上一章节 我们学习了如何利用 open() 函数创建一个文件,以及如何在文件内写入内容;今天我们就来了解一下如何将文件中的内容读取出去来的方法。
文件读取的模式
| 模式 | 介绍 |
|---|---|
| r (read 的缩写) | 读取文件(返回的是字符串类型) |
| rb | 二进制形式读取文件 |
注意:我们接触文件的写入与读取都是使用的 字符串 类型,那么 集合、元组、列表等就不能写入了么?严格来说是不可以的,但是我们可以进行数据类型转换转为字符串呀 。写入的时候转为字符串类型,读取的时候再转为原来的数据类型即可。 嘿嘿嘿…
文件对象的读取方法
| 方法名 | 参数 | 介绍 | 举例 |
|---|---|---|---|
| read | 无 | 将文件内容一次性全部独取出来,返回整个整个文件的字符串 | f.read() |
| readlines | 无 | 将文件内容的每一行内容切割成列表读取,返回文件列表 | f.readlines() |
| readline | 无 | 将文件每一行内容进行读取,一次返回一行,返回文件中的一行 | f.readline() |
| mode | 无 | open()函数的 mode属性,调用可返回当前文件模式 | f.mode() |
| name | 无 | 返回文件名称 | f.name() |
| closed | 无 | 返回一个 bool 类型,调用 closed() 函数可以知道文件是否关闭 | f.closed() |
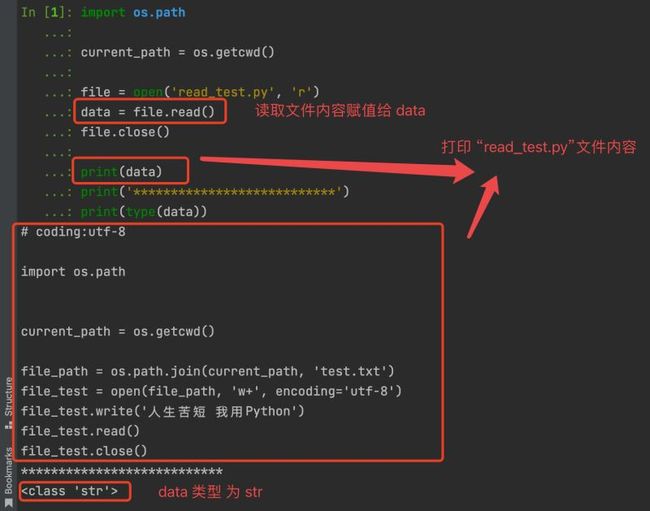
使用 read() 函数一次性读取文件全部内容
注意:下文演示的 Terminal 终端是在 read_test.py 文件路径启动的 ipython 执行的。
这是我们读取 事先创建好的 read_test.py 文件的脚本
import os.path
current_path = os.getcwd()
file = open('read_test.py', 'r')
data = file.read()
file.close()
print(data)
print('***************************')
print(type(data))
read_test.py 文件内容如下
# coding:utf-8
import os.path
current_path = os.getcwd()
file_path = os.path.join(current_path, 'test.txt')
file_test = open(file_path, 'w+', encoding='utf-8')
file_test.write('人生苦短 我用Python')
file_test.read()
file_test.close()
Terminal终端 执行效果如下图:
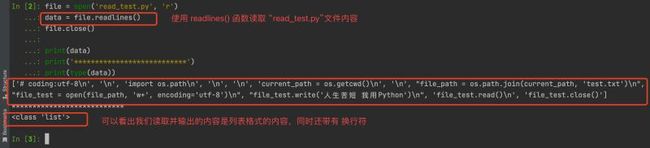
使用 readlines() 函数 读取文件内容
继续上面的脚本我们使用 readlines() 函数
file = open('read_test.py', 'r')
data = file.readlines()
file.close()
print(data)
print('***************************')
print(type(data))
Terminal 终端 执行的效果如下图:
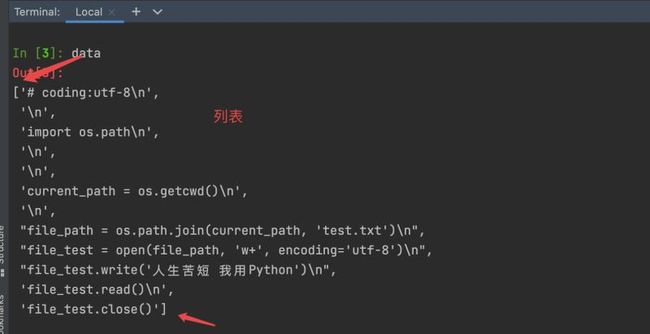
注意:区别于 print(data) ,直接打印 data ,显示效果如下:
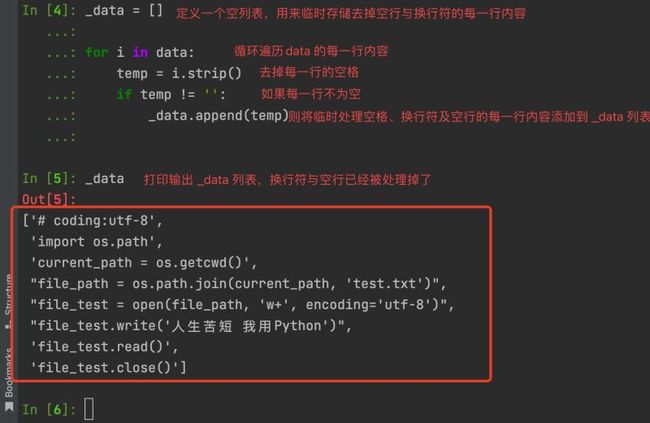
这里我们发现每一行和空行都会有一个换行符,如果我们需要读取、处理每一行的内容,空行与换行符会给我们造成很大的困扰。这里我们就可以利用到字符串的 strip() 函数加上 for 循环 就可以处理了。
_data = []
for i in data:
temp = i.strip()
if temp != '':
_data.append(temp)
_data
# >>> 执行结果如下图:
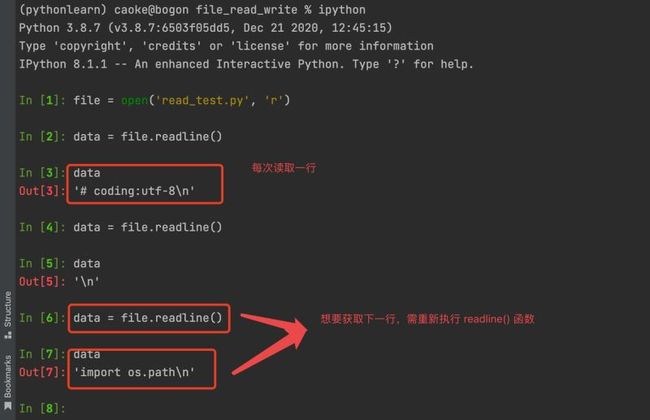
使用 readline() 函数 逐行读取文件内容
上文我们提到 readline() 函数 会针对文件每一行内容进行读取,一次返回一行;如果想要读取下一行内容,就需要再一次执行 readline() 函数;下面我们来看一下 演示案例:
file = open('read_test.py', 'r')
data = file.readline()
data
# >>> 执行结果如下:
# >>> '# coding:utf-8\n'
data = file.readline()
data
# >>> 执行结果如下:
# >>> '\n'
如下图:
mode()、name()、closed() 函数演示
见下图:

文件读取小实战
还记得我们上一章节的文件的创建于写入里面的实战小案例么?今天我们就在上一章节的实战小案例上进行一个补充,拓展一下我们关于读取文件的功能(函数)
在进行 文件读取小实战之前,我们先来了解一下 wiht open() 函数,如下。
with open() 函数
前文我们了解到,如果想要读取一个文件就需要先使用 open() 函数,打开文件并赋予其打开的模式,最后必须要要操作 close() 函数;这就是一个完整的读取文件内容的一个步骤,但是这个步骤过于繁琐不说,在文件不存在或者没有执行 close() 函数的情况下,还会抛出一个IOError的错误,并且给出错误码和详细的信息告诉你文件不存在,示例如下:
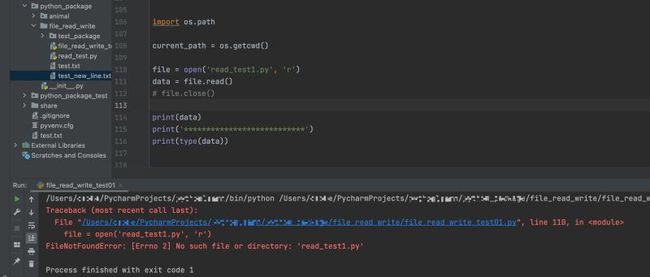
每次如果都按照如上最终方案去写的话,实在太繁琐。Python引入了with语句来自动帮我们调用close()方法
重点:!!!with 的作用就是自动调用close()方法 !!!
# 使用方法:
with open('/path/to/file', 'r') as f:
print(f.read())
# >>> 相较于单独使用 open() 函数,是不是代码更佳简洁,并且不必调用f.close()方法了呢?
利用with open() 函数读取文件的小实战
import os
def create_package(path):
if os.path.exists(path):
raise Exception('%s 已经存在,不可创建' % path)
else:
os.mkdir(path)
init_path = os.path.join(path, '__init__.py')
file_init = open(init_path, 'w', encoding='utf-8')
file_init.write('# coding:utf-8\n')
file_init.close()
class Open(object):
def __init__(self, path, mode='w', is_return=True): # 这里的 is_return 定义的是换行的意思,结合下文的 message 理解
self.path = path
self.mode = mode
self.is_return = is_return
def write(self, message):
file_test = open(self.path, mode=self.mode)
if self.is_return: # 如果返回 Ture 则 在 message 后,增加换行符
message = '%s\n' % message
file_test.write(message)
file_test.close()
def read(self, is_strip=True): # is_strip 用于判断每一行结尾的换行符将其去掉
result = [] # 定义一个空列表,用来读取每一行内容
with open(self.path, mode=self.mode) as file:
data = file.readlines() # 文件对象读取文件内容一但脱离 with open() 函数,就会自动执行 close() 函数 关闭文件
for line in data: # for循环遍历data ,若读取的那一行内容不为空且如果存在'\n'符,去掉'\n'符然后加入result列表
if is_strip: # is_strip 默认就是 True
temp = line.strip()
if temp != '':
result.append(temp)
else: # 如果读取的那一行不为空,加入result列表
if line != '':
result.append(line)
return result
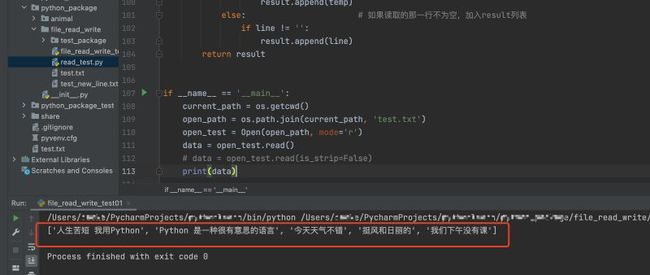
if __name__ == '__main__':
current_path = os.getcwd()
open_path = os.path.join(current_path, 'test.txt')
open_test = Open(open_path, mode='r')
data = open_test.read()
# data = open_test.read(is_strip=False)
print(data)
执行结果如下:
以上就是Python学习之文件的读取详解的详细内容,更多关于Python文件读取的资料请关注脚本之家其它相关文章!