神经网络基础
神经网络基础
- 1. 神经网络基础概念
-
- 1.1 神经元
- 1.2 感知机:
- 1.3 神经网络结构
-
- 神经网络中的参数说明:
- 神经网络的计算
- 参考链接:
- 2. 激活函数
-
- 2.1 sigmoid
- 2.2 tanh
- 2.3 ReLU
- 2.4 Leaky ReLU
- 2.5 Parametric ReLU
- 2.6 Maxout
- 2.7 Swish
- 小结:
- 3. 深度学习中的正则化:
-
- 3.1 L1&L2 正则化
- 3.2 其他策略
- 4. 深度模型中的优化
-
- 4.1 自适应学习率算法
-
- 4.1.1 Momentum
- 4.1.2 AdaGrad:
- 4.2.3 RMSProp
- 4.2.4 Adam
- 4.3 batch norm层
- 4.4 layer norm层
- 参考链接:
1. 神经网络基础概念
神经网络是机器学习中的一种模型,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。神经网络最开始是受生物神经系统的启发,为了模拟生物神经系统而出现的。生物神经系统中最基本的计算单元是神经元。
1.1 神经元
每个神经元从它的树突(dendrites)接受输入信号,沿着唯一的轴突(axon)产生输出信号,而轴突通过分支(branches of axon),通过突触(synapses)连接到其他神经元的树突,神经元之间就这通过这样的连接,进行传递。如下图所示:
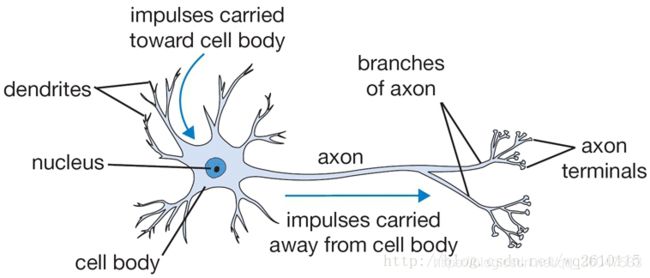
为了模拟神经系统,人们就构建了相应的数学模型 也就是“M-P神经元模型”。如下图:
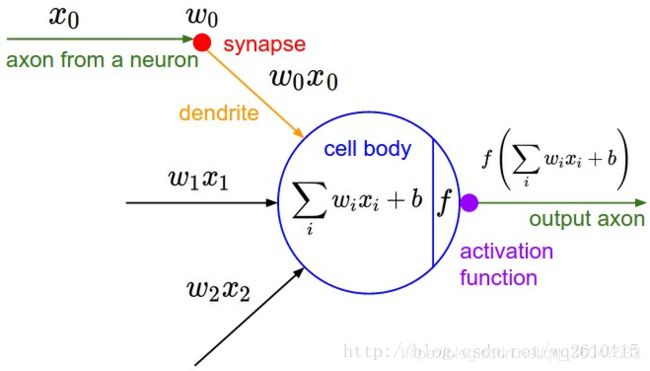
从上图M-P神经元模型可以看出,神经元的输出是
y = f ( ∑ w i x i + b ) y=f( \sum w_i x_i+b) y=f(∑wixi+b)
其中 x i x_i xi,是其他神经元沿着轴突通过突触、树突传送到此神经元的输入信号,该神经元通过与对应的 w i w_i wi参数(该参数表示该输入对该神经元影响的大小)相乘、求和等,得到最终的输出。其中 f f f为激活函数(activation funtion), b b b表示偏置项(bias)。
由激活函数给出最后的输出,往往是二进制的,0 状态代表抑制,1 状态代表激活。也就是:
y = { 0 , i f ∑ w i x i + b ≤ 0 1 , i f ∑ w i x i + b > 0 y= \begin{cases} 0, &if \sum w_i x_i+b \le 0\\ 1, &if \sum w_i x_i+b>0 \end{cases} y={0,1,if∑wixi+b≤0if∑wixi+b>0
1.2 感知机:
感知机在机器学习中的定义为:

感知机可以分为单层感知机,多层感知机。
(1) 单层感知机是由两层神经网络组成,输入层接收外界输入信号后传递给输出层,输出层是 M-P神经元,如下图所示:
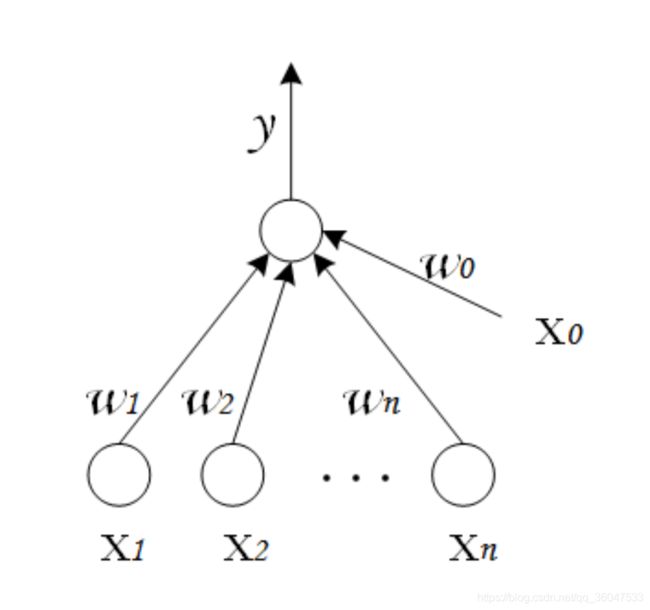
可以把感知机看作是 n 维实例空间中的超平面决策面,对于超平面一侧的样本,感知器输出 1,对于另一侧的实例输出 0,这个决策超平面方程是 w⋅x=0。
(2)多层感知机,或者说是多层神经网络,就是在输入层与输出层之间加了多个隐藏层。
1.3 神经网络结构
神经网络其实就是按照一定规则连接起来的多个神经元。下图一个简单的神经网络结构:
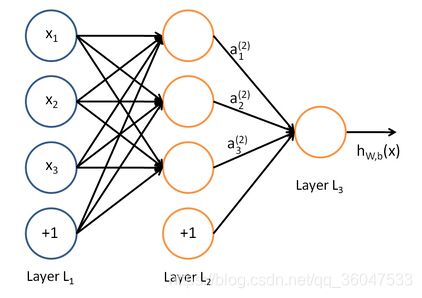
其中一个神经元的输出是另一个神经元的输入,+1项表示的是偏置项(bias)。上图是含有一个隐含层的神经网络模型,L1层称为输入层,L2层称为隐含层,L3层称为输出层。通常我们所说的N层神经网络并不包含输入层,如上图即两层的神经网络。
神经网络中的参数说明:
在神经网络中,主要有如下的一些参数标识:
- 网络的层数
- 神经网络的权重和偏置: ( W , b ) = ( W ( 1 ) , b ( 1 ) , W ( 2 ) , b ( 2 ) ) (W,b)=(W^(1),b^(1),W^(2),b^(2)) (W,b)=(W(1),b(1),W(2),b(2)), W i j ( l ) W_{ij}^{(l)} Wij(l) 表示的是第l层的第j个神经元和第l+1层的第i个神经元之间的连接参数, b i ( l ) b_i^{(l)} bi(l)是是第l+1层的第i个神经元的偏置项.
