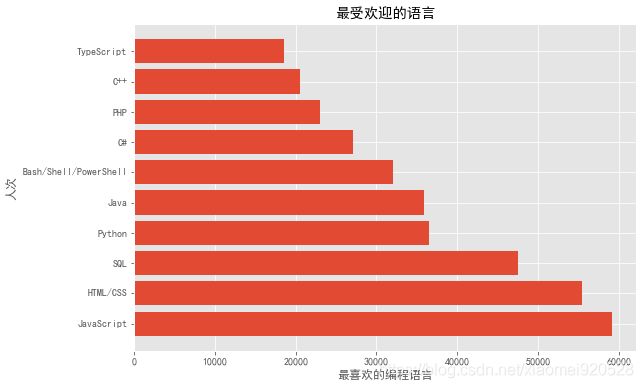
如果想最大值在上放,则
lang_x.reverse()
lang_y.reverse()
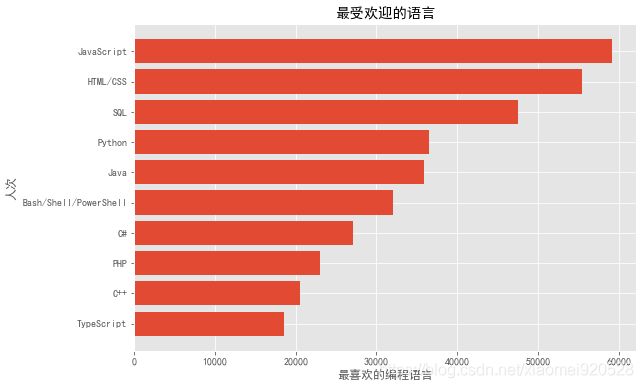
方法二:
plt.xticks(rotation=65)
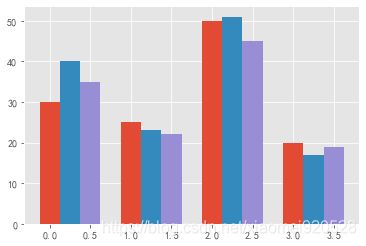
分组柱状图
data = [[30, 25, 50, 20],
[40, 23, 51, 17],
[35, 22, 45, 19]]
x = np.arange(4) #array([0, 1, 2, 3])
plt.bar(x,data[0],width=0.25)
plt.bar(x+0.25,data[1],width=0.25) #x+0.25坐标轴的偏移长度 width=0.25 条的宽度
plt.bar(x+0.5,data[2],width=0.25)
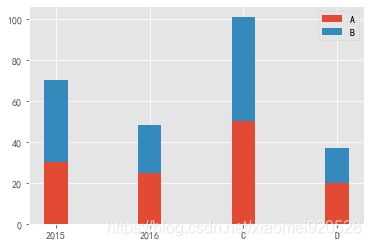
堆叠柱状图
plt.bar(x,data[0],width=0.25)
plt.bar(x,data[1],width=0.25,bottom=data[0]) #最底部从哪开始
plt.xticks(x,('2015','2016','C','D')) #底部X轴的标识
plt.legend(labels=['A','B']) #标识
第四节 绘制直方图(连续数据)
ages = [18,19,21,25,26,26,30,32,38,45,55]
bins = [20,30,40,50,60]
plt.hist(ages)
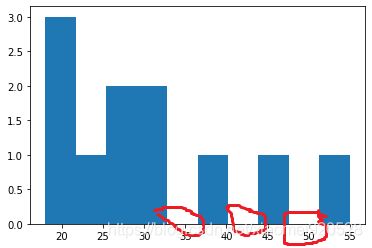
X轴是连续的,没有值保留这个值,bar图没有值根本不显示。
plt.hist(df.Age,bins=15,edgecolor='black') #bins=15 合并器 edgecolor边缘着色
median=df.Age.mean()
plt.axvline(median,color='r',label='mean') #axvline vlian 垂直线 hline 水平线
plt.axvline(df.Age.max(),color='g',label='max') #或者plt.axhline(28000,color='g',label='max')
plt.legend()
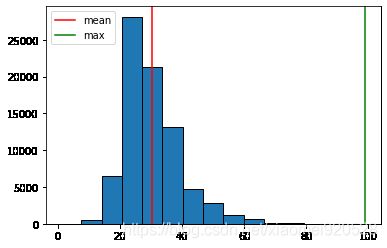
第五节 绘制堆叠图
前期学过的堆叠图:
第一种分组图:
需要自行计算索引值偏移多少
import matplotlib.pyplot as plt;import numpy as np
plt.style.use('fivethirtyeight')
minutes = [1, 2, 3, 4, 5, 6, 7, 8, 9]
player1 = [1, 2, 3, 3, 4, 4, 4, 4, 5]
player2 = [1, 1, 1, 1, 2, 2, 2, 3, 4]
player3 = [1, 5, 6, 2, 2, 2, 3, 3, 3]
index_x = np.arange(len(minutes))
w=0.25
plt.bar(index_x-w,player1,width=w)
plt.bar(index_x,player2,width=w)
plt.bar(index_x+w,player3,width=w)
plt.legend(labels=['1','2','3'])
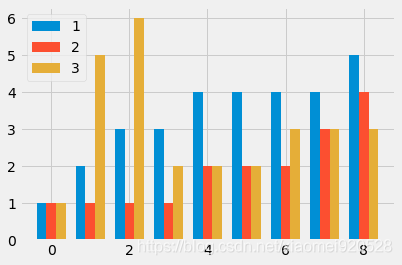
第二种堆叠图:
bottom需要自行计算底线,当有多种分组时不适合
plt.figure(figsize=(9,6))
plt.bar(index_x,player1,width=w)
plt.bar(index_x,player2,width=w,bottom=player1)
#player1+player2=[1, 2, 3, 3, 4, 4, 4, 4, 5, 1, 1, 1, 1, 2, 2, 2, 3, 4]
#相当于拼接而不是相加,所以用np.array(player1)+np.array(player2)
plt.bar(index_x,player3,width=w,bottom=np.array(player1)+np.array(player2))
plt.legend(labels=['1','2','3'])
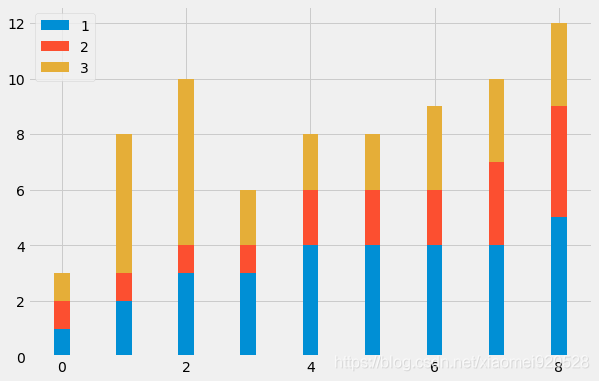
第三种 df.plot:
import pandas as pd
df = pd.DataFrame([['A', 10, 20, 10, 26], ['B', 20, 25, 15, 21], ['C', 12, 15, 19, 6],
['D', 10, 18, 11, 19]],
columns=['Team', 'Round 1', 'Round 2', 'Round 3', 'Round 4'])
#因为是df.plot所以可以直接给相应的字段 Team plot原来绘制折线图,kind='bar',模式为柱状图
df.plot(x='Team',kind='bar')
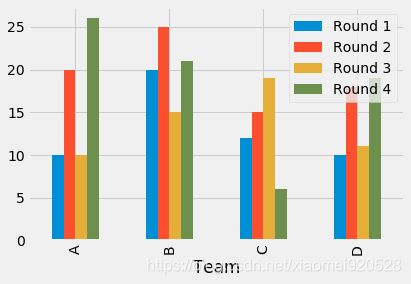
#stacked不需要处理细节了
df.plot(x='Team',kind='bar',stacked=True)
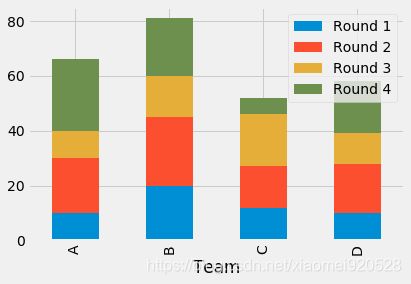
第四种 plt.stackplot:
小插曲:
np.vstack 按垂直方向(行顺序)堆叠数组构成一个新的数组
x = [1, 2, 3, 4, 5]
y1 = [1, 1, 2, 3, 5]
y2 = [0, 4, 2, 6, 8]
y3 = [1, 3, 5, 7, 9]
y = np.vstack([y1,y2,y3])
结果:
array([[1, 1, 2, 3, 5],
[0, 4, 2, 6, 8],
[1, 3, 5, 7, 9]])
plt.stackplot绘图:
colors = ['r','g','b']
plt.stackplot(x,y1,y2,y3,colors=colors)
plt.legend(labels=['y1','y2','y3'],loc='upper left')
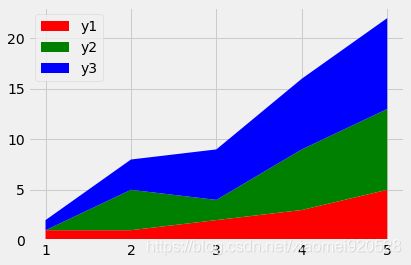
第六节 绘制带有阴影面积的折线图
如下一组数据(展示了部分)
Age All_Devs Python JavaScript
0 18 17784 20046 16446
1 19 16500 17100 16791
2 20 18012 20000 18942
3 21 20628 24744 21780
4 22 25206 30500 25704
data.plot() 可以直接展示,但是有一些细节不好调节,所以用plt.plot()
plt.plot(data.Age,data.All_Devs)
plt.plot(data.Age,data.Python)
plt.legend(labels=['All','Python'])
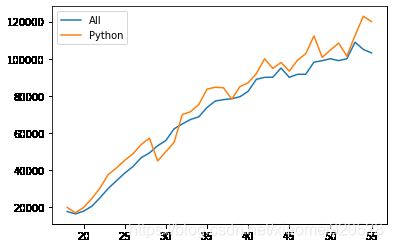
plt.plot(data.Age,data.All_Devs)
plt.plot(data.Age,data.Python)
plt.legend(labels=['All','Python'])
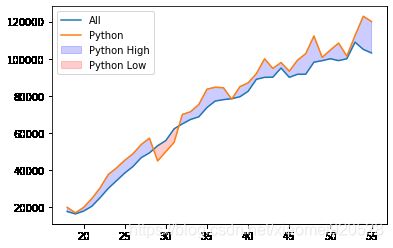
#第三个参数 data.All_Devs为边界线
plt.fill_between(data.Age,data.Python ,data.All_Devs,where=(data.Python > data.All_Devs), alpha=0.2 ,color='b')
plt.fill_between(data.Age,data.Python ,data.All_Devs,where=(data.Python < data.All_Devs), alpha=0.2 ,color='r')
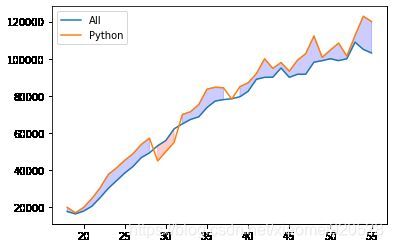
上图中空白部分为缺失值,可以使用interpolate做线性填充
plt.plot(data.Age,data.All_Devs)
plt.plot(data.Age,data.Python)
plt.legend(labels=['All','Python'])
plt.fill_between(data.Age,data.Python ,data.All_Devs,
where=(data.Python > data.All_Devs),
alpha=0.2 ,color='b',
interpolate=True,
)
plt.fill_between(data.Age,data.Python ,data.All_Devs,
where=(data.Python < data.All_Devs),
alpha=0.2 ,color='r',
interpolate=True,)
plt.legend(labels=['All','Python','Python High','Python Low'])
第七节 绘制pie饼图
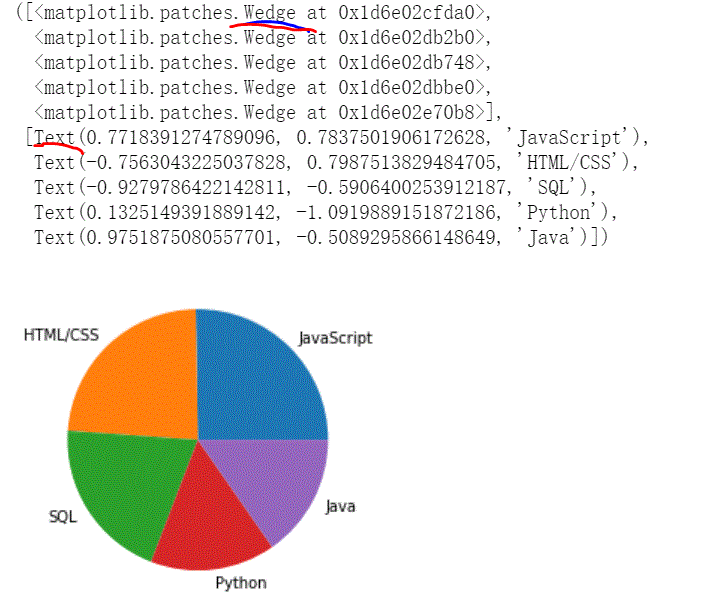
简单饼图
line图 bar图,或其他xy坐标的要告诉它xy轴就行,饼图需要数据并告诉他标签在哪
list1 =['JavaScript',
'HTML/CSS',
'SQL',
'Python',
'Java']
list2 = [59219,
55466,
47544,
36443,
35917]
plt.pie(list2,labels=list1)
共绘制了10个图,5个边界模块,5个text信息
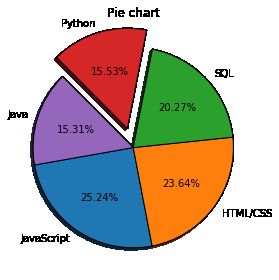
花样饼图
explo 突出某一块
shadow 阴影。模拟的3d效果
autopct 数据标注,比例数据。’% 数据格式 %’
startangle 开始的第一组数据在什么地方,转动
wedgeprops 勾线,edgecolor 边界颜色,字典格式
title 标题
tight_layout 浏览器尺寸自适应。
explo=[0,0,0,0.2,0]
plt.pie(list2,labels=list1,explode=explo,
shadow=True,
autopct='%1.2f%%' ,
startangle=190,
wedgeprops={'edgecolor':'black'}
)
plt.title("Pie chart")
plt.tight_layout()
实战未展示。。。。。。
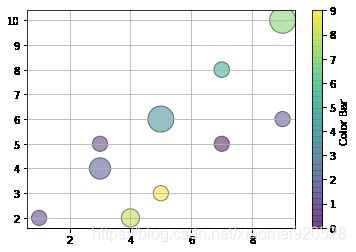
第八节 绘制散点图
基础知识
plt.scatter(x,y,c='r',s=140,edgecolor='black',alpha=0.5) #c颜色,s大小,edgecolor边缘颜色,alpha颜色透明度
plt.grid() #网格
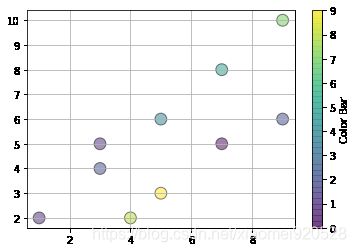
散点图有时候用来分别类别,用类别来判定数之间有没有关联,不一定肯定有关联,引入第三个参数–类别。
x=[1,3,5,7,9,4,5,7,9,3]
y=[2,4,6,8,10,2,3,5,6,5]
z=[1,2,4,5,7,8,9,0,2,1]
plt.scatter(x,y,c=z,s=140,edgecolor='black',alpha=0.5)
plt.grid()
cbar=plt.colorbar() #颜色标尺 种类太多有颜色过度,相当于标尺
cbar.set_label('Color Bar ')
以上是二维表格上用三组数据显示三维信息,除此之外还有第四组信息。
x=[1,3,5,7,9,4,5,7,9,3]
y=[2,4,6,8,10,2,3,5,6,5]
z=[1,2,4,5,7,8,9,0,2,1]
size=[233,455,677,244,677,333,233,233,233,233]
plt.scatter(x,y,c=z,s=size,edgecolor='black',alpha=0.5)
