一文详解R-CNN、Fast R-CNN、Faster
文章来源:微信公众号《AI与计算机视觉》
1 引言
目标检测是一个重要的计算机视觉任务。它由图像分类任务发展而来,区别在于不再只是对一张图像中的单一类型目标进行分类,而是要同时完成一张图像里可能存在的多个目标的分类和定位,其中分类是指给目标分配类别标签,定位是指确定目标的位置也即是外围边界框的中心点坐标和长宽。因此,目标检测也可以作为图像分割、图像描述、动作识别等更复杂的计算机视觉任务的研究基础。
目标检测算法主要分为3个步骤:图像特征提取、候选区域生成与候选区域分类。其中,图像特征提取是整个检测流程的基石。传统算法普遍是基于人工设计的特征算子来描述图像,例如SIFT特征、HOG特征等等。这些特征算子普遍是基于人工设计的,因此很难获取复杂图像里的语义信息。2012年,Krizhevsky等人提出的AlexNet在ILSVRC挑战赛的图像分类任务上以显著优势夺得了冠军,让人们看到了卷积神经网络强大的特征表示能力。自此,基于深度学习的研究热潮拉开了帷幕。在之后的几年里,VGGNet、GoogLeNet、ResNet等更强大的分类网络相继问世。由于它们能够提出非常抽象的特征,因此除了完成图像分类任务之外,还普遍被用作更复杂的计算机视觉任务的骨架网络(backbone),其中就包括目标检测。2014年,Girshick等人提出的R-CNN算法在PASCAL VOC检测数据集上以绝对优势攻击了传统的DPM算法,为目标检测开启了一个新的里程碑。自此,深度学习算法在目标检测的研究领域里占据了绝对的主导地位,并一直持续至今,近年有很多综述文献对此进行了详细的调研。
基于深度学习的目标检测算法主要分为两个流派:(1)以R-CNN系列为代表的Two-Stage算法;(2)以SSD、YOLO为代表的One-Stage算法。具体来说,Two-Stage算法首先在图像上生成候选区域,然后对每一个候选区域依次进行分类与边界回归;而One-Stage算法则是直接在整张图像上完成所有目标的定位和分类,省去了生成候选区域这一步骤。两种流派各有优势,通常来说,前者精度更高,后者速度更快。本文以One-Stage算法中的Faster R-CNN算法为例,详细介绍Faster R-CNN算法的发展历程和算法原理,并分析了该算法的优缺点和具体案例。最后根据现有的目标检测算法中存在的问题和挑战,对未来发展趋势作了思考和展望。
2 算法发展进程及原理
Faster R-CNN的前身是R-CNN和Fast R-CNN,为了更好的讲解Faster R-CNN算法,本文将会把这三种算法的网络结构、算法实现细节和损失函数进行相关的分析和研究。
2.1 R-CNN算法

图1 R-CNN网络结构图
从图1中可以看出,R-CNN主要包括以下几个方面的内容:
① Extract region proposal,使用selective search的方法提取2000个候选区域;
② Compute CNN features,使用CNN网络计算每个proposal region的feature map;
③ Classify regions,将提取到的feature输入到SVM中进行分类;
④ Non-maximum suppression,用于去除掉重复的box;
⑤ Bounding box regression,位置精修,使用回归器精细修正候选框的位置。
2.1.1 候选建议框选取
R-CNN使用了selective search这个方法来选择候选区域,输入一张图片,selective search根据以下的步骤生成regionproposals:
① 使用一种过分割方法,将图片分割成比较小的区域;
② 计算所有邻近区域之间的相似性,包括颜色、纹理、尺度等;
③ 将相似度比较高的区域合并到一起;
④ 计算合并区域和临近区域的相似度;
⑤ 重复3、4过程,直到整个图片变成一个区域。
在每次迭代中,形成更大的区域并将其添加到区域提议列表中。这种自下而上的方式可以创建从小到大的不同scale的Region Proposal,如图2所示。
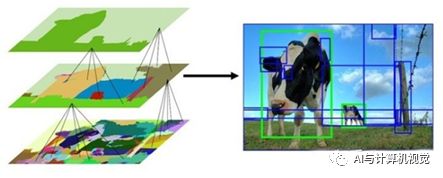
图2 R-CNN区域建议框选取
2.1.2 计算卷积特征
2.1.2.1 剪裁候选区域
由于文中使用的CNN中包含有全连接层,这就需要输入神经网络的图片有相同的size,但是Selective Search提取的Region Proposal都是不同size的,所以需要对每个Region Proposal都缩放到固定的大小(227*227)。paper试验了两种不同的处理方法:
(1)各向异性缩放
这种方法比较简单暴力,不考虑图片的长宽比例,不考虑图片是否扭曲,直接缩放到CNN输入的大小227*227。不过这种方法容易导致图片中目标发生严重形变,如下图3(D)所示。

图3 不同比例图片
2)各向同性缩放
先扩充后裁剪:直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪。如果已经延伸到了原始图片的外边界,那么就用boundingbox中的颜色均值填充。如上图3(B)所示。
先裁剪后扩充:先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如上图3(C)所示。
注:对于上面的异性、同性缩放,文献还有个padding处理,上面的示意图中第1、3行就是结合了padding=0,第2、4行结果图采用padding=16的结果。经过最后的试验,作者发现采用各向异性缩放、padding=16的精度最高。
2.1.2.2 训练卷积神经网络模型
利用Selective Search提取Region Proposal并resize后,接下来使用CNN(AlexNet、VGG)从每个Region Proposal提取特征。本文训练CNN的方法,主要包括以下两步:
(1)Pre-training阶段:由于物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法是不足以从零开始训练出一个好的CNN模型。基于此,本文采用的是有监督的预训练,使用一个大的数据集(ImageNet ILSVC 2012)来训练AlexNet,得到一个分类的预训练(Pre-trained)模型。
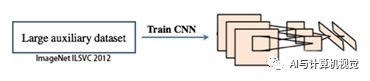
图4 预分类模型
(2)Fine-tuning阶段:使用RegionProposal(PASCAL VOC)对Pre-trained模型进行fine-tuning。首先将原来预训练模型最后的1000-way的全连接层(分类层)换成21-way的分类层(20类物体+背景),然后计算每个region proposal和ground truth 的IOU,对于IOU>0.5的regionproposal被视为正样本,否则为负样本(即背景)。在每次迭代的过程中,选取32个正样本和96个负样本组成一个mini-batch(128,正负比:1:3)。我们使用0.001的学习率和SGD来进行训练。

图5 微调网络模型
备注: 如果不针对特定任务进行fine-tuning,而是把CNN当作特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。例如:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征。
2.1.2.3 保存卷积提取特征
虽然R-CNN训练了CNN网络对region proposal进行分类,但是实际中,这个CNN的作用只是提取每个region proposal的feature。因此,我们输入region proposal进行前向传播,然后保存AlexNet的FC7层features,以供后续的SVM分类使用。
2.1.3 分类候选框
R-CNN使用SVM进行分类对于每一类都会训练一个SVM分类器,所以共有N(N=21)个分类器,下面具体来看一下是如何训练和使用SVM分类器的。
2.1.3.1 训练模型
如下图6所示,在训练过程中,SVM的输入包括两部分:

图6 SVM分类结构
(1) CNN feature:这个便是CNN网络为每个region proposal提取的feature,共2000*4096。
(2)Ground truth labels:在训练时,会为每个regionproposal附上一个label(标注好的labels称为Ground truth labels)。
在SVM分类过程中,当IOU<0.3时,为负样本,正样本便是ground truth box。然后SVM分类器也会输出一个预测的labels,然后用labels和groundtruth labels计算loss,然后训练SVM。
2.1.3.2 测试模型
Testing的过程就是输入经过之前的步骤得到test image的Region Proposal的feature,然后输出对2000个proposal的类别预测值。
2.1.4 非极大值抑制处理
经过SVM之后,我们会得到2000个region proposal的class probability,然后我们可以根据‘有无物体’这一类过滤掉一大批region proposal,然后如果某个候选框的最大class probability小于阀值,那也可以过滤掉这些region proposal,那剩下的可能如下左图所示,就是有多个box相互重叠,但是我们目标检测的目标是一个物体有一个box即可,那这个时候就需要用到非极大值抑制(NMS)了,经过NMS之后,最终的检测结果如下右图所示:

图7 非极大值抑制处理
2.1.5 边界框回归
目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要Bounding box regression步骤。如下图8,绿色的框表示Ground TruthBox, 红色的框为我们预测得到的Region Proposal。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IOU<0.5), 那么这张图相当于没有正确的检测出飞机。所以需要对红色的框进行微调,使得经过微调后的窗口跟Ground Truth Box更接近,这样就可以更准确的定位。图9是表示R-CNN的整个流程。

图8 真实框与预测框对比
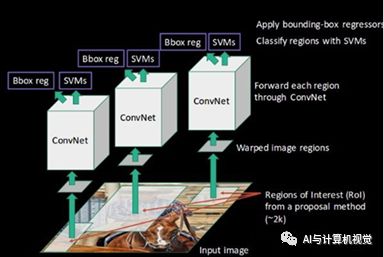
图9 R-CNN整体流程图
2.1.6 R-CNN算法不足
训练时间长:主要原因是分阶段多次训练,而且对于每个region proposal都要单独计算一次feature map,导致整体的时间变长。
占用空间大:主要原因是每个region proposal的feature map都要写入硬盘中保存,以供后续的步骤使用。
multi-stage:文章中提出的模型包括多个模块,每个模块都是相互独立的,训练也是分开的。
测试时间长:由于不共享计算,所以对于test image,也要为每个proposal单独计算一次feature map,因此测试时间也很长。
2.2 Fast R-CNN算法
继2014年的R-CNN之后,Ross Girshick在15年推出Fast RCNN,构思精巧,流程更为紧凑,大幅提升了目标检测的速度。同样使用最大规模的网络,Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
2.2.1 基本结构
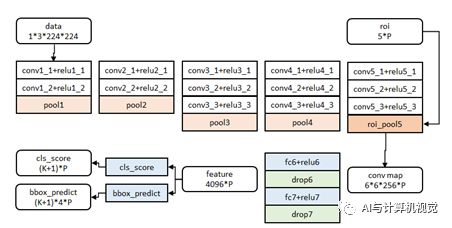
图10 网络结构图
图像归一化为224x224的大小作为网络的输入。前五个阶段是基础的conv+relu+pooling的形式,之后输入P个候选区域,放在ROI Pooling层,经过全连接层后进行分类和回归。
2.2.2 ROI Pooling层
Roi pooling层将每个候选区域均匀分成MxN块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
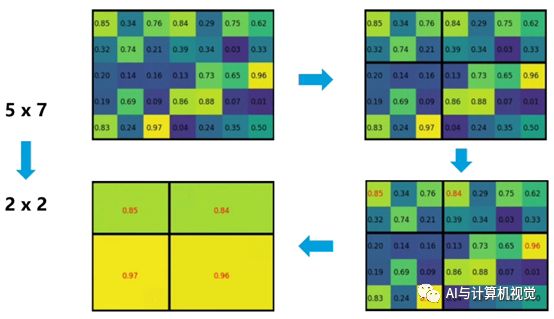
图11 ROI Pooling原理图
2.2.3 改进
①卷积不再是对每个Region Proposal进行,而是直接对整张图像。
②用Roi Pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把Region Proposal作为输入。
③ 用SoftMax代替原来的SVM分类器。
2.2.3 优缺点
(1)Fast RCNN与RCNN相比有如下优点:
①测试时的速度得到了提升。RCNN算法与图像内的大量候选帧重叠,导致提取特征操作中的大量冗余。而Fast RCNN很好地解决了这一问题。
②训练时的速度得到了提升。
③训练所需的空间大。RCNN中分类器和回归器需要大量特征作为训练样本,而Fast RCNN则不再需要额外的存储。
(2)Fast RCNN仍存在的不足:
①由于使用的Selective Search选择性搜索,这一过程十分耗费时间。
② 由于使用Selective Search来预先提取候选区域,Fast RCNN并未实现真正意义上端到端的训练模式。
2.3 Faster R-CNN
经过R-CNN和Fast RCNN的积淀,Ross B. Girshick在2016年提出了新的Faster R-CNN,在使用VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升,该算法在2015年的ILSVRV和COCO竞赛中获得多项第一。Faster RCNN摒弃了传统的滑动窗口和选择性搜索方法,直接使用RPN生成检测框,这也是Faster RCNN的巨大优势,能极大提升检测框的生成速度。Faster R-CNN的网络结构如图12所示。
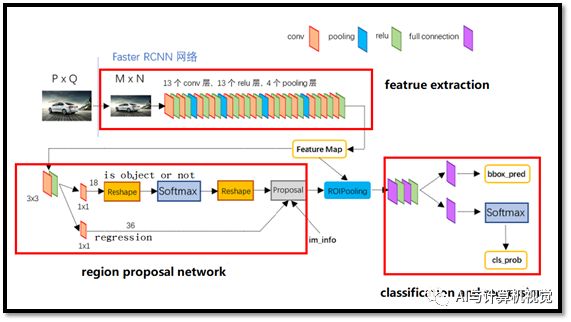
图12 Faster R-CNN结构图
2.3.1主干提取网络
Faster R-CNN第一步是采用基于分类任务的卷积神经网络模型作为特征提取器,其最早是采用在ImageNet上训练的ZF和VGG网络模型,其后出现了很多其它权重不同的网络。如一种小型高效的网络结构MobileNet,模型大小仅有3.3MB;随后出现的ResNet-152的参数量虽然达到了60MB,但残差结构使得深度模型的训练更加容易。再到新的网络结构DenseNet,在提高了结果准确度的同时,大大降低了参数数量。VGG和ResNet网络结构图如下所示。
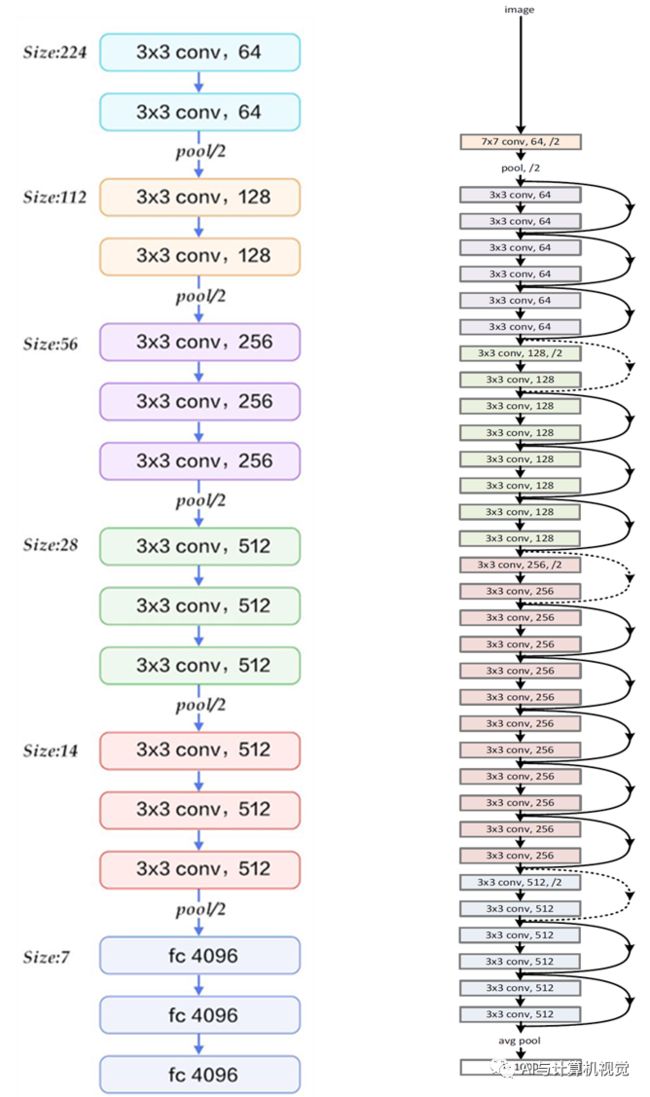
图13 VGG网络结构 图14 ResNet网络结构
2.3.2 RPN模块
RPN(Region Propose Network)模块对提取的卷积特征图进行处理。用于寻找可能包含objects的预定义数量的区域(regions,边界框)。这是Faster R-CNN最核心的改进,在基于深度学习的目标检测中,最难的问题就是生成长度不定的边界框列表。在构建深度神经网络时,最后的网络输出一般是固定尺寸的张量输出(采用RNN的除外)。例如在图片分类中,网络输出是形状为(N, )的张量,N是类别标签数,张量的每个位置的标量值表示图片是类别的概率值。在RPN 中,通过采用anchors来解决边界框列表长度不定的问题,即在原始图像中统一放置固定大小的参考边界框而不同于直接检测objects的位置。RPN网络的基本结构如下图15所示。
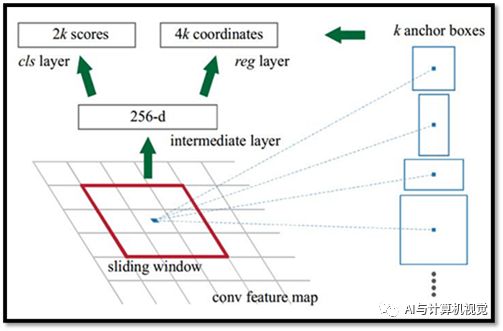
图15 RPN网络的基本结构
RPN模块主要执行的流程为输入Faster RCNN的公共Feature Map,生成Anchors,通过激活函数SoftMax提取并微调正样本Anchors,最后的Proposal Layer层负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除重叠和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能,其流程图如下图16所示。

图16 RPN网络流程图
3 案例分析与实验效果
前面讲解了Faster R-CNN算法发展进程史以及其算法原理,下面就具体展示使用Faster R-CNN算法实现的3个具体解决实际问题的应用案例:多目标识别、血细胞检测、驾驶员驾驶检测。
3.1 多目标检测
第一个案例是多目标检测,使用到的数据集是Pascal VOC数据集,该数据集是2005年至2012年开展的一个关于视觉对象的分类识别和检测一个比赛,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统,简称为PASCAL VOC(Pattern Analysis, Statical Modeling andComputational Learning)挑战赛。
Pascal VOC竞赛的目标主要是进行图像的目标识别,其提供的数据集包含20类的物体。
每张图片都有标注,标注的目标物体包括人、动物(猫、狗、鸟、牛、狗、马、羊)、交通工具(车、船、飞机、汽车、摩托车、火车、巴士)、家具(如椅子、桌子、沙发等)在内的20个类别,如下图所示:

图17 Pascal VOC 20个类别分类效果图
检测效果图如下,我们可以从图中看到,多目标检测效果达到了十分好的效果,即使灯光不是十分明亮的情况下,检测的物体数量多、概率高。

图18 目标检测效果图
3.2 血细胞检测
第二个应用案例是医学中的血细胞检测,使用的数据集是BCCD(Blood Cell Classification Datasets),该数据集是医学影像中一个比较古老的数据集,该数据集总共364张图像,包括白细胞WBC(White Blood Cell)、红细胞RBC(Red Blood Cell)、血小板Platelets总共3个类别的图像,类别图如下所示,黄色框代表红细胞,紫色框代表白细胞、粉色框代表白小板。

图20 血细胞类别图
总共的目标标签数为4888个,分布图如下,其中红细胞标签个数最多,白细胞和血小板标签个数差不多相同。
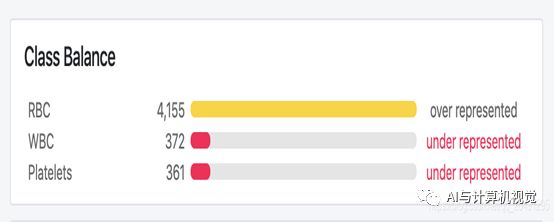
图21 血细胞各类别数量
使用Faster R-CNN检测血细胞效果图如下所示,我们可以看到达到了基本的检测效果,这可以应用在医学中进行细胞不同种类的检测和统计,从而帮助医生进行医学诊断。

图22 血细胞检测效果图
3.3 驾驶员驾驶检测
最后一个应用案例是驾驶员驾驶检测,这里需要自己制作数据集,制作数据集使用到的工具是LabelImg,标注界面如下:

图23 LabelImg制作标签
目标标注信息以xml文件格式进行存储,标注信息包括:标注图片的存储路径、图像的大小、标注目标的名称、标注目标框的左上角和右下角的位置坐标,如下图24所示:
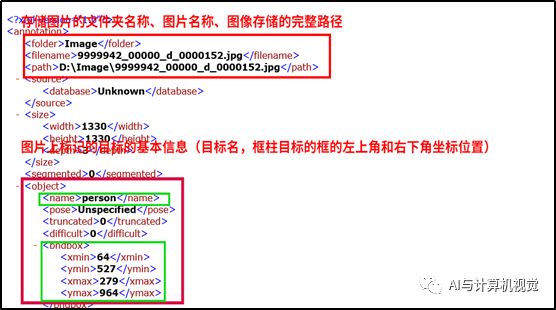
图24 LabelImg生成的标签文件
我们首先检测方向盘、手机、人手这三个目标,然后通过检测框位置信息,通过几何运算得到目标的质心坐标,判断不同目标质心距离从而判断驾驶员在驾驶过程中是否进行规范驾驶,即在驾驶过程中是否玩手机,手是否放在方向盘上。最终的检测效果图如下图所示,这减少了车辆事故的发生,并且在智能车辆上得到应用。

图25 驾驶员驾驶部位检测效果图
4 未来展望
根据前面原理的介绍和案例效果的展示,可以发现FasterR-CNN系列算法的优缺点以及其改进的地方,具体细节见表1。
表1 Faster RCNN系列算法优缺点比较
| 算法 |
使用方法 |
缺点 |
改进 |
| R-CNN (Region-based Convolutional Neural Networks) |
①SS提取RP ②CNN提取特征 ③SVM分类 ④Bounding Box回归 |
①训练步骤繁琐(微调网络+训练SVM+训练bbox) ②训练、测试速度慢 ③训练占空间 |
①从DPM HSC的34.3%直接提升到了66%(mAP) ②引入RP+CNN |
| Fast R-CNN (Fast Region-based Convolutional Neural Networks) |
①SS提取RP ②CNN提取特征 ③SoftMax分类 ④多任务损失函数边界框回归 |
①依旧使用SS提取RP(耗时2-3s,特征提取耗时0.32s) ②无法满足实时应用,没有真正实现端到端训练 ③使用了GPU,但是区域建议方法是在CPU上实现的 |
①mAP由66.9%提升到70% ②每张图像耗时约为3s |
| Faster R-CNN (Fast Region-based Convolutional Neural Networks) |
①RPN提取RP ②CNN提取特征 ③SoftMax分类 ④多任务损失函数边界框回归 |
①还是无法达到实时检测目标 ②获取Region Proposal,再对每个Proposal分类,计算量还是比较大 |
①提高了检测精度和速度 ②真正实现了端到端的目标检测框架 ③生成建议框仅需10ms |
由表由表1可知,R-CNN系列的目标检测经过一步步地改进和演化得到最后的Faster R-CNN算法,算法无论在精度上还是在速度上都有很大的提升。但是依然没有办法达到实时的目标检测效果,因此后面引入了One-Stage的目标检测算法,比较的典型的例子就是SSD和YOLO系列,SSD算法可以达到59FPS,YOLO系列算法最快的可以140FPS,这已经在实时性做了很大的改进,但是对于要达到实际的应用要求还有很长的路要走。第二个面临的挑战是对小目标的检测还是不准确,甚至基本都检测不到小目标,所以未来需要改进算法,增强对小目标的识别情况。
关于目标检测的未来,或许要与实例分割结合起来,我们不仅要检测出目标类别,还要识别出该目标是什么,比如它属于什么猫,对于人的话就是识别出具体的人。再一个方向是与人机交互结合起来,目标检测最终的目的就是实现机器看懂世界,将目标检测应用于自动驾驶、智能机器人等领域将是未来目标检测所能达到的应用水平。
参考文献
[1]Girshick R, Donahue J, Darrell T, et al. Rich Feature Hierarchies for AccurateObject Detection and Semantic Segmentation[J]. IEEE Computer Society, 2013.
[2]Girshick R. Fast R-CNN[J]. Computer Science, 2015.
[3]Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks[J]. IEEE Transactions on PatternAnalysis & Machine Intelligence, 2017, 39(6):1137-1149.
[4]Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[J].Springer, Cham, 2016.
[5]Lin T Y, Dollar P, Girshick R, et al. Feature Pyramid Networks for ObjectDetection[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). IEEE Computer Society, 2017.
[6]Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-TimeObject Detection[C]// Computer Vision & Pattern Recognition. IEEE, 2016.
[7]Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[J]. IEEE Conference onComputer Vision & Pattern Recognition, 2017:6517-6525.
[8]Redmon J, Farhadi A. YOLOv3: An Incremental Improvement[J]. arXiv e-prints,2018.
[9]Bochkovskiy A, Wang C Y, Liao H. YOLOv4: Optimal Speed and Accuracy of ObjectDetection[J]. 2020.
[10]Le T, Zheng Y, Zhu C, et al. Multiple Scale Faster-RCNN Approach to Driver'sCell-Phone Usage and Hands on Steering Wheel Detection[C]// Computer Vision& Pattern Recognition Workshops. IEEE, 2016.
[11]史凯静, 鲍泓, 徐冰心,等. 基于Faster RCNN的智能车道路前方车辆检测方法[J]. 计算机工程, 2018(7):36-41.
[12]艾曼. 基于Faster-RCNN的车牌检测[J]. 计算机与数字工程, 2020, v.48;No.363(01):179-182.