神经网络的计算

此部分内容来自:
https://blog.csdn.net/google19890102/article/details/49736619
更为详细的复杂神经网络模型可见以下链接内容:
https://www.cnblogs.com/maybe2030/p/5597716.html#_label0
参考链接:
http://blackblog.tech/2018/02/23/Eight-Neural-Network/
https://www.cnblogs.com/maybe2030/p/5597716.html#_label0
https://blog.csdn.net/google19890102/article/details/49736619
https://blog.csdn.net/Dream_angel_Z/article/details/48915561
https://www.zybuluo.com/hanbingtao/note/476663
2. 激活函数
2.1 sigmoid
sigmoid函数是非线性的,其数学公式为:
σ ( x ) = 1 / ( 1 + e x ) \sigma(x)=1/(1+e^x) σ(x)=1/(1+ex)
其图像如下图:
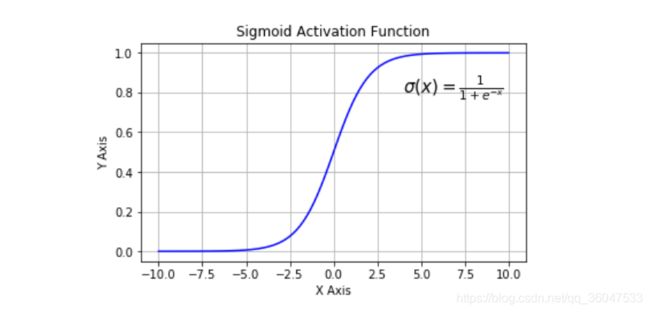
sigmoid导数的图像如下:
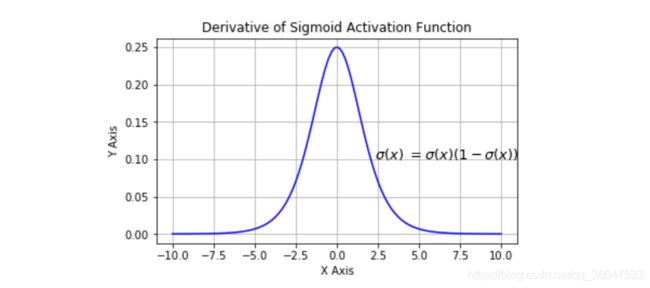
Sigmoid 函数将实数值映射到0到1的范围内,越小的数越趋近于0,越大的数越趋近于1。Sigmoid函数是原来使用最多的激活函数,由于其能够很好的解释神经元的起火频率,0表示没起火,1表示全饱和(fully-saturated)。从上图可以看出x<-10或者x>10都不存在梯度。
但sigmoid函数有三个缺陷:
-
容易饱和从而导致梯度消失:
sigmoid函数在0或者1的状态下会饱和,梯度在这些地方接近于0。那么在反向传播过程中,由于梯度太小,导致神经元相应的权重参数几乎无法更新,并且也会影响后续参数的更新。由于函数在饱和状态下,会产生杀死梯度的现象,那么我们在初始化网络参数时,就应该更加注意来防止饱和现象的发生。例如,当初始化参数太大,大多数的神经元将会饱和,网络就很难学习。 -
Sigmoid函数的输出并不是以0对称的:
由于Sigmoid的函数输出范围是0-1,并不是以0为中心对称的,那么在梯度反向传播的过程中,要么是全正,要么全负(根据表达式f=wTx+b来决定),这样就会带来参数更新过程中不理想的锯齿形变化。当然这点的严重程度比上一点要低很多。 -
计算成本高昂:
exp() 函数与其他非线性激活函数相比,计算成本高昂。
2.2 tanh
tanh函数是非线性的,其数学公式为:
t a n h = 2 σ ( 2 x ) − 1 tanh= 2\sigma(2x)-1 tanh=2σ(2x)−1
其图像如下图:
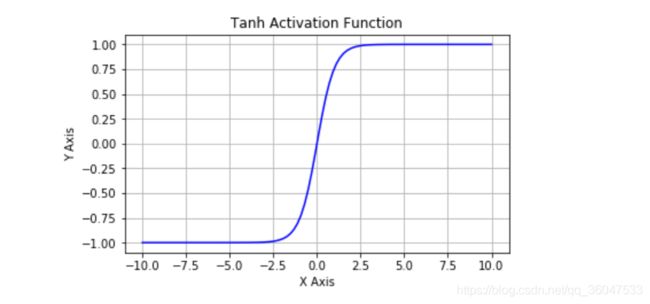
tanh函数的导数函数图像如下:
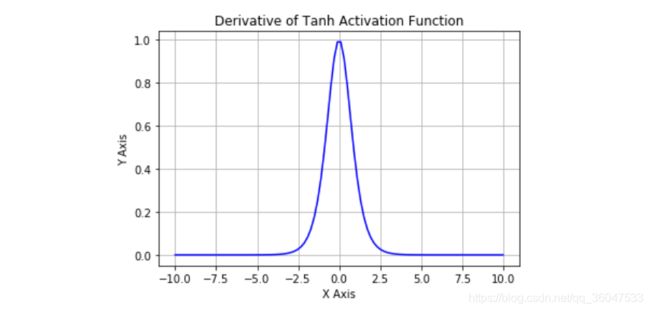
从图中可以看到,tanh将实数压缩到-1到1的范围内,和sigmoid函数一样,它仍然存在饱和与梯度消失的现象,但是比sigmoid函数好的地方,tanh函数的取值是以0为中心对成的,因此在实验中,tanh函数的效果往往要比sigmoid函数好。但仍然存在的缺点是:Tanh 函数也会有梯度消失的问题,因此在饱和时也会造成梯度消失。
2.3 ReLU
ReLU是这几年使用最多的激活函数,它的计算公式是
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
其函数图像如下图:

ReLU导函数的图像如下:

从上图可以看到,ReLU 是从底部开始半修正的一种函数。当输入 x<0 时,输出为 0,当 x> 0 时,输出为 x。
因此 使用ReLU激活函数的好处是:
- 相比于tanh和sigmoid函数,ReLU函数具有非常快的收敛速度
- 不会饱和,可以对抗梯度消失问题,至少在正区域(x> 0 时)可以这样,因此神经元至少在一半区域中不会把所有零进行反向传播。由于使用了简单的阈值化(thresholding),ReLU 计算效率很高。
但是 ReLU 也存在一些缺点:
- **不以零为中心:**和 Sigmoid 激活函数类似,ReLU 函数的输出不以零为中心。
- 学习率过高可能会导致神经网络无法工作:前向传导(forward pass)过程中,如果 x < 0,则神经元保持非激活状态,且在后向传导(backward pass)中使梯度消失。这样权重无法得到更新,网络无法学习。因此,在实验设置中,要设置一个合适的学习率,如果学习率太高,将会导致超过40%的神经元不工作。 当 x = 0 时,该点的梯度未定义,但是这个问题在实现中得到了解决,通过采用左侧或右侧的梯度的方式。
2.4 Leaky ReLU
Leaky ReLU函数是为了解决ReLU函数不工作问题而提出的,其公式是
f ( x ) = m a x ( 0.1 x , x ) f(x)=max(0.1x,x) f(x)=max(0.1x,x)
其函数图像如下图:

Leaky ReLU 的概念是:当 x < 0 时,它得到 0.1 的正梯度。该函数一定程度上缓解了 ReLU 问题,但是使用该函数的结果并不连贯。尽管它具备 ReLU 激活函数的所有特征,如计算高效、快速收敛、在正区域内不会饱和。
2.5 Parametric ReLU
Leaky ReLU 可以得到更多扩展。不让 x 乘常数项,而是让 x 乘超参数,这看起来比 Leaky ReLU 效果要好。该扩展就是 Parametric ReLU。公式是: f ( x ) = m a x ( α x , x ) f(x)=max(\alpha x,x) f(x)=max(αx,x)
其中 α \alpha α是超参数。这里引入了一个随机的超参数,它可以被学习,因为你可以对它进行反向传播。这使神经元能够选择负区域最好的梯度,有了这种能力,它们可以变成 ReLU 或 Leaky ReLU。
2.6 Maxout
Maxout函数由Goodfellow等人提出,函数泛化了ReLU和leaky ReLU,Maxout的计算,Maxout的计算公式为:
f ( x ) = m a x ( w 1 T x + b 1 , w 2 T x + b 2 ) f(x)=max(w_1^Tx+b_1, w_2^Tx+b_2) f(x)=max(w1Tx+b1,w2Tx+b2)
可以看出,当 w 1 , b 1 = 0 w_1,b_1=0 w1,b1=0时,Maxout函数就变成了ReLU函数,因此Maxout具有ReLU函数的优势,但是由于其增加了一倍的参数,增加了计算的复杂性。
2.7 Swish
Swish函数又叫作自门控激活函数,其公式如下:
f ( x ) = x / ( 1 + e x ) f(x)=x/(1+e^x) f(x)=x/(1+ex)

根据上图,我们可以观察到在 x 轴的负区域曲线的形状与 ReLU 激活函数不同,因此,Swish 激活函数的输出可能下降,即使在输入值增大的情况下。大多数激活函数是单调的,即输入值增大的情况下,输出值不可能下降。而 Swish 函数为 0 时具备单侧有界(one-sided boundedness)的特性,它是平滑、非单调的。
小结:
当使用ReLU是要注意学习率的设置,或者尝试使用Leaky ReLu或者Maxout函数,但是不需要使用sigmoid和tanh函数了,因为它们的性能比ReLU/Maxout会差。