plt.grid()
cbar=plt.colorbar() #颜色标尺 种类太多有颜色过度,相当于标尺
cbar.set_label('Color Bar ')
实战
测试数据为影片的观看数量以及点赞数量信息,有三个字段,读取数据如下
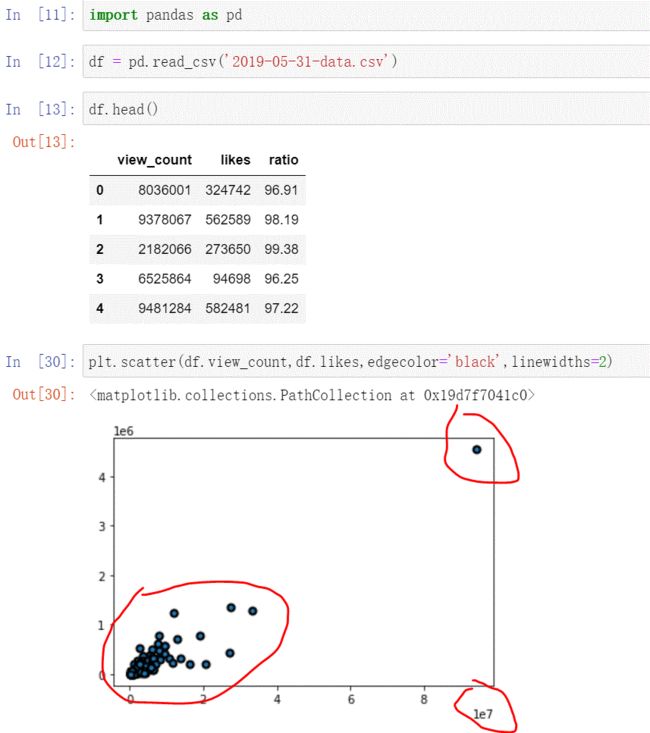
对于此类数据量的量级很大的情况(比如最后x轴的坐标都到了10的7次方),或者因为一个超级大的数据,别的数据都堆叠在一块,可以采用对数转化,将x轴的数据转化为对数表示,代码指令:
plt.xscale(‘log’),
plt.yscale(‘log’)
plt.figure(figsize=(10,6))
plt.scatter(df.view_count,df.likes,c=df.ratio)
plt.xscale('log')
plt.yscale('log')
cbar =plt.colorbar()
cbar.set_label('Like/Dislike ')
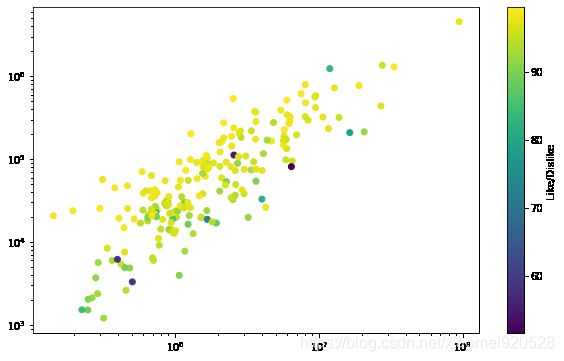
少数深颜色的可能为烂片,要根据实际数据分析。
plt.scatter(df.view_count,df.likes,edgecolor='black',linewidth=1,alpha=0.9,c=df.ratio,cmap='summer')
cmap:可以用来控制颜色渐变,字符串或者matplotlib.colors.Colormap
第八节 时序数据可视化
基础知识
字符串时间数据和Datetime格式的时间数据绘图对比
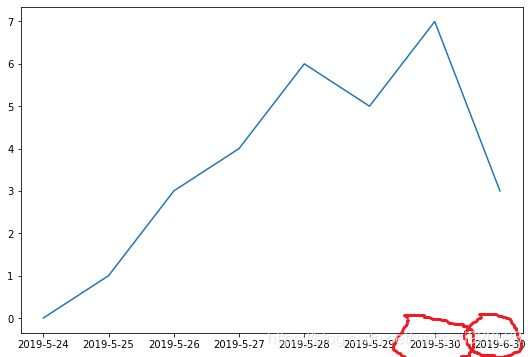
1.字符串格式的时间绘图: 忽略时间的连续性,只是当样本
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime,timedelta
from matplotlib import dates as mpl_dates
x = ['2019-5-24','2019-5-25','2019-5-26','2019-5-27','2019-5-28','2019-5-29','2019-5-30','2019-6-30']
y = [0,1,3,4,6,5,7,3]
plt.figure(figsize=(9,6))
plt.plot(x,y)
2.再编写一个Datetime格式的时序绘图 考虑了时间的连续性,缺失的时间会自动补齐。
x2 = [
datetime(2019,5,24),
datetime(2019,5,25),
datetime(2019,5,26),
datetime(2019,5,27),
datetime(2019,5,28),
datetime(2019,5,29),
datetime(2019,5,30),
datetime(2019,6,30),]
y = [0,1,3,4,6,5,7,3]
plt.figure(figsize=(9,6))
plt.plot(x2,y)
plt.xticks(rotation=45)
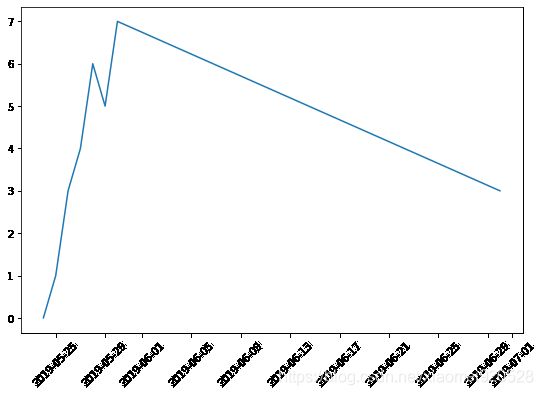
总结: 对比字符串时间数据和Datetime时间数据作为x轴绘制图形,可以发现前者只是将时间作为一个样例,忽略了时间的连续性,而后者证实体现了时间连续性,在绘制图形上没有忽略中间缺失的时间。
plt.plot_date(x2,y2, linestyle='solid')
plt.gcf().autofmt_xdate() #相当于plt.xticks(rotation=45)
date_format = mpl_dates.DateFormatter('%b,%d %Y') #设置时间格式
plt.gca().xaxis.set_major_formatter(date_format) #设置x轴的时间格式
实战
遇到字符串格式的时间,要先转化为时间序列,因为字符串不会按时间排序,所以要排下序。
df.Date= pd.to_datetime(df.Date) #时间类型转化
df.sort_values('Date',inplace=True) #时间排序
plt.plot_date(df.Date,df.Close, linestyle='solid')
plt.gcf().autofmt_xdate()
date_format = mpl_dates.DateFormatter('%b,%d %Y')
plt.gca().xaxis.set_major_formatter(date_format)
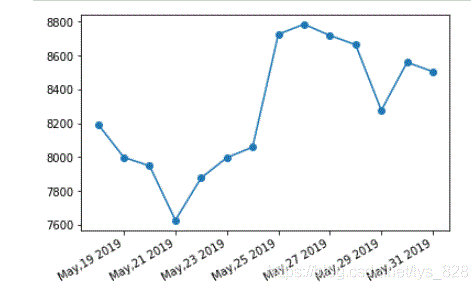
第九节 实时数据可视化(不太明白实用性,提问课问问)
实时数据绘制以及模块调用
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import HTML
from itertools import count
import random
from matplotlib.animation import FuncAnimation
x1=[]
y1=[]
index =count()
def animate(i):
x1.append(next(index))
y1.append(random.randint(0,10))
plt.cla()
plt.plot(x1,y1)
plt.style.use('fivethirtyeight')
ani = FuncAnimation(plt.gcf(),animate,interval=1000)
HTML(ani.to_jshtml())
第十节 图表的多重绘制(subplot)
plt.plot(data.Age,data.All_Devs)
plt.plot(data.Age,data.Python)
plt.plot(data.Age,data.JavaScript)
plt.legend(labels=['All_Devs','Python','JavaScript'])
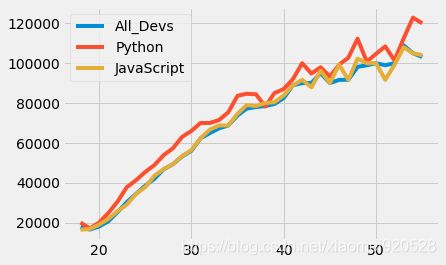
之前的代码都是一张图中绘制多条线,那怎么在一张图中绘制3份线呢?
第一种方式:plt.subplots()绘制子图
fig ,(ax1,ax2,ax3) = plt.subplots(nrows=1,ncols=3,figsize=(12,6),sharey=True)
ax1.plot(data.Age,data.All_Devs,c='r',label='All_Devs')
ax2.plot(data.Age,data.Python,c='g',label='Python')
ax3.plot(data.Age,data.JavaScript,c='b',label='JavaScript')
# a.legend(labels=['All_Devs','Python','JavaScript'])
ax1.legend()
ax2.legend()
ax3.legend()
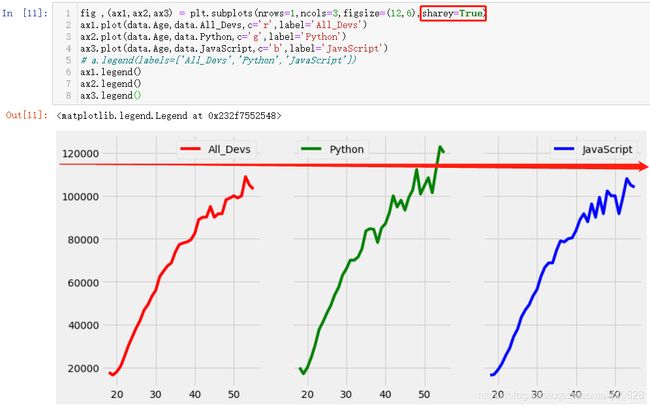
注意:
- plt.figure(figsize=(9,9))在多重绘制图标中已失效,用plt.subplots(figsize=(12,6))
- 要想三份图表的y坐标轴一样的刻度,需要添加,sharey=True命令。
绘图的风格可以自行进行切换,前面已经介绍过如何使用内置的一些绘图风格,比如切换成为seaborn,排列的方式变成1行3列(这里默认就是已经x轴刻度范围一致,也就不用指定sharex参数,其它样式的出图也可以试试,找个自己倾向的即可)
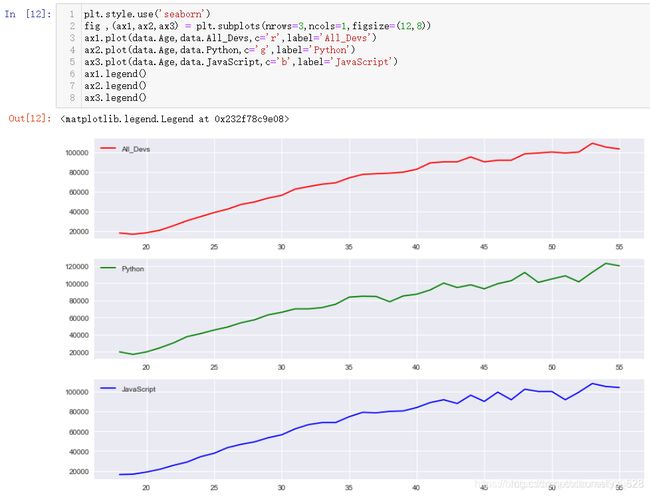
第二种方式:fig.add_subplot 绘制子图
fig = plt.figure(figsize=(12,6))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(212)
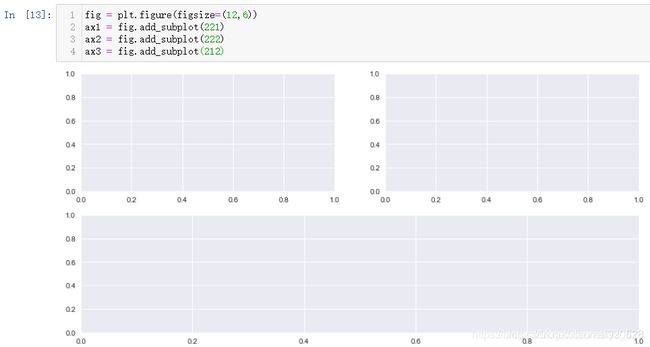
既然fig是实例化的对象,直接可以使用它调用显示图例的函数,但是最终得效果是把所有的图例放在了一起,如果要单独显示图例还是需要单端使用ax进行指定
fig = plt.figure(figsize=(12,6))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(212)
ax1.plot(data.Age,data.All_Devs,c='r',label='All_Devs')
ax2.plot(data.Age,data.Python,c='g',label='Python')
ax3.plot(data.Age,data.JavaScript,c='b',label='JavaScript')
