从0开始配置YOLOv4训练自己的数据集
第一步 下载源码
YOLOv4 https://github.com/AlexeyAB/darknet
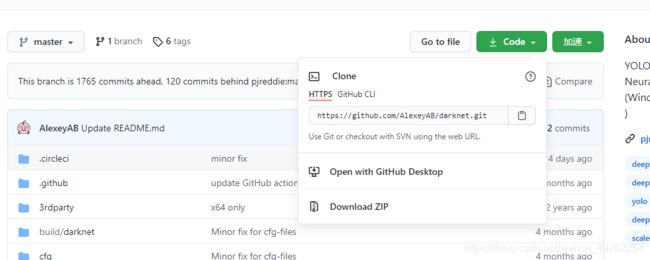
Download ZIP 并解压

第二步 创建虚拟环境
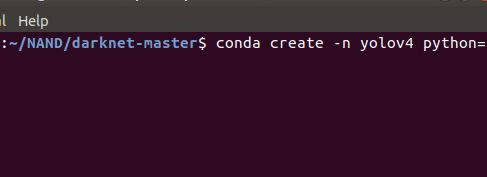
详见https://blog.csdn.net/weixin_49252254/article/details/110307445
第三步 配置OpenCV
pip install opencv-python
pip install opencv-contrib-python
第四步 制作自己的数据集
1.标注自己的数据集
详见https://blog.csdn.net/weixin_49252254/article/details/110185522
2.在 darknet-master文件下创建 data文件(本来包含的删除掉就行)
data文件下包含
1.obj.data
创建一个.txt文件自己改后缀即可

里面包含

classes = 1 #数据集中待测物体的类别数量,我这里就一个
train = data/train.txt #固定格式,照着复制就好
test = data/test.txt
names = data/obj.names
backup = backup/
2.obj.names


里面为需要检测的种类
3.train.txt


训练图像路径
4.test.txt
测试图像路径
5.obj

里面包含自己的预训练图片和对应的.txt文件

.txt通过标注生成的.xml文件和一下程序生成
# -*- coding: utf-8 -*-
# ——author—— = “调得一手好参”
# Email : [email protected]
# time : 2020.5.12
# function: 将xml文件转为yolo的标签
import os
import argparse
import xml.etree.ElementTree as ET
import glob
def xml_to_txt(data_path,anno_path,path,use_difficult_bbox=False):
classes = ['am','fm','gsm','qpsk']
image_inds = file_name(data_path+"train_label/") #遍历xml文件
with open(anno_path, 'a') as f:
for image_ind in image_inds:
img_txt = data_path + 'obj/'+ image_ind + '.txt'
img_txt_file = open(img_txt, 'w')
image_path = os.path.join(data_path, 'obj/', image_ind + '.jpg')
label_path = os.path.join(data_path, 'train_label', image_ind +'.xml')
root = ET.parse(label_path).getroot()
objects_size = root.findall('size')
image_width = int(objects_size[0].find('width').text)
image_height = int(objects_size[0].find('height').text)
objects = root.findall('object')
for obj in objects:
difficult = obj.find('difficult').text.strip()
if (not use_difficult_bbox) and(int(difficult) == 1):
continue
bbox = obj.find('bndbox')
class_ind = str(classes.index(obj.find('name').text.lower().strip()))
xmin = int(bbox.find('xmin').text.strip())
xmax = int(bbox.find('xmax').text.strip())
ymin = int(bbox.find('ymin').text.strip())
ymax = int(bbox.find('ymax').text.strip())
x_center = str((xmin + xmax)/(2*image_width))
y_center = str((ymin + ymax)/(2*image_height))
width_ = str((xmax - xmin)/(image_width))
height_ = str((ymax - ymin)/(image_height))
class_ind += ' ' + ','.join([x_center+' '+y_center+' '+width_+' '+height_])
img_txt_file.write(class_ind + "\n")
f.write(image_path + "\n")
def file_name(file_dir):
L = []
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == '.xml':
L.append(file.split(".")[0])
return L
if __name__ == '__main__':
num1 = xml_to_txt('.data/','./data/train.txt','train')#我把文件放的位置和原作者有出入,大家也可以根据自己的需求改路径
# num2 = convert_voc_annotation('./data/', './data/test.txt', False)
print('done')
参考原作者https://blog.csdn.net/qq_38800014/article/details/106094605?utm_medium=distribute.pc_relevant.none-task-blog-2defaultBlogCommendFromBaidudefault-6.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2defaultBlogCommendFromBaidudefault-6.control
6.最终包含data文件夹

