Pytorch动态神经网络学习记录
课程名:《Pytorch 动态神经网络》
课程来源:here
作者:莫烦
目录
-
- 课程名:《Pytorch 动态神经网络》
- day01 安装Pytorch
- day02
-
- 一、神经网络简介
- 二、why Pytorch?
- 三、Variable变量
- day 03
-
- 一、激励函数(Activation)
- 二、Regression回归
- 三、 Classification 分类
- 四、快速搭建网络
- 五、网络的保存和提取
- 六、批数据训练(mini_batch training)
- day 04
-
- 一、优化器Optimizer加速神经网络训练(深度学习)
- 二、Opttimizer优化器
- 三、 卷积神经网络(CNN)
- 四、什么是LSTM循环卷积网络(RNN)
- 五、自编码/非监督学习(Autoencoder)
- 六、GAN—生成对抗网络
- 七、为什么Torch是动态的(待补充)
- 八、GPU加速
- day 05
-
- 一、过拟合(Overfitting)
- 二、批标准化(Batch Normalization)
day01 安装Pytorch
前提:安装Anaconda参考别人的安装教程https://www.jianshu.com/p/742dc4d8f4c5
- 在开始菜单找到Anaconda的命令提示行(Anaconda Prompt),并输入conda create -n pytorch python=3.7(我自己的是3.7版本),建立一个Pytorch的环境:

- 然后,出现以下情况,问是否安装等等工具包,选择[y]开始安装:

- 安装成功以后,会出现如下,就是激活环境的语句:

- 输入conda activate pytorch进入pytorch环境:

- 输入pip list可以查看这个环境下的工具包,可以看到没有需要的pytorch,所以需要安装:

- 去官网查看自己适合哪个版本,比如我的是CPU,习惯用pip,如下图:

pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://download.pytorch.org/whl/torch_stable.html- 完了以后,在pytorch环境中进入>>python,测试一下是否安装成功,输入import torch即可。
day02
一、神经网络简介
1、 机器学习—梯度下降机制(optimization)
2、神经网络黑盒:输入端-黑盒-输出端;
黑盒:特征代表输入数据。
二、why Pytorch?
1、与tensorflow的区别
- tensorflow是静态的框架,构建好tensorflow的计算图之后,这个计算图是不能改变的,计算流程是固定的,类似C++,写代码时要用他自己的一些API。缺点之一例如训练的时候loss一直将不下来,模型很难得到优化,debug就很困难。
- pytorch是动态的框架,和python一样,直接计算,不用开启会话。
三、Variable变量
- 在 Torch 中的 Variable 就是一个存放会变化的值的地理位置,里面的值会不停的变化,就像一个裝鸡蛋的篮子,鸡蛋数会不停变动。那里面的鸡蛋就是 Torch 的 Tensor 。
- PyTorch采用动态图设计,可以很方便地查看中间层的输出,动态的设计计算图结构。
- from torch.autograd import Variable
ten=torch.FloatTensor([[1,2],[3,4]]) # tensor的类型 variable=Variable(tensor,requires_grad=True) # 将tensor传给variable,需要Variable来建立一个计算图纸,把鸡蛋放到篮子里, requires_grad是参不参与误差反向传播, 要不要计算梯度,如果要就会计算Variable节点的梯度 t_out = torch.mean(ten*ten) # 计算x^2 v_out = torch.mean(variable*variable) v_out.backward() # v_outbackward时,variable也会变化,因为是一体的 print(variable) #直接print(variable)只会输出 Variable 形式的数据, 在很多时候是用不了的(比如想要用 plt 画图),所以我们要转换一下, 将它变成 tensor 形式 print(variable.data) print(variable.data.numpy())# variable.data为tensor的形式,tensor才能转换为numpy形式 - autograd根据用户对Variable的操作构建其计算图,这个图将所有的计算步骤 (节点) 都连接起来,最后进行误差反向传递的时候, 一次性将所有 variable 里面的修改幅度 (梯度) 都计算出来, 而 tensor 就没有这个能力。
- variable默认是不需要求导的,即requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。
- 多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需指定retain_graph=True来保存这些缓存。
- variable的grad与data形状一致,应避免直接修改variable.data,因为对data的直接操作无法利用autograd进行反向传播。
day 03
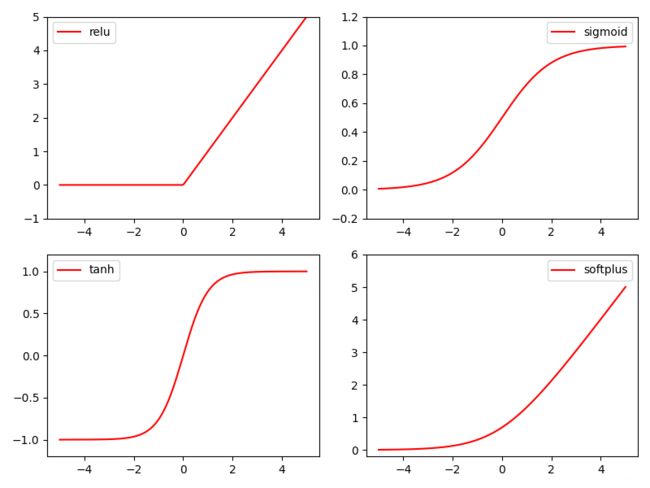
一、激励函数(Activation)
-
什么是Activation
非线性的函数激活网络的输出:ReLU、Sigmoid、Tanh、Softplus -
Torch中的激励函数
import torch.nn.functional as F from torch.autograd import Variable import matplotlib.pyplot as plt x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(100, 1) x = Variable(x) x_np = x.data.numpy() # numpy 数据才能用来画图 y_relu = torch.relu(x).data.numpy() y_sigmoid = torch.sigmoid(x).data.numpy() y_tanh = torch.tanh(x).data.numpy() # 计算出非线性函数输出后也要转化为numpy数据 # y_softplus = F.softplus(x).data.numpy() #画图 plt.figure(1, figsize=(8, 6)) plt.subplot(221) plt.plot(x_np, y_relu, c='red', label='relu') plt.ylim((-1, 5)) plt.legend(loc='best') -
结果
二、Regression回归
直接放莫老师教的代码过来:
-
Layer图搭建以及计算流程
class Net(torch.nn.Module): # torch.nn.Module是Net的主模块 def __init__(self, n_feature, n_hidden, n_output): # 搭建层所需要的信息 super(Net, self).__init__() # 继承Net的模块功能 self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer self.predict = torch.nn.Linear(n_hidden, n_output) # output layer def forward(self, x): # 前向传递的过程,搭流程图 x = F.relu(self.hidden(x)) # activation function for hidden layer x = self.predict(x) # linear output return x
-
定义Net
net = Net(n_feature=1, n_hidden=10, n_output=1) # define
-
优化神经网络(torch.optim.),以及loss function定义
optimizer = torch.optim.SGD(net.parameters(), lr=0.2) loss_func = torch.nn.MSELoss() # 均方差作为loss -
开始训练
for t in range(200): prediction = net(x) # input x and predict based on x loss = loss_func(prediction, y) # must be (1. nn output, 2. target) optimizer.zero_grad() # clear gradients for next train loss.backward() # backpropagation, compute gradients optimizer.step() # apply gradients # 以上三步为优化步骤
三、 Classification 分类
与上面不同的是:
-
构造的伪数据不一样,是包含有对应标签的数据;(数据不能是一维)
-
网络输入输出不同,有两个输入两个输出;
-
loss用到的是交叉熵cross entropy loss,out与标签y
loss_func = torch.nn.CrossEntropyLoss() loss = loss_func(out, y) -
output是取值,转换成概率值需要加softmax(out)
out = net(x) # input x and predict based on x prediction = F.softmax(out) #将输出对应值转化成概率
四、快速搭建网络
-
method1—搭建网络、流程图,定义网络
class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output): super(Net, self).__init__() self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer self.predict = torch.nn.Linear(n_hidden, n_output) # output layer def forward(self, x): x = F.relu(self.hidden(x)) # activation function for hidden layer x = self.predict(x) # linear output return x net1 = Net(n_feature=2, n_hidden=10, n_output=2) -
method2—利用torch.nn.Sequential直接定义网络
net2=torch.nn.Sequential( torch.nn.Linear(2,10), torch.nn.ReLU(), torch.nn.Linear(10,2) )
五、网络的保存和提取
-
方法1:保存—提取
torch.save(net1, 'net.pkl') # 保存整个网络,以pkl形式保存net2 = torch.load('net.pkl') prediction = net2(x) -
方法2:保存—提取
torch.save(net1.state_dict(), 'net_params.pkl') # 只保存网络中节点的参数 (速度快, 占内存少)net3 = torch.nn.Sequential( torch.nn.Linear(1, 10), torch.nn.ReLU(), torch.nn.Linear(10, 1) ) net3.load_state_dict(torch.load('net_params.pkl')) prediction = net3(x)
六、批数据训练(mini_batch training)
-
将数据分批训练,一个epoch训练所有批次的数据:
import torch.utils.data as Data BATCH_SIZE = 5 # 抽取训练的数据 # BATCH_SIZE = 8 x = torch.linspace(1, 10, 10) # this is x data (torch tensor) y = torch.linspace(10, 1, 10) # this is y data (torch tensor) torch_dataset = Data.TensorDataset(data_tensor = x, target_tensor = y) loader = Data.DataLoader( dataset=torch_dataset, # torch TensorDataset format batch_size=BATCH_SIZE, # mini batch size shuffle=True, # random shuffle for training num_workers=2, # 多线程来读数据 ) for epoch in range(3): # 训练所有!整套!数据 3 次 for step, (batch_x, batch_y) in enumerate(loader): # 每一步 loader 释放一小批数据用来学习 # 假设这里就是你训练的地方... # 打出来一些数据 print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy()) -
DataLoader
是PyTorch中数据读取的接口,PyTorch训练模型基本都会用到该接口,其目的:将dataset根据batch_size大小、shuffle等封装成一个Batch Size大小的Tensor,用于后面的训练。 -
enumerate()函数
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。在这里就是把是个数据分成size为5的两份数据后,将每一份数据对应的下标给step,数据给(batch_x, batch_y)。
day 04
一、优化器Optimizer加速神经网络训练(深度学习)
- 数据分批送入网络,进行SGD优化;
- Momentum更新参数方法: m = b 1 ∗ m − L e a r n i n g r a t e ∗ d x , W + = m m=b1*m-Learningrate*dx,W+=m m=b1∗m−Learningrate∗dx,W+=m
- AdaGrad: v + = d x 2 , W + = − L e a r n i n g r a t e ∗ d x / v v+=dx^2,W+=-Learning rate*dx/\sqrt v v+=dx2,W+=−Learningrate∗dx/v
- RMSProp方法(上述两种的合并): v = b 1 ∗ v + ( 1 − b 1 ) ∗ d x 2 , W + = − L e a r n i n g r a t e ∗ d x / v v=b1*v+(1-b1)*dx^2,W+=-Learning_rate*dx/\sqrt v v=b1∗v+(1−b1)∗dx2,W+=−Learningrate∗dx/v
- Adam: m = b 1 ∗ m + ( 1 − b 1 ) ∗ d x m = b1*m+(1-b1)*dx m=b1∗m+(1−b1)∗dx——>Momentum
v = b 2 ∗ v + ( 1 − b 2 ) ∗ d x 2 v = b2*v+(1-b2)*dx^2 v=b2∗v+(1−b2)∗dx2——>AdaGrad
W + = − L e a r n i n g r a t e ∗ m / v W+=-Learning_rate*m/\sqrt v W+=−Learningrate∗m/v
二、Opttimizer优化器
- 几种常见优化器:
# different optimizers opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR) opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8) opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9) opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99)) optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]

从图中可以看出,目前性能最优的应该是Adam。
三、 卷积神经网络(CNN)
图像处理中,不是对每个像素点卷积处理,而是对一小块区域进行计算,这样加强了图像信息的连续性,使得神经网络能看到图片信息而非一个点,同时加深了神经网络对图片的理解。批量过滤器每次对图像收集一小块信息,最后将这些整理出来得到边缘信息,再对这些信息进行类似的处理,得到更高层的信息结构(例如眼睛、鼻子等),最后把总结出来的信息套入几层full connection进行分类等操作。卷积操作时,神经层会丢失一些信息,池化层可以将Layer中有用的信息筛选出来给下一层,因此图片的长宽不断压缩,压缩的工作是池化层进行的。
1、import需要的工具包和库:torch、torchvision、torch.nn、torch.utils.data
2、超参数:EPOCH、BATCH_SIZE、LR
3、下载mnist数据集:torchvision.datasets.MNIST(root='./mnist/',train=True,transform=torchvision.transform.ToTensor(),download=True)
#root是保存或提取的位置,transform是将数据集PIL.Image or numpy.ndarray转换成torch.FloatTensor(C×H×W),训练的时候normalize成[0,1]间的值
test数据集处理:test—_x,test_y
4、批训练train_loader定义:Data.DataLoader(dataset=train_data,batch_size=BATCH_SIZE,shuffle=True)
5、定义网络构架CNN(nn.Module):conv1—conv2—RELU—pooling—conv2—ReLU—pooling—output
网络计算流程:conv1(x)——conv2(x)——展平多维卷积图——计算输出
6、定义optimizer和loss function
7、训练和测试
四、什么是LSTM循环卷积网络(RNN)
- LSTM(Long Short-Term Memory)——长短期记忆
- RNN是在有序的数据上进行学习
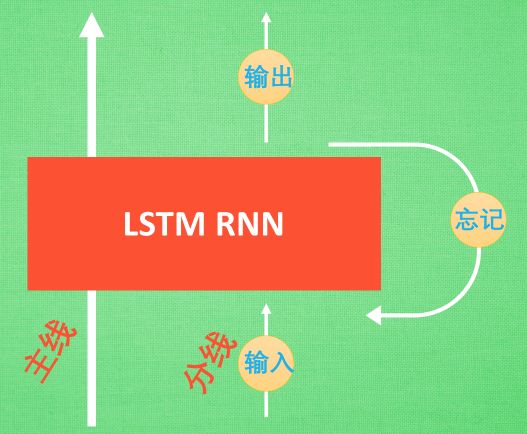
- 分类问题(mnist数据集)
我们将图片数据看成一个时间上的连续数据, 每一行的像素点都是这个时刻的输入, 读完整张图片就是从上而下的读完了每行的像素点。然后我们就可以拿出 RNN 在最后一步的分析值判断图片是哪一类了。(再补充) - 回归问题
这部分内容参考KiKi的另一篇blog,包括分类问题和回归问题的pytorch实现。
五、自编码/非监督学习(Autoencoder)
原来有时神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作。 所以, 何不压缩一下, 提取出原图片中的最具代表性的信息, 缩减输入信息量, 再把缩减过后的信息放进神经网络学习,这样学习起来就简单轻松了。 训练好的自编码中间这一部分就是能总结原数据的精髓,我们只用到了输入数据 X, 并没有用到 X 对应的数据标签, 所以也可以说自编码是一种非监督学习。到了真正使用自编码的时候,通常只会用到自编码前半部分。(摘自莫烦python)
-
代码
self.encoder = nn.Sequential( nn.Linear(28*28, 128), nn.Tanh(), nn.Linear(128, 64), nn.Tanh(), nn.Linear(64, 12), nn.Tanh(), nn.Linear(12, 3), # compress to 3 features which can be visualized in plt ) self.decoder = nn.Sequential( nn.Linear(3, 12), nn.Tanh(), nn.Linear(12, 64), nn.Tanh(), nn.Linear(64, 128), nn.Tanh(), nn.Linear(128, 28*28), nn.Sigmoid(), # compress to a range (0, 1) ) def forward(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return encoded, decoded autoencoder = AutoEncoder()
六、GAN—生成对抗网络
(原理已经学习过了,直接上代码)
-
pytorch中实现:(代码中的对象不是图像,用到的是二次曲线)
-
超参数
BATCH_SIZE = 64 LR_G = 0.0001 # 生成器的学习率 LR_D = 0.0001 # 判别器的学习率 N_IDEAS = 5 # random_noise的个数 ART_COMPONENTS = 15 # 定义规格,一条曲线上有多少个点 PAINT_POINTS = np.vstack([np.linspace(-1,1,ART_COMPONENTS)for _ in range(BATCH_SIZE)]) # 规定整批画的点,从-1到1共15个点 -
没有train data,自己伪造一些real data
def artist_works(): # painting from the famous artist (real target) a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis] # 二次曲线的系数 paintings = a * np.power(PAINT_POINTS, 2) + (a-1) # 二次曲线的参数,区间表示upper和 paintings = torch.from_numpy(paintings).float() return paintings -
定义生成器和判别器
G = nn.Sequential( # Generator nn.Linear(N_IDEAS, 128), # random ideas (could from normal distribution) nn.ReLU(), nn.Linear(128, ART_COMPONENTS), # making a painting from these random ideas ) D = nn.Sequential( # Discriminator nn.Linear(ART_COMPONENTS, 128), # receive art work either from the famous artist or a newbie like G nn.ReLU(), nn.Linear(128, 1), nn.Sigmoid(), # tell the probability that the art work is made by artist ) -
优化器
opt_D = torch.optim.Adam(D.parameters(), lr=LR_D) opt_G = torch.optim.Adam(G.parameters(), lr=LR_G) -
训练啦
for step in range(10000): artist_paintings = artist_works() # real painting from artist G_ideas = torch.randn(BATCH_SIZE, N_IDEAS) # random ideas G_paintings = G(G_ideas) # fake painting from G (random ideas) prob_artist0 = D(artist_paintings) # D try to increase this prob prob_artist1 = D(G_paintings) # D try to reduce this prob D_loss = - torch.mean(torch.log(prob_artist0) + torch.log(1. - prob_artist1)) G_loss = torch.mean(torch.log(1. - prob_artist1)) opt_D.zero_grad() D_loss.backward(retain_graph=True) # reusing computational graph opt_D.step() opt_G.zero_grad() G_loss.backward() opt_G.step()
-
补充: cGAN与GAN的区别在于多了一个类别标签,这个label会跟随noise一起输入到生成器中,并且也要跟随fake和real一起输入到判别其中,最终计算各自的loss。
七、为什么Torch是动态的(待补充)
例子:RNN网络
Tensorflow就是预先定义好要做的task的框架、步骤,然后开启会话之后喂数据一步到位的计算出结果,开启会话后便不能修改网络构架了,只能是照着计算流图跟着计算,所以是静态的;Torch也可以先定义好框架然后套进去,但计算的时候无论网络怎么变化每一个叶子节点的梯度都能给出,tensorflow就做不到这一点,并且torch是边给出计算图纸一边进行训练。torch就像是散装的一样,可以一块一块的制作好并进行计算,比较灵活,所以是动态的。
八、GPU加速
以之前CNN为例,对其代码进行修改
-
dataset部分
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor).cuda()/255. # Tensor on GPU test_y = test_data.test_labels.cuda() -
CNN网络的参数改为GPU兼容形式
class CNN(nn.Module): ... cnn = CNN() ##########转换cnn到CUDA######### cnn.cuda() # Moves all model parameters and buffers to the GPU. -
training data变成GPU形式
for epoch ..: for step, ...: ##########修改1########### b_x = x.cuda() # Tensor on GPU b_y = y.cuda() # Tensor on GPU ... if step % 50 == 0: test_output = cnn(test_x) # !!!!!!!! 修改2 !!!!!!!!! # pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze() # 将操作放去 GPU accuracy = torch.sum(pred_y == test_y) / test_y.size(0) ... test_output = cnn(test_x[:10]) # !!!!!!!! 修改3 !!!!!!!!! # pred_y = torch.max(test_output, 1)[1].cuda().data.squeeze() # 将操作放去 GPU ... print(test_y[:10], 'real number')
day 05
一、过拟合(Overfitting)
-
过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。模型在训练集上效果好,然而在测试集上效果差,模型泛化能力差。
-
原因
1)在对模型进行训练时,有可能遇到训练数据不够,即训练数据无法对整个数据的分布进行估计的时候;
2)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。 -
解决方法
方法一: 增加数据量。
方法二:运用正规化,L1、 L2 regularization等等。(神经网络的正规化方法dropout——就是在训练的时候, 随机忽略掉一些神经元和神经联结 , 使这个神经网络变得”不完整”,用这个不完整的神经网络训练一次。第二次再随机忽略另一些, 变成另一个不完整的神经网络。有了这些随机 drop 掉的规则, 我们可以想象每次训练的时候, 让每一次预测结果不会依赖于其中某部分特定的神经元。像l1, l2正规化一样, 过度依赖的 W , 也就是训练参数的数值会很大, l1, l2会惩罚这些大的 参数,Dropout 的做法是从根本上让神经网络没机会过度依赖。) -
Dropout
# 不加dropout的网络 net_overfitting = torch.nn.Sequential( torch.nn.Linear(1, N_HIDDEN), torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN, N_HIDDEN), torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN, 1), ) # 加上dropout net_dropped = torch.nn.Sequential( torch.nn.Linear(1, N_HIDDEN), torch.nn.Dropout(0.5), # drop 50% of the neuron torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN, N_HIDDEN), torch.nn.Dropout(0.5), # drop 50% of the neuron torch.nn.ReLU(), torch.nn.Linear(N_HIDDEN, 1), ) #除了网络构架不同外,其他大同小异。
二、批标准化(Batch Normalization)
-
什么是批标准化
Batch Normalization(BN), 批标准化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法。 具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律。数据随着神经网络的传递计算,激活函数的存在会造成网络层对数据的不敏感,比如0.1和2经过Tanh函数后,前者仍0.1,而2变成1,那这样再大的数都会变成1,所以神经层对数据失去了感觉,这样的问题同样存在于隐藏层中,所以BN则是用在这些神经层中优化网络的方法。
Batch就是数据分批处理,每一批数据前向传递的过程中,每一层都进行BN处理,添加在层和激励函数之间。反BN: B N ( γ , β ) ( x i ) BN_(\gamma,\beta)(x_i) BN(γ,β)(xi)是将 normalize 后的数据再扩展和平移,是为了让神经网络自己去学着使用和修改这个扩展参数 γ \gamma γ, 和 平移参数 β \beta β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 γ \gamma γ和 β \beta β来抵消一些 normalization 的操作。 -
代码
莫烦BN_code
~~~~~~~~完结撒花###########
部分内容待学习