Hive作业在运行时会在HDFS的临时目录产生大量的数据文件,这些数据文件会占用大量的HDFS空间。这些文件夹用于存储每个查询的临时或中间数据集,并且会在查询完成时通常由Hive客户端清理。但是,如果Hive客户端异常终止,可能会导致Hive作业的临时或中间数据集无法清理,从而导致Hive作业临时目录占用大量的HDFS空间。本篇文章Fayson主要介绍如何解决清理Hive作业产生的临时文件。
测试环境
1.CM和CDH版本为5.15
2.Hive作业临时目录说明
Hive作业在运行时会在HDFS的指定目录下生成作业临时或中间数据集存储目录,大数据培训此临时目录路径有hive-site.xml配置中的hive.exec.scratchdir参数定义:
Hive 0.2.0到0.8.0版本中默认值为:/tmp/${user.name}
Hive0.8.1到0.14.0版本中默认值为:/tmp/hive-${user.name}
Hive0.14.1及更高版本中默认值为:/tmp/hive/${user.name}
当前Fayson的CDH5.15.0中Hive版本为1.1.0,Hive作业的临时或中间数据集在HDFS的/tmp/hive/${user.name}目录下:
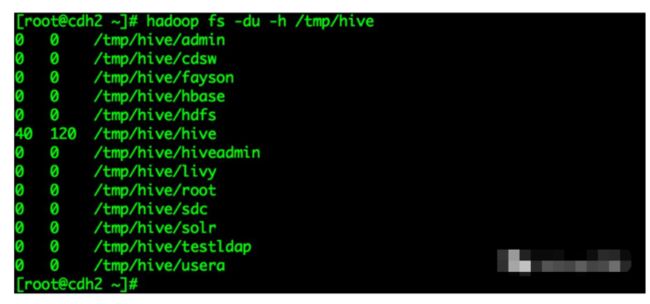
3.清理Hive作业临时及目录
由于Hive客户端的作业异常退出客户端无法正常的清理HDFS的临时目录,从而导致临时数据文件占用了大量的HDFS空间。因此,需要在Hive作业临时目录中删除不需要的目录和已完成作业的目录文件。
注意:清理临时Hive作业产生的临时目录时,不能删除任何正在运行的Hive作业这样可能会导致作业运行失败。只可以删除不再与当前正在执行的Hive作业相关联的文件和目录。
1.创建一个定时清理作业的脚本hive_clean.sh内容如下:
[root@cdh3 clean]# vim hive-clean.sh
!/bin/bash
kinit -kt /opt/cloudera/clean/hdfs.keytab hdfs/[email protected]
yarn jar /opt/cloudera/parcels/CDH/lib/solr/contrib/mr/search-mr--job.jar org.apache.solr.hadoop.HdfsFindTool -find '/tmp/hive/' -type d -name '' -mtime +7 | xargs hdfs dfs -rm -r -f -skipTrash

2.将hive-clean.sh脚本放在/opt/cloudera/clean目录下
注意:Fayson的集群启用了Kerberos,所以这里使用了hdfs用户的keytab,确保执行HDFS命令时有权限删除不用用户创建的临时文件和目录。
3.在Linux中配置crontab定时任务,脚本如下:
[root@cdh3 ~]# chmod +x /opt/cloudera/clean/hive-clean.sh
[root@cdh3 ~]# crontab -e
/1 * /opt/cloudera/clean/hive-clean.sh > /opt/cloudera/clean/clean.log 2>&1 &

这里配置的crontab为每分钟执行一次脚本可以将执行频率调整至1天即“ /1 *”
4.查看执行日志

总结
1.Hive作业在运行时会将临时或中间结果存储HDFS,如果Hive客户端作业异常退出会导致HDFS上存储的临时数据不能被清除而导致HDFS空间被占用。
2.可以通过创建定时任务定期的将Hive作业的临时文件和目录删除
3.清理Hive作业临时文件和目录时需要注意,不能将正在运行的作业文件和目录清除,否则会导致作业运行失败。
关键词:大数据培训