第五步 修改配置文件
在cfg 文件下找到yolov4.cfg

将所有classes=80 改为自己检测目标的数量,我的是1
所以改为classes=1
一共三个
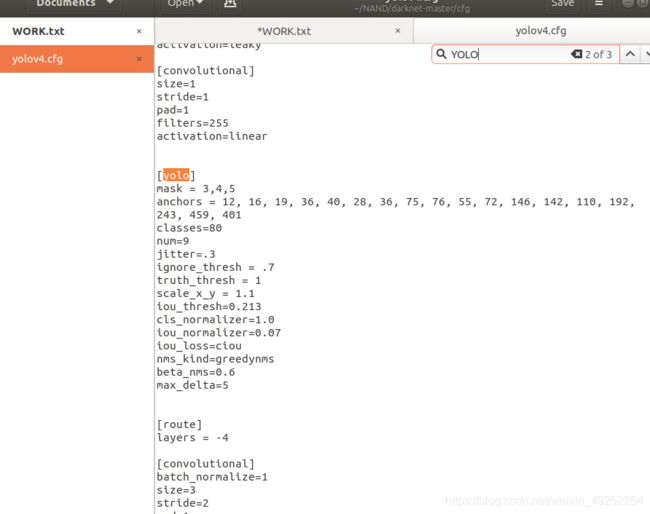
找到yolo上面的 filters=255 改为3*(5+classes的数量)
我的 filters=18
(3是代表3个bbox,5=w,h,x,y+confidnce,classes=类别数,他们的和为最后输出的通道。如果没记错的话。)
一共三个
在cfg 文件下找到yolov4-tiny.cfg
同上,不过这里面需要改的filters少一个
第六步修改makefile文件
在darknet-master文件夹下找到

(1) GPU=1: 表示在训练的时候使用CUDA进行加速训练(CUDA应该在 /usr/local/cuda文件夹下)
(2) CUDNN=1: 表示在训练的过程中使用CUDNN v5-v7进行加速(cuDNN应该在 /usr/local/cudnn文件夹下)
(3) CUDNN_half=1: 为Tensor Cores (在Titan V / Tesla V100 / DGX-2等)上进行加速训练和推理。
(4) OPENCV=1: 编译OpenCV 4.x/3.x/2.4.x等。OpenCV可以读取视频或者图片。
(5) DEBUG=1: 编译debug版本的Yolo
(6) OPENMP=1:使用OpenMP进行编译,能够使用多核的CPU进行加速
(7) LIBOS=1: 编译构建darknet.so动态库。
(8) ZED_CAMREA=0: 置为1的时候表示构建ZED-3D-camera的库。
修改方法参考https://blog.csdn.net/weixin_49252254/article/details/110405757
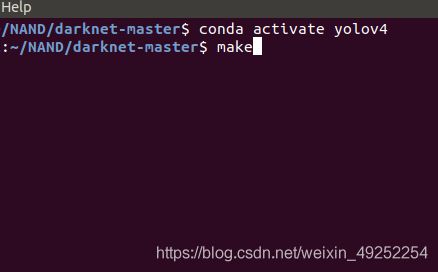
第七步make
在刚才的命令行里输入
make
编译一下darknet-master
第八步预训练
下载yolov4.conv.137
放到darknet-master文件夹下
在刚才的命令行运行
./darknet detector train data/obj.data cfg/yolov4.cfg yolov4.conv.137 -map
#代码的意思是 运行 darknet-master/darknet 调用这个路径的文件arknet-master/data/obj.data 、./darknet-master/cfg/yolov4.cfg 和./darknet-master/yolov4.conv.137三个文件
#你可以在这个目录下找到对应的文件
第九步7训练yolov4-tiny
下载:yolov4-tiny.conv.29
放到darknet-master文件夹下
在刚才的命令行运行
./darknet detector train data/obj.data cfg/yolov4-tiny.cfg yolov4-tiny.conv.29
同上
训练后的权重保存在看backup文件夹下:
出结果:
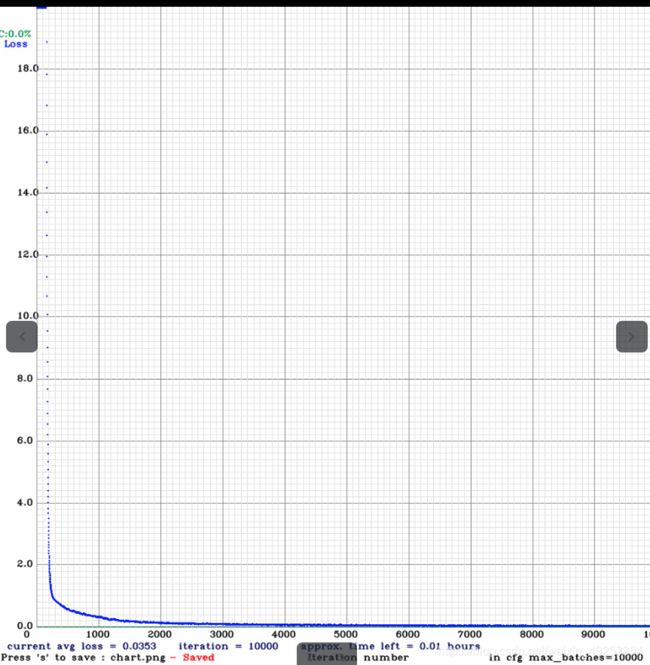
文件里默认的迭代次数时候2002000次,根据需求自己改。我改为10000次。
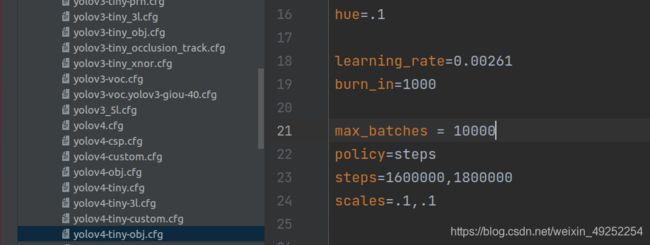
在cfg/yolov4-tiny.cfg 里面改max_batches 改不改取决于你的数据集的大小,我是为了看图方便改的。
第十步测试结果
./darknet detector test data/obj.data cfg/yolov4-tiny.cfg backup/yolo-obj_final.weights
#同上,选择自己的obj.data,训练模型,和最后一次训练权重
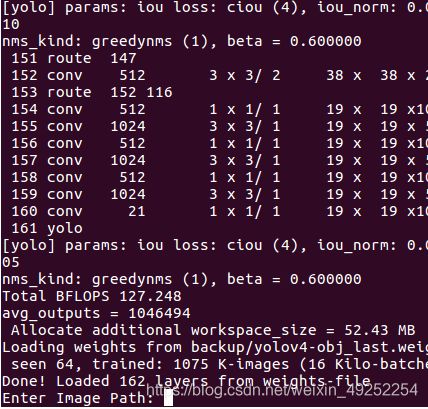
输入需要测试的图片地址:
data/obj/xxxx.jpg#我的训练集路径随便找的一张