基于深度学习的IRS辅助MIMO通信系统的CSI压缩及恢复研究
基于深度学习的IRS辅助MIMO通信系统的CSI压缩及恢复研究
人工智能技术与咨询

来源:《无线通信 》 ,作者黄富铿等
关键词: 智能反射面;深度学习;信道状态信息反馈;
摘要: 智能反射面(IRS, Intelligent Reflecting Surface)因成本低、功耗低、可提升通信质量等优点被广泛研究。在采用正交频分复用作为多载波调制方案的IRS辅助频分双工多输入多输出(MIMO, Multiple input Multiple Output)通信系统中,为了提升系统的系统增益,用户端(UE, User Equipment)需要将多个信道的信道状态信息(CSI, Channel State Information)通过反馈链路发送至基站端(BS, Base Station)。因此,相比于传统的MIMO系统,该系统中CSI的数据量和反馈开销无疑将会是更加巨大的。针对此问题,本文提出了一种基于注意力机制的深度残差网络IARNet (Inception-Attention-Residual-Net)来对大数据量的CSI进行压缩重建。该网络在传统的Inception网络结构上结合了多卷积特征融合、混合注意力机制以及残差等子模块,这种混合结构可以有效地将大数据量的CSI进行压缩重建。仿真结果表明,与现有的2种深度学习网络相比,IARNet在基于热身法的模型训练方案加持下可以显著提高大数据量CSI的重建质量。
1. 引言
随着5G通信网络进入商业化阶段,为了获得更快和更可靠的数据传输,6G通信技术已经处于研究状态,其中智能反射面(IRS, Intelligent Reflecting Surface)技术因其成本低、易部署、功耗低、可提升通信质量等特点被应用到各种无线通信系统。IRS是一种有大量无源反射单元的表面,该表面的反射单元可以将入射信号进行被动反射,通过调整IRS的反射系数还可以进一步提高反射信号的传输质量。因为IRS十分轻巧,所以人们可以轻易地将其部署在建筑外墙、广告面板和楼顶等地方。在信号反射的过程中,由于IRS除了控制反射单元以外无需消耗额外能量的特点,因此IRS被业界广泛视作为一种绿色、环保以及有前景的技术。基于上述优点,IRS技术很好地契合了现阶段人们对6G的愿景,即智能、融合、绿色 [1] [2] [3] [4] [5]。
深度学习是一种通过构造深层网络自动地提取出数据内在特征和规律的人工智能技术。自从2012年Geoffrey Hinton等人使用深度学习技术并以绝对优势获得了ImageNet图像识别比赛的冠军以来,越来越多的研究者参与对深度学习的研究并取得了巨大进展。最近研究表明,深度学习技术不仅在图像识别领域有杰出表现,而且在自然语言处理和图像压缩等领域也取得了不俗的成绩 [6] - [18]。近年来有很多通信领域的研究者将深度学习技术应用在了通信相关领域,和传统的通信算法相比,深度学习在信道估计、信号检测和CSI (CSI, Channel State Information)反馈等方向上获取了更好的表现。
针对CSI反馈开销过大的问题,文献 [15] 首次提出了使用深度学习技术将CSI进行压缩再重建,并提出了名为CsiNet的深度学习网络。相比于传统压缩感知的方法,CsiNet有更好的重建质量和重建速度。文献 [16] 在CsiNet的基础上引入了Inception模块,提出了多分辨率体系结构的网络:CRNet。相比于CsiNet,CRNet可以在网络参数变化不大的情况下进一步提升重建的质量。文献 [17] 在CsiNet的基础上引入了Dense Block模块,提出了有极致残差模块的网络:DS-NLCsiNet。相比于CsiNet,DS-NLCsiNet进一步提高了重建质量和恢复精读。文献 [18] 在CsiNet基础上引入了量化模块,提出了QuanCsiNet。相比于CsiNet,QuanCsiNet可以进一步压缩反馈的CSI。此外文献 [18] 在训练深度学习网络的时候还使用了基于真实信道的数据集,这进一步表明了基于深度学习的CSI压缩反馈确实是有效的。
但是现有的网络和工作都是在压缩和重建数据量较小的CSI,数据量一般都不超过2048个32位浮点数。在IRS辅助的频分双工(FDD, Frequency Division Duplex)模式下的多输入多输出(MIMO, Multiple input Multiple Output)通信系统中采用正交频分复用(OFDM, Orthogonal Frequency Division Multiplexing)作为多载波的传输方案。该系统中下行链路反馈的CSI不仅包括基站端(BS, Base Station)到用户端(UE, User Equipment)的CSI,还需要包括BS到IRS的CSI以及IRS到UE的CSI,因此该系统的反馈开销将会是更加巨大的,同时使用深度学习将CSI进行压缩和重建的时候数据量也会大大增加。在本系统中压缩和重建的数据量超过了一般工作研究的4倍,达8704个32位浮点数。现有的网络在本系统中对数据量更大的CSI进行压缩重建的时候会出现重建质量低下的问题。因此需要针对数据量更大的CSI设计出一种新的深度学习网络来将CSI压缩和重建,以提升系统的重建质量。
本文针对IRS辅助的通信系统中反馈开销更加巨大的问题提出了一种新的深度学网络IARNet以及基于热身法的模型训练方案 [7]。IARNet在传统卷积神经网络基础上采用了多卷积特征融合、混合注意力机制以及残差等模块。通过仿真发现:与现有的深度学习网络相比,IARNet在基于热身法的模型训练方案加持下可以显著提高CSI重建质量,即使是在较低压缩比下IARNet仍能很好地将CSI恢复出来。本文的贡献总结如下:
1) 研究了在IRS辅助下的MIMO通信系统的CSI压缩及重建问题,并提出了相关系统模型。
2) 针对一般深度学习网络在大数据量CSI压缩重建过程中出现重建质量低下的问题,本文在传统卷积网络的基础上加入了多卷积特征融合、混合注意力机制以及残差等模块,提出了深度学习网络IARNet,实验表明,在基于热身法的模型训练方案加持下可以显著提高CSI重建质量。
3) 进一步研究了基于热身法的学习率调整策略与三种传统的学习率调整策略在1/8压缩比下对网络的性能影响,实验表明:相比于传统方法基于热身法的学习率调整策略可以进一步提高CSI的重建质量,重建质量至少提升24.9%。
2. 系统模型
本文研究IRS辅助下的MIMO FDD通信系统,它采用OFDM作为多载波的传输方案,系统模型如图1所示。
在该系统中,配置有 NiNi 个反射单元的IRS辅助有 NtNt 根天线的BS与有 NrNr 根天线的UE进行通信,而OFDM的子载波数量则设置为 NcNc。那么UE处第 mm 根天线在第 cc 个子载波接收到的信号 ym,cym,c 可以表达为:
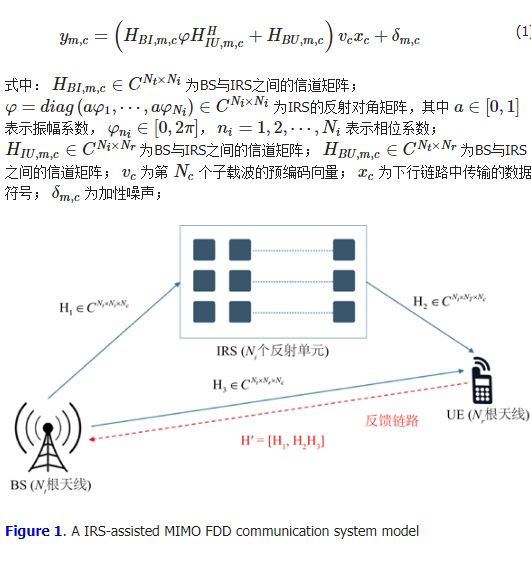
Figure 1. A IRS-assisted MIMO FDD communication system model
图1. IRS辅助下的MIMO FDD通信系统模型
BS需要设计合理的预编码向量 vcvc 才能消除用户间干扰进而提升通信质量。然而在FDD模式下,BS需要获得精确的下行链路CSI才能对路预编码向量进行合理设计。在该系统中,完整维度的下行链路的CSI H′H′ 包括BS到UE信道的CSI H1∈CNt×Ni×NcH1∈CNt×Ni×Nc 、BS到IRS信道的CSI H2∈CNi×Nr×NcH2∈CNi×Nr×Nc 、IRS到UE信道的CSI H3∈CNt×Nr×NcH3∈CNt×Nr×Nc,即 H′=[H1,H2,H3]H′=[H1,H2,H3]。完整的CSI数据如图2所示。
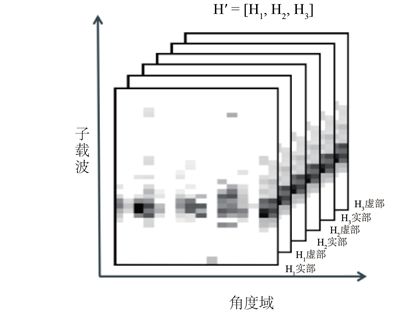
Figure 2. Schematic of the complete CSI data
图2. 完整的CSI数据示意图
因为时延扩展的有限性,CSI中会有大量的0值,所以放入IARNet的CSI矩阵可以将CSI截断并只保留前 N˜cN˜c 行的有效数据,阶段后的CSI可以表示为

本文主要研究深度学习在IRS辅助下通信系统CSI压缩与恢复,因此假设UE已经获得了反馈的所有CSI,即忽略信道估计误差,同时假设BS也能完整地接收到UE反馈的所有信息。
本系统在UE和BS分别设置了编码器和译码器,UE处的编码器可以将原始的 JJ 维的CSI HH 压缩成 KK 维向量 cc,压缩比可以表示为: η=K/Jη=K/J,其中 (K 式中: HˆH^ 表示重建后的CSI矩阵; fdefde 表示译码器; ΘdeΘde 表示译码器的深度学习网络参数。 为了评估本系统的重建质量,本系统使用归一化均方误差(NMSE, Normalized Mean Squared Error)作为判断标准,NMSE可以评估原始CSI与重建后的CSI之间的误差,这个值越小表示系统重建质量越佳,因此本文主要的目标是通过优化系统模型最小化该值。其中NMSE定义为: 式中: ∥⋅∥2‖⋅‖2 表示L2范数。 3. IARNet的结构 本文所提出的IARNet深度学习网络结构如图3所示,其由UE处的编码器和BS处的解码器构成。IARNet的输入是信道CSI HH, HH 的具体尺寸为 128×16×6128×16×6,其中128表示角度,16表示截断后的子载波数,6表示三个CSI的虚数和实数。IARNet的输出是重建后的CSI HˆH^,尺寸和 HH 一致。 Figure 3. Architecture of IARNet 图3. IARNet的架构 在编码器侧。模型首先将 HH 放入混合注意力模块进行特征提取。该模块同时提取了CSI在空间和通道上的数据,经过该模块后深度学习网络可以更专注于信息量大的数据,提升数据权重,反之降低信息量小的数据权重,加强了特征表达能力。然后,将数据放入编码器复合模块处理。该模块主要是借鉴了Inception网络的思想,将多个尺寸卷积后的结果直接进行拼接处理,这可以让拼接后的结果具有多维度特征信息的特点。此外该模块还引入了分组卷积的处理方法以降低训练参数。接着再利用混合注意力模块进行特征提取,进一步加强了特征表达能力。接着,将数据Reshape成长度为 128×16×6=12288128×16×6=12288 的一维向量并将其输入到神经元数量为 8704×η8704×η 的全连接层神经网络中进行压缩,其中8704表示 HH 的有效数据,为了对齐6个通道的尺寸, H′3H′3 需要补0处理,具体见第五章仿真部分。最后,通过反馈链路将压缩后的数据发送给BS端的解码器。 在解码器侧。模型首先将长度为 8704×η8704×η 的一维向量Reshape成 HH 尺寸大小的矩阵。然后,用解码器复合模块将数据进行处理。该模块与编码器复合模块类似,但是更轻量化。其中该模块引入了比例残差的设计,相比一般的残差网络,网络性能更佳。最后,解码器输出重建后的CSI矩阵 HˆH^。 混合注意力模块主要由通道注意力模块和空间注意力模块两部分组成。通道注意力模块中,首先通过两种并行的平面平均池化和平面最大池化的处理,接着再将它们分别送入MLP神经网络之中,最后通过Sigmoid函数输出结果。通过通道注意力模块处理让模型关注到通道之间的关系并自动学习到不同通道特征的重要程度。空间注意力模块中,将通道注意力模块输出的数据作为输入,首先通过两个并行的通道平均池化和通道最大池化处理并将两个处理结果进行通道拼接,然后通过卷积操作将通道降为一维,最后进行Sigmoid激活函数处和残差处理。通过通道注意力模块处理,模型会关注到同一通道上不同数据位置的关系并自动学习到不同空间特征的重要程度。混合注意力模块的结构如图4所示。混合注意力模块的输入为 128×16×6128×16×6 的特征,其中6表示为输入特征通道数;16表示特征的高度即子载波数;128表示特征的宽度即角度; 1×61×6 表示MLP神经网络的神经元个数; ⊗⊗ 表示矩阵乘法; ⊕⊕ 表示矩阵加法; 混合注意力模块同时关注到了通道信息和空间信息的重要关系,增大了有效通道和空间的权重,减少了无效通道和空间的权重,进而提升了网络性能。同时混合注意力模块还可以很轻易地集成到现有的深度学习网络架构上去,输入与输出的特征尺寸完全一致,这让网络的配置更加简单和便捷。 Figure 4. Architecture of hybrid attention module 图4. 混合注意力模块的架构 复合网络模块的结构 编码器复合模块及解码器复合模块如图5所示,其中每个方框附近的小数字表示此步的通道数(卷积核个数),在数据处理的过程中CSI的长宽不变,即保持为 128×16128×16 尺寸的数据,通道数随着卷积核变化。 文献 [15] 中已经证明基于 3×33×3 卷积和残差网络的CsiNet在信道压缩中的应用是有效的。但CsiNet是一种固定卷积尺寸的网络,固定尺寸卷积处理下的网络并不能很好地同时提取稀疏矩阵和密集矩阵的特征。如果想较好地同时提取稀疏矩阵和密集矩阵的特征,就需要考虑同时用不同尺寸卷积处理CSI。小尺寸的卷积处理(如 3×33×3 卷积)可以提取CSI更加精细的特征,在处理密集CSI的时候小尺寸的卷积有更好的效果。大尺寸的卷积处理(如 9×99×9 卷积)可以提供更大的感受视野,在处理稀疏CSI的时候这种卷积有更好的效果。因此在编码器复合模块和解码器复合模块中大量使用了多支路并行的多尺寸卷积处理,然后将不同支路上的结果在通道上直接拼接起来,这样可以将不同尺寸卷积处理下的结果进行多卷积特征融合,让输出拥有更加丰富的特征。特别是在编码器复合模块中,为了更好提取原始CSI的特征,编码器复合模块在中同时使用了 3×33×3 卷积、 5×55×5 卷积、 7×77×7 卷积和残差的并行处理,这将极大地丰富了输出特征。此外,每个卷积模块进行卷积处理前都进行了一次批归一化处理。 Figure 5. Composite module of encoder (left) and decoder (right) 图5. 编码器复合模块(左)及解码器复合模块(右) 为减少复合网络模块中的参数数量和运算复杂度,模型还引入了分组卷积的处理方法。在分组卷积中通过以下步骤来分解 M×MM×M 卷积。首先,设置组数 gg 并将原来的特征通道数平均分解成 gg 组,每个小组的特征通道数为原来的 1/g1/g,每一个小组的卷积核个数也为原来的 1/g1/g,保持长宽不变。然后,每个小组进行 M×MM×M 的卷积计算。最后,将每个小组的结果进行通道拼接,最终输出的特征尺寸不变。而且由于将标准的 M×MM×M 卷积拆分成了更小规模的子运算,这可以大幅度降低运算复杂度,减少设备的运行要求。 此外,为了解决梯度消失的问题,提高系统的性能,复合网络模块还加入了大量的残差网络。特别是在解码器复合模块的末端还利用了比例残差的网络,即将主干的输出乘以一个小于1的系数(本网络采用0.7),调整主干的输出比例。经此设计,IARNet的性能有进一步的提升。 4. 学习率及其调整策略 在深度学习模型的训练过程中,模型训练方案对模型的最终呈现效果有着决定性的影响。在一些基于深度学习的信道压缩反馈研究中,其模型训练方案是相对简要的,没有针对特定的系统模型进一步优化模型训练方案。如在CsiNet和DS-NLCsiNet的文章中,模型的batch size、epochs和初始学习率分别直接设置为200、1000和0.001,也没有设置学习率调整策略。这些文章都省略了对模型训练方案的介绍,特别是学习率及其调整策略上,而这恰恰是十分重要的。 如果学习率设置过高,虽然系统训练会加快,但是在采用梯度下降算法来寻找全局最优解的过程中,损失函数将不会收敛至全局最小值附近。如果学习率设置过小,虽然网络可以寻找到全局最优解,但是这会花费大量的训练时间并且很容易陷入局部最优解。另外学习率调整策略对系统训练也有很大的影响,一般采用的策略有固定法、步衰减法(Step Decay)法以及余弦衰减法(Cosine Decay)等。固定法需要多次试验才能找到较好的学习率,而且网络也很容易陷入局部最优解。衰减类的方法可以在较高的学习率上加速网络训练,然后在低学习率上寻找到全局最优解 [19]。在IARNet的模型训练方案上采用基于热身法的余弦衰减学习率调整策略。由于深度学习网络在刚开始训练的时候非常不稳定,所以我们需要将初始的学习率设置得很低,这可以让深度学习网络缓慢地趋向于稳定。当网络趋于稳定的时候再升高学习率,这可以让网络可以快速地收敛,这个过程就称之为热身,热身完之后将采用余弦衰减的方法减少学习率。这样就可以让整个训练过程变得平稳、快速,同时也提高了网络性能。本方案的学习率调整策略可以表达为: Figure 6. Learning rate adjustment strategy of cosine decay based on the warm-up method 图6. 基于热身法的余弦衰减学习率调整策略 5. 仿真结果 仿真过程中BS的天线数设置为4,IRS的反射单元数设置为32,UE的天线数设置为4,子载波数设置为128。仿真采用COST 2100信道模型 [20] 在中心频率为5.3GHz的频带的室内场景下生成数据集。其中BS到IRS之间信道用发射天线数为4、接收天线为32的信道替代,IRS到UE之间信道用发射天线数为32、接收天线为4的信道模型替代。然后将BS到IRS、IRS到UE以及BS到UE的CSI在通道上拼接起来。因为时延扩展的有限性,CSI中会有大量的0值,所以将CSI截断并只保留前16行的有效数据。然后将截断后CSI中的6个通道的特征尺寸补齐,即BS到UE的CSI由 16×1616×16 用0值扩展至 128×16128×16。6个通道保持 128×16128×16 的尺寸,其中有效数据为8704,其余数据为对齐CSI补的0值,压缩比是按照有效数据8704与压缩后的数据量计算。补齐后CSI的尺寸为: 128×16×6128×16×6。其中128表示为角度;16为子载波;6分别为BS到IRS的CSI、IRS到UE的CSI以及BS到UE的CSI的虚数和实数。 使用COST 2100模型生成10万个数据集,然后按照4:1的比例将数据集分成训练集和测试集。模型训练时,采用均方误差(MSE, Mean Squared Error)作为系统的损失函数,使用Adam算法 [21] 更新参数。batch size设置为150,epoch设置为100,初始学习率设置为0.0045并使用基于热身法的模型训练方法, epoch′epoch′ 设置为20。 本文比较了IARNet与CRNet与CsiNet在不同压缩比下的性能表现,结果如表1所示,加粗表示为该压缩比下的最佳性能表现。仿真结果表明,IARNet在大数据量CSI压缩场景下对比其他基于深度学习的CSI重建算法有更好的性能表现,即使是在1/32的压缩比下IARNet仍能将CSI较好地重建起来,这主要得益于IARNet采用了多卷积特征融合、混合注意力机制以及比例残差等方法并进行了联合优化,在优化过程中尽量避免了不必要的计算开销,这让网络保持性能的同时也更轻量化。 压缩比 深度学习网络 NMSE 1/2 CsiNet CRNet IARNet 1.0889 0.5529 0.0273 1/4 CsiNet CRNet IARNet 1.0894 0.5537 0.0281 1/8 CsiNet CRNet IARNet 1.0902 0.5625 0.0680 1/16 CsiNet CRNet IARNet 1.0910 0.6172 0.1740 1/32 CsiNet CRNet IARNet 1.0919 0.6578 0.3841 1/64 CsiNet CRNet IARNet 1.2300 0.8266 0.6076 Table 1. Comparison of NMSE performance of IARNet with CRNet and CsiNet 表1. IARNet与CRNet和CsiNet算法的NMSE性能比较 图7是IARNet、CRNet和CsiNet在压缩比为1/8下系统的NMSE随着epoch变化的曲线。由图7所示,在训练过程中,CsiNet的NMSE始终保持较高的水平,NMSE从最初的25.112收敛至1.0902,这表明数据集超出了系统的学习能力,CsiNet无法学习和重建大数据量的CSI。CRNet的NMSE从最初的3.11可以收敛至0.5625,但是33个epoch后系统的NMSE基本不变,这表明CRNet可以学习和重建部分CSI的数据,但是重建质量不佳。