人工智能实践Tensorflow2.0 第五章--3.八股法搭建AlexNet网络--北京大学慕课
第五章–卷积神经网络基础–八股法搭建AlexNet网络
本讲目标:
介绍八股法搭建AlexNet网络的流程。参考视频。
卷积神经网络基础
- 1.AlexNet网络介绍
-
- 1.1-网络分析
- 1.2-卷积层搭建
- 2.AlexNet网络搭建
-
- 2.1六步法回顾
- 2.2完整代码
- 2.3输出结果
1.AlexNet网络介绍
1.1-网络分析
AlexNet网络诞生于2012年,当年ImageNet竞赛的冠军,Top5错误率为16.4%
借鉴点:使用了Relu激活函数,提升训练速度;使用了Dropout, 防止过拟合。使用了图像增强,使得样本量增加。
AlexNet的总体结构和LeNet5有相似之处,但是有一些很重要的改进:
- 由五层卷积、三层全连接层组成,输入图像尺寸为224x224x3,网络规模远大于LeNet5
- 使用了Relu激活函数
- 进行了舍弃(Dropout)操作,防止模型过拟合,提升鲁棒性
- 增加了一些训练上的技巧,包括数据增强、学习率衰减、权重衰减(L2正则化)等。
AlexNet的网络结构如下图所示:

卷积就是特征提取器:CBAPB
特征提取器(卷积层):
C1:
C(核:96x3x3,步长:1,填充:valid)
B(LRN/BN)原文用LRN进行标准化,我们用BN标准化
A(relu)
P(max,核:3x3,步长:2)
D(None)
C2:
C(核:256x3x3,步长:1,填充:valid)
B (LRN/BN)原文用LRN进行标准化,我们用BN标准化
A(relu)
P(max,核:3x3,步长:2)
D(None)
C3:
C(核:384x3x3,步长:1,填充:same)
B(None)
A(relu)
P(None)
D(None)
C4:
C(核:384x3x3,步长:1,填充:same)
B(None)
A(relu)
P(None)
D(None)
C5:
C(核:256x3x3,步长:1,填充:same)
B(None)
A(relu)
P(max,核:3x3,步长:2)
D(None)
分类器(全连接层):
D1:
Dense(神经元:2048,激活:relu,Dropout:0.5)
D2:
Dense(神经元:2048,激活:relu,Dropout:0.5)
D3:
Dense(神经元: 10,激活:softmax)
1.2-卷积层搭建
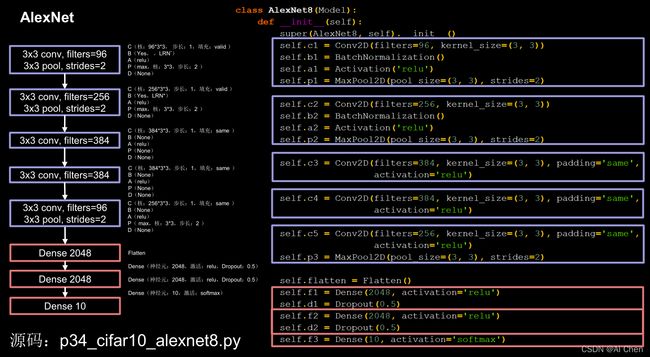
上图中,紫色的部分为卷积层(即特征提取器CBAPD),红色为全连接层(即分类器)。可以看到,与结构类似的 LeNet5 相比,AlexNet 模型的参数量有了非常明显的提升,卷积运算的层数也更多了,这有利于更好地提取特征;Relu 激活函数的使用加快了模型的训练速度;Dropout 的使用提升了模型的鲁棒性,这些优势使得 AlexNet 的性能大大提升。
2.AlexNet网络搭建
2.1六步法回顾
import
train,test
model=tf.keras.Sequantial()/ class
model.compile
model.fit
model.summary
2.2完整代码
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/AlexNet8.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
2.3输出结果
Epoch 1/5
2022-03-05 20:52:20.740566: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2022-03-05 20:52:20.926925: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2022-03-05 20:52:21.542291: W tensorflow/stream_executor/gpu/asm_compiler.cc:81] Running ptxas --version returned 256
2022-03-05 20:52:21.569444: W tensorflow/stream_executor/gpu/redzone_allocator.cc:314] Internal: ptxas exited with non-zero error code 256, output:
Relying on driver to perform ptx compilation.
Modify $PATH to customize ptxas location.
This message will be only logged once.
1563/1563 [==============================] - 18s 12ms/step - loss: 1.0037 - sparse_categorical_accuracy: 0.6526 - val_loss: 1.0097 - val_sparse_categorical_accuracy: 0.6555
Epoch 2/5
1563/1563 [==============================] - 13s 8ms/step - loss: 0.9603 - sparse_categorical_accuracy: 0.6715 - val_loss: 1.1345 - val_sparse_categorical_accuracy: 0.6125
Epoch 3/5
1563/1563 [==============================] - 13s 8ms/step - loss: 0.9086 - sparse_categorical_accuracy: 0.6874 - val_loss: 0.9535 - val_sparse_categorical_accuracy: 0.6780
Epoch 4/5
1563/1563 [==============================] - 13s 8ms/step - loss: 0.8701 - sparse_categorical_accuracy: 0.7035 - val_loss: 1.0130 - val_sparse_categorical_accuracy: 0.6560
Epoch 5/5
1563/1563 [==============================] - 13s 8ms/step - loss: 0.8372 - sparse_categorical_accuracy: 0.7153 - val_loss: 0.9217 - val_sparse_categorical_accuracy: 0.6854
Model: "alex_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 2688
_________________________________________________________________
batch_normalization (BatchNo multiple 384
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
conv2d_1 (Conv2D) multiple 221440
_________________________________________________________________
batch_normalization_1 (Batch multiple 1024
_________________________________________________________________
activation_1 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 multiple 0
_________________________________________________________________
conv2d_2 (Conv2D) multiple 885120
_________________________________________________________________
conv2d_3 (Conv2D) multiple 1327488
_________________________________________________________________
conv2d_4 (Conv2D) multiple 884992
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 multiple 0
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dense (Dense) multiple 2099200
_________________________________________________________________
dropout (Dropout) multiple 0
_________________________________________________________________
dense_1 (Dense) multiple 4196352
_________________________________________________________________
dropout_1 (Dropout) multiple 0
_________________________________________________________________
dense_2 (Dense) multiple 20490
=================================================================
Total params: 9,639,178
Trainable params: 9,638,474
Non-trainable params: 704
_________________________________________________________________