# a.legend(labels=['All_Devs','Python','JavaScript'])
ax1.legend()
ax2.legend()
ax3.legend()
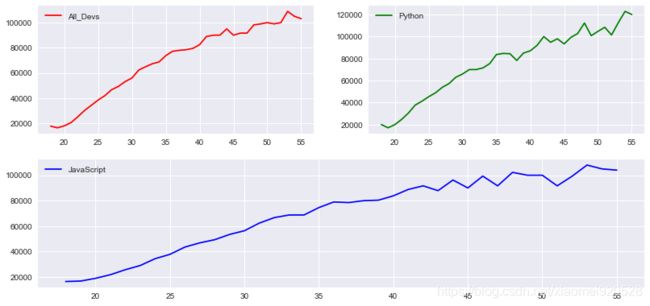
**注意:**这时候就没有前面的函数的共享x轴或者y轴的参数,这种方法的使用主要在于位置布局上有优势
第三种方式 plt.subplot2grid 绘制子图
第二种的坐标易混
fig = plt.figure(figsize=(12,6))
ax1 = plt.subplot2grid((6,2),(0,0),rowspan=2,colspan=1)
ax2 = plt.subplot2grid((6,2),(0,1),rowspan=2,colspan=1)
ax3 = plt.subplot2grid((6,2),(2,0),rowspan=1,colspan=2)
ax4 = plt.subplot2grid((6,2),(4,0),rowspan=2,colspan=1)
ax5 = plt.subplot2grid((6,2),(4,1),rowspan=2,colspan=1)
ax1.plot(data.Age,data.All_Devs,label='All')
ax2.plot(data.Age,data.Python,label='Python',color='g')
ax3.plot(data.Age,data.JavaScript,label='JS',color='r')
ax4.plot(data.Age,data.Python,label='Python',color='g')
ax5.plot(data.Age,data.JavaScript,label='JS',color='r')
ax1.legend()
ax2.legend()
ax3.legend()
函数中的第一个参数(6,2)是指定要绘制的图形行和列,共6行2列;第二个参数就是图形绘制的起始位置,比如(0,0),代表第0行第0列的位置;第3,4个参数rowspan,colspan就是图形跨过的行和列的数量,比如rowspan=2,colspan=1代表图形跨2行,只占1列。ax3绘制的图形解析:绘制的图像都是在6行2列的画布上,起始点在第2行第0列,然后跨1行跨2列
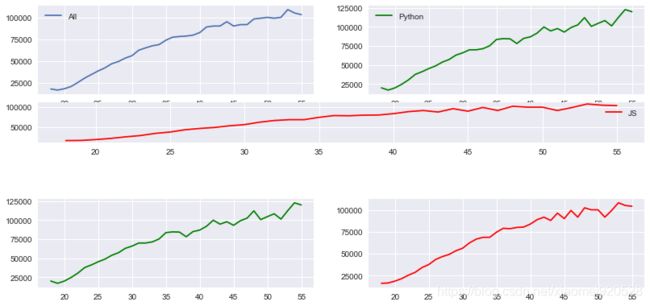
注意: 上图发现第3个图像把上面第1,2图像的x轴刻度信息覆盖了,这种可以尝试通过指定画布大小进行解决,输出如下(比如指定figsize=(12,10),也就是增加一下图形的高度,自然在纵向上就拥挤了。
附官网网址
Matplotlib官方示例图库
撒花,待更新、、、、、