IARNet的NMSE从最初的0.9912可以收敛至0.0680,NMSE曲线在整个训练过程中都趋于下降,在90个epoch后逐渐平稳,这表明IARNet可以很好地学习和重建大部分的CSI数据,重建质量佳。 Figure 7. NMSE variation curves of three networks at 1/8 compression ratio during the training process 图7. 训练过程中三种网络在1/8压缩比下的NMSE变化曲线 图8是IARNet在压缩比为1/8下系统的测试集损失函数和训练集的损失函数随着epoch变化的曲线。由图7可见,测试集损失函数和训练集的损失函数随着epoch增加而逐渐减少,测试集损失函数在训练集损失函数附近波动。训练结束后,训练集的损失函数可以收敛至0.03附近,训练集的损失函数可以收敛至0.05附近,这说明IARNet有轻微的过拟合,但是整体上可以忽略不计。 Figure 8. Comparison of the loss functions of the training and test sets 图8. 训练集和测试集的损失函数对比 此外本文还比较了四种学习率调整策略配合其最佳初始学习率在压缩比为1/8情况下对IARNet性能的影响。第一种是本方案采用基于热身法的余弦衰减方案,最佳初始学习率为0.0045。第二种方案是固定法,最佳初始学习率为:0.0002。第三种方案是步衰减法,最佳初始学习率为:0.001。第四种方案是余弦衰减法,最佳初始学习率为0.0003。NMSE随着训练过程推进的仿真变化曲线如图9所示。由图9仿真结果表明,相比于传统的学习率调整策略,本方案采用的方法可以让系统有更好的重建性能,NMSE收敛至更低的水平,可达0.0683。而固定法、步衰减法和余弦衰减法训练后的系统分别收敛至0.1572、0.0903和0.1822。相比传统的方法基于热身法学习率调整策略的重建质量至少提升24.9%。 Figure 9. NMSE variation curves of four learning rate adjustment strategies during training 图9. 训练过程中四种学习率调整策略的NMSE变化曲线 另外表2比较了IARNet与CRNet和CsiNet在不同压缩比下的参数量,M表示百万。IARNet除了在1/64压缩比下参数量高于CRNet和CsiNe以外,其他压缩比下的参数量均小于IARNet和CRNet,因此IARNet可以较易地被部署在各类设备里面,节省设备存储空间。 压缩比 1/2 1/4 1/8 1/16 1/32 1/64 参数量 CsiNet 67.22M 33.63M 16.82M 16.82M 4.26M 2.21M CRNet 67.13M 33.57M 16.79M 16.79M 4.21M 2.11M IARNet 40.95M 24.17M 15.78M 15.78M 3.91M 2.86M Table 2. Comparison of the number of parameters of IARNet with CRNet and CsiNet at different compression ratios 表2. IARNet与CRNet和CsiNet在不同压缩比下的参数量比较 6. 结论 本文针对IRS辅助的通信系统中反馈开销更加巨大的问题提出了一种新的深度学网络IARNet。该网络在传统的Inception网络结构上结合了多卷积特征融合、混合注意力机制以及残差等子模块,这种混合结构可以有效地将大数据量的CSI进行压缩重建。计算机仿真结果显示IARNet在IRS通信系统中对大数据量的CSI进行压缩重建有更好的表现,并且基于热身法的模型训练方案优于传统的固定法和衰减类法。 我们的服务类型 公开课程 人工智能、大数据、嵌入式 内训课程 普通内训、定制内训 项目咨询 技术路线设计、算法设计与实现(图像处理、自然语言处理、语音识别) 