参考链接:
https://blog.csdn.net/wq2610115/article/details/68928368
https://www.jiqizhixin.com/articles/2017-11-02-26
3. 深度学习中的正则化:
神经网络的学习要求大量数据,对计算能力的要求很高。神经元和参数之间的大量连接需要通过梯度下降及其变体以迭代的方式不断调整。此外,有些架构可能因为强大的表征力而产生测试数据过拟合等现象。这时我们可以使用正则化和优化技术来解决这两个问题。
目前有多种适合机器学习算法的正则化方法,如数据增强、L2 正则化(权重衰减)、L1 正则化、Dropout、Drop Connect、随机池化和早停等
3.1 L1&L2 正则化
L1 和 L2 正则化是最常用的正则化方法。L1 正则化向目标函数添加正则化项,以减少参数的绝对值总和;而 L2 正则化中,添加正则化项的目的在于减少参数平方的总和。根据之前的研究,L1 正则化中的很多参数向量是稀疏向量,因为很多模型导致参数趋近于 0,因此它常用于特征选择设置中。机器学习中最常用的正则化方法是对权重施加 L2 范数约束。
标准正则化代价函数如下:
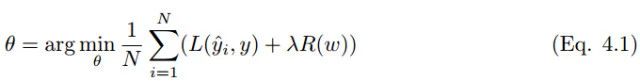
其中正则化项 R(w) 是:

另一种惩罚权重的绝对值总和的方法是 L1 正则化:

L1 正则化在零点不可微,因此权重以趋近于零的常数因子增长。很多神经网络在权重衰减公式中使用一阶步骤来解决非凸 L1 正则化问题 。L1 范数的近似变体是:

另一个正则化方法是混合 L1 和 L2 正则化,即弹性网络罚项
3.2 其他策略
- 数据集增强
数据增强是提升算法性能、满足深度学习模型对大量数据的需求的重要工具。数据增强通过向训练数据添加转换或扰动来人工增加训练数据集。数据增强技术如水平或垂直翻转图像、裁剪、色彩变换、扩展和旋转通常应用在视觉表象和图像分类中。
- Drop Connect
Drop Connect 是另一种减少算法过拟合的正则化策略,是 Dropout 的一般化。在 Drop Connect 的过程中需要将网络架构权重的一个随机选择子集设置为零,取代了在 Dropout 中对每个层随机选择激活函数的子集设置为零的做法。由于每个单元接收来自过去层单元的随机子集的输入,Drop Connect 和 Dropout 都可以获得有限的泛化性能 [22]。Drop Connect 和 Dropout 相似的地方在于它涉及在模型中引入稀疏性,不同之处在于它引入的是权重的稀疏性而不是层的输出向量的稀疏性。
- early stop
早停法可以限制模型最小化代价函数所需的训练迭代次数。早停法通常用于防止训练中过度表达的模型泛化性能差。如果迭代次数太少,算法容易欠拟合(方差较小,偏差较大),而迭代次数太多,算法容易过拟合(方差较大,偏差较小)。早停法通过确定迭代次数解决这个问题,不需要对特定值进行手动设置。
- Dropout层
Bagging 是通过结合多个模型降低泛化误差的技术,主要的做法是分别训练几个不同的模型,然后让所有模型表决测试样例的输出。而 Dropout 可以被认为是集成了大量深层神经网络的 Bagging 方法,因此它提供了一种廉价的 Bagging 集成近似方法,能够训练和评估值数据数量的神经网络。
Dropout 指暂时丢弃一部分神经元及其连接。随机丢弃神经元可以防止过拟合,同时指数级、高效地连接不同网络架构。神经元被丢弃的概率为 1 − p,减少神经元之间的共适应。隐藏层通常以 0.5 的概率丢弃神经元。使用完整网络(每个节点的输出权重为 p)对所有 2^n 个 dropout 神经元的样本平均值进行近似计算。Dropout 显著降低了过拟合,同时通过避免在训练数据上的训练节点提高了算法的学习速度。
这部分内容来自以下链接:
