阿里云视频云视频编码与增强技术团队最新研究成果论文《基于可变形卷积的压缩视频质量增强网络》(Deformable Convolution Dense Network for Compressed Video Quality Enhancement)已被 ICASSP 2022 Image, Video & Multidimensional Signal Processing 主题会议接收,并受邀在今年5月的全球会议上向工业界和学术界进行方案报告。以下为技术成果的核心内容分享。
佳芙|作者
背景
视频压缩算法是一种广泛应用于视频传播和视频存储的技术,它能够帮助节省带宽和节约存储空间,但同时也带来了视频质量下降的问题。压缩视频质量增强任务的目标便是减少由视频压缩带来的 artifacts,提升视频质量。
近些年来,基于多帧策略的方法成为了压缩视频质量增强任务中的主流,为了融合多帧信息,这些方法大多都严重依赖于光流估计,然而不准确且低效率的光流估计算法限制住了增强算法的性能。为了打破光流估计算法的限制,本文提出了一种结合了可变形卷积的稠密残差连接网络结构,这个网络结构无需在显式光流估计的帮助下就能完成从高质量帧到低质量帧的补偿。
利用可变形卷积来实现隐式的运动估计,并通过稠密残差连接来提高模型对误差的容忍度。具体而言,我们所提出的网络结构由两个模块组成,分别是利用可变形卷积来实现隐式估计的运动补偿模块,以及使用稠密残差连接来提高模型误差容忍度和信息保留度的质量增强模块,此外,本文还提出了一个新的边缘增强损失来增强物体边缘结构。在公开数据集上的实验结果表明,该方法显著优于其他 baseline 模型。
方法解析
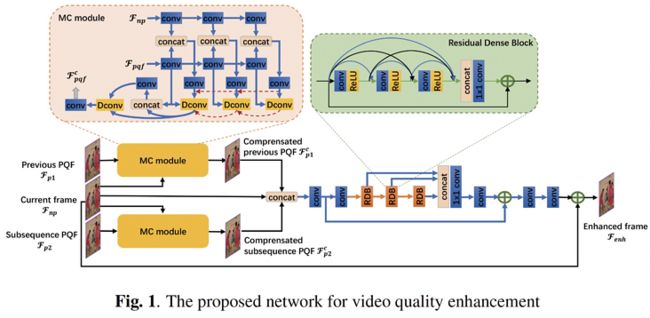
受到 MFQE[1] 的启发,我们的方法也使用了 PQF 来作为参考帧。在 MFQE 中,PQF 被定义为质量高于其前后连续帧的视频帧,而在本文中,使用了 I 帧来作为 PQF,高质量的 PQF 可以为低质量的输入帧提供更准确的信息,从而更大限度地提升视频帧的质量。
图 1 展示了我们的模型结构,其中\( F_{np} \)表示当前帧,\( F_{p1} \)和\( F_{p2} \)分别代表最近的前后 PQF,MC module 代表运动补偿模块,后方的多个密集残差块和卷积层组成了质量增强模块。
将 PQF( \( F_{p1} \) 或 \( F_{p2} \) )作为参考帧,运动补偿模块中的可变形卷积层可为其预测时序运动信息,并将参考帧补偿为输入帧的内容,此时的补偿帧\( {F}^{c}_{p1} \)、\( {F}^{c}_{p2} \)同时具有和输入帧\( F_{np} \)相似的内容以及和参考帧\( F_{p1} \)、\( F_{p2} \)相近的质量。
接着,质量增强模块\( R_{\theta_{qe}} \)将融合多个参考帧的信息,最终输出一个增强帧\( F_{enh} \)。
$$ F_{enh}=F_{np}+R_{\theta_{qe}}(\left [ F^{^{c } }_{p1},F _{np} ,F^{c}_{p2} \right ] ) $$
此外,考虑到 artifacts 通常出现在物体边缘附近,我们针对性地提出了一个边缘增强损失,这个损失可以检测并强调视频帧中的物体边缘\( W \),帮助模型更好地重建被 artifacts 破坏掉的物体轮廓。
$$ L_{e} =\frac{1}{N} \sum_{i=1}^{N}{W} \ast \left ( F_{raw} - F_{enh} \right ) ^{2} $$
实验结果
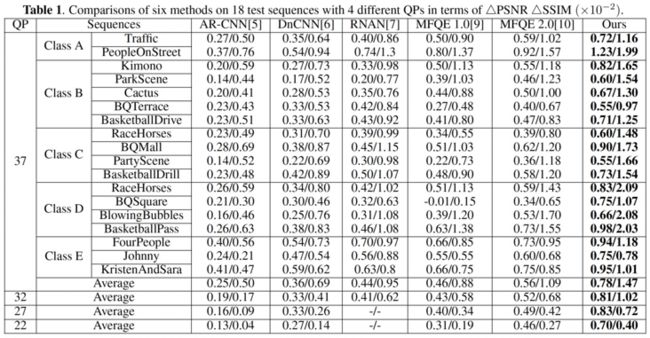
峰值信噪比(PSNR)和结构相似性(SSIM)是最为广泛使用的图像质量评估指标,为了更方便直观地比较算法效果,本文使用了\( \bigtriangleup PSNR \)和\( \bigtriangleup SSIM \),即增强帧相对于输入帧的 PSNR 和 SSIM 的增量来作为评估指标。
将我们的方法与其他 5 个 baseline 模型进行了比较,在 5 个对比方法中,ARCNN[2]、DnCNN[3] 和 RNAN[4] 都是压缩图像质量增强算法,能够独立地对每一个视频帧进行增强,但表现一般。MFQE 1.0 则是一个基于多帧策略和 PQF 的压缩视频质量增强算法,在 MFQE 1.0 的基础上,MFQE 2.0[5] 通过改进 PQF 检测器和质量增强模块来进一步提升了增强效果。从表 1 中可以看出,我们的方法可获得了比其他 5 个方法更高的\( \bigtriangleup PSNR \)和\( \bigtriangleup SSIM \)。特别地,对于 QP=37 的测试序列,我们相对于 MFQE2.0 的性能提升接近是 MFQE2.0 相对于 MFQE1.0 的提升的两倍。
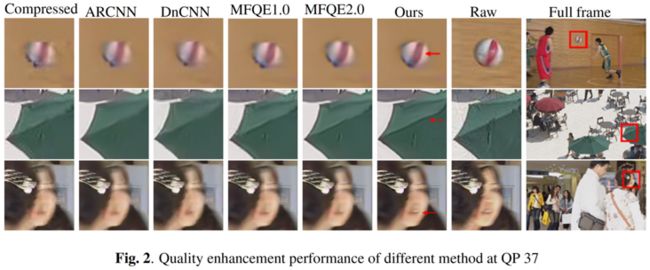
图 2 展示了 5 种方法的主观效果,显然我们所提的方法可以将视频帧的质量提升得更高。以图 2 中的球、伞架和嘴巴为例,我们的方法恢复出了更清晰的物体边缘和更多的细节,这说明对于视频中快速运动的物体,比如球,我们网络中使用的金字塔结构的可变形卷积可以更准确地补偿运动,并且在质量增强模块的高效帮助和边缘增强损失的正确引导下,本文方法在边缘重建和细节补充上获得了更优表现。
基于该技术的深度研发,极大提升了阿里云视频云窄带高清产品对低质量视频的边缘细节修复效果,尤其是在人们比较关注的人脸区域提升效果更加显著,从而为用户提供更好的观看体验,该成果可广泛运用于短视频和直播场景中,如已应用于央视春晚、阿里健康等场景。此外,该项技术对中高质量视频也有很好的视觉提升效果,在同等带宽下,使整体画面变得更加清晰,未来该技术还将广泛应用于更多的场景以提升观看体验。
关于窄带高清
窄带高清是一项基于阿里云独家转码技术的媒体处理功能,采用阿里云独有算法,突破视频编码器能力上限,对转码技术进行升级和迭代,持续优化视频播放的流畅度与清晰度,实现在同等画质下更省流、在同等带宽下更高清的观看体验。窄带高清利用其低码高清、画质重生、场景定制、节省 50% 带宽成本等技术特点,为 2022 年北京“云上冬奥”和阿里云聚“Alibaba Cloud ME”提供了重要技术支撑。(窄带高清产品官网)
参考文献
[1]Ren Yang, Mai Xu, Zulin Wang, and Tianyi Li, “Multiframe quality enhancement for compressed video,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6664–6673.
[2]Chao Dong, Yubin Deng, Chen Change Loy, and Xiaoou Tang, “Compression artifacts reduction by a deep convolutional network,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 576–584.
[3]Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,” IEEE Transactions on Image Processing, vol. 26, no. 7, pp. 3142–3155, 2017.
[4]Yulun Zhang, Kunpeng Li, Kai Li, Bineng Zhong, and Yun Fu, “Residual non-local attention networks for image restoration,” arXiv preprint arXiv:1903.10082, 2019.
[5] Zhenyu Guan, Qunliang Xing, Mai Xu, Ren Yang, Tie Liu, and Zulin Wang, “Mfqe 2.0: A new approach for multi-frame quality enhancement on compressed video,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。