调参,注意神经网络处于哪种相态

©PaperWeekly 原创 · 作者|张耀宇、许志钦
单位|上海交通大学
研究方向|机器学习的基础研究
作者按:神经网络的现象错综复杂,理解其本质的一个基础工作是研究神经网络的训练动力学过程有哪几类不同的状态并揭示它们与超参数的依赖关系,即进行相图分析。本文介绍的工作第一次给两层无限宽网络画出完整的相图,该工作已经被 Journal of Machine Learning Research 接收。

论文标题:
Phase diagram for two-layer ReLU neural networks at infinite-width limit
论文链接:
https://arxiv.org/abs/2007.07497
神经网络的初始化参数对其训练动力学过程和泛化性能有显著的影响。现在的理论分析通常是在一个具体的参数初始化下进行的,比如这两年研究很多的神经正切核理论(NTK)和平均场理论(mean-field),它们研究的训练行为是基于两种不同尺度的参数初始化。
前者的训练动力学近似线性,而后者则有显著非线性。同时,也有很多其它工作研究了其它初始化下神经网络训练动力学的行为。一个直接的问题便是,哪些参数初始化有类似的动力学行为,哪些有本质的不同?研究这个问题可以直接帮助我们预测任意初始化下神经网络的动力学行为特征,进而指导我们调整初始化的超参数来提升神经网络的预测性能。
神经网络的参数一般很多。研究这么多参数的演化问题,我们可以借鉴我们熟悉的水。一杯水含有远超一亿亿个分子,我们不可能通过追踪每个水分子的微观运动来推测水的状态。幸运的是,这样的复杂高维动力系统通常呈现出高度规律的宏观特征,可以通过测量温度、压强这样的宏观统计量来准确推测它处于液态,还是会结冰或者汽化。
理论上,在分子数目趋于无穷的热力学极限下,水的固液气三相泾渭分明,不同相的转变经历相变。这些信息都可以精确地呈现在一张以温度和压强为坐标的相图中,指导我们的实践。
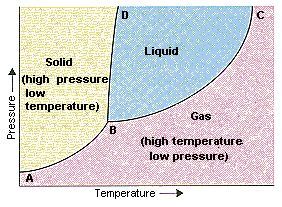
▲ 来自http://chemed.chem.purdue.edu/genchem/topicreview/bp/ch14/phase.php
类似地,我们针对两层神经网络众多的参数找到了合适的宏观统计量,并在隐藏层神经元数目趋于无穷的极限下建立了清晰的相图,划分了不同的动力学态。具体来说,我们考虑以下两层神经网络:
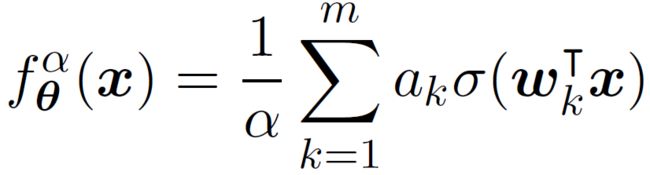
其中 为 ReLU 函数,参数初始化服从:
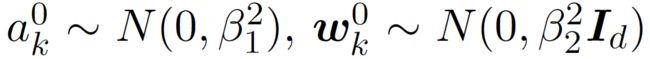
这个模型有三个自由的超参数 。当 时,这就是平均场理论研究的模型。当 时,这就是神经正切核理论研究的模型。
由于我们只关注神经网络训练动力学从初始到无穷时刻的轨迹而不在意时间,我们发现只需要以下两个有效参数就可以分类神经网络的动力学(第一个参数体现神经网络的输出尺度,第二个参数是输入和输出权重的不一致性)。
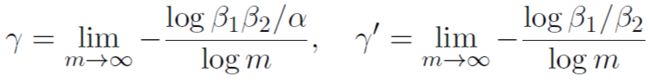
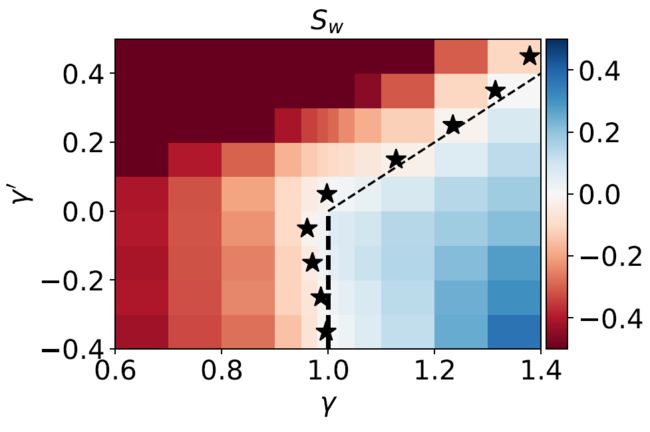
下图是通过这两个统计量划分的相图。
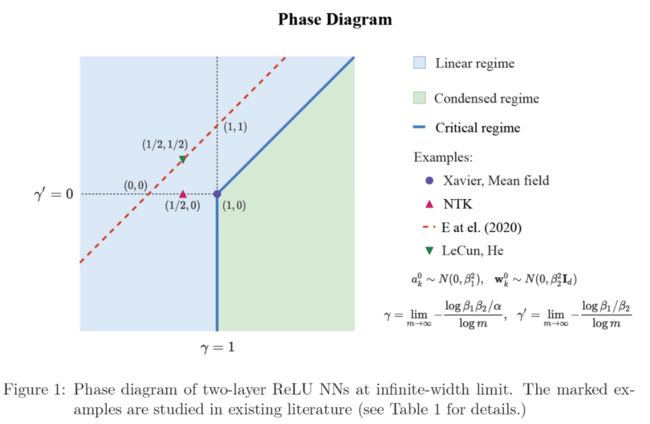
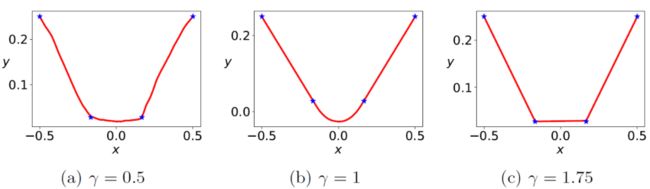
接下来,我们讲述上面的相图是怎么得到的。首先,我们来看一下三种不同初始化下(固定 , 分别取 0.5、1、1.75),神经网络学习的不同结果。在下图中,四个蓝色星星是训练点,红色是神经网络训练结束后学习到的函数曲线。显然,这三种不同初始化使得同样的神经网络从同样的数据中学到了显著不同函数。
进一步,我们观察每个神经元学习到的特征的分布差异。实验结果如下图所示(d、e、f 分别对应 a、b、c)。
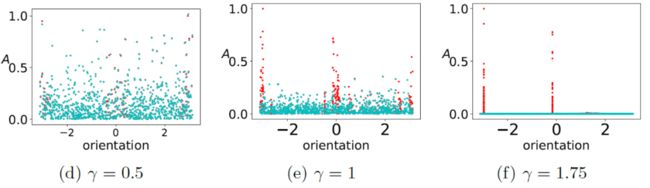
输入权重 w 的方向可以看作神经元的特征(上图横坐标为 对应的角度,取值在 ,w 的模长 与输出权重的长度 的乘积可以看作这个特征的幅度 (由于 ReLU 激活函数的齐次性)。
如下,我们发现对第一种情况,全体神经元特征的初始分布(青色点)和末态分布(红色点)非常靠近,这正是 NTK 的典型特征。由于从初态到末态网络参数改变不大,所以神经网络在整个训练过程中可以很好地被其在参数初值的线性展开近似。
第二种情况,初始分布和末态分布有显著差异,特征有所聚集,这是常见的平均场理论研究的情况。第三种情况,初始分布和末态分布完全不同,特征在末态几乎只凝聚在离散的几个方向上。由于我们用图片里的最大值做了归一化,所以初始的特征幅度几乎趋于零,即末态特征的最大幅值相对初态几乎趋于无穷大。
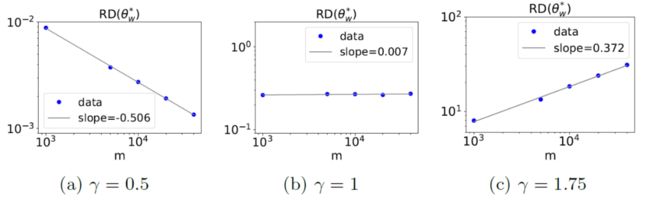
仔细分析可以发现,神经网络在整个训练过程中是否可以用一个线性模型逼近主要取决于非线性激活函数内参数 w 的变化。只要所有神经元的 w 几乎不变,那神经网络就可以由其参数初值附近的线性展开近似,训练动力学呈线性。于是,我们定义以下 的相对变化量:

下图展示了 随神经元数目增长的情况。对于第一种情况,斜率小于零,即当神经元数目无穷大的时候, 的初态和末态几乎一样。对于第二种情况,无论神经元数目多大, 从初态到末态的相对变化量几乎是一个非零的常量,是一个临界状态。第三种情况,斜率大于零,即 的末态与初态的相对差异趋于无穷大。
接下来,我们把以上特例推广到所有可能的 的取值。下图展示的是不同统计量下, 的相对变化量 关于神经元数目在对数图中的斜率 。
红色区域斜率小于零,当神经元数目趋于无穷大,我们将这部分区域定义为线性态。蓝色区域斜率大于零,当神经元数目趋于无穷大,这部分区域动力学呈强非线性。
由于参数都有如上图第三种情况所示的凝聚现象,我们称之为凝聚(condensed)态。而星星标出的区域正是如上图第二种情况所示的过渡区域。虚线是我们理论上预测的分界线,与实验完全一致。我们在 MNIST 数据上也得到了类似的结果。
最后我们对相图中这条分界线提供一些直观解释,严格的数学理论可以参考论文 [1]。我们先考虑 的情况。神经网络初始的输出尺度大约是:

一般目标函数的量级是 ,所以只要 ,那么神经网络就有机会通过对每个参数做很小的改变来拟合好目标函数。该条件等价于:
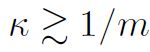
即 。接着,我们解释 45 度斜线的来源。在神经网络的梯度流动力学中,容易注意到 a 和 w 的演化速度和对方的大小成正比。只要 a 的演化速度远大于 w 且整个训练过程中远小于 ,就能保证 w 的演化远慢于 a。在 w 几乎不变(即保持 的尺度)并且 a 的尺度始终远小于 的情况下,我们有:

因为神经网络拟合好目标函数的必要条件是其末态的输出尺度 ,则:
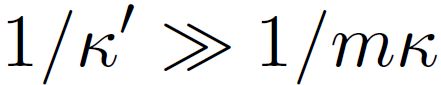
对应图中的 45 度边界。
有了两层神经网络的相图,我们就可以进一步研究神经网络各动力学态不同的隐式正则化效应。不同的实际问题常常需要不同的隐式正则化,我们这项工作可以为实践中通过调参定向改变神经网络的隐式正则化提供指导意见。
在这项工作的基础上,我们将进一步研究多层网络的相图,探索有限神经元数目对不同动力学态特性的影响,从而使我们对实际神经网络的超参调节、动力学特征以及隐式正则化有更深入的理解。
作者团队现招收数学与机器学习相关的博士后,感兴趣的读者可联系:[email protected]
参考文献
[1] Tao Luo, Zhi-Qin John Xu, Zheng Ma, Yaoyu Zhang, Phase diagram for two-layer ReLU neural networks at infinite-width limit. arXiv:2007.07497, 2020. (Accepted by Journal of Machine Learning Research)
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