https://www.jiqizhixin.com/articles/2017-12-20
4. 深度模型中的优化
4.1 自适应学习率算法
4.1.1 Momentum
随机梯度下降和小批量梯度下降是机器学习中最常见的优化技术,然而在大规模应用和复杂模型中,算法学习的效率是非常低的。而动量策略旨在加速学习过程,特别是在具有较高曲率的情况下。动量算法利用先前梯度的指数衰减滑动平均值在该方向上进行回退。该算法引入了变量 v 作为参数在参数空间中持续移动的速度向量,速度一般可以设置为负梯度的指数衰减滑动平均值。对于一个给定需要最小化的代价函数,动量可以表达为:
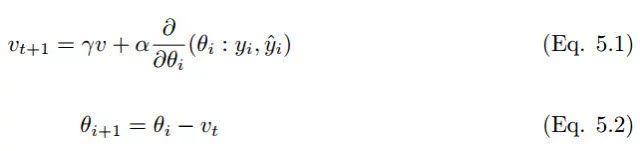
其中 α 为学习率,γ ∈ (0, 1] 为动量系数,v 是速度向量,θ是保持和速度向量方向相同的参数。一般来说,梯度下降算法下降的方向为局部最速的方向(数学上称为最速下降法),它的下降方向在每一个下降点一定与对应等高线的切线垂直,因此这也就导致了 GD 算法的锯齿现象。虽然 SGD 算法收敛较慢,但动量法是令梯度直接指向最优解的策略之一。在实践中,γ初始设置为 0.5,并在初始学习稳定后增加到 0.9。同样,α 一般也设置地非常小,因为梯度的量级通常是比较大的。
4.1.2 AdaGrad:
Adagrad 亦称为自适应梯度(adaptive gradient),允许学习率基于参数进行调整,而不需要在学习过程中人为调整学习率。Adagrad 根据不常用的参数进行较大幅度的学习率更新,根据常用的参数进行较小幅度的学习率更新。因此,Adagrad 成了稀疏数据如图像识别和 NLP 的天然选择。然而 Adagrad 的最大问题在于,在某些案例中,学习率变得太小,学习率单调下降使得网络停止学习过程。在经典的动量算法和 Nesterov 中,加速梯度参数更新是对所有参数进行的,并且学习过程中的学习率保持不变。在 Adagrad 中,每次迭代中每个参数使用的都是不同的学习率。
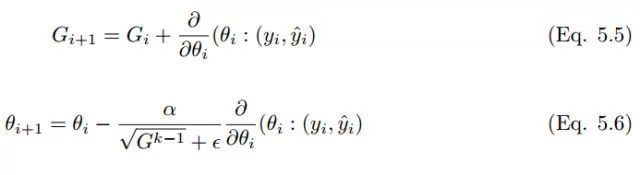
4.2.3 RMSProp
RMS prop 类似于 Adadelta 的首个更新向量,
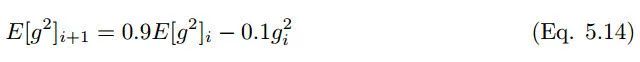
RMS prop 的更新规则如下:
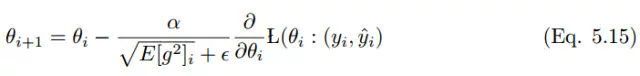
在 RMS prop 中,学习率除以平方梯度的指数衰减平均值。
4.2.4 Adam
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
Adam 算法的提出者描述其为两种随机梯度下降扩展式的优点集合,即:
适应性梯度算法(AdaGrad)为每一个参数保留一个学习率以提升在稀疏梯度(即自然语言和计算机视觉问题)上的性能。
均方根传播(RMSProp)基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能。
Adam 算法同时获得了 AdaGrad 和 RMSProp 算法的优点。Adam 不仅如 RMSProp 算法那样基于一阶矩均值计算适应性参数学习率,它同时还充分利用了梯度的二阶矩均值(即有偏方差/uncentered variance)。具体来说,算法计算了梯度的指数移动均值(exponential moving average),超参数 beta1 和 beta2 控制了这些移动均值的衰减率。
移动均值的初始值和 beta1、beta2 值接近于 1(推荐值),因此矩估计的偏差接近于 0。该偏差通过首先计算带偏差的估计而后计算偏差修正后的估计而得到提升。
这部分内容链接来自:
https://www.jiqizhixin.com/articles/2017-12-20
4.3 batch norm层
为了减小InternalInternal InternalInternal CovariateCovariate CovariateCovariate ShiftShift ShiftShift,对神经网络的每一层做归一化不就可以了,假设将每一层输出后的数据都归一化到0均值,1方差,满足正太分布,但是,此时有一个问题,每一层的数据分布都是标准正太分布,导致其完全学习不到输入数据的特征,因为,费劲心思学习到的特征分布被归一化了,因此,直接对每一层做归一化显然是不合理的。
但是如果稍作修改,加入可训练的参数做归一化,那就是BatchNormBatchNorm BatchNormBatchNorm实现的了,接下来结合下图的伪代码做详细的分析:

batchnorm的步骤如下:

此部分内容来自:
https://blog.csdn.net/qq_25737169/article/details/79048516
4.4 layer norm层
本文主要是针对 batch normalization 存在的问题 提出了 Layer Normalization 进行改进的。
这里首先来回顾一下 batch normalization :
对于前馈神经网络第 l 隐层,神经元的输入为 a, 激活函数为 f, 激活函数输出为 h。权值 w 通过 SGD学习得到。 如下面的公式所示:
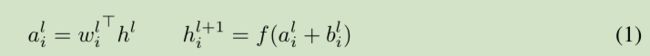
深度学习中的一个挑战就是对于上面公式中 一层的权值 w 的梯度 高度依赖于前一层神经元的输出,特别是当这些输出的改变高度相关的时候。(梯度容易受样本数据的影响,导致权值难以快速的收敛,一会向东,一会向西,走来走去,走了半天也没走多少路啊,这样走到全局最优值要走到哪天。这个问题有个名字,叫 covariate shift)。 针对此问题 [Ioffe and Szegedy, 2015] 提出了 Batch normalization 来降低这个 covariate shift 的影响。对于每个隐层的神经元,我们在所有的训练样本上归一化该神经元的输入。
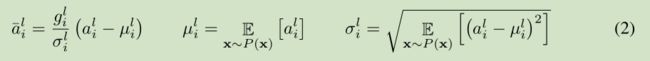
在整个训练样本上计算均值方差,然后对神经元的输入进行归一化。由于对整个训练样本计算均值方差不太有效率(对于训练来说),所以提出了 在最小训练批次上估计 均值方差。 current mini-batch 。 这个约束导致Batch normalization 难以应用于 recurrent neural networks。
针对前面提到的 Batch normalization 的问题,我们提出了 Layer normalization。
注意到一层输出的改变会产生下一层输入的高相关性改变,特别是当使用 ReLU,其输出改变很大。那么我们可以通过固定一层神经元的输入均值和方差来降低 covariate shift 的影响。
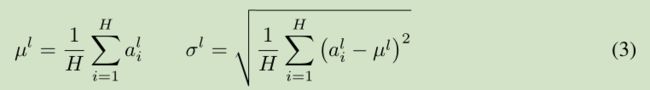
上面公式中 H 是 一层神经元的个数。这里一层网络 共享一个均值和方差,不同训练样本对应不同的均值和方差,这是和 Batch normalization 的最大区别。
Layer normalization 对于recurrent neural networks 的帮助最大,但对于 Convolutional Networks 作用不是很大,
此部分内容来自:
https://blog.csdn.net/zhangjunhit/article/details/53169308
参考链接:
https://www.jiqizhixin.com/articles/2017-12-20
https://zhuanlan.zhihu.com/p/54915217