Visual Attention Network
文章地址:https://arxiv.org/abs/2202.09741
自注意力机制将2D图像视为1D序列,这会破坏图像的关键2D结构。由于其二次计算和内存开销,处理高分辨率图像也很困难。此外,自注意力机制是一种特殊的注意,它只考虑空间维度的适应性,而忽略了通道维度的适应性,这对视觉任务也很重要。 作者设计了一种新的计算机视觉注意机制LKA,它既考虑了卷积和自我注意的优点,又避免了它们的缺点。在LKA的基础上,提出了一个简单的视觉主干,称为VAN。
一、文章简介:
本文思路与MobileNet相似,MobileNet将标准卷积分解为两部分,深度卷积和点态卷积(也称为1×1 Conv[)。本文的方法将卷积分解为三部分:深度卷积、深度和扩展卷积,以及点态卷积。得益于这种分解,更适合于高效分解大型核卷积。还将注意机制引入到我们的方法中,以获得自适应特性。
二、实现细节:
自注意力最初是为NLP设计的。在处理计算机视觉任务时,它有三个缺点。
(1) 它将图像视为一维序列,忽略了图像的二维结构。
(2) 二次复杂度对于高分辨率图像来说太昂贵了。
(3) 它只实现了空间适应性,而忽略了通道维度的适应性。对于视觉任务,不同的通道通常代表不同的对象。通道适应性对于视觉任务也很重要。为了解决这些问题,提出了LKA。它涉及自注意力的优点,如适应性和长期依赖性。此外,它还受益于卷积的优点,例如利用本地上下文信息。
注意机制可以看作是一个自适应选择过程,它可以根据输入特征选择有区别的特征,并自动忽略噪声响应。注意机制的关键步骤是生成注意图,以显示不同点的重要性。
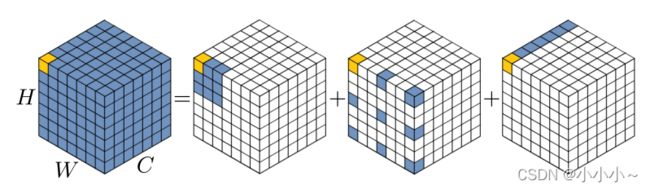
利用自注意力和大核卷积的优点,可以分解一个大核卷积运算来捕获长程关系。如上所示,大型内核卷积可分为三个部分:空间局部卷积(深度卷积)、空间远程卷积(深度扩展卷积)和通道卷积(1×1卷积)。更细致的说,可以将一个K×K卷积分解为一个膨胀系数为d的 k / d × k / d k/d×k/d k/d×k/d深度方向的膨胀卷积,一个 ( 2 d − 1 ) × ( 2 d − 1 ) (2d − 1) ×(2d− 1) (2d−1)×(2d−1) 深度卷积和1×1卷积。通过上述分解,可以用少量的计算成本和参数捕捉长期关系。在获得长期关系后,可以估计一个点的重要性并生成注意图。
LKA模块可以写为:

F ∈ R C × H × W F∈ R^{C×H×W} F∈RC×H×W是输入特征, A t t e n t i o n ∈ R C × H × W Attention∈ R^{C×H×W} Attention∈RC×H×W表示注意图。注意图中的值表示每个特征的重要性。⊗ 是指元素的乘积,LKA结合了卷积和自注意力的优点。它考虑了局部语境信息、大的感受野和动态过程。此外,LKA不仅实现了空间维度的适应性,还实现了通道维度的适应性。值得注意的是,在深层神经网络中,不同的通道通常代表不同的对象,通道维度的适应性对于视觉任务也很重要。

VAN具有简单的层次结构,即四级序列,其分辨率以及通道变化如上:输出空间分辨率降低,分别为 H / 4 × W / 4 、 H / 8 × W / 8 、 H / 16 × W / 16 和 H / 32 × W / 32 H/4×W/4、H/8×W/8、H/16×W/16和H/32×W/32 H/4×W/4、H/8×W/8、H/16×W/16和H/32×W/32。这里,H和W表示输入图像的高度和宽度。随着分辨率的降低,输出通道的数量也在增加。输出通道C的变化如上图。
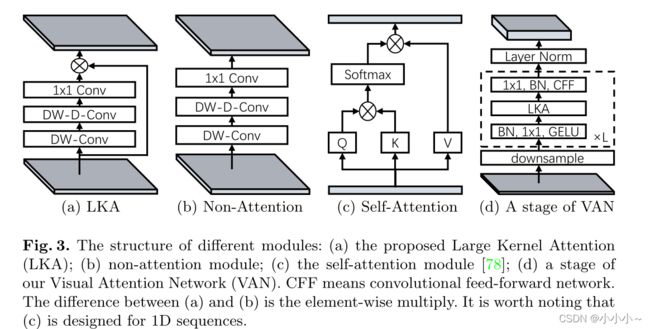
每个阶段,首先对输入进行下采样,并使用步幅数来控制下采样率。下采样后,一个阶段中的所有其他层保持相同的输出大小,即空间分辨率和通道的数量,结构如上。然后,将批量归一化、GELU激活、大核注意和卷积前馈网络的L组按顺序叠加以提取特征。最后,在每个阶段结束时应用层规范化。根据参数和计算量,设计了四种结构V-AN-Tiny、V-AN-Small、V-AN-Base和V-AN-Large。
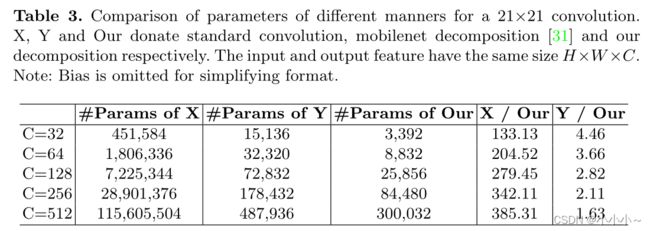
假设输入和输出特征具有相同的大小H×W×C。parameters and FLOPs为:
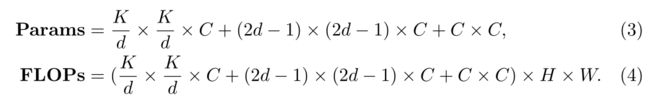
d表示膨胀率,K表示内核大小。当K=21时,(3)可以写成:

当d=3时,公式(5)取最小值。因此,默认设置K=21和d=3。
默认情况下,LKA采用5×5深度方向的卷积、膨胀率为3的7×7深度方向的卷积和1×1卷积来近似21×21卷积。在此设置下,VAN可以有效地实现本地信息和远程连接。分别使用7×7和3×3步距卷积进行4×和2×下采样。
三、消融实验:

DW-Conv:DW Conv可以利用图像的局部上下文信息。如果没有它,分类性能将下降0.5%(74.9%),显示了局部结构信息在图像处理中的重要性.
DW-D-Conv:DW-D-Conv提供深度方向的扩张卷积,这在捕获LKA中的长程依赖性方面起到了作用。如果没有它,分类性能将下降1.3%(74.1%对75.4%),这证实了即长期依赖对视觉任务至关重要。
注意机制:注意机制的引入可以看作是使网络实现了适应性。得益于此,V AN Tiny实现了约1.1%的改善(74.3%对75.4%)。
1×1 Conv:1×1 Conv通道维度中的关系。结合注意机制,引入了渠道维度的适应性。它带来了0.8%(74.1%对75.4%)的改善,这证明了渠道维度适应性的必要性。
通过以上分析,LKA可以利用本地信息,捕获长距离依赖,并且在通道和空间维度上都具有适应性。此外,实验结果证明所有属性对识别任务都是积极的。虽然标准卷积可以充分利用局部上下文信息,但它忽略了长期依赖性和适应性。在自我注意方面,虽然它能够捕捉长期依赖,并在空间维度上具有适应性,但它忽略了局部信息和通道维度上的适应性。



实验结果如上
相关代码:
class AttentionModule(nn.Module):
def __init__(self, dim):
super().__init__()
# depth-wise convolution
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
# depth-wise dilation convolution
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
# channel convolution (1×1 convolution)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn