【亲测】Swin-Transformer 自定义数据集图像分类
Swin-Transformer是当前热门的深度学习框架,适用于多种视觉任务,相关的原理,网上有很多资源,大家可自行查看,这里主要介绍其在图像分类方面的代码调试经验,方便各位快速上手实验。Swin-Transformer代码链接点击进入

实验环境及配置:
Pytorch: 1.7.1
CUDA: 10.1.243 版本(使用 nvcc --version 查看)
GPU:显存8G
操作系统: Centos 7
1 环境配置
其实根据官方的配置步骤,可以实现快速的配置,但是在进行到 Nvidia apex 那个步骤的时候,可能会出现一些问题,因为可能我们不是那么容易安装 apex 这个加速框架,等下会进一步介绍。下面先按照代码官方的配置过程来:
1.1 下载官网代码,也可以用官网推荐的以下命令:
git clone https://github.com/microsoft/Swin-Transformer.git (可能会出翔网络问题)
cd Swin-Transformer (进入下载的文件夹)
如果您的网络有问题,不能使用以上命令下载,则直接在官网界面点击下载 zip 压缩包,再进行解压就行。

1.2 创建并激活虚拟环境,使用以下命令:
conda create -n swin python=3.7 -y (其中虚拟环境 swin 名字,可以自定义)
conda activate swin (进入该虚拟环境)
1.3 确定自己GPU 安装的 CUDA 版本(运行时的版本),使用 nvcc -V (或 nvcc --version)使用 nvidia-smi 看到的是 CUDA 为驱动API版本,和运行时的版本不同,这个需要注意。
用于支持driver API的必要文件(如libcuda.so)是由GPU driver installer安装的。nvidia-smi就属于这一类API。
用于支持runtime API的必要文件(如libcudart.so以及nvcc)是由CUDA Toolkit installer安装的。一般后续安装各种包或库,需要此类CUDA编译,所以我们后来需要安装和这个版本对应的 cudatoolkit 版本。

下面是安装包或库,这个需要在 你刚才创建的那个虚拟环境下进行安装
1.4 安装 PyTorch==1.7.1 and torchvision==0.8.2 with CUDA==10.1:,这里的CUDA 和上面的运行时 API 一样。
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1 -c pytorch
1.5 安装 timm 包
pip install timm==0.3.2
PyTorch Image Models (timm)是一个图像模型(models)、层(layers)、实用程序(utilities)、优化器(optimizers)、调度器(schedulers)、数据加载/增强(data-loaders / augmentations)和参考训练/验证脚本(reference training / validation scripts)的集合,目的是将各种SOTA模型组合在一起,从而能够重现ImageNet的训练结果
1.6 安装 apex
官方安装语句,但是有时候 git 会因为网络问题,不能下载,且在运行下面第三句话时 pip 时会出现问题。所以我们尽量介绍另外的安装策略。
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
如果上面的 git 命令无法下载,则采用下面的策略:

解压下载的文件后,进那个 apex 文件夹就行

下面说下,我安装过程中出现的问题有:
1) 当然如果您上面的 cudatoolkit 版本没安装正确,同样也会报一个 mismatch 的错误,所以以上的安装一定要安装对版本。
2)同样如果直接运行第三句命令,还会报一个,apex 文件夹中没有 setup.py 文件等,此时注意到,上面的图中,在apex 文件夹外就有个 setup.py 把那个文件直接复制进 apex 文件夹,再次运行上面的 第三条命令,看看能不能顺利执行,如果最终成功了,恭喜您,如果没成功,不要着急,我还有另外的安装方式。
如果上文的命令不行,请使用下面的命令:
1 在 apex 文件夹中运行 python setup.py install
2 然后运行 python setup.py build 即可,然后编译为我后面截图那个文件夹,
3 把那个apex 复制到swin-tranformer 的代码目录,即可。
如果还不行, 可以直接使用 pip install apex 试试

这个是我编译好的apex 文件夹情况,

编译好的 apex 直接复制到 swin-transformer 文件夹

1.7 安装一些其他包:
pip install opencv-python==4.4.0.46 termcolor==1.1.0 yacs==0.1.8
以上就是环境配置,如果配置完全,即可进行下面的步骤了。
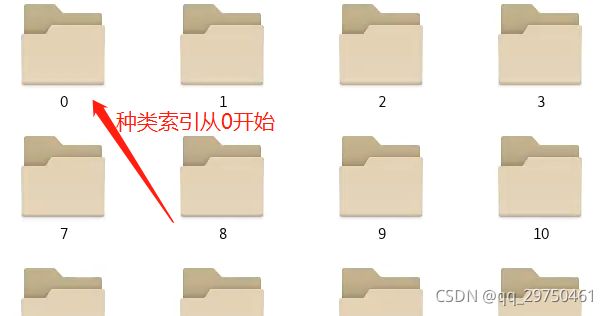
2 数据准备
数据集处理成 imagenet 的格式,即每个类别放在一个文件夹,最好是类名直接命名为数字形式,也可以是真是类标,然后将 训练集 验证集 测试集 分文件夹存储,每个文件夹的格式就像下面的 样子。

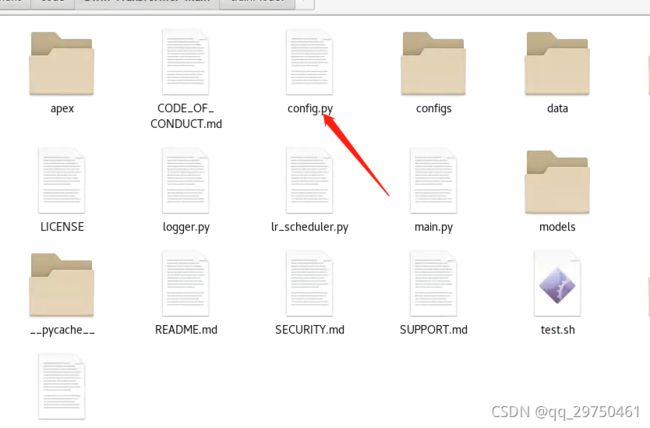
代码更改
1 打开 config.py , 将数据集的文件夹写进去,这样到时候训练时候,就不用再写了。
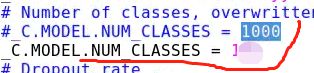
2 修改类别的数量,因为默认是 1000类,
3 下载预训练模型,并在 config.py中配置

使用百度云盘下载即可。

**![]()
**
还要改正几个地方,
1 build.py 中的 类别数数量

2 预训练模型加载过程中,由于自定义数据集类别未必是1000 所以需要改utils.py 中的这个函数,我这里是加了个判断,您也可以改为其他的形式。
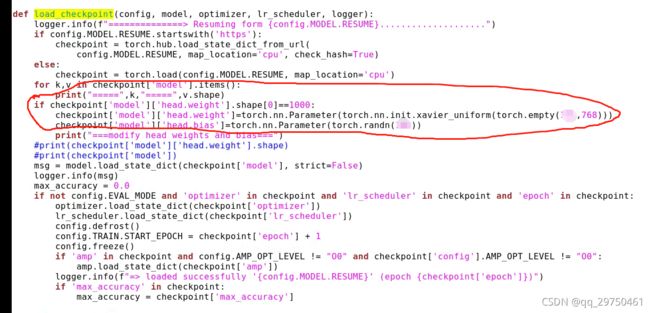
3 测试时候,需要将 数据集改为 test 数据集,因为代码默认 为验证集,在 build.py 中

单块GPU训练和测试的命令
训练
python -m torch.distributed.launch --nproc_per_node 1 --master_port 12345 main.py \
--cfg configs/swin_tiny_patch4_window7_224.yaml --batch-size 8
测试
python -m torch.distributed.launch --nproc_per_node 1 --master_port 12345 main.py --eval\
--cfg configs/swin_tiny_patch4_window7_224.yaml --resume 训练模型路径 --batch-size 8
【以上即为Swin-Transformer图像分类调试过程】
训练过程: