YOLO v1详细解读
《You Only Look Once: Unifified, Real-Time Object Detection》
Joseph Redmon∗* , Santosh Divvala∗†, Ross Girshick*¶* , Ali Farhadi∗†
University of Washington∗ , Allen Institute for AI*†* , Facebook AI Research*¶**
发表时间及期刊:2016 CVPR
YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。
因为只需要看一次,YOLO被称为Region-free方法,相比于Region-based方法,YOLO不需要提前找到可能存在目标的Region。
也就是说,一个典型的Region-base方法的流程是这样的:先通过计算机图形学(或者深度学习)的方法,对图片进行分析,找出若干个可能存在物体的区域,将这些区域裁剪下来,放入一个图片分类器中,由分类器分类。
因为YOLO这样的Region-free方法只需要一次扫描,也被称为单阶段(1-stage)模型。Region-based方法方法也被称为两阶段(2-stage)方法。
对于YOLO v1而言,它在PascalVOC 2007测试数据集上达到的mAP是63.4%,在输入图像大小为448×448像素的图像上处理速度能够达到每秒45帧,该网络的一个小版本FastYOLO每秒处理速度也达到了惊人的155帧。
虽然YOLO v1的精度不及RCNN系列,但奈何其速度非常快,所以在工业界应用还是很普遍的。
本文主要通过四方面进行分析: 论文思想、网络结构、损失函数及不足
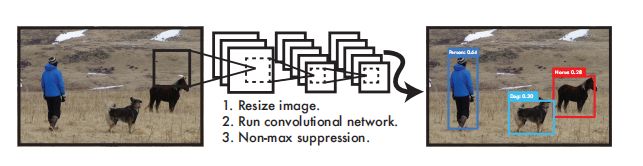
整体流程:
1. 缩放图像
2. 将图像通过卷积神经网络
3. 利用非极大值抑制(NMS)进行筛选
一.论文思想
1)图像划分
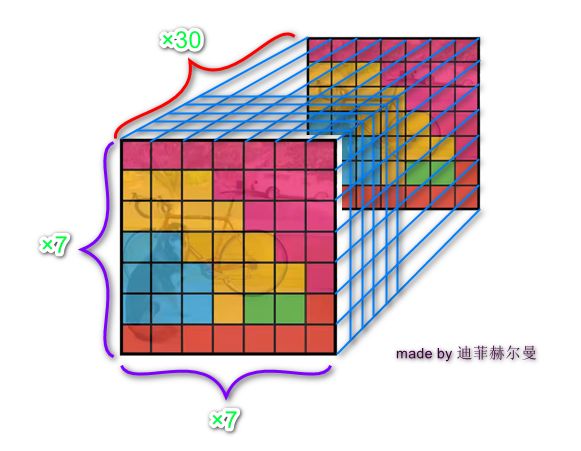
将一幅图片划分成S×S个网格(gird cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
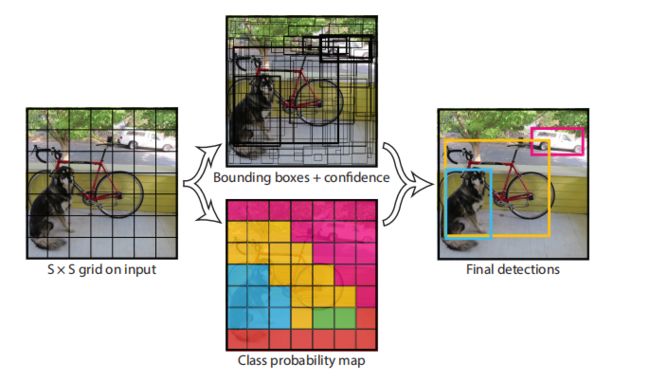
1号图中显示图片被分为 7 × 7 = 49个grid cell
2号图中显示每个grid cell生成2个bounding box(预测框),一共98个bounding box,框的粗细代表置信度大小,框越粗代表框住的是一个完整物体的概率越大
3号图中用不同颜色表示每个grid cell所预测的物体最可能属于分类,如蓝色的grid cell生成的最可能bounding box最可能框住的是狗、黄色的grid cell最可能预测自行车…
4号图为最终输出的显示效果
2) Bounding boxes 预测
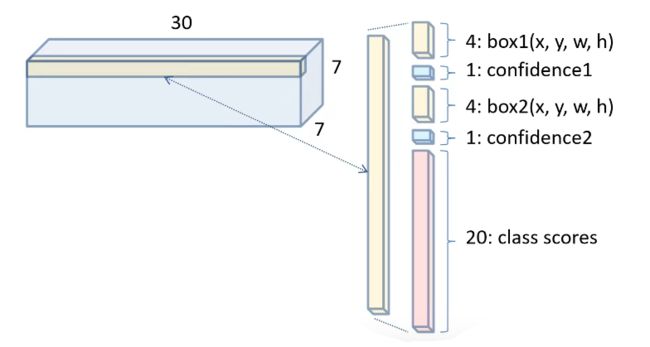
1.先看 bounding boxes + confidence 。在这一步中,YOLO 为每一个网格给出了两个预测框,这里有点像faster rcnn 的anchor ,但不完全相同。YOLO给出的预测框,是基于网格中心点的,大小自定义。每一个网格预测 B 个bounding boxes,每个bounding boxes 有四个坐标和一个置信度(confidence),所以最终的预测结果是 S × S × (B ∗ 5 + C)个向量。
2.再看第二个class probablity map,这一路的工作其实是和上一步是同时进行的,负责的是网格(gird cell)类别的分数,预测的结果一样是放在 最后的 7 × 7 × 30 的张量中
概括的讲就是:
训练过程:首先将图像分成 S × S 网格(gird cell)、然后将图像送入网络,生成S × S × (B ∗ 5 + C)个结果,根据结果求Loss并反向传播梯度下降。
预测过程:首先将图像分成 S × S网格(gird cell)、然后将图像送入网络,生成S × S × (B ∗ 5 + C)个结果,用NMS选出合适的预选框。

为了评估YOLO在PASCAL VOC数据集上的水平,我们使用S=7,B=2。PASCAL VOC有20个标签类,所以C=20。我们最终的预测是一个7×7×30张量。

每个边界框由5个预测组成:x、y、w、h和confidence。(x、y)坐标表示相对于网格单元格边界的方框的中心。并将其宽度和高度相对于整个图像进行了预测。

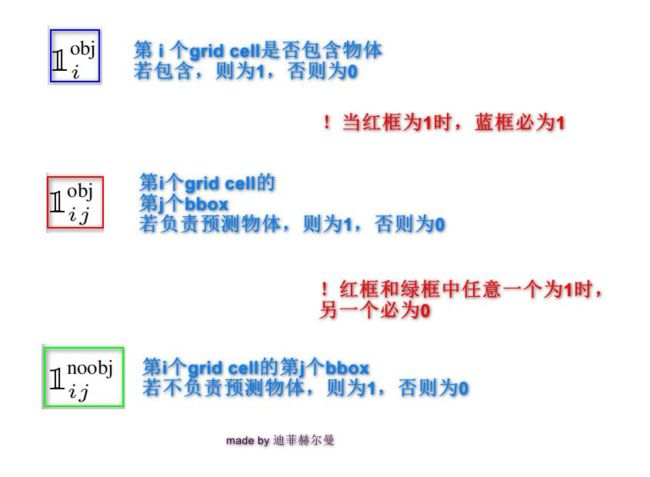
这里要说的就是confidence!
confidence是YOLO系列论文独有的一个参数,那什么是confidence呢?看图5,你可以理解为confidence有两种情况,分别是 “0”和“1”,当我们的网格中确实存在目标时,那我们图5中的Pr(Object)就是等于 “1” 的,所以我们预测的confidence就直接等于IOU,如果网格中没有目标落在里面,那么Pr(Object)就是等于 “0” 的,所以confidence就是等于零的。
其实我们完全可以把confidence理解为IOU,但是这里的IOU是我们预测的bounding box与真实的bounding box的交并比。YOLO v1中并没有像Faster RCNN或SSD的Anchor概念的,所以这里预测的x,y,w,h是直接预测我们bounding box的坐标信息的,并不是像我们在Faster RCNN或SSD当中预测的四个值都是相对Anchor的回归参数。

在测试时,也就是我们最终预测时,我们对于每个目标的最终概率是将conditional class probabilities 乘上 confidence 的,对于每个grid cell而言,它有C个类别,那我们就会预测C个类别分数,那么这里的类别分数就是对应的conditional class probabilities,也就是Pr(Classi|Object)
注意 Pr(Classi|Object)这里的写法涉及到概率学中的条件概率,懂得自动跳过就好
用白话解释“条件概率”就是:“指事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为:P(A|B),读作“在B的条件下A的概率”。
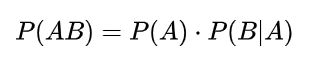
在我们这篇论文里就可以这样理解:类别i在它为目标的前提下的概率
那么通过图6我们知道,这两项相乘之后,最终给出的目标概率就是
![]()
通过这个表达式我们也能够知道,论文给出的这个表达式既包含了:它为某个目标的概率;也包含了我们预测的目标边界框与我们真实目标框的重合程度,这里与Faster RCNN和SSD中直接预测的目标概率是不一样的。
二.网络结构分析
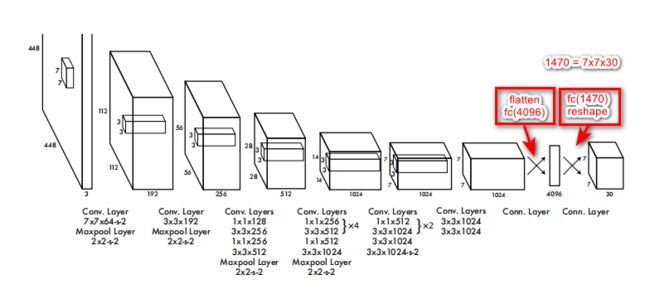
整个网络结构看似很简单,实则确实很简单!(“s-2”,意思就是步长为“2”,没写的就是默认步长为“1”)
整个检测网络有24个卷积层,后面跟了2个全连接层。交替的1×1个卷积层目的是减少前一层的特征。整个网络输入的是448 × 448的图片,最终得到的是7×7×30的张量。
所以说得到的7×7×30的张量到底是个啥?请看下面两幅图,这个7×7好理解,一共划分成7×7的网格,那么这30是什么呢?实际上这个30包含了两个预测框的参数和Pascal VOC的类别参数:每个预测框有5个参数:x,y,w,h,confidence;Pascal VOC里面还有20个类别;这样的话30 = (2 × 5)+ 20,也就是说这一个30维的向量就是一个gird cell的信息,那总共是7 × 7个gird cell一共就是7 × 7 ×(2 × 5+ 20)= 7 × 7 × 30 tensor = 1470 outputs,正好对应论文。
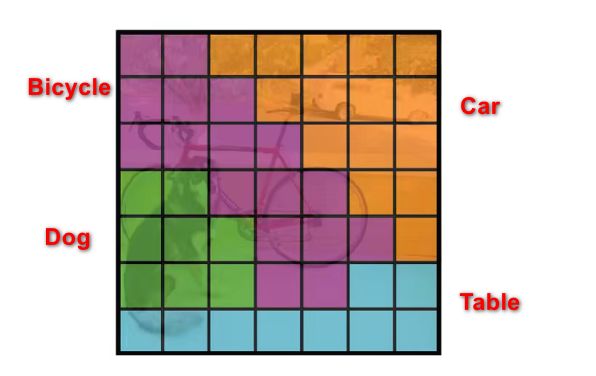
到这里就很清晰了,从图中我们可以看到每个gird cell还可以生成20个类别的条件概率,此图就展示了条件概率最高的那些类别所占有的框,也就是说,每个gird cell只能有一个类别,它会从这20个类别概率中选取概率最高的那一个,进而也说明了每个gird cell只能预测一个物体,那么7×7=49个gird cell最多只能预测49个物体,这也是YOLO v1对小密集物体识别差的原因,后面会谈到这一点。
三.损失函数详解

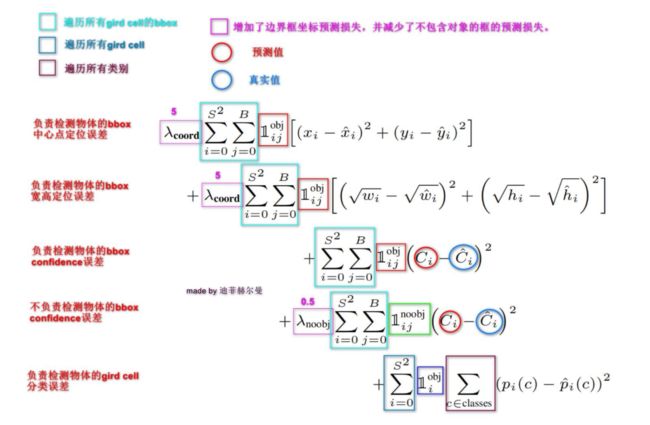
在损失函数这里作者每一项都用的平方和误差,将目标检测问题当作回归问题。
下面来看一下损失函数中每个参数的含义:
这里面有个值得注意的地方,就是宽高定位误差那里,这里作者取了一个根号,实际上这样做的目的就是使小框对误差更敏感一点。我觉得作者这样做的目的和RCNN边框回归中使用相对坐标差的想法是一样的,实际上就是尺度归一化。
四.YOLO v1不足

作者说YOLO v1对一些群体性的小目标检测效果很差,比如天空中成群结队的鸟儿,如果这群鸟每个目标都很小,那么YOLO就很难对他们进行预测,因为在我们YOLO v1的思想中,每个cell只预测两个bounding box,而且两个bounding box预测的还是属于同一个类别的。因为我们对每个grid cell都只预测一组classes参数,所以针对每个grid cell预测的是同一个类别的目标,所以说当一些小目标聚集在一起时YOLO v1的检测效果就非常的差。

第二个问题就是当我们的目标出现新的尺寸或者配置的时候,YOLO v1的预测效果也是非常的差。

最后一个问题就是作者发现主要的误差都是由于定位不准。这个问题主要是由于作者选择直接预测目标的坐标信息,而不是像Faster RCNN或SSD那样预测Anchor的回归参数,所以后续YOLO v2开始,作者就采用了Faster RCNN或SSD那样基于Anchor的回归预测。
五.检测效果展示
