【读点论文】PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices,一种可在边缘设备上部署的深度学习目标检测
PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices
https://github.com/ChanChiChoi/awesome-Face_Recognition
- 在目标检测中,更好的精度和效率的权衡一直是一个具有挑战性的问题。在这项工作中,致力于研究目标检测的关键优化和神经网络结构的选择,以提高准确性和效率。研究了无锚策略在轻量级对象检测模型上的适用性。增强了主干结构,设计了颈部的轻量化结构,提高了网络的特征提取能力。改进了标签分配策略和损失函数,使训练更加稳定和高效。通过这些优化,创建了一个新的实时对象检测器家族,命名为PP-PicoDet,它在移动设备上实现了卓越的对象检测性能。
- 与其他流行的模型相比,本文的模型在准确性和延迟之间实现了更好的平衡。只有0.99M参数的PicoDet-S实现了30.6%的mAP,与YOLOX-Nano相比,在mAP上绝对提高了4.8%,同时降低了55%的移动CPU推理延迟,与NanoDet相比,在mAP上绝对提高了7.1%。当输入大小为320时,它在移动ARM CPU上达到123 FPS(使用Paddle Lite时为150 FPS)。只有3.3M参数的PicoDet-L实现了40.9%的mAP,在mAP上绝对提升了3.7%,比YOLOv5s快了44%。如下图所示,本文的模型远远优于轻量级对象检测的最新结果。PaddleDetection提供代码和预训练模型。
- 不同轻量化模型的贴图对比。在批量为1的高通骁龙865(4A77+4A55)处理器上测试的所有模型的延迟。
- COCO数据集上不同轻型探测器的速度和精度的比较。使用NCNN库进行延迟测试,并为PP-PicoDet模型添加了Paddle Lite推理延迟(标记为>)。在高通snapdragon 865(4 * A77+4 * A55)处理器上测试的所有模型的延迟,批量大小为1,CPU线程为4。


Introduction
目标检测广泛应用于许多计算机视觉任务中,包括自动驾驶、机器人视觉、智能交通、工业质量检测、目标跟踪等。两阶段模型通常会带来更高的性能。然而,这种类型的资源消耗网络限制了现实世界应用的采用。为了克服这个问题,轻型移动目标检测器吸引了越来越多的研究兴趣,旨在设计高效的目标检测。
YOLO系列中的现代物体探测器变得流行,因为它们是考虑资源限制的作品的一个小子集。与两级模型相比,YOLO系列具有更好的效率和高精度。然而,YOLO系列没有处理以下问题:
- 1)需要仔细地和手动地重新设计锚盒以采用不同的数据集。
- 2)由于生成的锚点大部分是阴性的,正负样本不平衡的问题。
近年来,许多工作旨在开发更有效的检测器结构,例如无锚检测器。FCOS解决了ground-truth标签内的重叠问题。与其他无锚检测器相比,没有复杂的超参数调谐。然而,大多数无锚检测器都是大规模服务器检测器。
- FCOS算法是基于anchor-free,引入了逐像素回归预测,多尺度特征以及center-ness三种策略。
- FCOS算法在对目标物体框中所有的点进行目标框回归时,是用的距离各个边的长度, 预测一个4维 vector, 用来表示box的上下左右边界离这个位置的距离。主干网络为FPN结构,利用多尺度策略得到不同的五个尺度层来处理不同的目标框,也就是对这五个尺度都做逐像素回归,输出包含三个分支类别,边界框回归以及center-ness分支。
- center-ness分支就是为了滤掉大部分的误检框。它对位置进行打分, 这样远离需要检测的目标中心位置的位置, 分数会较低, 这样就把当前这个位置表示的box的分数降低, 在非极大值抑制的时候就可以把这个分值低的抑制掉,相反,分值高的会作为候选预测框。
