(四)pix2pixGAN论文笔记与实战
(四)pix2pixGAN论文笔记与实战
-
-
- 一、论文要点
- 二、网络架构
- 三、完整代码(详细注释)
- 四、效果截图
- 五、遇到的问题及解决
-
一、论文要点
1.图像建模的结构化损失
图像到图像的翻译问题通常是根据像素分类或回归来解决的。这些公式将输出空间视为“非结构化”,即在给定输入图像的情况下,每个输出像素被视为与所有其他像素有条件地独立。而cGANs( conditional-GAN)的不同之处在于学习结构化损失,并且理论上可以惩罚输出和目标之间的任何可能结构。
2.损失函数
一般的 cGANs 的目标函数如下: x x x是条件, y y y=G( x , z x,z x,z), z z z是噪声
L c G A N ( G , D ) L_{cGAN}(G, D) LcGAN(G,D) = E x , y [ l o g D ( x , y ) ] E_{x,y}[logD(x, y)] Ex,y[logD(x,y)] + E x , z [ l o g ( 1 − D ( x , G ( x , z ) ) ] E_{x, z}[log(1-D(x, G(x, z))] Ex,z[log(1−D(x,G(x,z))]
对于图像翻译任务而言,G 的输入和输出之间其实共享了很多信息,比如图像上色任务、输入和输出之间就共享了边信息。因而为了保证输入图像和输出图像之间的相似度、还加入了 L1 Loss, 前人的一些工作中发现,将GAN的目标函数和传统的loss结合,可以带来更好的效果。由于以前的研究中发现,对于cGAN,增加一个额外的损失,如L2距离(真实图像和生成图像),效果更好。此时判别器的损失不变,生成器的损失变了。该论文中使用L1距离,原因是相比于L2距离,L1距离产生的模糊更小。所以论文增加了一个L1 loss交给生成器G去最小化。
L L 1 ( G ) L_{L1}(G) LL1(G) = E x , y , z [ ∣ ∣ y − G ( x , z ) ∣ ∣ 1 ] E_{x,y,z}[|| y-G(x,z) ||_1] Ex,y,z[∣∣y−G(x,z)∣∣1]
即生成的 fake images 与 真实的 real images 之间的 L1 距离,(imgB’ 和imgB)保证了输入和输出图像的相似度。最终的损失函数:

二、网络架构
图像到图像翻译问题的一个定义特征是它们将高分辨率输入网格映射到高分辨率输出网格。 另外,对于我们考虑的问题,输入和输出的表面外观不同,但两者应该共享一些信息。 因此,输入中的结构与输出中的结构大致对齐。 我们围绕这些考虑设计了生成器架构。
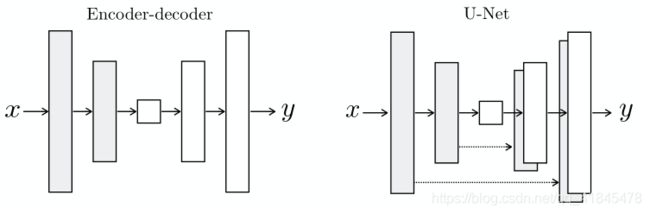
U-Net 结构基于 Encoder-Decoder 模型,而 Encoder 和 Decoder 是对称结构。 U-Net 的不同之处是将第 i 层和第 n-i 层连接起来,其中 n 是层的总数,这种连接方式称为跳过连接(skip connections)。第 i 层和第 n-i 层的图像大小是一致的,可以认为他们承载着类似的信息 。
为了能更好得对图像的局部做判断,Pix2pix 判别网络采用 patchGAN 结构,也就是说把图像等分成多个固定大小的 Patch,分别判断每个Patch的真假,最后再取平均值作为 D 最后的输出。这样做的好处:
- D 的输入变小,计算量小,训练速度快。
- 因为 G 本身是全卷积的,对图像尺度没有限制。而D如果是按照Patch去处理图像,也对图像大小没有限制。就会让整个 Pix2pix 框架对图像大小没有限制,增大了框架的扩展性。
论文中将 PatchGAN 看成另一种形式的纹理损失或样式损失。在具体实验时,采用不同尺寸 patch, 发现 70x70 的尺寸比较合适。

图片来源:TeeyoHuang
一、Generator
Let Ck denote a Convolution-BatchNorm-ReLU layer with k filters. CDk denotes a Convolution-BatchNorm-Dropout-ReLU layer with a dropout rate of 50%. All convolutions are 4×4 spatial filters applied with stride 2. Convolutions in the encoder, and in the discriminator, downsample by a factor of 2, whereas in the decoder they upsample by a factor of 2.
encoder:
C64-C128-C256-C512-C512-C512-C512-C512
decoder:
CD512-CD512-CD512-C512-C256-C128-C64
在decoder的卷积层的最后一层使用 Tanh 激活函数, encoder的第一层 C64不使用 Instance-Normolization, encoder 的 所有卷积层的激活函数是LeakReLU, 参数 0.2 , 而decoder的所有卷积层的激活函数使用ReLU.
U-Net decoder:
CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128
三、完整代码(详细注释)
使用的数据集:facades 提取码:co9v
import argparse
import os
import numpy as np
import torch.nn as nn
import torch
import torch.nn.functional as F
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets
from torch.autograd import Variable
import glob
import random
from PIL import Image
import time
import sys
import datetime
parser = argparse.ArgumentParser()
parser.add_argument('--epoch', type = int, default=0, help = 'epoch to start training from')
parser.add_argument('--n_epochs', type = int, default=100, help = 'number of epochs of training')
parser.add_argument('--dataset_name', type = str, default='facades', help = 'name of the dataset')
parser.add_argument('--batch_size', type = int, default=1, help='size of the batchs')
parser.add_argument('--lr', type = float, default=0.0002, help = 'learning rate')
parser.add_argument('--b1', type = float, default=0.5, help = 'adam: decay of first order momentum of gradient')
parser.add_argument('--b2', type = float, default=0.999, help='adam: decay of second order momentum of gradient')
parser.add_argument('--decay_epoch', type = int, default=100, help='epoch from which to start lr decay')
parser.add_argument('--img_height', type = int, default=256, help='size of image height')
parser.add_argument('--img_width', type = int, default=256, help = 'size of image width')
parser.add_argument('--channels', type = int, default=3, help = 'number of image channels')
parser.add_argument("--sample_interval", type=int, default=500, help="interval between sampling of images from generators")
parser.add_argument("--checkpoint_interval", type=int, default=5, help="interval between model checkpoints")
opt = parser.parse_args(args = [])
print(opt)
random.seed(22)
torch.manual_seed(22)
os.makedirs(name='Picture/pix2pixGAN/{}'.format(opt.dataset_name), exist_ok=True)
os.makedirs(name='Model/pix2pixGAN/{}'.format(opt.dataset_name), exist_ok= True)
# cuda = True if torch.cuda.is_available() else False
# torch.cuda.empty_cache()
'''数据集类'''
class ImageDataset(Dataset):
def __init__(self, root, transforms_ = None, mode = 'train'):
self.transform = transforms.Compose(transforms_)
self.files = sorted(glob.glob(os.path.join(root, mode) + '/*.*'))
if mode == 'train':
# list.extend():给list添加多个元素
self.files.extend(sorted(glob.glob(os.path.join(root, 'test') + '/*.*'))) # 这里是把测试集的数据也拿来一起训练
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
# Image.crop(left, up, right, below) left:与左边界的距离 up:与上边界的距离
# right:还是与左边界的距离 below:还是与上边界的距离 !!!
img_A = img.crop((0, 0, w/2, h)) # 竖着切一刀,保留左边,左边是真实图片
img_B = img.crop((w/2, 0, w, h)) # 竖着切一刀,保留右边,右边是对应的‘虚幻图’
# 论文中提到的:random jitter and mirroring(随机抖动与镜像)
if np.random.random() < 0.5: # 随机翻转
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], 'RGB') # 左右翻转图片
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], 'RGB') # 左右翻转图片
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {'A':img_A, 'B':img_B}
def __len__(self):
return len(self.files)
'''加载数据集'''
transform = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
]
# 训练数据集
dataloader = DataLoader(ImageDataset('../dataset/{}'.format(opt.dataset_name), transforms_=transform, mode='train'),
batch_size=opt.batch_size, shuffle=False, num_workers=0)
# 验证数据集
val_dataloader = DataLoader(ImageDataset('../dataset/{}'.format(opt.dataset_name),transforms_ = transform,
mode='val'),batch_size = 10, shuffle = False, num_workers = 0)
'''网络结构'''
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize = True):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias = False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2, inplace=True))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size,dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True)
]
if dropout:
layers.append(nn.Dropout2d(0.5))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input): # 输出完再合并
x = self.model(x)
x = torch.cat((x, skip_input), dim = 1) # 在通道的维度上进行合并,这样通道数目增加为两倍
return x
class GeneratorUNet(nn.Module):
def __init__(self, in_channels = 3, out_channels = 3):
super(GeneratorUNet, self).__init__()
# C64-C128-C256-C512-C512-C512-C512-C512 [b, 3, 256, 256] --> [b, 64, 128, 128]
self.down1 = UNetDown(in_channels, 64, normalize=False) # 第一层不进行规范化(论文中说的)
self.down2 = UNetDown(64, 128) # --> [b, 128, 64, 64]
self.down3 = UNetDown(128, 256) # --> [b, 256, 32, 32]
self.down4 = UNetDown(256, 512) # --> [b, 512, 16, 16]
self.down5 = UNetDown(512, 512) # --> [b, 512, 8, 8]
self.down6 = UNetDown(512, 512) # -->[b, 512, 4, 4]
self.down7 = UNetDown(512, 512) # -->[b, 512, 2, 2]
self.down8 = UNetDown(512, 512, normalize=False) # -->[b, 512, 1, 1]
# CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128
self.up1 = UNetUp(512, 512, dropout=0.5) # --> [b, 512, 2, 2]
self.up2 = UNetUp(1024, 512, dropout=0.5) # 这里会收到两倍的feature map, 所以是1024 -->[b, 512, 4, 4]
self.up3 = UNetUp(1024, 512, dropout=0.5) # --> [b, 512, 8, 8]
self.up4 = UNetUp(1024, 512) # --> [b, 512, 16, 16]
self.up5 = UNetUp(1024, 256) # --> [b, 256, 32, 32]
self.up6 = UNetUp(512, 128) # --> [b, 128, 64, 64]
self.up7 = UNetUp(256, 64) # --> [b, 64, 128, 128]
self.final = nn.Sequential(
nn.Upsample(scale_factor=2), # 进行上采样,输出的H*W是输入的两倍 -->[b, 64, 256, 256]
nn.ZeroPad2d((1, 0, 1, 0)), # -->[b, 64, 257, 257] 左上个填充一行0,方便下一行还原到[b, 64, 256, 256]
nn.Conv2d(128, out_channels, 4, 1, 1) # -->[b, 3, 256, 256]
)
def forward(self, x):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, in_channels = 3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalize = True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels * 2, 64, normalize=False), # [b, 3*2, 256, 256]-->[b,64, 128, 128]
*discriminator_block(64, 128), # -->[b, 128, 64, 64]
*discriminator_block(128, 256), # -->[b, 256, 32, 32]
*discriminator_block(256, 512), # -->[b, 512, 16, 16]
nn.ZeroPad2d((1,0, 1, 0)), # -->[b, 512, 17, 17]
nn.Conv2d(512, 1, 4, 1, 1, bias=False) # -->[b, 1, 16, 16]
)
def forward(self, img_A, img_B):
# Concatenate image and condition image by channels to produce input
img_input = torch.cat((img_A, img_B), dim = 1)
return self.model(img_input)
generator = GeneratorUNet()
discriminator = Discriminator()
'''训练'''
# Loss functions
criterion_GAN = torch.nn.MSELoss()
criterion_pixel = torch.nn.L1Loss()
# Loss weight of L1 pixel-wise loss between translated image and real image
lambda_pixel = 100
# Calculate output of image discriminator (PatchGAN)
patch = (1, 16, 16)
if opt.epoch !=0:
# Load pretrained models
generator.load_state_dict(torch.load('Model/{}/generator_{}.pth'.format(opt.dataset_name, opt.epoch)))
discriminator.load_state_dict(torch.load('Model/{}/discriminator_{}.pth'.format(opt.dataset_name, opt.epoch)))
else :
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr = opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr = opt.lr, betas=(opt.b1, opt.b2))
# Tensor type
# Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
Tensor = torch.FloatTensor
def save_images(batch_done):
"""Saves a generated sample from the validation set"""
with torch.no_grad():
imgs = next(iter(val_dataloader))
real_A = Variable(imgs['B'].type(Tensor)) #加入gpu
real_B = Variable(imgs['A'].type(Tensor))
fake_B = generator(real_A).detach()
img_sample = torch.cat((real_A, fake_B, real_B), dim = -1)
save_image(img_sample, 'Picture/pix2pixGAN/{}/{}.png'.format(opt.dataset_name, batch_done), nrow=5, normalize=True)
# if cuda:
# generator.cuda()
# discriminator.cuda()
# criterion_GAN.cuda()
# criterion_pixel.cuda()
# ----------
# Training
# ----------
prev_time = time.time()
for epoch in range(opt.n_epochs):
for i , batch in enumerate(dataloader):
# Model inputs
real_A = Variable(batch['B'].type(Tensor))
real_B = Variable(batch['A'].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad = False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad = False)
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
fake_B = generator(real_A).detach()
# real loss
pred_real = discriminator(real_B, real_A)
loss_real = criterion_GAN(pred_real, valid)
# fake loss
pred_fake = discriminator(fake_B, real_A)
loss_fake = criterion_GAN(pred_fake, fake)
# total loss
loss_D = (loss_real + loss_fake) * 0.5
loss_D.backward()
optimizer_D.step()
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
fake_B = generator(real_A)
# GAN loss
pred_fake = discriminator(fake_B, real_A).detach()
loss_GAN = criterion_GAN(pred_fake, valid)
# pixel loss
loss_pixel = criterion_pixel(fake_B, real_B)
# total loss
loss_G = loss_GAN + lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batch_done = epoch * len(dataloader) + i
batch_left = opt.n_epochs * len(dataloader) - batch_done
time_left = datetime.timedelta(seconds = batch_left * (time.time() - prev_time))
prev_time = time.time()
# print log
print(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, GAN: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_pixel.item(),
loss_GAN.item(),
time_left,
)
)
# If at sample interval save image
if batch_done % opt.sample_interval == 0:
save_images(batch_done)
if opt.checkpoint_interval !=-1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), 'Model/pix2pixGAN/{}/generator_{}.pth'.format(opt.dataset_name, epoch))
torch.save(discriminator.state_dict(), 'Model/pix2pixGAN/{}/discriminator_{}.pth'.format(opt.dataset_name, epoch))
四、效果截图
一组三幅图:虚幻图-生成图-真实图,一次测试十组
epoch = 1时:
epoch = 5时:
epoch = 10时:
epoch = 15时:
epoch = 20时:
由于我GPU显存装不下,所以只能用cpu跑,跑了一天实在有点不耐烦,最后手动结束了,跑完要花太多时间。
五、遇到的问题及解决
一、如果把shuffle设置为True, 则大部分情况下运行会报错,设置为False就没问题,不知道什么原因:

二、pytorch torch.nn 实现上采样——nn.Upsample
三、pytorch常用的padding函数
四、运行Pytorch tutorial代码报错:BrokenPipeError: [Errno 32] Broken pipe
五、深度学习中,偏置(bias)在什么情况下可以要,可以不要?
六、sys.stdout.write()可以刷新显示,即覆盖前面的记录