救救小王吧:如何快速解决图像相似性检测问题?
相似性图像检测,是模型训练过程中常出现的问题,本文介绍了 4 个常用的哈希算法,并通过 Colab 代码,展示了完整的训练过程。
新晋炼丹师小王最近遇到了一个难题,愁的头发掉了好几根儿。
一问才知道,原来是他师傅给他分配了一个深度学习模型训练的任务,但是训练模型的图像数据集,略微有那么一丝丝复杂:
里边除了已有的公开数据集外,还包含一些从 Google、Bing 等网站上爬取的图像。
重复图像的存在,使得模型性能变得十分不可靠,毕竟:
* 重复图像将 bias 引入数据集,使得深度学习模型不得不学习重复图像的特定模式;
* 特定的学习模式,会使得深度学习模型概括新图像的能力下降。
手动删除重复图像,绝对不是最优解,原因是数据集中的图像数量动辄成百上千万,手动检查和删除会是一个非(丧)常(心)繁(病)琐(狂)的过程,将会耗费大量时间。
哈希算法成为小王最先想到的解决方案。
图像相似性检索,「哈希」一下
哈希算法是解决图像相似性检索的「魔法工具」,它可以对任意一组输入数据进行计算,得到一个固定长度的输出摘要(字符串)。
比较输出摘要,结果越接近,就说明图像越相似。
哈希算法具有以下特点:
* 相同的输入一定得到相同的输出;
* 不同的输入大概率得到不同的输出;
注意: 哪怕两张输入图像之间,只有一个字节之差,输出的哈希值也可能天差地别。
ImageHash Python 库中,常用的哈希算法包括 aHash、pHash、dHash 及 wHash。
Average Hash (aHash):均值哈希算法,将图像切割成 8x8 的灰度图像,并依据像素值是否大于图像所有颜色的平均值,来设置哈希值中的 64 位。
aHash 计算速度快,不受图像尺寸大小影响,但对均值敏感,例如对图像进行伽马校正或直方图均衡会影响均值,从而导致报率,准确度无法保证。
 aHash 图像处理效果展示
aHash 图像处理效果展示
Perceptual Hash (pHash):感知哈希算法,与 aHash 类似,区别是 pHash 不依赖 average color,而是依赖离散余弦变换 (DCT),并依据频率 (frequency) 而非颜色值 (color value) 进行比较。
pHash 能避免伽马校正或颜色直方图被调整带来的影响,它准确率高、误报少,但计算速度比较慢。
 pHash 图像处理效果展示
pHash 图像处理效果展示
Difference Hash (dHash):差异值哈希算法与 aHash 原理类似,只是不使用平均颜色值的信息,而是使用梯度(相邻像素的差异)。
dHash 算法运行速度与 aHash 相当,但误报率非常低。
 dHash 图像处理效果展示
dHash 图像处理效果展示
Wavelet Hash (wHash):小波哈希算法,与 pHash 非常相似,但是 wHash 使用的是离散小波变换 (discrete wavelet transformation),而非 DCT。
wHash 比 pHash 更迅速,更准确,误报更少。
 wHash 图像处理效果展示
wHash 图像处理效果展示
不同哈希算法效果对比详见:TESTING DIFFERENT IMAGE HASH FUNCTIONS
善用轮子:用现成模块进行相似图像检测
作为一名合格的工程师,避免重复造轮子、提高开发效率,是小王一贯的追求。
经过搜索查找,小王发现了 Jina Hub 的 ImageHasher Executor。

查阅相关文档后小王发现,Executor 对应神经搜索系统中的不同模块,实现数据处理的核心功能,可以直接使用。
Flow 则对应整套神经搜索系统,它将多个 Executor 连接起来,构建成一套完整的搜索系统,轻松实现相似图像检测。
直接上代码:
!gdown --id 1wPg_Yx2ydcgsDA3BYO-Lw8ym5vjT0oQ3
!unzip data.zip -d images! mkdir index
! mv images/*1.* index/! mkdir query
!mv images/*.* query/!pip install jina imagehash创建一个索引 Document 的 Flow:
from jina import Flow
from docarray import Document, DocumentArray
import matplotlib.pyplot as plt!rm -rf workspace包含图像的 Document 将被编码成哈希值,接下来可以使用上述 4 种哈希算法中的任何一种,并用 SimpleIndexer 进行存储:
# Creating a DocumentArray object
docs_index = DocumentArray.from_files('index/*')
docs_index = [doc.load_uri_to_image_tensor() for doc in docs_index]
# Creating the indexing flow with ImageHasher and SimpleIndexer
flow = (
Flow()
.add(uses='jinahub://ImageHasher/v0.2', uses_metas={'hash_type': 'dhash'})
.add(
uses='jinahub://SimpleIndexer',
uses_metas={'workspace': 'workspace'},
uses_with={
'match_args': {'limit': 1, 'metric': 'euclidean', 'use_scipy': True}
},
)
)
# Indexing the Documents using the flow
with flow:
flow.post(on='/index', inputs=docs_index)def print_matches(resp):
for idx, doc in enumerate(resp.docs):
print('-'*50)
print(f'Query {idx + 1}')
plt.imshow(doc.tensor)
plt.show()
for match in doc.matches:
print('Matching query -->')
plt.imshow(match.tensor)
plt.show()查询任何一个新的 Document,并在索引数据中找到匹配的 Document:
docs_query = DocumentArray.from_files('query/*')
docs_query = [doc.load_uri_to_image_tensor() for doc in docs_query]
# Using the same flow to find matches
# Opening the flow for incoming queries
with flow:
flow.post(
on='/search',
inputs=docs_query,
on_done=print_matches,
)整个过程跑下来,一起来看看小王的相似图像检测结果吧!
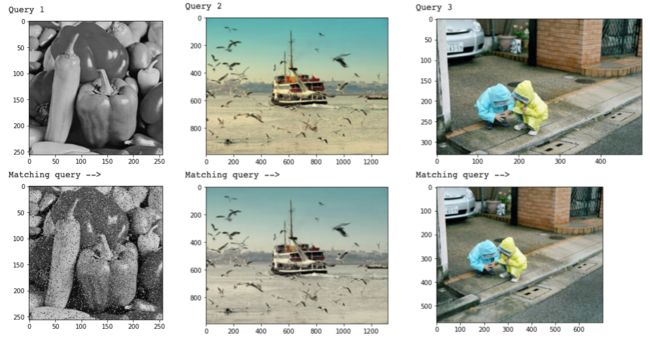 即使图像只是像素、滤镜或尺寸不同,也可以利用哈希算法检测出来
即使图像只是像素、滤镜或尺寸不同,也可以利用哈希算法检测出来
炼丹师小王利用 Jina Hub ImageHasher Executor,终于解决了数据集中的相似图像问题,并将代码都放到了 Colab 上。
参与更多深度学习、哈希算法相关讨论,找到组织戳→Slack。
热心小王期待大家的加入!
参考文献:
Imagehashing--Find duplicates 完整 Colab
ImageHasher Executor
廖雪峰的官方网站--哈希算法
相似图像检测方法
Testing different image hash functions
An image hashing library written in Python