<从零开始pytorch>:02-torch搭建神经网络模型-气温预测案例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
搭建Pytorch神经网路进行气温预测
获取数据并,展示分析数据
features = pd.read_csv('temps.csv')
features.head()
| year | month | day | week | temp_2 | temp_1 | average | actual | friend | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016 | 1 | 1 | Fri | 45 | 45 | 45.6 | 45 | 29 |
| 1 | 2016 | 1 | 2 | Sat | 44 | 45 | 45.7 | 44 | 61 |
| 2 | 2016 | 1 | 3 | Sun | 45 | 44 | 45.8 | 41 | 56 |
| 3 | 2016 | 1 | 4 | Mon | 44 | 41 | 45.9 | 40 | 53 |
| 4 | 2016 | 1 | 5 | Tues | 41 | 40 | 46.0 | 44 | 41 |
- temp_2:前天的最高气温
- temp_1:昨天的最高气温
- average: 每年这一天的平均最高温度值
- actual : 实际的值,y值,要预测的值
- friend : 一个不准确的数据,朋友猜的今天的气温
# 查看数据的形状
features.shape
(348, 9)
# 处理时间数据
import datetime
# 分别得到年/月/日
years = features['year']
months = features['month']
days = features['day']
# 处理成datetime格式
dates = [str(int(year))+'-'+str(int(month))+'-'+str(int(day)) for year,month,day in zip(years,months,days)]
dates = [datetime.datetime.strptime(date,'%Y-%m-%d') for date in dates]
dates[:5]
[datetime.datetime(2016, 1, 1, 0, 0),
datetime.datetime(2016, 1, 2, 0, 0),
datetime.datetime(2016, 1, 3, 0, 0),
datetime.datetime(2016, 1, 4, 0, 0),
datetime.datetime(2016, 1, 5, 0, 0)]
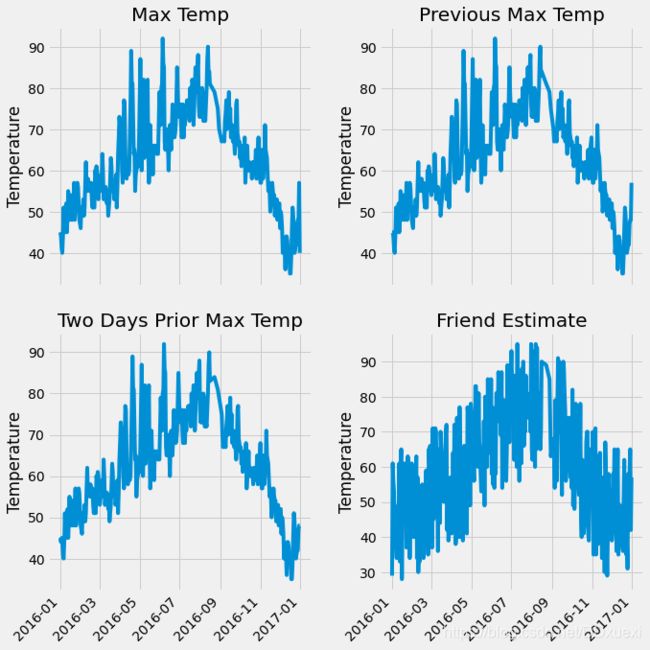
# 画图展示:观察数据大概是什么样子的
plt.style.use('fivethirtyeight') # 指定默认风格
# 设置布局
fig,((ax1,ax2),(ax3,ax4)) = plt.subplots(nrows=2,ncols=2,figsize=(10,10))
fig.autofmt_xdate(rotation=45)
# 标签值
ax1.plot(dates,features['actual'])
ax1.set_xlabel('');ax1.set_ylabel('Temperature');ax1.set_title('Max Temp')
# 昨天
ax2.plot(dates,features['temp_1'])
ax2.set_xlabel('');ax2.set_ylabel('Temperature');ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates,features['temp_2'])
ax3.set_xlabel('');ax3.set_ylabel('Temperature');ax3.set_title('Two Days Prior Max Temp')
# 我的逗比朋友
ax4.plot(dates,features['friend'])
ax4.set_xlabel('');ax4.set_ylabel('Temperature');ax4.set_title('Friend Estimate')
plt.tight_layout(pad=2)
# 将日期进行one_hot编码 -- week一列不见了,多了7列
features = pd.get_dummies(features)
features
| year | month | day | temp_2 | temp_1 | average | actual | friend | week_Fri | week_Mon | week_Sat | week_Sun | week_Thurs | week_Tues | week_Wed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016 | 1 | 1 | 45 | 45 | 45.6 | 45 | 29 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2016 | 1 | 2 | 44 | 45 | 45.7 | 44 | 61 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 2016 | 1 | 3 | 45 | 44 | 45.8 | 41 | 56 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 2016 | 1 | 4 | 44 | 41 | 45.9 | 40 | 53 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 2016 | 1 | 5 | 41 | 40 | 46.0 | 44 | 41 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 343 | 2016 | 12 | 27 | 42 | 42 | 45.2 | 47 | 47 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 344 | 2016 | 12 | 28 | 42 | 47 | 45.3 | 48 | 58 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 345 | 2016 | 12 | 29 | 47 | 48 | 45.3 | 48 | 65 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 346 | 2016 | 12 | 30 | 48 | 48 | 45.4 | 57 | 42 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 347 | 2016 | 12 | 31 | 48 | 57 | 45.5 | 40 | 57 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
348 rows × 15 columns
# 标签
labels = np.array(features['actual'])
# 去掉便签后的数据
features = features.drop('actual',axis=1)
features_list = list(features.columns)
# 将train转成合适的格式
features = np.array(features)
labels.shape, features.shape,features_list
((348,),
(348, 14),
['year',
'month',
'day',
'temp_2',
'temp_1',
'average',
'friend',
'week_Fri',
'week_Mon',
'week_Sat',
'week_Sun',
'week_Thurs',
'week_Tues',
'week_Wed'])
数据预处理
- 此时,数据中的数有的很大,有的很小,需要进行数据的预处理
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
input_features[0] # 处理之后的数据,变得比较小了
array([ 0. , -1.5678393 , -1.65682171, -1.48452388, -1.49443549,
-1.3470703 , -1.98891668, 2.44131112, -0.40482045, -0.40961596,
-0.40482045, -0.40482045, -0.41913682, -0.40482045])
input_features.shape
(348, 14)
构建网络模型
1.将ndarray格式的 x 和 y转换成tensor格式
x = torch.tensor(input_features,dtype=float)
y = torch.tensor(labels,dtype=float)
# 使用torch.from_numpy(input_features)方法也可以将ndarray转换成tensor
x.shape,y.shape,x.shape[1]
(torch.Size([348, 14]), torch.Size([348]), 14)
2.构建网络模型
1. 初始化权重和学习率,构建一个空列表存储损失Loss
2. 每次迭代中进行前向传播和反向传播
- 前向传播就是每一层之间是如何传递的,输入层->隐层->激活函数->输出层->损失函数的定义->保存损失
- 反向传播就是从损失那里开始: backward()开始反向传播计算->更新参数->每次迭代后清空参数的梯度
# 权重的参数初始化
weights = torch.randn((14,128),dtype=float,requires_grad=True)
biases = torch.randn(128,dtype=float,requires_grad=True)
weights2 = torch.randn((128,1),dtype=float,requires_grad=True)
biases2 = torch.randn(1,dtype=float,requires_grad=True)
# 学习率和损失
learning_rate = 0.001
losses = []
for i in range(1000):
# 就是隐层 mm是矩阵乘法
hidden = x.mm(weights) + biases
# 加入激活函数
hidden = torch.relu(hidden)
# 预测结果
predict = hidden.mm(weights2) +biases2
# 计算损失
loss = torch.mean((predict - y) ** 2)
losses.append(loss.data.numpy()) # loss.data.numpy()这种写法记住
# 打印损失值
if i % 100 == 0:
print('loss:',loss)
# 反向传播计算
loss.backward()
# 更新参数
weights.data.add_(- learning_rate * weights.grad.data)
biases.data.add_(- learning_rate * biases.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases2.data.add_(- learning_rate * biases2.grad.data)
# 每次迭代后,需要清空梯度的值,不然下次会累加,就会出错
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
loss: tensor(2951.7420, dtype=torch.float64, grad_fn=)
loss: tensor(151.5399, dtype=torch.float64, grad_fn=)
loss: tensor(145.4891, dtype=torch.float64, grad_fn=)
loss: tensor(143.6134, dtype=torch.float64, grad_fn=)
loss: tensor(142.5731, dtype=torch.float64, grad_fn=)
loss: tensor(141.8965, dtype=torch.float64, grad_fn=)
loss: tensor(141.4289, dtype=torch.float64, grad_fn=)
loss: tensor(141.0740, dtype=torch.float64, grad_fn=)
loss: tensor(140.8079, dtype=torch.float64, grad_fn=)
loss: tensor(140.6008, dtype=torch.float64, grad_fn=)
简单构造神经网络模型–torch自带的方式定义网络模型
- 在用定义好的模型架构是,务必要想明白自己的输入是什么 : input_size = .shape[-1],一般是这样的
input_size = input_features.shape[1] # 14 ,每个样本的特征数
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size,hidden_size),
torch.nn.ReLU(),
torch.nn.Linear(hidden_size,output_size)
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(),lr=0.001)
# 训练网络
losses = []
for i in range(1000):
batch_loss = []
# MINI-batch方法来进行训练
for start in range(0,len(input_features),batch_size):
end = start + batch_size if batch_size + start < len(input_features) else len(input_features)
xx = torch.tensor(input_features[start:end],dtype=torch.float,requires_grad=True)
yy = torch.tensor(labels[start:end],dtype=torch.float,requires_grad=True)
predict = my_nn(xx)
loss = cost(predict,yy) # 前向传播后,计算损失
optimizer.zero_grad() # 计算过损失后,记得将本次的梯度清0
loss.backward(retain_graph=True) # 从损失这里进行反向传播, retain_graph=True,这个cell代码可以重复执行
optimizer.step() # 得到了梯度
batch_loss.append(loss.data.numpy())
# 打印损失
if i % 100 == 0:
losses.append(np.mean(batch_loss))
print(i,np.mean(batch_loss))
0 3983.5085
100 38.791477
200 36.883423
300 35.156437
400 34.256096
500 33.815426
600 33.510506
700 33.3035
800 33.108738
900 32.939754
预测训练结果
# 拿测试集进行训练 - 测试集用的就是训练集
x = torch.tensor(input_features, dtype = torch.float)
predict = my_nn(x).data.numpy() # x传进去网络后输出预测值,改成numpy格式是为了方便画图
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
len(dates),labels.shape
(348, (348,))
- 注:dates是个列表,labels是个array数组,一样可以形成一个DateFrame
# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
true_data
| date | actual | |
|---|---|---|
| 0 | 2016-01-01 | 45 |
| 1 | 2016-01-02 | 44 |
| 2 | 2016-01-03 | 41 |
| 3 | 2016-01-04 | 40 |
| 4 | 2016-01-05 | 44 |
| ... | ... | ... |
| 343 | 2016-12-27 | 47 |
| 344 | 2016-12-28 | 48 |
| 345 | 2016-12-29 | 48 |
| 346 | 2016-12-30 | 57 |
| 347 | 2016-12-31 | 40 |
348 rows × 2 columns
# 同理,再创建一个来存日期和其对应的模型预测值
months = features[:, features_list.index('month')]
days = features[:, features_list.index('day')]
years = features[:, features_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predict.reshape(-1)})
predictions_data
| date | prediction | |
|---|---|---|
| 0 | 2016-01-01 | 47.536388 |
| 1 | 2016-01-02 | 47.490662 |
| 2 | 2016-01-03 | 47.177219 |
| 3 | 2016-01-04 | 46.825207 |
| 4 | 2016-01-05 | 47.268284 |
| ... | ... | ... |
| 343 | 2016-12-27 | 46.065796 |
| 344 | 2016-12-28 | 44.972095 |
| 345 | 2016-12-29 | 46.179050 |
| 346 | 2016-12-30 | 46.860462 |
| 347 | 2016-12-31 | 47.443775 |
348 rows × 2 columns
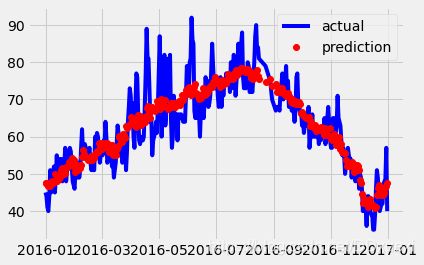
# 真实值 -- 用DataFrame格式的数据画图 : x轴,y轴,图的表示方式(颜色/线条形状),标签(就是注释)
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.legend()
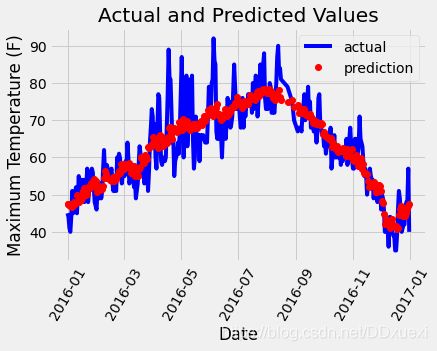
# 真实值 -- 用DataFrame格式的数据画图 : x轴,y轴,图的表示方式(颜色/线条形状),标签(就是注释)
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60'); # 横坐标的值倾斜的角度
plt.legend()
# 图名
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)');
plt.title('Actual and Predicted Values');
总结
-
1.将读取的数据转成tensor然后才能传入模型,tf中字典/ndarray/tensor格式都可以
-
2.神经网络搭建流程
-
3.画图怎么画的
- plt.plot(x轴数据,y轴数据,颜色/线条/,label)
- plt.x_label(),plt.ylabel(’’)给x轴和y轴命名
- plt.title()指定标题
- !!! plt.xticks(rotation=‘60’)设置x轴字体的倾斜角度是60
-
4.同时画多个图!!!
-
设置布局
-
fig,((ax1,ax2),(ax3,ax4)) = plt.subplots(nrows=2,ncols=2,figsize=(10,10))
-
fig.autofmt_xdate(rotation=45)
-
其中ax1,…ax4就是指的这四个图,可以用ax1.plot/ax1.xlabel()等定义图的一些格式
-
figsize是四个图的大小,不是一个图的
-
plt.subplots是画多个图的方法,在其中指定了几行几列和大小
-
fig是什么emm
-
-
5.时间格式的处理
- import datetime 是定义时间相关的
- dates = [str(int(year))+’-’+str(int(month))+’-’+str(int(day)) for year,month,day in zip(years,months,days)]
- dates = [datetime.datetime.strptime(date,’%Y-%m-%d’) for date in dates] : 将数据转成想要的格式