在少数情况下,NanoDet和YOLOXNano是无锚检测器,也是移动检测器。问题是,轻量级无锚探测器通常不能很好地平衡精度和效率。因此,在这项工作中,受FCOS和GFL的启发,提出了一种改进的移动友好的高精度无锚检测器,命名为PP-PicoDet。概括而言,我们的主要贡献如下:
- 采用CSP结构构建CSP-PAN作为瓶颈。CSP-PAN通过对颈部的所有分支进行1 × 1卷积来统一输入通道数,这显著增强了特征提取能力并减少了网络参数。将3 × 3深度方向可分离卷积扩大到5 × 5深度方向可分离卷积以扩大感受野。
- 标签分配策略在目标检测中至关重要。使用SimOTA动态标签分配策略,并优化了一些计算细节。具体来说,使用Varifocal损失(VFL)和GIoU损失的加权和来计算成本矩阵,从而在不影响效率的情况下提高准确性。
- ShuffleNetV2在移动设备上性价比高。进一步增强了网络结构,并提出了一种新的主干网,即增强型Enhanced ShuffleNet (ESNet),其性能优于ShuffleNetV2。
- 提出了一种改进的检测一次性神经结构搜索(NAS)流水线来自动寻找目标检测的最佳结构。直接在检测数据集上训练超网,这导致检测的显著计算节省和优化。NAS生成的模型实现了更好的效率和准确性平衡。
通过上述优化,PicoDetS仅用0.99M参数和1.08G FLOPs就实现了30.6%的mAP。当输入大小为320时,它在移动ARM CPU上实现了150 FPS。PicoDet-M仅用2.15M参数和2.5G FLOPs就实现了34.3%的mAP。PicoDet-L仅用3.3M参数和8.74G FLOPs就实现了40.9%的mAP。本文提供小型、中型和大型型号来支持不同的部署。所有的实验都是基于PaddlePaddle2实现的。PaddleDetection提供代码和预训练模型。
Related Works
对象检测是一个经典的计算机视觉挑战,旨在识别图片或视频中的对象类别和对象位置。
现有的目标检测器可以分为两类:基于锚的检测器和无锚的检测器。通常基于锚的两级检测器从图像中生成区域提议,然后从区域提议中生成最终的边界框。为了提高物体定位的准确性,FPN融合了多尺度的高级语义特征。两级检测器在物体定位上更加准确,但在CPU或ARM设备上很难实现实时检测。一级目标检测器也是基于锚的检测器,其在速度和精度之间具有更好的平衡,因此在实践中被广泛使用。SSD,检测多尺度物体,对小物体更友好,但在精度上没有竞争力。同时,YOLO系列(YOLOv1除外)在精度和速度上都表现不错。然而,它没有解决我们在前面部分分析的一些问题。
无锚检测器旨在消除锚盒,这是对象检测中的一个重大改进。YOLOv1的主要思想是将图像分成多个网格,然后在物体中心附近的点上预测包围盒。CornerNet检测边界框的一对角,而不将锚框设计为先验框。CenterNet舍弃左上角和右下角,直接检测中心点。FCOS首先以每像素预测的方式重新阐述了对象检测,并提出了“中心化”分支。无锚点检测器解决了基于锚点检测器的一些问题,减少了内存开销,并提供了更精确的包围盒计算。
后来的工作从不同方面进一步完善了物体检测器。ATSS提出了一种自适应训练样本选择,根据对象的统计特征自动选择正负样本。广义聚焦损失(GFL)消除了FCOS的“中心性”分支,并将质量估计合并到类别预测向量中,以形成定位质量和分类的联合表示。
在移动物体检测领域,已经投入了大量努力来实现更准确和有效的物体检测器。通过YOLOv4的压缩-编译协同设计,yolobile实现了移动设备上的实时物体检测。PP-YOLOTiny在PP-YOLO的基础上采用MobileNetV3主干和TinyFPN结构。NanoDet使用ShuffleNetV2作为其主干,以使模型更轻,并使用ATSS和GFL来提高准确性。YOLOXNano是YOLOX系列中目前最轻的型号,使用动态标签分配策略SimOTA在可接受的参数内实现其最佳性能。
- ATSS:目标检测的自适应正负anchor选择
- 输入G表示图片的真实框集合,L表示特征金字塔层次,A_i表示第i层的一系列的anchor box,A表示所有的anchor box,k表示一个超参数。输出P表示正例的集合,N表示负例的集合。
- 该方法根据目标的相关统计特征自动进行正负样本的选择,对于每个GT(groundTruth) box g,首先在每个特征层找到中心点最近的k个候选anchor boxes(非预测结果),计算候选box与GT间的IoU D g D_g Dg,计算IoU的均值 m g m_g mg和标准差 v g v_g vg,得到IoU阈值 t g = m g + v g t_g=m_g+v_g tg=mg+vg,最后选择阈值大于 t g t_g tg的box作为最后的输出。如果anchor box对应多个GT,则选择IoU最大的GT。
手工制作的技术严重依赖专业知识和繁琐的试验。近年来,NAS在发现和优化网络架构方面取得了可喜的成果,例如MobileNetV3、EfficientNet和Mnasnet。因此,NAS可能是产生具有更好的效率-准确度折衷的检测器的极好选择。
One-shot NAS方法通过相互共享相同的权重来节省计算资源。近年来,许多One-shot NAS致力于图像分类,如ENAS,SMASH。很少有人尝试开发用于对象检测的NAS。NAS-FPN搜索特征金字塔网络(FPN)。DetNas首先在ImageNet上训练超网主干,然后在COCO上微调超网。MobileDets使用NAS,并提出了一个扩展的搜索空间家族,以在移动设备上实现更好的延迟准确性折衷。

Approach
Better Backbone
Manually Designed Backbone:基于许多实验,发现ShuffleNetV2在移动设备上比其他网络更健壮。为了进一步提高ShuffleNetV2的性能,遵循PP-LCNet的一些方法来增强网络结构,构建新的主干,即Enhanced ShuffleNet (ESNet)。
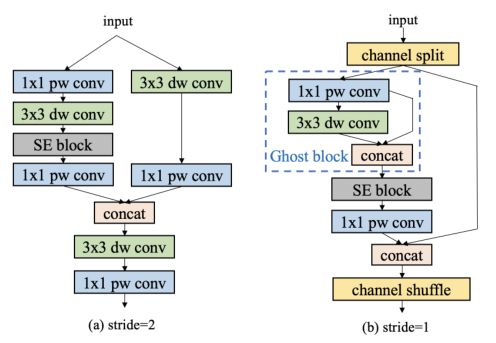
下图详细描述了ESNet的ES模块。SE模块很好地对网络信道进行了加权,以获得更好的特性。本文将SE模块添加到所有块中。与MobileNetV3一样,SE模块的两层激活函数分别是ReLU和H-Sigmoid。信道Shuffle提供了ShuffleNetV2信道的信息交换,但是它造成了融合特征的损失。
为了解决这个问题,增加了深度方向卷积和点方向卷积,以便在步长为2时整合不同的通道信息(下图a)。GhostNet的作者提出了一种新颖的Ghost模块,可以用更少的参数生成更多的特征图,提高网络的学习能力。在stride设置为1的块中添加了Ghost模块,以进一步增强我们的ESNet的性能(下图b)。
- ES块架构。(a)步幅=2的ES块;(b)步幅=1的ES块。
Neural Architecture Search:提出了一次努力的one-shot searching的目标探测器。配备有用于分类的高性能主干的对象检测器可能由于不同任务之间的差距而不是最佳的。不搜索更好的分类器,而是直接在检测数据集上训练和搜索检测超网,检测而不是分类的显著计算节省和优化。该框架简单地由两个步骤组成:
- (1)在检测数据集上训练一次性超网,
- (2)用进化算法在训练好的超网上进行结构搜索。
- 简单地使用逐通道搜索主干。给出了灵活的比率选项来选择不同的通道比率。在[0.5,0.675,0.75,0.875,1]中随机粗选比值。例如,0.5表示宽度是整个模型的0.5倍。可被8整除的通道数可以提高硬件设备上推理时间的速度。
- 因此,没有使用原始模型中的通道号,而是首先使用每个阶段块的通道号[128,256,512]来训练整个模型。所有比率选项也可以保持通道数被8整除。所选择的比率适用于每个块中的所有可修剪卷积。所有输出通道都固定为完整模型。为了避免繁琐的超参数调整,修复了架构搜索中的所有原始设置。
- 对于训练策略,采用sandwich rule对最大(完整)和最小的子模型进行采样,并对每个训练迭代随机采样六个子模型。在训练策略中不再采用额外的技术,例如蒸馏,因为不同的技术对于不同的模型表现不一致,特别是对于检测任务。最后,选定的架构在ImageNet数据集上重新训练,然后在COCO上训练。
- sandwich rule:在每次迭代中,以最小宽度、最大宽度和(n−2)随机宽度训练模型,而不是n个随机宽度,该方法有很好的收敛性和整体性能。可以在训练时明确地跟踪模型的验证准确性,这也表明了网络的性能下界和上界。
CSP-PAN and Detector Head
- 使用PAN结构获得多级特征图,并使用CSP结构在相邻特征图之间进行特征连接和融合。CSP结构广泛应用于YOLOv4和YOLOX的颈部。
- 在最初的CSP-PAN中,每个输出特征映射中的通道号与来自主干的输入保持相同。对于移动设备来说,具有大信道数的结构具有昂贵的计算成本。通过1 × 1卷积使所有特征图中的所有通道号等于最小通道号来解决这个问题。
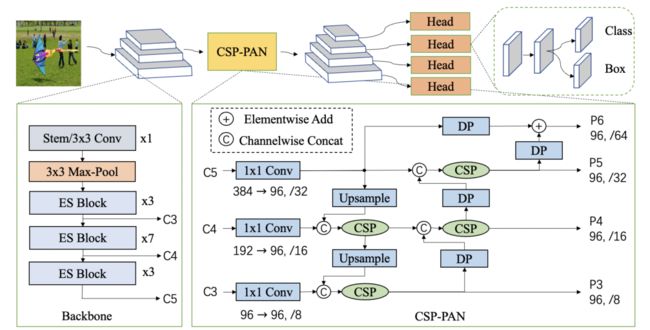
- 然后通过CSP结构使用自顶向下和自底向上的特征融合。按比例缩小的特征导致较低的计算成本和未受损的精度。此外,在CSP-PAN的顶部添加了一个特征地图比例,以检测更多的对象。同时,除1 × 1卷积外,所有卷积都是深度可分卷积。深度方向可分离卷积通过5 × 5卷积扩展感受野。这种结构以更少的参数显著提高了精度。具体结构如下图所示:
- PP-PicoDet架构。主干是ESNet,它向颈部输出C3-C5特征图。颈部是CSP-PAN,输入三个特征图,输出四个特征图。对于PP-PicoDet-S,输入通道号为[96,192,384],输出通道号为[96,96,96,96]。DP模块使用深度方向和点方向卷积。
- 在探测头中,使用深度方向可分离卷积和5 × 5卷积来扩展感受野。深度方向可分离卷积的数量可以设置为2、4或更多。整体网络结构如上图所示。颈部和头部都有四个分支。保持头部中的通道号与颈部模块一致,并耦合分类和回归分支。YOLOX使用通道数更少的去耦头来提高精度。耦合头在不减少通道数的情况下性能更好。参数和推理速度与解耦头几乎相同。
Label Assignment Strategy and Loss
阳性和阴性样品的标签分配对物体检测器有重要影响。大多数对象检测器使用固定标签分配策略。
RetinaNet直接用锚和ground-truth的IoU来划分正负样本。FCOS以中心点在ground-truth内部的锚点作为正样本,YOLOv4和YOLOv5选取ground-truth中心点的位置及其相邻锚点作为正样本。ATSS基于ground_truth周围的最近锚的统计特征来确定正样本和负样本。
上述标签分配策略在全局训练过程中是不变的。SimOTA是一种随着训练过程不断变化的标签分配策略,在YOLOX中取得了很好的效果。
使用SimOTA动态标签分配策略来优化训练过程。SimOTA首先通过中心先验确定候选区域,然后计算候选区域内预测盒和ground-truth的IoU,最后通过对每个ground-truth的n个最大IoU求和得到参数κ。
成本矩阵通过直接计算候选区域中所有预测盒和ground-truth的损失来获得。对于每个ground-truth,对应于最小κ损失的锚被选择并被分配为正样本。
最初的SimOTA使用CE损耗和IoU损耗的加权和来计算成本矩阵。为了调整SimOTA中的成本和目标函数,使用Varifocal损失和GIoU损失的加权和作为成本度量。GIoU损失的权重是λ,它被设置为6,如实验所示。具体公式是:
c o s t = l o s s v f l + λ ⋅ l o s s g i o u cost=loss_{vfl}+\lambda·loss_{giou} cost=lossvfl+λ⋅lossgiou
在检测头中,对于分类,使用Varifocal loss来耦合分类预测和质量预测。对于回归,使用GIoU损失和Distribution Focal Loss。公式如下:
l o s s = l o s s v f l + 2 ⋅ l o s s g i o u + 0.25 ⋅ l o s s d f l loss=loss_{vfl}+2·loss_{giou}+0.25·loss_{dfl} loss=lossvfl+2⋅lossgiou+0.25⋅lossdfl
在上述所有公式中,lossvfl表示V焦点损失,lossgiou表示giou损失,lossdfl表示分布焦点损失。
Other Strategies
- 近年来,出现了更多超越ReLU的激活函数。在这些激活函数中,H-Swish是Swish激活函数的简化版本,计算速度更快,对移动设备更友好。将检测器中的激活功能从ReLU替换为H-Swish。在保持推理时间不变的情况下,性能显著提高。
- 与线性步长学习率衰减不同,余弦学习率衰减是学习率的指数衰减。余弦学习率平滑下降,有利于训练过程,尤其是批量较大时。
- 对于轻量级模型,过多的数据扩充总是会增加正则化效果,并使训练更难收敛。因此,在这项工作中,只使用随机翻转,随机裁剪和多尺度调整数据增加训练。
Experiments
Implementation Details
对于训练,使用动量为0.9、权重衰减为4e-5的随机梯度下降(SGD)。采用余弦衰减学习率调度策略,初始学习率为0.1。在8x32G V100 GPU设备上,批量大小默认为80x8。训练300个epochs,花费2到3天。
所有实验都在COCO-2017训练集上用80个类别和118k张图像进行训练,并在COCO-2017验证集上用5000张图像使用单一尺度的标准COCO AP度量进行评估。
滑动平均(EMA)大量利用最近的信息,直观地保持长期影响。轻量级模型更容易陷入局部最优,并且更难收敛。因此,引入了一种类似于正则化的机制,名为Cycle-EMA,它通过一个遗忘步骤来重置历史的内容。
EMA:也叫做指数加权平均(exponentially weighted moving average),可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。
E M A T o d a y = ( V a l u e T o d a y ∗ ( S m o o t h i n g 1 + D a y s ) ) + E M A Y e s t e r d a y ∗ ( 1 − ( S m o o t h i n g 1 + D a y s ) ) EMA_{Today}=(Value_{Today}*(\frac{Smoothing}{1+Days}))+EMA_{Yesterday}*(1-(\frac{Smoothing}{1+Days})) EMAToday=(ValueToday∗(1+DaysSmoothing))+EMAYesterday∗(1−(1+DaysSmoothing))
其中Smoothing为滑动因子
对于架构搜索任务,用于超网训练的所有超参数和数据集的设置与原始模型相同。本文使用L2范数梯度截断,以避免爆炸梯度。另一个不同是,由于我们的搜索空间很大,所以我们为每一步训练八个候选人。
Gradient Clipping:随着神经网络层数的增多,会出现梯度消失或梯度爆炸问题。针对梯度爆炸问题,解决方案是引入Gradient Clipping(梯度裁剪)。通过Gradient Clipping,将梯度约束在一个范围内,这样不会使得梯度过大。
- 首先设置一个梯度阈值:clip_gradient
- 在后向传播中求出各参数的梯度,这里不直接使用梯度进去参数更新,求这些梯度的L2范数
- 然后比较梯度的L2范数||g||与clip_gradient的大小
- 如果前者大,求缩放因子clip_gradient/||g||, 由缩放因子可以看出梯度越大,则缩放因子越小,这样便很好地控制了梯度的范围
- 最后将梯度乘上缩放因子便得到最后所需的梯度
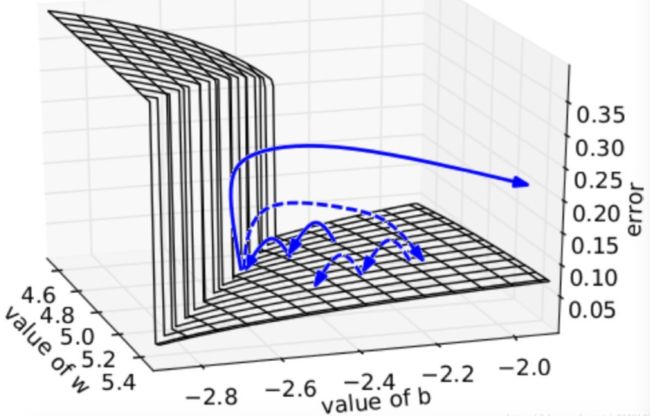
梯度爆炸的影响:在一个只有一个隐藏节点的网络中,损失函数和权值w偏置b构成error surface,其中有一堵墙,如下所示
损失函数每次迭代都是每次一小步,但是当遇到这堵墙时,在墙上的某点计算梯度,梯度会瞬间增大,指向某处不理想的位置。如果使用缩放,可以把误导控制在可接受范围内,如虚线箭头所示。
Ablation Study
所有消融实验的结果如下表所示。所有实验结果都在COCO-2017验证集上。
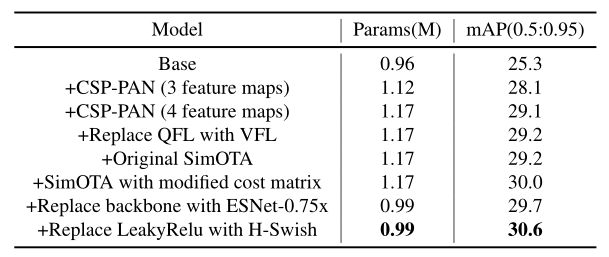
CSP-PAN:先得到类似NanoDet的模型,主干采用ShuffleNetV2-1x,颈部采用无卷积的PAN,损耗采用标准GFL损耗,标签分配策略采用ATSS。所有激活函数都使用LeakyRelu。得到的mAP(0.5:0.95)为25.3。此外,采用CSP-PAN结构。特征地图比例为3。mAP(0.5:0.95)增加到28.1。最后,在CSP-PAN的顶部添加一个特征地图比例尺。就像CSP-PAN的最终结构一样,参数数量增加不到50K。mAP(0.5:0.95)进一步提高到29.1。
Loss:比较了上一节中相同配置下的Varifocal Loss (VFL) 和Quality Focal Loss (QFL) 的影响。两者比较接近,Varifocal Loss的效果只比Quality Focal Loss略好。用VFL代替QFL,mAP(0.5:0.95)从29.1提高到29.2。
Varifocal Loss:设计了Varifocal Loss用来训练IACS,这是从Focal Loss演化而来的。Focal Loss的定义如下:
F L ( p , y ) = { − α ( 1 − p ) γ l o g ( P ) if y=1 − ( 1 − α ) p γ l o g ( 1 − P ) if otherwise FL(p,y)=\begin{cases} -\alpha(1-p)^{\gamma}log(P) &\text{if y=1}\\ -(1-\alpha)p^{\gamma}log(1-P) &\text{if otherwise}\\ \end{cases} FL(p,y)={−α(1−p)γlog(P)−(1−α)pγlog(1−P)if y=1if otherwise
α是用来平衡正负样本的权重, ( 1 − p ) γ (1-p)^{\gamma} (1−p)γ和 p γ p^{\gamma} pγ用来调制每个样本的权重,使得困难样本有较高的权重,避免大量的简单的负样本主导了训练时候的loss。借用了Focal Loss中的这种加权的思想,用Varifocal Loss来训练回归连续的IACS(预测一个和定位相关的分类得分,或者是IoU相关的分类得分,叫做IACS),和Focal Loss不一样的是,Focal Loss对于正负样本的处理是相同的,这里是不对等的,Varifocal Loss定义为:
V F L ( p , q ) = { − q ( q l o g ( p ) + ( 1 − p ) l o g ( 1 − p ) ) if q>0 − α p γ l o g ( 1 − P ) if q=0 VFL(p,q)=\begin{cases} -q(qlog(p)+(1-p)log(1-p)) &\text{if q>0}\\ -\alpha{p}^{\gamma}log(1-P) &\text{if q=0}\\ \end{cases} VFL(p,q)={−q(qlog(p)+(1−p)log(1−p))−αpγlog(1−P)if q>0if q=0
其中p是预测的IACS,q是目标IoU得分,对于正样本,q是预测包围框和gt框之间的IoU,对于负样本,q为0。
VFL只对负样本进行 p γ p^{\gamma} pγ 的衰减,这是由于正样本太少了,希望充分利用正样本的监督信号。另一方面,受到PISA和IoU-balanced Loss的启发,对正样本使用q进行了加权,如果正样本具有很高的gt_iou,那么,loss的贡献就要大一些,这样使得训练可以聚焦在那些质量高的样本上。为了平衡总体的正负样本,同样使用了α进行了负样本的加权。
Label Assignment Strategy:用原始SimOTA和本文修改SimOTA代替ATSS。发现n越大,效果越差。然后,参数n被设置为10。ATSS的性能几乎与原来的SimOTA相同。改进的SimOTA的mAP (0.5:0.95)达到30.0。
simOTA能够做到自动的分析每个gt要拥有多少个正样本。能自动决定每个gt要从哪个特征图来检测。相比较OTA,simOTA运算速度更快,避免额外超参数。simOTA标签匹配策略如下:
- 找到样本选择区间
- 计算区间内前十IOU之和,然后取整为a
- 取选择区间cost(小到大排序)前a个的正样本
- 取正样本的IOU为最后的IOU损失
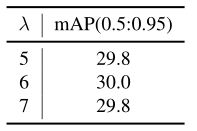
进一步比较了当Varifocal loss和GIoU损失具有不同权重时SimOTA的影响。改变公式 c o s t = l o s s v f l + λ ⋅ l o s s g i o u cost=loss_{vfl}+\lambda·loss_{giou} cost=lossvfl+λ⋅lossgiou的λ来进行消融实验。结果如下表所示。当GIoU损失的权重为6时,获得最好的结果。
- SimOTA在不同λ下的成本矩阵
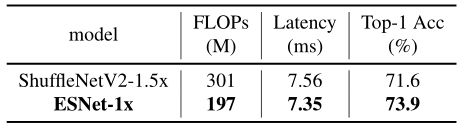
ESNet Backbone。在ImageNet-1k上比较了ESNet-1x和原始ShuffleNetV2-1.5x的性能。下表表明,用更少的推理时间,ESNet获得了更高的准确性
- ShuffleNetV2和ESNet(使用HSwish)的比较,批处理大小为1,CPU线程为4。
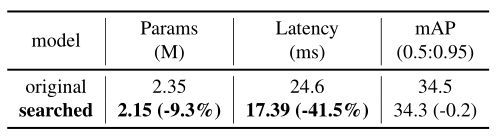
还比较了原始模型和本文搜索模型的性能,结果如下表所示。延迟约束下的搜索模型仅减少0.2% mAP,移动CPU推理时间加速41.5%(使用Paddle Lite时为54.9%)。当用ESNet0.75x替换了上面提到的检测器的主干,参数数量减少了近200K,mAP (0.5:0.95)最终为29.7。
- 设计模型与批量为1、CPU线程为4的NAS搜索模型的比较。
H-Swish Activation Function:将所有激活函数的LeakyRelu替换为H-Swish,mAP (0.5:0.95)最终增加到30.6。
Comparison with the SOTA
本文模型在准确性和速度上远远超过所有YOLO模型。这些成就主要归功于以下改进:
- (1)本文模型的颈部比YOLO系列的颈部更轻,因此颈部和头部可以分配更多的重量。
- (2)本文的处理类别不平衡的Varifocal损失、动态的和可学习的样本分配以及基于FCOS的回归方法的组合在轻量模型中表现得更好。
在相同的参数下,PP-PicoDet-S的mAP和延迟都优于YOLOX-Nano和NanoDet。PP-PicoDet-L的mAP和潜伏期均超过YOLOv5s。由于通过汇编语言进行了更有效的卷积算子优化,发现当使用PaddleLite时,本文的模型的推理测试性能甚至比使用NCNN更好。总之,本文的模型在很大程度上领先于SOTA模型。
- 各大互联网公司已经陆续推出了各自的移动端AI推理框架,开源免费,腾讯的NCNN、小米的MACE、阿里的MNN,百度的Paddle Lite
Conclusion and Future Work
- 提供一系列新的轻量级对象检测器,在移动设备的对象检测方面具有卓越的性能。PP-PicoDet-S模型是第一个mAP (0.5:0.95)超过30的模型,同时在ARM CPU上保持1M参数和100+ FPS。此外,PP-PicoDet-L模型的mAP (0.5:0.95)仅用3.3M的参数就超过了40。今后,将继续研究新技术,以提供更多高精度和高效率的探测器。