Voxel-RCNN论文和逐代码解析
1、前言
当前的3D点云目标检测主要分为两种方式,Voxel-based和Point-based。其中很多高性能的3D检测器都基于Point-base的方法,认为该方法表达的特征更具备物体的结构信息,取得更精确的box预测结果;但是point-base的方法因为不规则的数据结构,也让计算开销较大。相反Voxel-based的方法因为能将数据栅格化,更适合进行特征提取操作。
本文作者基于上述观点提出了自己不同的想法,认为精确的原始点云信息对于高性能的3D点云检测器不是必不可少的,同时提出使用粗粒度的voxel(coarse voxel granularity)信息同样可以得到不错的检测精度。
基于此观点,作者设计了Voxel-RCNN,一个基于voxel-based的简单有效的高性能3D点云检测器。为了能充分的利用体素特征(voxel feature)的,作者为此设计了 voxel ROI-Pooling用来提取来自体素的特征信息给二阶段的精调网络。网络结构总览如下图:
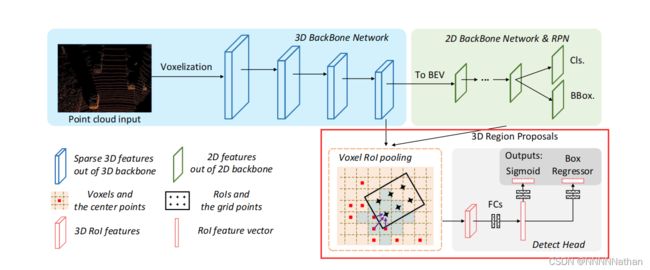
注:网络的整体结构可以视作SECOND加上我用红框框出的二阶调优过程,同时整体网络的结构与PV-RCNN十分相似,本文不会重头实现网络的所有模块和功能,如果对PV-RCNN或SECOND不熟悉的小伙伴建议先了解该部分内容,也可以看我之前的博客内容。
SECOND点云检测代码详解_NNNNNathan的博客-CSDN博客1、前言SECOND也是一片基于Voxel按anchor-based的点云检测方法,网络的整体结构和实现大部分与原先VoxelNet相近,同时在VoxelNet的基础上改进了中间层的3D卷积,采用稀疏卷积来完成,提高了训练的效率和网络推理的速度,同时解决了VoxelNet中角度预测中,因为物体完全反向和产生很大loss的情况;同时,SECOND还提出了GT_Aug的点云数据增强。没有了解过VoxelNet的小伙伴可以查看我的这篇文章:VoxelNet点云检测详解_NNNNNathan...https://blog.csdn.net/qq_41366026/article/details/123323578?spm=1001.2014.3001.5502
PV-RCNN论文和逐代码解析(一)_NNNNNathan的博客-CSDN博客1、前言当前的点云3D检测主要分为两大类,第一类为grid-based的方法,第二类为point-based的方法。grid-based的方法将不规则的点云数据转换成规则的3D voxels (VoxelNet, SECOND , Fast PointRCNN, Part A^2 Net)或者转化成 2D的BEV特征图(PIXOR, HDNet,PointPillars),这种方法可以将不规则的数据转换后使用3D或者2D的CNN来高效的进行特征提取。...https://blog.csdn.net/qq_41366026/article/details/123349889?spm=1001.2014.3001.5502
Voxel-RCNN论文地址:https://arxiv.org/pdf/2012.15712
Voxel-RCNN论文开源代码地址:GitHub - djiajunustc/Voxel-R-CNN
OpenPCDet仓库地址:GitHub - open-mmlab/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.
Voxel-RCNN(Towards High Performance Voxel-based 3D Object Detection)在OpenPCDet中的类流程图:

Voxel-RCNN的6个模块
1、MeanVFE
2、VoxelBackBone8x
3、HeightCompression
4、BaseBEVBackbone
5、AnchorHeadSingle
6、VoxelRCNNHead
注1:其中黑色部分均与SECOND中相同。
注2:第6点内容为Voxel-RCNN的二阶段调优实现,代码解析会直接从这里开始,前面的内容均与SECOND一致。
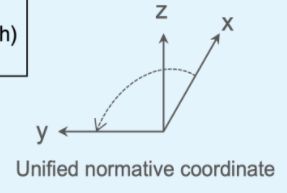
PCDet中的统一规范坐标:(X向前,Y向左,Z向上)
2、Voxel-RCNN设计思考:
Voxel-RCNN的设计初衷,是为了能够达到和point-based一样的精度同时要和Voxel-based的方法一样的快。因此,作者还是采用了基于Voxel-based的方法,并试图对他进行改造提升他的精度。所以,文中对比了PV-RCNN、SECOND两个经典的网络来进行分析。

注:在PV-RCNN中,也是通过SECOND的网络结构作为第一阶段的特征提取,但是同时也采取了关键点编码场景特征的方式来聚合不同尺度下3D卷积层特征;并在精调阶段,将对应的关键点特征融入proposal中,提高了网络的性能。
对比上图,可以发现,如果直接对SECOND加入二阶网络的box refinement操作,精度的提升也是十分有限, 说明BEV特征的表达能力受限,主要原因是现存的voxel-based的方法检测精度受限的主要原因来源于直接将经过3D的卷积的voxel feature直接在Z轴堆叠之后之后在BEV视角上进行检测,没有在中间的过程中恢复特征原有的3D结构信息。
秉持这个观点,在二阶网络的精调过程中融合来自3D卷积层中的3D结构信息。文章中对这部分的实现主要是使用voxel ROI pooling来提取proposal中相邻的voxel特征,并设计了一个local feature aggregation模块来进一步提升计算速度,因为作者比对了PV-RCNN各个模块的耗时,结果如下
可以看到最不同尺度的voxel进行关键点编码是十分耗时的。
总的来说总结如下:
1、3D的结构信息对于3D检测器十分重要,单纯使用来自BEV的特征表达对于精确的3D BBOX定位是有限的。
2、如果直接使用point-voxel的方式来生成编码特征是十分耗时的,影响了检测器的效率。
3、voxel ROI pooling
为了直接从经过3D卷积后的3D特征层上聚合空间信息,直接将每层3D特征层认为是一个的非空的Voxel的集合![]()
![]() ,和所有对应非空voxel的特征向量
,和所有对应非空voxel的特征向量
![]() ,同时每个voxel的3D中心坐标根据3D卷积的indice、voxel size(KITTI:[0.05,0.05,0.1],WAYMO:[0.1,0.1,0.2])、选取的点云的范围计算得来。
,同时每个voxel的3D中心坐标根据3D卷积的indice、voxel size(KITTI:[0.05,0.05,0.1],WAYMO:[0.1,0.1,0.2])、选取的点云的范围计算得来。
得到非空voxel的坐标和特征后,