单目深度估计 | Learning Depth from Monocular Videos using Direct Methods 学习笔记
文章目录
- 摘要
- 1. 论文主要贡献:
- 2. 从视频中学习预测深度
-
- 2.1 尺度模糊
- 2.2 建模姿态估计预测器
- 3. 可微分直接视觉测距法
-
- 3.1 直接视觉测距法(DVO)
- 3.2 可微分的实现
- 4 训练损失
- 5 实验
-
- 5.1 训练设置
- 5.2 KITTI数据集上的结果
- 5.3 Make3D数据集上的结果
- 6.讨论
- 深度估计系列文章:
Learning Depth from Monocular Videos using Direct Methods
会议: CVPR 2018
标题:《Learning Depth from Monocular Videos using Direct Methods》
论文链接: http://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_Learning_Depth_From_CVPR_2018_paper.pdf
摘要
利用CNN的最新进展预测单个图像的深度,越来越引起视觉界的兴趣
使用非监督的策略从单张图片中学习深度图非常的具有吸引力,因为它可以利用大量且种类丰富的单目视频数据库,无需标注真实的场景和深度信息。在之前的工作中,必须将确定单独的姿态和深度卷积神经网络分类器联合起来确定输出的测光误差最小化。受直接视觉测距法(DVO)最新进展的启发,我们认为深度卷积神经网络预测器可以在没有姿势CNN预测器的情况下学习。此外,我们还根据经验证明,与使用单目视频进行训练的最新技术相比,结合可微分的DVO实现以及新的深度归一化策略,可以显著提高性能。
1. 论文主要贡献:
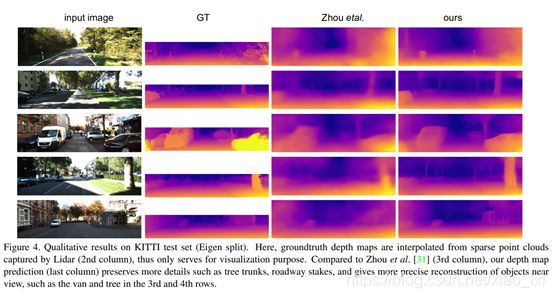
首先,从理论上描述和实证上论证了当前单目方法中尺度模糊的原因。具体地说,是在训练中深度正则化的使用导致了尺度敏感性,受直接视觉测距法相关工作的启发,我们提出了一种简单的标准化策略,避免了许多这些问题,并显著提高了性能。(见图1可以定性比较)
第二,我们认为学习一个额外的姿势预测CNN(我们在这里称之为姿势CNN)不是从单目视频用CNN估计深度最有效的策略。Zhou等人使用的Pose-Cnn,没有充分利用摄像机姿态和深度预测之间的关系,忽略了从深度进行姿态估计是一个具有已知的几何特性和良好的算法的值得研究得好问题。相反,我们在框架中引入一个直接视觉测距(DVO)位姿预测器。因为:1)它不需要可学习的参数。2)在输入密集深度地图和输出预测位姿之间建立一个直接联系,3)它是从相同的图片中得到重建损失,用来最小化我们全部的非监督训练基准。为了将DVO引入端到端的训练,我们提出了DVO的一种可微分实现(DDVO模块),使到达摄像机姿态预测器的后传播信号可以传播到深度预测器中。
最后,由于DVO是基于二阶梯度下降的方法,一个好的初始化点可以得到更好的结果。因此,我们没有从同一姿势启动DDVO模块,而是提出了一个混合的训练过程,使用预先训练的姿态CNN来提供初始化姿态。从经验上证明,这种混合方法比单用POSE-CNN或DDVO训练提供更好的性能,并达到了Gordard等人的结果,其结果在Kitti数据集上用标定的双目镜测试的最先进方法。
符号:小写黑体符号(如x)表示矢量,大写黑体符号(如W)表示矩阵,大写书法符号(如L)表示图像。我们还使用符号L(x):R^^ 2→R^^ k来表示k通道图像的子像素位置x=[x,y]处的采样。
此算法目前的不足:
1) 像人和摩托车这种动态场景效果不太好
2) 路面过度曝光,倒是大面积的纹理减少的情况
3) 大片纹理区域少的开阔场景

2. 从视频中学习预测深度
我们的目标是学习一个被θd参数化的函数fd(由CNN建模),θd是从单张图像L中预测到的逆深度图D,我们希望从更广泛的没有真实深度的可用数据源中学习,而不是有监督的学习。此外,我们不再局限于被标定好的双目摄像头,而是采用更普通的单目视频序列。
在介绍我们的端到端训练方式之前,值得一提的是另一种方法。考虑到连续视频帧之间的时间线索,可以先从SfM算法中获取辅助深度标注信息,然后利用其输出作为监督来学习深度信息估计。假设SFM算法可以简化为进行光度学束调整,从而将结合外观误差重叠、测量像素对应的差异性和一些先验成本优先级的成本函数最小化,从而促进深度图的平滑。这个过程可以总结为以下两部优化:
- 通过SfM算法计算逆深度图和像机姿态信息
- 通过公式1中得到的逆深度图信息作为监督信息来学习估计深度信息。

我们认为这两步优化在理论上是次优的。因为我们假设公式1中的SfM的成本函数反映了深度图预测的质量,所以我们真正想要的是找到θd,这将使成本降到最低。然而,在第二步中最小化等式2并不一定会导致最小化等式1。
因此,原则上,通过直接最小化等式1中的成本函数来对深度预测器进行端到端学习是最佳方法。然而,在实践中,由于等式1过于简单化了真实的SFM步骤,因此与具有梯度下降的端到端训练相比,从上述两步优化方法中获得更好的监督仍然是可能的。因此,如第3节所述,我们的一项贡献是将现代SLAM算法的一部分(例如,DVO)带入训练框架。



2.1 尺度模糊
为了解决这一问题,提出了一种新方法。在输入到损失层之前,应用非线性归一化深度cnn的输出。这里我们使用的算符η(·)是用下式除以输入张量

尽管这种标准化技巧也被用于LSD-SLAM中的关键帧选择,但它还没有被用于单目视频的学习深度估计。根据经验,我们发现这个简单的归一化技巧显著提高了结果(见图3),因为它消除了损失函数的尺度敏感问题。

2.2 建模姿态估计预测器

3. 可微分直接视觉测距法
3.1 直接视觉测距法(DVO)
DVO从参考图像L获取输入信息,它相应的深度图D和原图像L’。将像素坐标xi ∈ R 2的强度和逆深度在参考图像上分别表示为L(xi)和di,摄像机姿态由平移坐标t和指数坐标w联合表示,且摄像机内参已知,则从参考图像坐标xi到源图像坐标xi’的投影可以表示为:

利用高斯-牛顿方法可以有效地解决这个非线性最小二乘问题。为了提高计算效率,逆合成算法不像普通的高斯-牛顿方法那样线性逼近源图像,而是反转源图像和参考图像,并计算参考图像的参数更新。因此,雅可比矩阵和黑森矩阵不需要每次迭代都重新评估。我们将算法总结如下:


3.2 可微分的实现
我们对DVO的不同实现类似于反向组合空间变换网络,两种方法都迭代更新几何变换参数,并通过双线性采样反向扭曲源图像。区别在于,我们的“回归量”不是使用具有可学习参数的回归网络层,而是由等式13计算构成的。计算关于方程13的导数涉及微分矩阵伪逆。
4 训练损失
训练损失是外观损失和先验的平滑度损失的组合,通过4个尺度进行汇总。外观损失测量三组图像之间像素级对应的不同性(如图2所示)。先验损失对三联体图像的逆深度Di加强了平滑性,在第k尺寸上的损失可表示为:
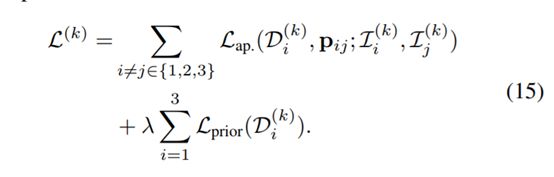
我们使用参数λ作为惩罚因子来控制先验平滑性。
外观差异性损失
如图2所示,我们测量了三个连续图像之间的外观差异损失。给出了由这些图像分别预测的逆深度图,以及相对于第二幅图像估计的两个相机外部图像,我们将第一幅和最后一幅图像的逆弯曲与第二幅图像进行了比较。我们也做相反的,比较第二个图像的逆向弯曲和其他两个图像。这种双向的外观损失使我们能够以最小的额外计算成本增加训练集。
通过深度CNN网络的输出的四个尺度来聚集外观相异性。对于三个较粗的尺度,我们使用L1光度损失;对于最后一个最细的标度,我们采用L1光度损失和单标度SSIM损失的线性组合。
逆深度平滑损失
我们使用二阶梯度作为平滑成本,以使深度预测具有更好的梯度。为了提高深度预测的清晰度,我们采用了两种策略:
(1)根据图像强度的拉普拉斯函数,给出了不同位置像素的平滑度代价的不同权重。如果拉普拉斯更高,这意味着像素更可能出现在边缘或角落,我们会在该位置施加较低的平滑度成本。
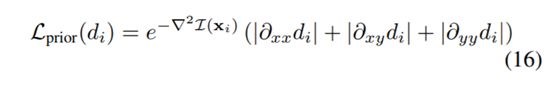
(2)我们不再直接从最终的逆深度估计中计算平滑成本,而是将逆深度图按因子2简化为三个更粗的尺度。我们只从两个最粗的尺度来计算平滑度成本。
5 实验
实验在KITTI数据集上进行训练。
设置训练集
我们首先通过检查光流的平均大小是否小于1像素来去除静态帧。每个训练样本是一个3个连续视频帧的短片段,大小调整为128×416像素。
深度卷积神经网络框架
该网络类似U-Net网络结果。包括一个编解码设计,在编码器和解码器网络之间跳过中间特性的连接,并使用VGG作为其编码器网络结构。我们也在解码器的末尾输出多尺度逆深度预测。由于逆深度在0(无穷大)和与相机的最小深度的逆之间,所以我们将sigmoid非线性应用于网络输出。此外,我们将最终反深度输出乘以10,将其限制在一个合理的范围内,并添加一个小值0.01,以提高数值稳定性。
Pose-CNN 结构
我们使用CNN架构,它从三个连续帧中获取输入。区别是1)我们训练我们的Pose-CNN来预测指数坐标,而不是将欧拉角旋转作为输出;2)我们将预测的平移除以估计深度的平均值,以便平移的比例与深度预测一致。
训练超参数
我们的训练损失是外观差异性损失和平滑度损失的加权和。我们将平滑度损失的权重设置为0.01。因为根据经验发现,这个加权参数在深度预测的锐度和总体结构正确性之间提供了一个理想的平衡。
通过Adam优化器训练网络,学习率设为0.0001, β1 = 0.9 and β2 = 0.999。受DDVO模块中非常规操作的限制,为了提高计算效率,我们将训练的batch设置为1。这种对batch大小的妥协仅仅是由于实现问题,而不是理论上的暗示。根据经验,我们观察到对整体绩效没有负面影响。

5.1 训练设置
为了更全面的测试本文提出的方法,我们在四种不同设置的情况下完成实验。
Baseline ,为了检测我们在2.1部分中提出的标准化技巧的效果。我们设置了一个基线配置。我们使用Pose-CNN作为姿态预测器,并关闭逆深度图归一化。此设置相当于于在zhou等人的方法中用我们的损失函数定义和修改。由于训练10个epoch后出现发现(见图3),我们显示了第10个epoch的训练结果
Pose-CNN ,我们进行逆深度归一化,仍然使用Pose-CNN作为姿态预测器。报告显示第10个epoch的结果。
DDVO ,用我们提出的DDVO模块替换掉Pose-CNN。DDVO用标识姿态初始化,为了解决训练集中的大运动问题,我们将模块设置为粗到细的五个刻度。我们从头开始训练模型,报告显示第10个epoch的结果。
Pose-CNN+DDVO,我们使用Depth-CNN和Pose-CNN来自“我们的(Pose-CNN)模块”作为预训练模型。然后修改Pose-CNN,将它的输出作为DDVO模块的初始化姿态,并将深度CNN微调2个epoch。由于Pose-CNN已经给了我们一个大致可以接受的估计结果,DDVO在这种情况下不需要考虑大的运动。因此,为了加快培训速度,我们直接在最好的规模上运行DDVO,而不是执行从粗到细的操作。
5.2 KITTI数据集上的结果
在本节,我们评估了在来自Eigen测试分割的697个Kitti图像的性能。我们使用与[11,31,13]中相同的性能指标计算同一裁剪区域的所有误差,并且不限制到最大深度。由于单目设置的问题,我们的方法无法恢复场景的真实比例。因此,我们通过将预测值乘以公式S = ∙中位数(实际值)/中位数(预测值),将预测值的范围与实际情况保持一致。
深度图归一化效果
我们比较了在“Baseline”设置和在“Pose-CNN”设置情况下的实验结果。这两种实验仅仅是在是否进行反向深度归一化方面有所不同(见第2.1节),结果如表1所示,简单的归一化方法在使用相同体系的所有度量中都得到了显著的改进。此外,通过深度归一化结果,“Pose-CNN”的实验结果不仅大幅度超越了zhou等人,还与Godard等人在校正立体声对上训练的结果非常接近。
DDVO vs Pose-CNN
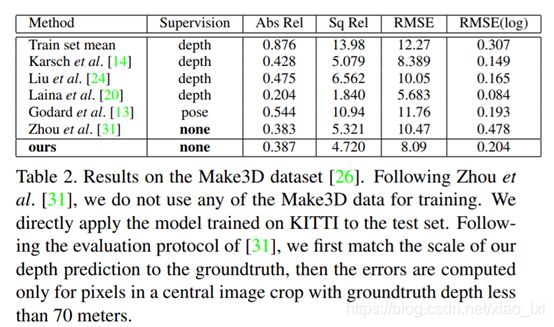
5.3 Make3D数据集上的结果

6.讨论
我们发现,正如单目视觉SLAM算法一样,在使用单目视频进行训练的时候,必须考虑尺度模糊性。如图3所示,这是之前在单目视频训练中的一个缺失点。另外,我们已经证明,可以使用DVO代替Pose-CNN来估计帧之间的相对相机位姿。这种策略可能需要更少的图像来训练,更少的参数来学习。未来我们计划调研需要的图像数量。最后,我们发现,可以利用Pose-CNN初始化和DDVO姿态优化的混合体系结构,对DDVO和POSE CNN姿态预测模块进行改进,获得最佳效果。
目前我们的方法的主要瓶颈是我们没有对世界的非刚性进行建模。如图6所示,我们目前的方法对于像摩托车手和行人这样的有关节的物体效果不佳。未来可能的工作是将非刚性技术
SFM引入到框架中。
如图6 所示,在以下情况下,我们的方法表现得效果不太好:
- 像人和摩托车这种动态场景效果不太好
- 路面过度曝光,倒是大面积的纹理减少的情况
- 大片纹理区域少的开阔场景

深度估计系列文章:
单目深度估计 | Learning Depth from Monocular Videos using Direct Methods
单目深度估计 | Real-Time Monocular Depth Estimation using Synthetic Data with Domain Adaptation via Image
单目深度估计 | Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras